



-
摘要:
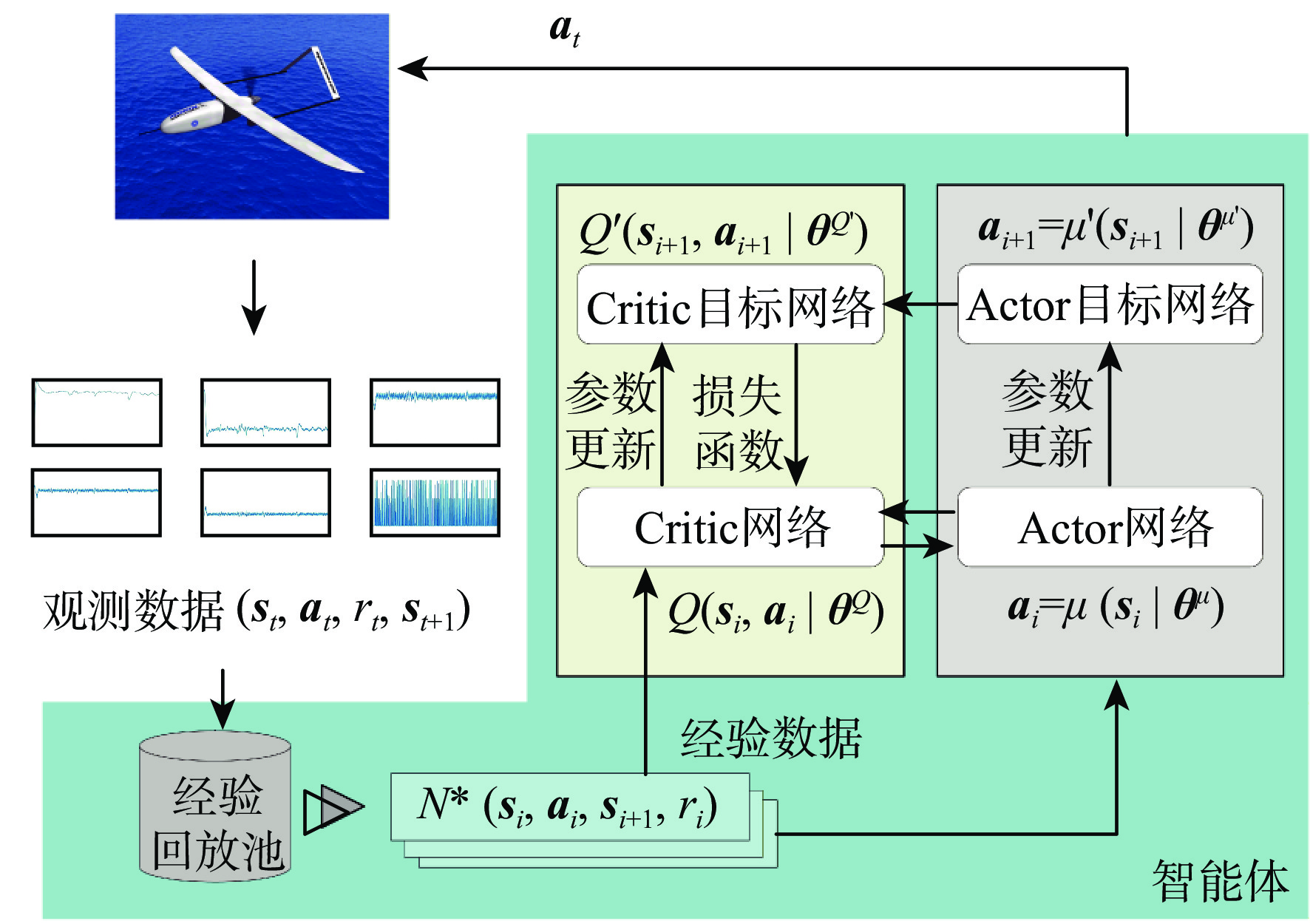
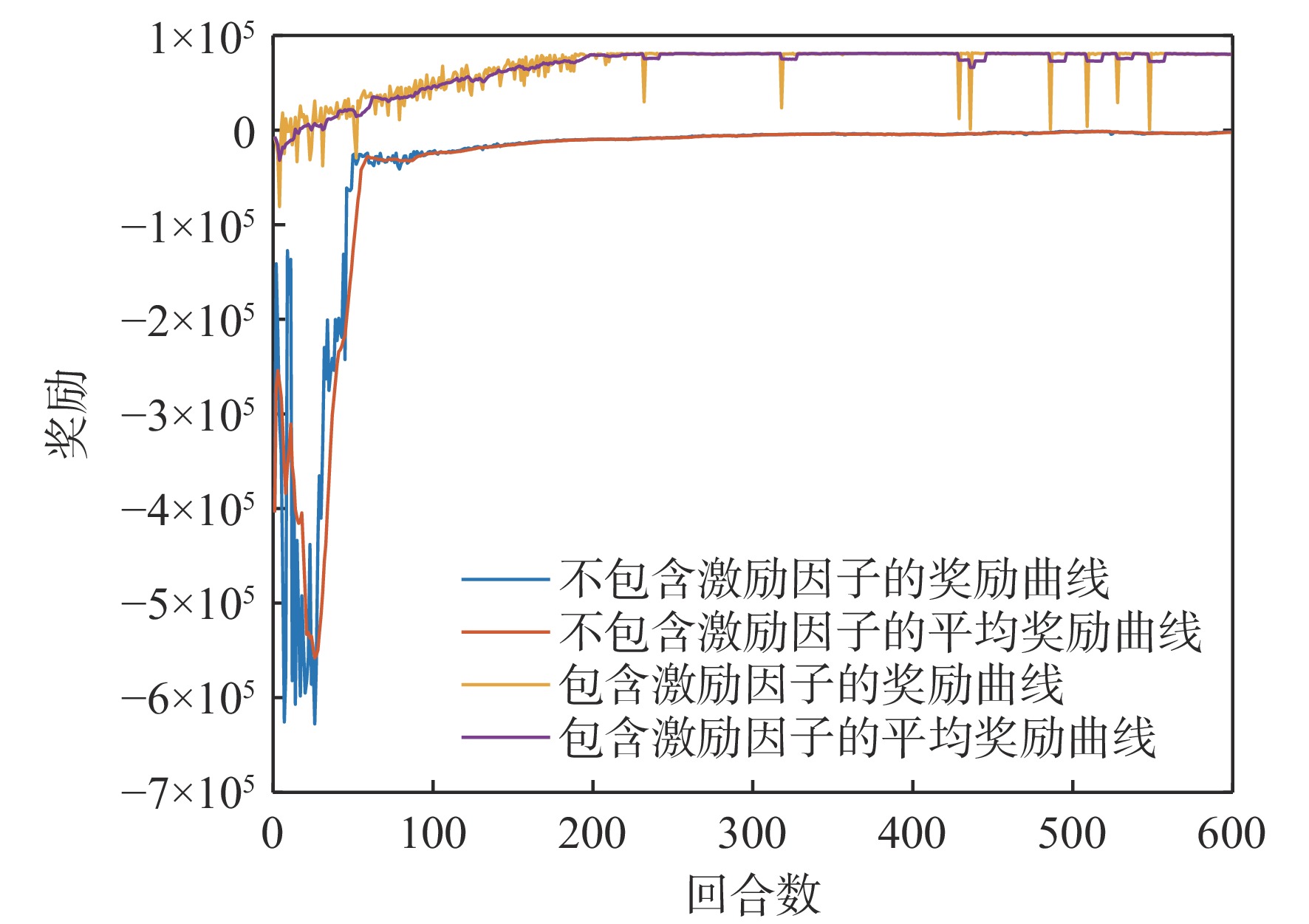
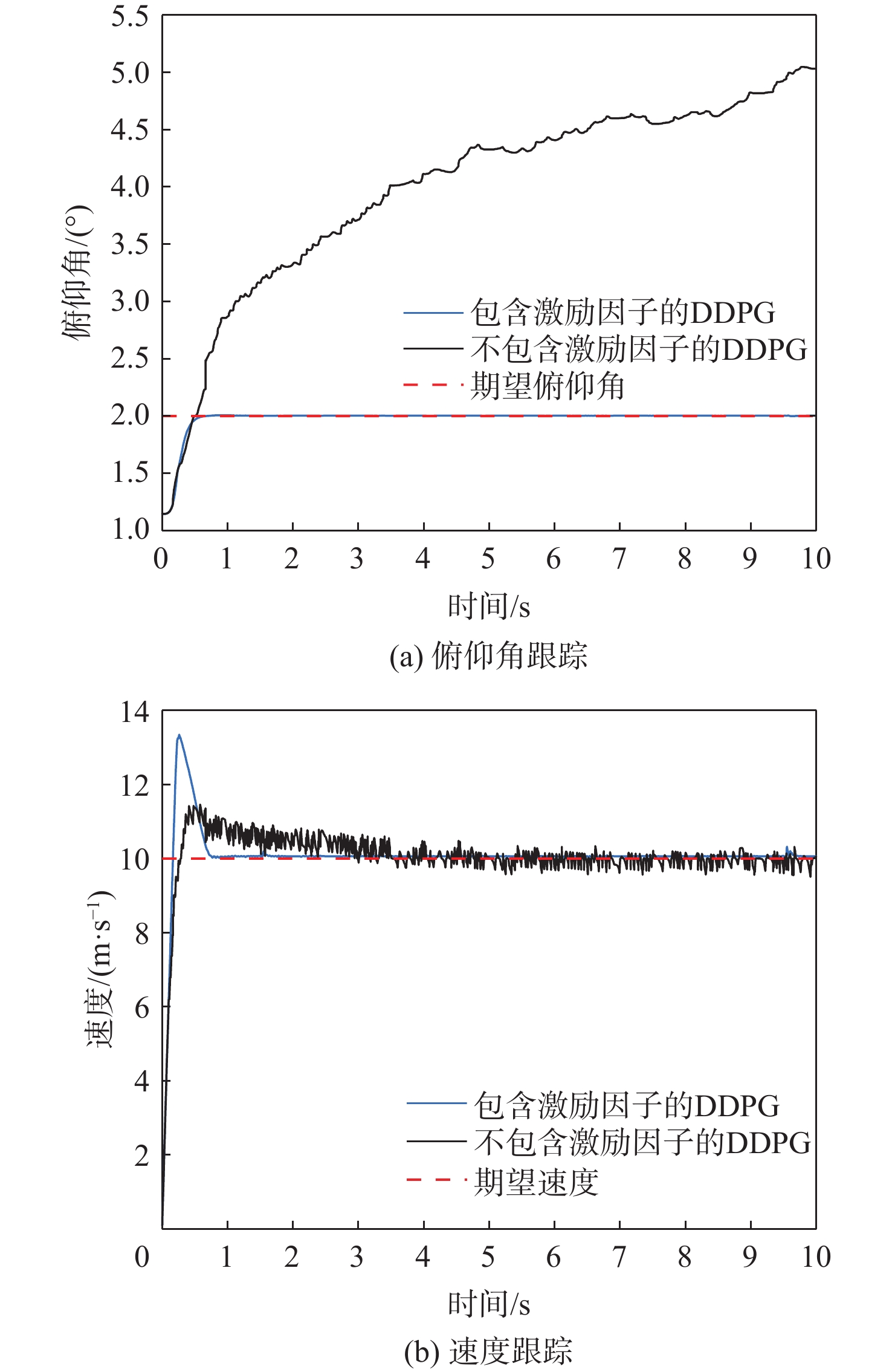
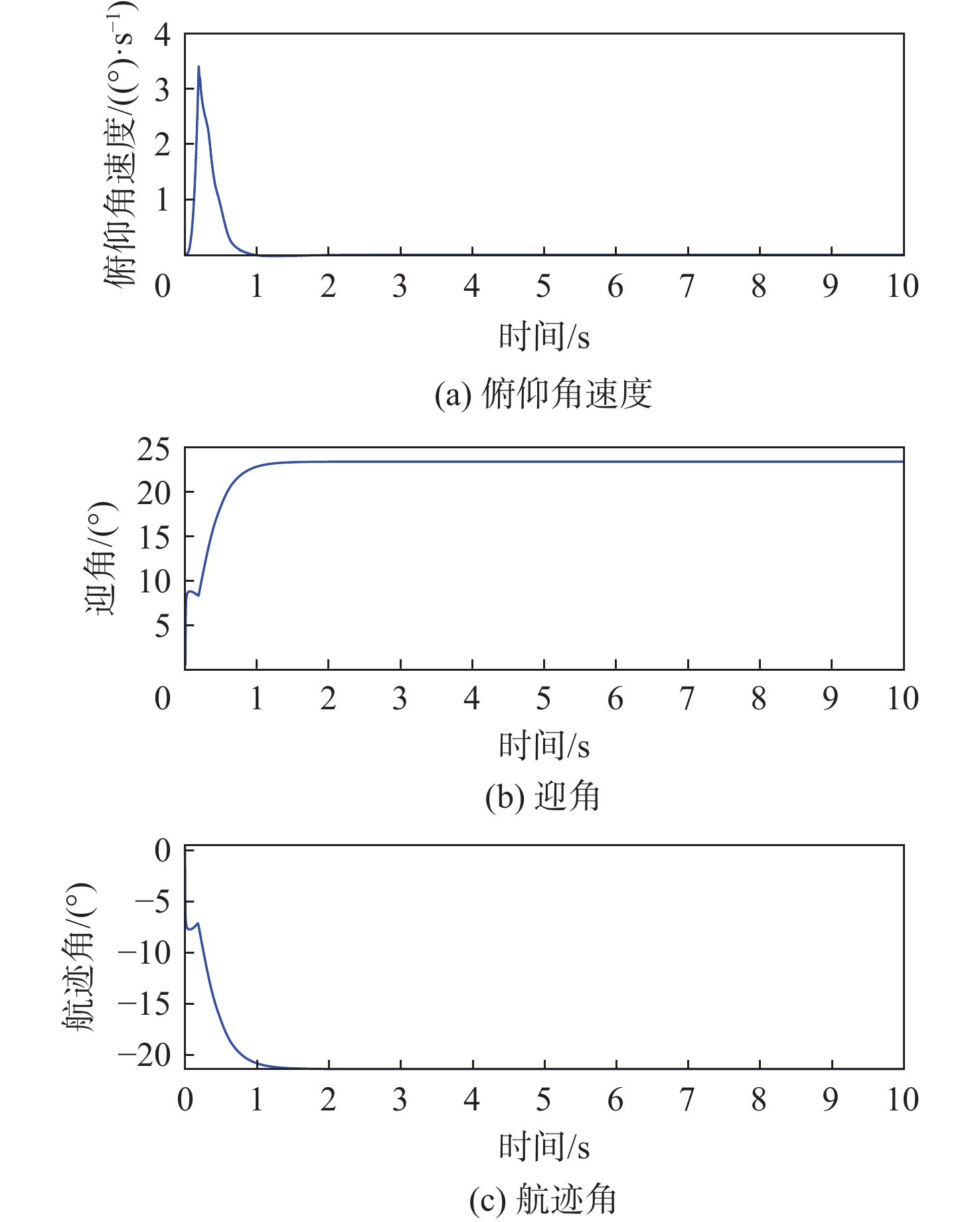
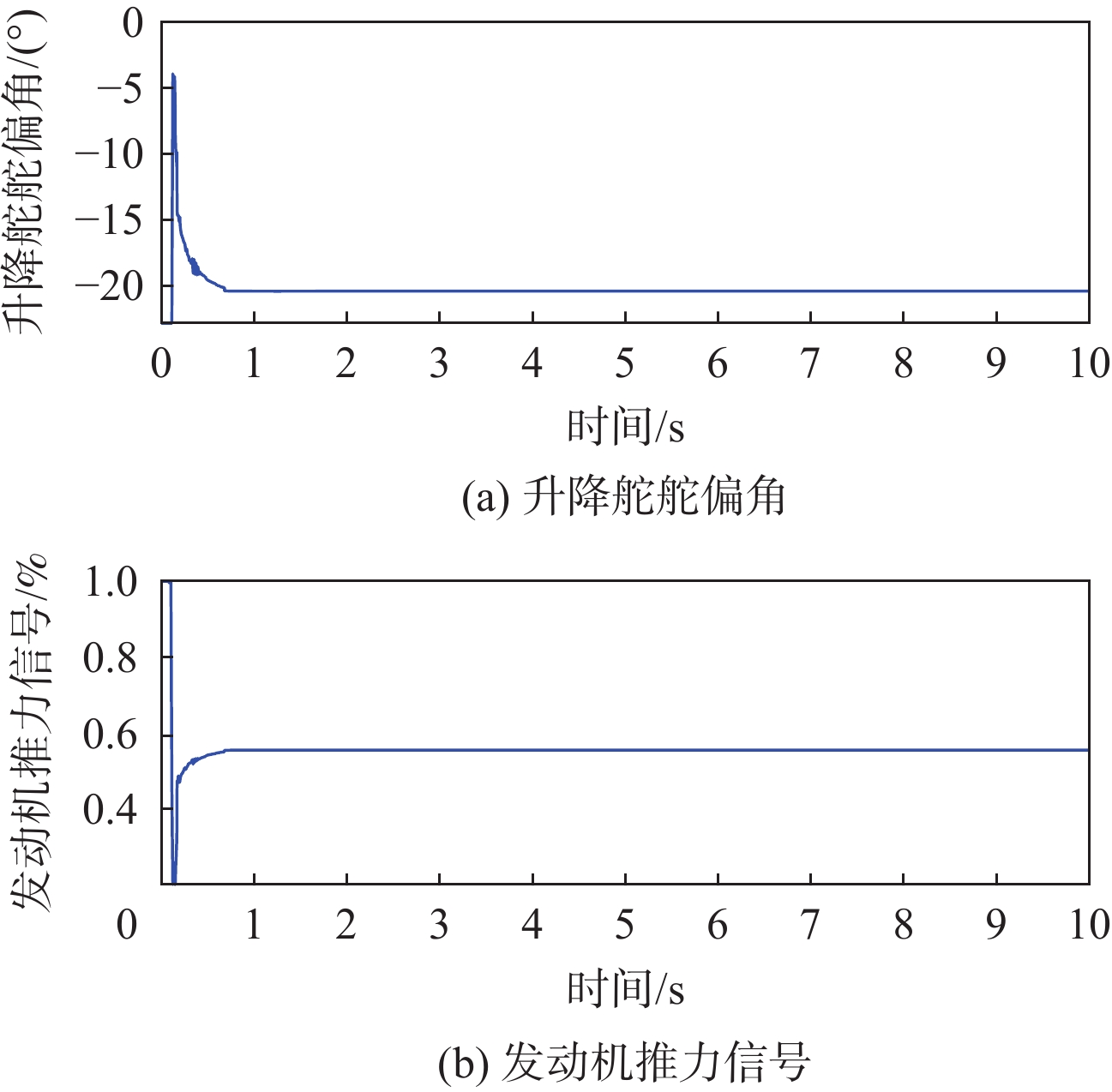
固定翼无人机(UAV)作为典型的非线性系统,其动态特性变得越来越复杂。传统的控制方法主要基于模型和经验设计,缺乏对复杂环境和任务的适应性。基于多维连续状态输入、多维连续动作输出的深度确定性策略梯度(DDPG)算法,设计了一种固定翼无人机的纵向飞行控制器,以多个时刻的速度、俯仰角跟踪误差及相关量作为控制器的输入,输出为升降舵舵偏角和发动机推力信号。为提高算法的学习效率,减轻稀疏奖励对算法学习的影响,奖励函数中除跟踪误差的密集惩罚项外,还引入了正值激励因子,当跟踪误差控制在一定范围内并快速跟踪目标时给予正值奖励。实现了从无人机状态到控制面的端到端控制,并使用比例-积分-微分(PID)控制器进行了变控制目标与模型参数摄动的飞行仿真对比,仿真结果表明,基于深度强化学习(DRL)算法构建的控制系统不仅能实现控制目标,还具备一定的泛化能力和鲁棒性,控制性能在部分情况下优于PID控制器。
Abstract:As a typical nonlinear system, the dynamic characteristics of a fixed-wing unmanned aerial vehicle (UAV) become more and more complex. Traditional control methods are mainly designed based on model and experience, and lack adaptability to complex environments and tasks. Based on the deep deterministic policy gradient (DDPG) algorithm of multi-dimensional continuous state input and multi-dimensional continuous action output, a longitudinal flight controller of a fixed-wing UAV was designed. The speed, pitch angle tracking errors, and related quantities of multiple moments were taken as the input of the controller, and the output was the elevator deflection and throttle setting signals. To improve the learning efficiency of the algorithm and mitigate the impact of sparse rewards on learning, the reward function introduced positive reward incentives in addition to the dense penalty for tracking errors. These positive rewards were given when the tracking error fell within a certain range and when the agent quickly reached the tracking target. Ultimately, end-to-end control from the longitudinal state of the UAV to the control surface was achieved, and under various control targets and model parameter perturbations, simulations were performed to compare the proportional-integral-derivative (PID) controller with a deep reinforcement learning-based control system. According to the simulation results, the deep reinforcement learning (DRL)-based control system may accomplish control goals and show some degree of robustness and generalization, with control performance sometimes outperforming the PID controller.
-
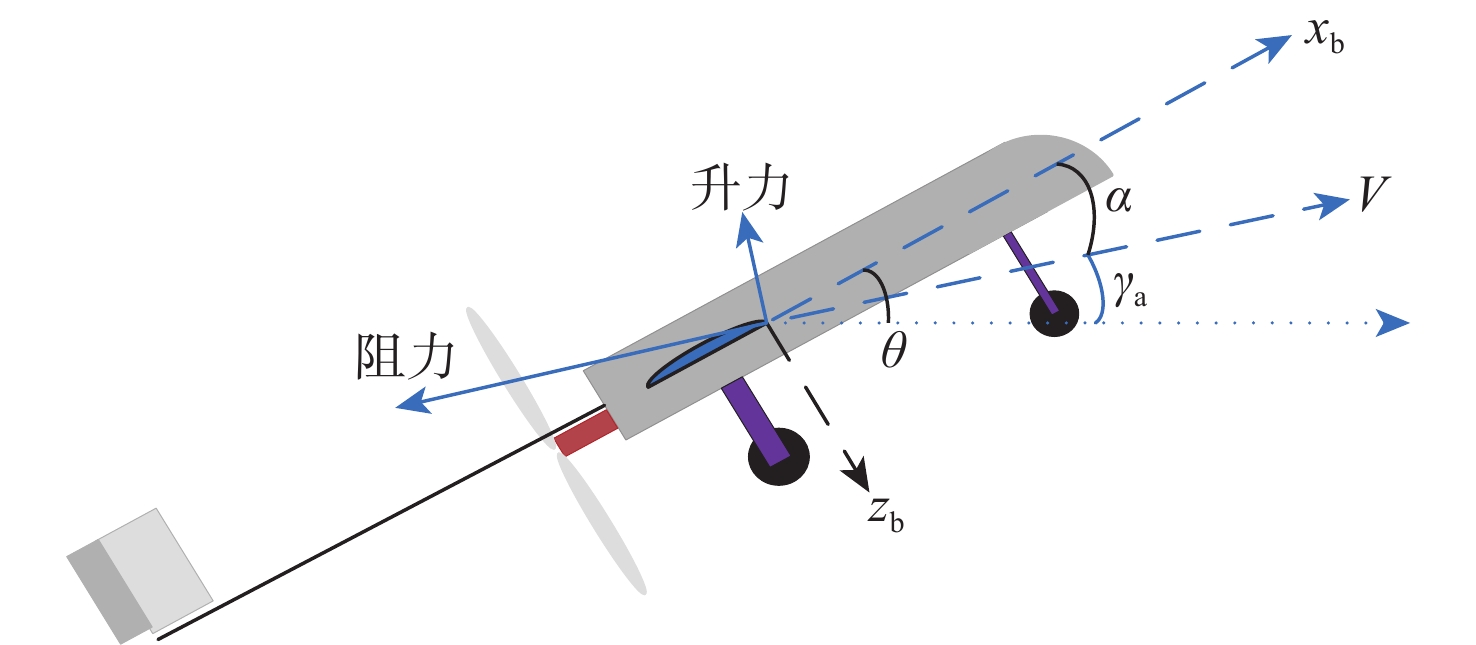
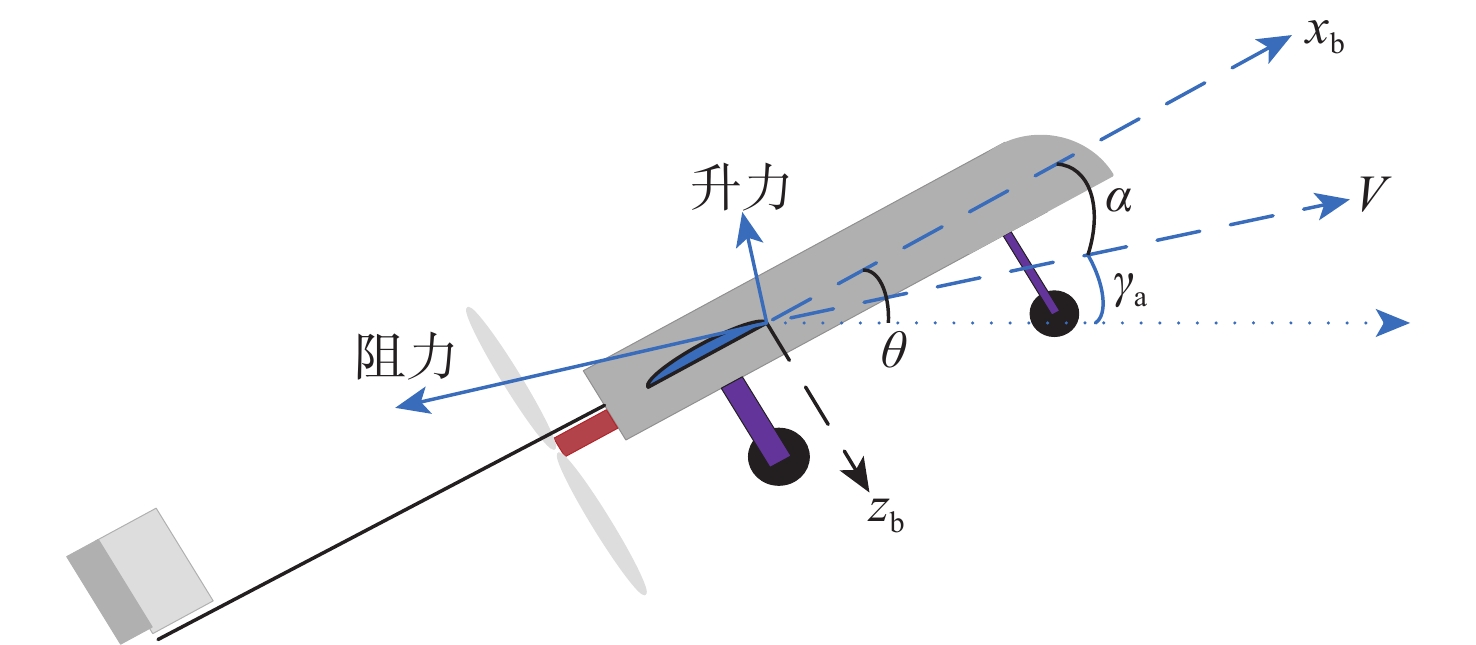
图 1 无人机系统坐标、角度与空气动力学示意图
Figure 1. Illustration of UAV system coordinates, angles, and aerodynamics forces
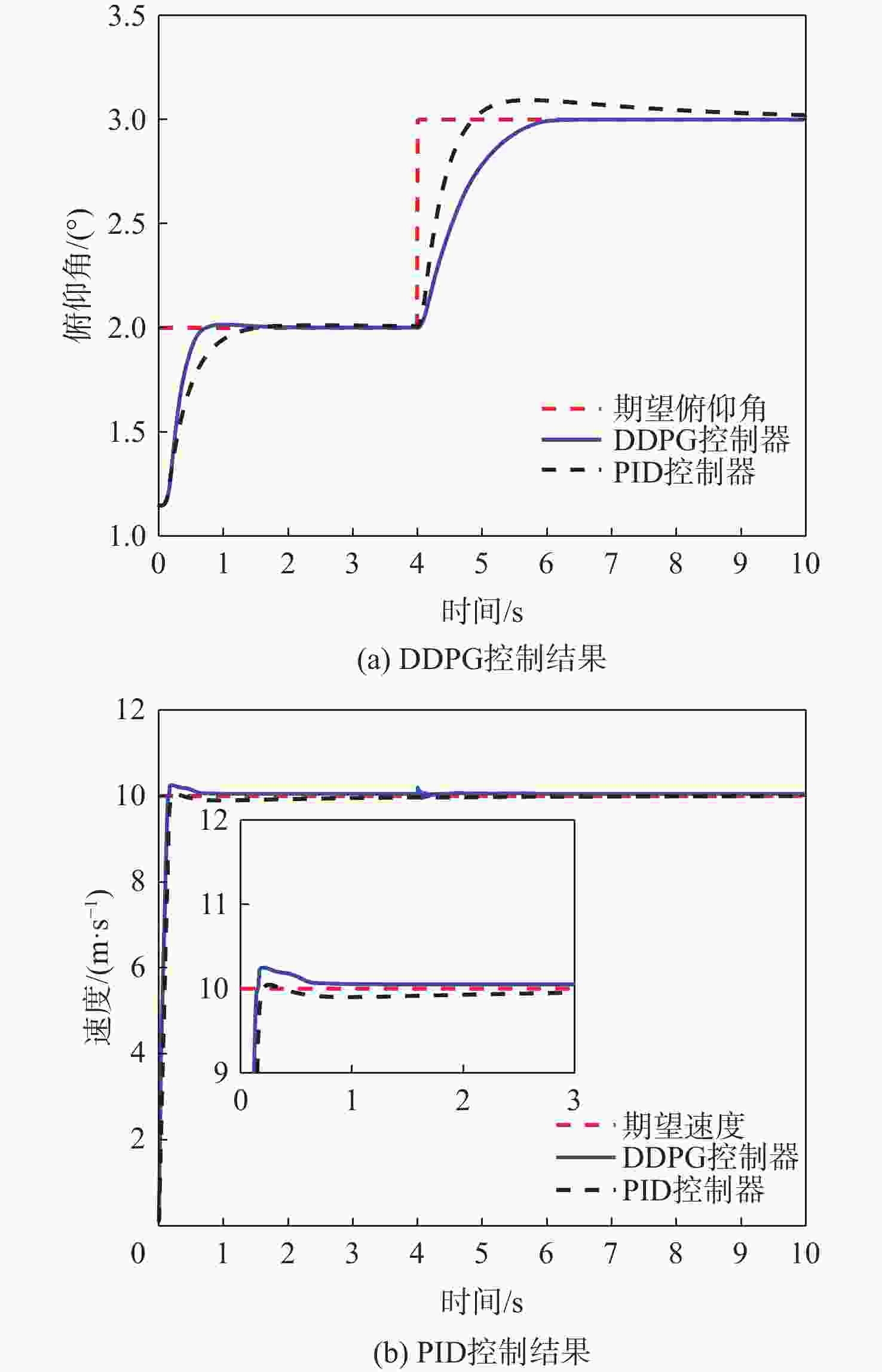
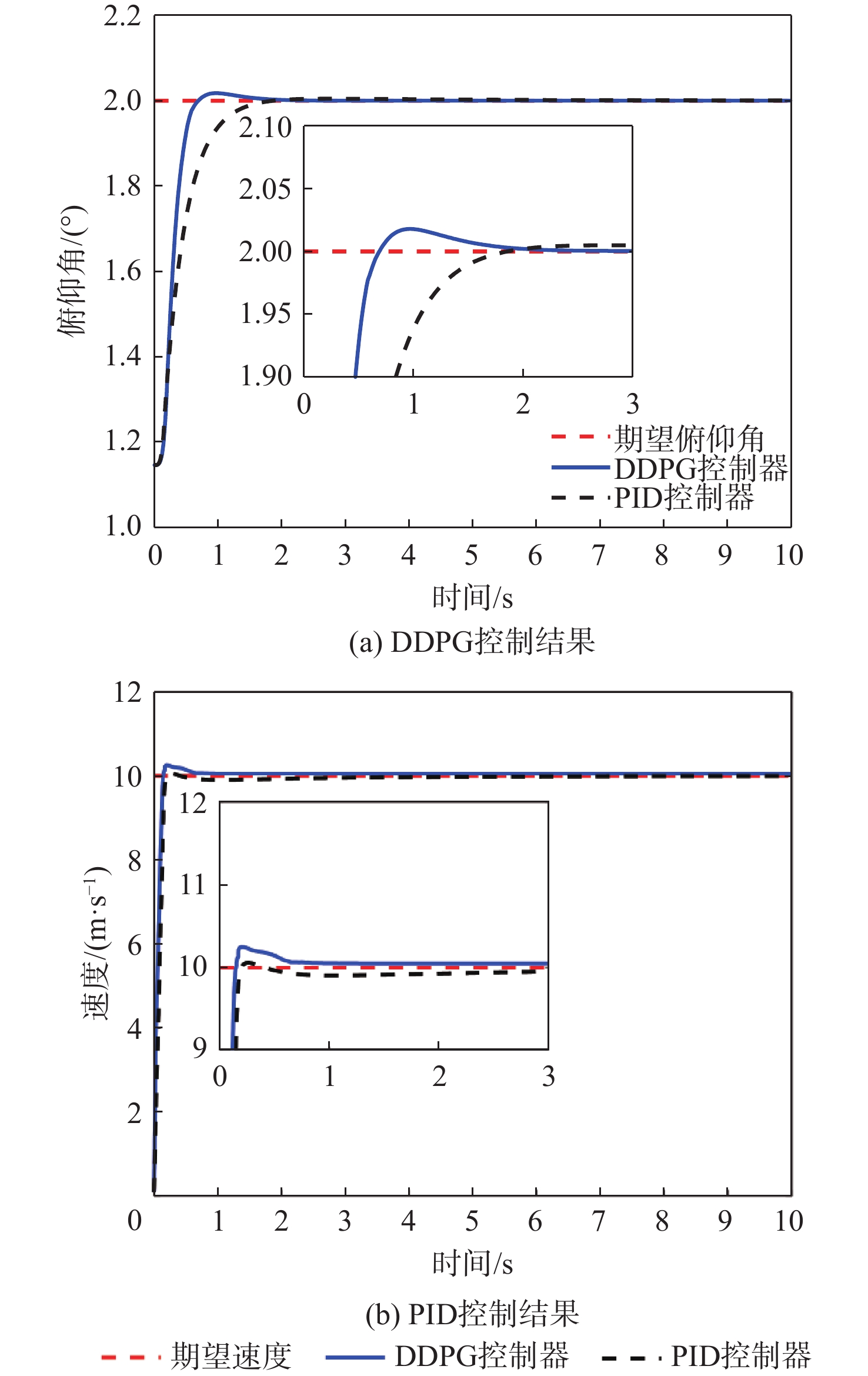
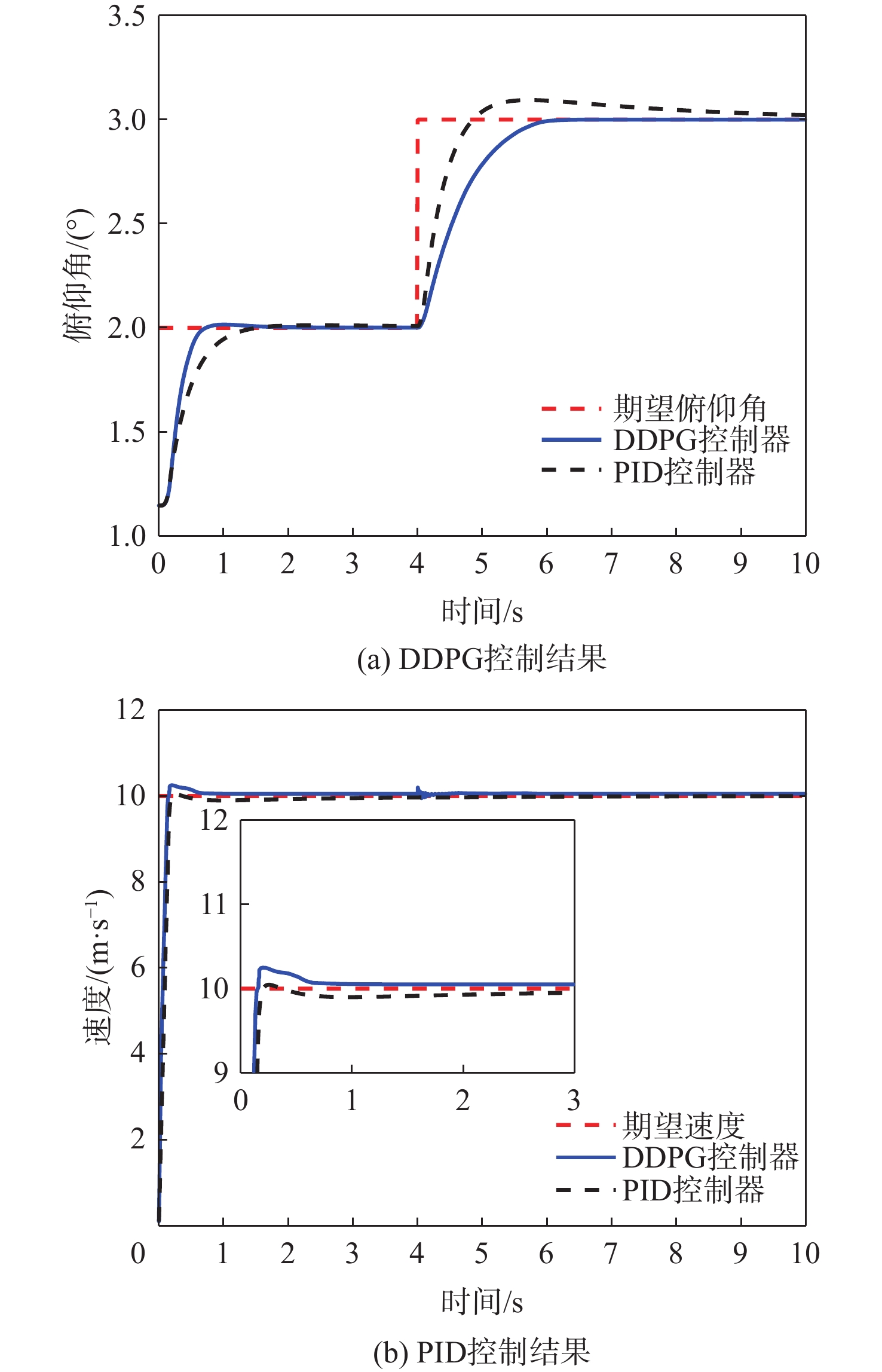
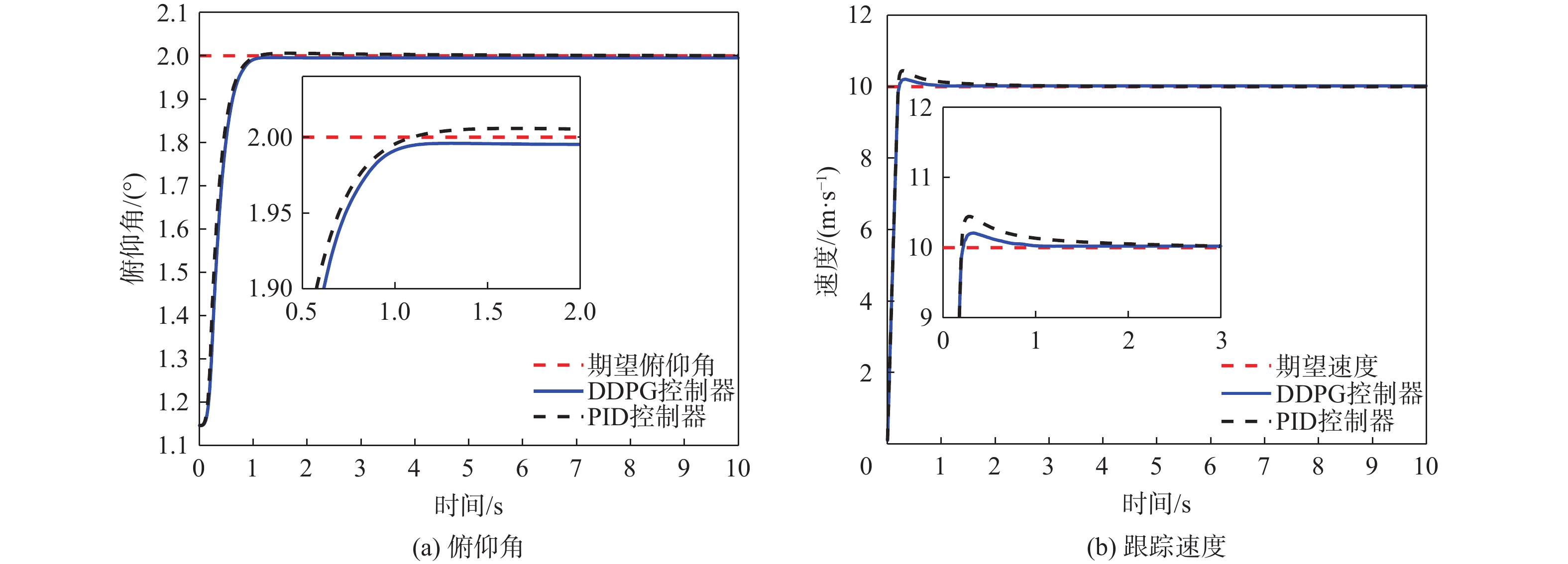
图 8 变期望俯仰角后DDPG与PID控制结果对比
Figure 8. Comparison of DDPG and PID control results after changing desired pitch angle
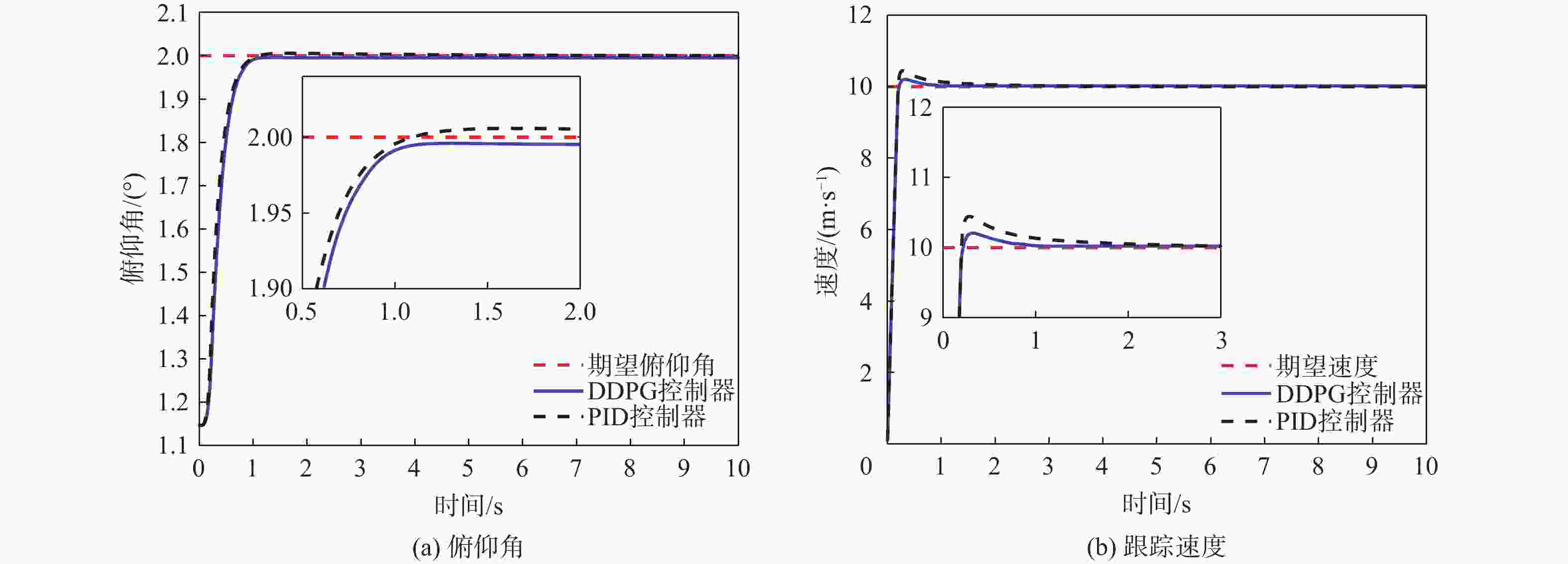
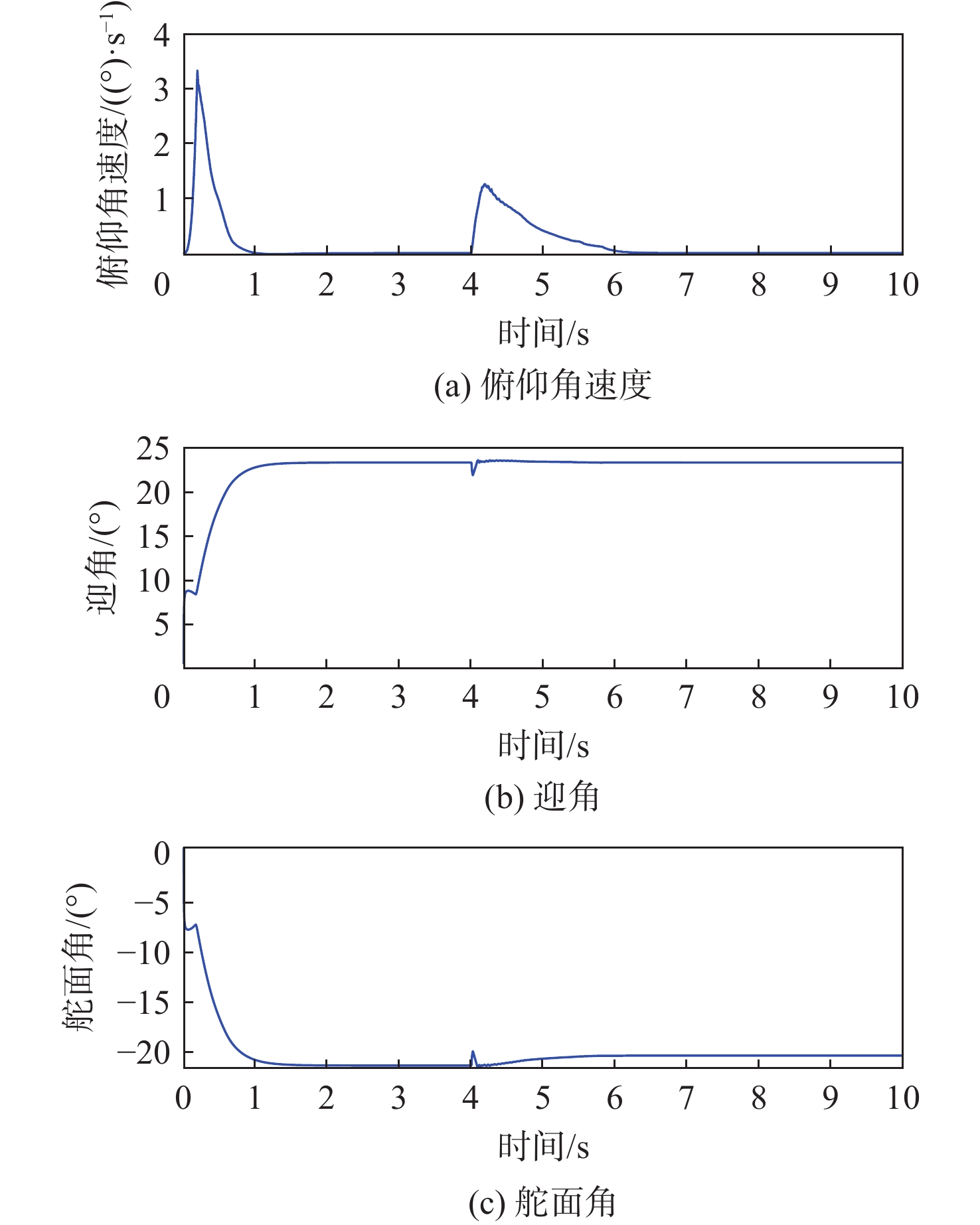
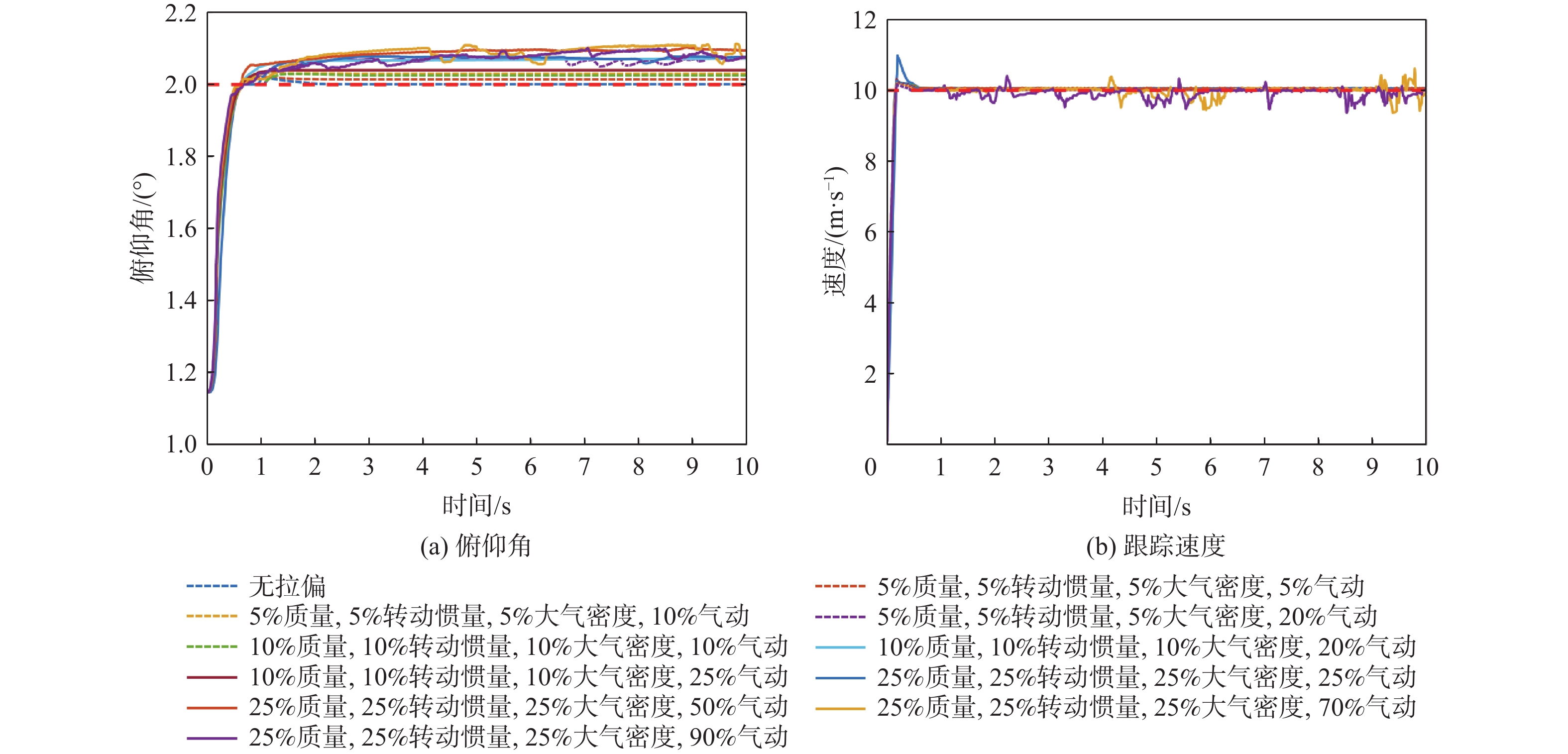
图 10 DDPG和PID在模型参数摄动下的控制结果对比
Figure 10. Comparison of control results between DDPG and PID controllers under perturbed model parameters
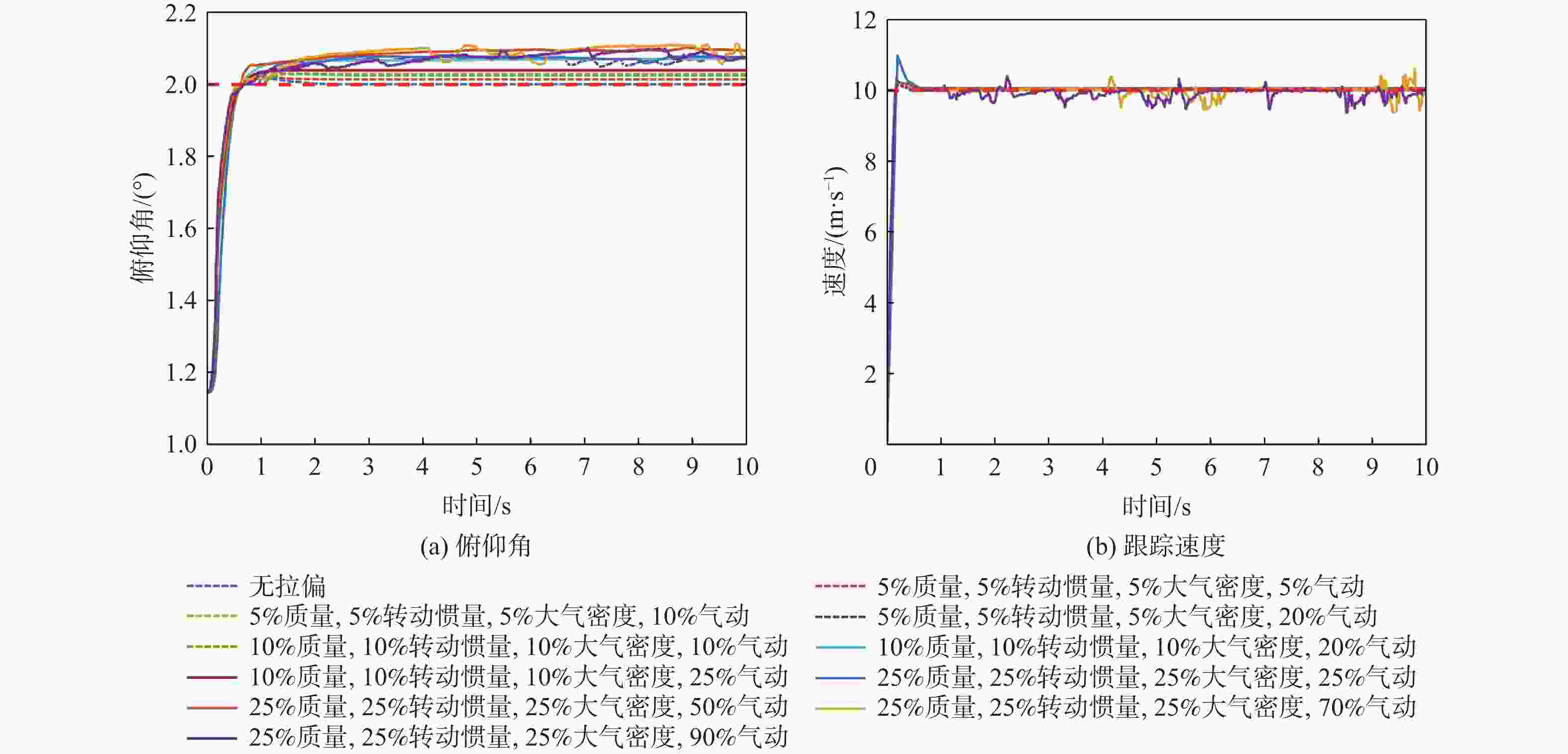
图 11 DDPG在模型参数摄动的控制结果
Figure 11. Control results of DDPG with model parameter perturbation
表 1 DDPG训练参数
Table 1. DDPG training parameters
Critic 学习率 Actor 学习率 优化器 批数量 经验回放池大小 惯性更新率 折扣系数 单次训练周期/个 0.001 0.000 5 Adam 128 1000000 0.001 0.98 1000 注:一个单次训练周期为10 s。  下载: 导出CSV
下载: 导出CSV
表 2 控制器对比仿真使用的参数不确定性
Table 2. Parameters uncertainties used for controllers comparison simulation
参数 不确定性/% $ m $ 25 $ {I}_{y} $ 25 $ \rho $ 25 $ {C}_{{{L}_{\alpha }}} $ 25 $ {C}_{{{L}_{0}}}$ 10 ${C}_{{{L}_{{{\delta }_{{\mathrm{e}}}}}}} $ 10 $ {C}_{{{m}_{0}}} $ −20 $ {C}_{{{m}_{\alpha }}}$ −20 $ {C}_{{{m}_{{{\delta }_{{\mathrm{e}}}}}}} $ −20
下载: 导出CSV
-
[1] GHAMARI M, RANGEL P, MEHRUBEOGLU M, et al. Unmanned aerial vehicle communications for civil applications: a review[J]. IEEE Access, 2022, 10: 102492-102531. [2] 符文星, 郭行, 闫杰. 智能无人飞行器技术发展趋势综述[J]. 无人系统技术, 2019, 2(4): 31-37.FU W X, GUO H, YAN J. Overview on the technology development trend of intelligent unmanned aerial vehicle[J]. Unmanned Systems Technology, 2019, 2(4): 31-37(in Chinese). [3] SHAN Y Q, WANG S, KONVISAROVA A, et al. Attitude control of flying wing UAV based on advanced ADRC[J]. IOP Conference Series: Materials Science and Engineering, 2019, 677(5): 137-142. [4] YU Z Q, ZHANG Y M, JIANG B. PID-type fault-tolerant prescribed performance control of fixed-wing UAV[J]. Journal of Systems Engineering and Electronics, 2021, 32(5): 1053-1061. [5] ZHAO X C, YUAN M N, CHENG P Y, et al. Robust H∞/S-plane controller of longitudinal control for UAVs[J]. IEEE Access, 2019, 7: 91367-91374. [6] ZHENG F Y, ZHEN Z Y, GONG H J. Observer-based backstepping longitudinal control for carrier-based UAV with actuator faults[J]. Journal of Systems Engineering and Electronics, 2017, 28(2): 322-377. [7] SEOKWON L, JIHOON L, SOMANG L, et al. Sliding mode guidance and control for UAV carrier landing[J]. IEEE Transactions on Aerospace and Electronic Systems, 2019, 55(2): 951-966. [8] ZHANG J L, ZHANG P, YAN J G. Distributed adaptive finite-time compensation control for UAV swarm with uncertain disturbances[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2021, 68(2): 829-841. [9] YU K Y, JIN K, DENG X Y. Review of deep reinforcement learning[C]//Proceedings of the 2022 IEEE 5th Advanced Information Management, Communicates, Electronic and Automation Control Conference. Piscataway: IEEE Press, 2022: 41-48. [10] 甄岩, 袁健全, 池庆玺, 等. 深度强化学习方法在飞行器控制中的应用研究[J]. 战术导弹技术, 2020(4): 112-118.ZHEN Y, YUAN J Q, CHI Q X, et al. Research on application of deep reinforcement learning method in aircraft control[J]. Tactical Missile Technology, 2020(4): 112-118(in Chinese). [11] 程林, 蒋方华, 李俊峰. 深度学习在飞行器动力学与控制中的应用研究综述[J]. 力学与实践, 2020, 42(3): 267-276.CHENG L, JIANG F H, LI J F. A review on the applications of deep learning in aircraft dynamics and control[J]. Mechanics in Engineering, 2020, 42(3): 267-276(in Chinese). [12] PI C H, HU K C, CHENG S, et al. Low-level autonomous control and tracking of quadrotor using reinforcement learning[J]. Control Engineering Practice, 2020, 95: 104222. [13] 孙丹, 高东, 郑建华, 等. 引入积分补偿的四旋翼确定性策略梯度控制器[J]. 计算机工程与设计, 2023, 44(1): 255-261.SUN D, GAO D, ZHENG J H, et al. Deterministic policy gradient controller with integral compensator for quadrotor[J]. Computer Engineering and Design, 2023, 44(1): 255-261(in Chinese). [14] YOO J, JANG D, KIM H J, et al. Hybrid reinforcement learning control for a micro quadrotor flight[J]. IEEE Control Systems Letters, 2021, 5(2): 505-510. [15] HAN H R, CHENG J, XI Z L, et al. Cascade flight control of quadrotors based on deep reinforcement learning[J]. IEEE Robotics and Automation Letters, 2022, 7(4): 11134-11141. [16] 梁吉, 王立松, 黄昱洲, 等. 基于深度强化学习的四旋翼无人机自主控制方法[J]. 计算机科学, 2023, 50(增刊2): 13-19.LIANG J, WANG L S, HUANG Y Z, et al. Autonomous control method of quadrotor UAV based on deep reinforcement learning[J]. Computer Science, 2023, 50(Sup 2): 13-19(in Chinese). [17] 孙丹, 高东, 郑建华, 等. 示教知识辅助的无人机强化学习控制算法[J]. 北京航空航天大学学报, 2023, 49(6): 1424-1433.SUN D, GAO D, ZHENG J H, et al. UAV reinforcement learning control algorithm with demonstrations[J]. Journal of Beijing University of Aeronautics and Astronautics, 2023, 49(6): 1424-1433(in Chinese). [18] 张经伦, 杨希祥, 邓小龙, 等. 基于深度强化学习的平流层浮空器高度控制[J]. 北京航空航天大学学报, 2023, 49(8): 2062-2070.ZHANG J L, YANG X X, DENG X L, et al. Altitude control of stratospheric aerostat based on deep reinforcement learning[J]. Journal of Beijing University of Aeronautics and Astronautics, 2023, 49(8): 2062-2070(in Chinese). [19] BØHN E, COATES E M, REINHARDT D, et al. Data-efficient deep reinforcement learning for attitude control of fixed-wing UAVs: field experiments[J]. IEEE Transactions on Neural Networks and Learning Systems, 2023, 35(3): 3168-3180. [20] BOHN E, COATES E M, MOE S, et al. Deep reinforcement learning attitude control of fixed-wing UAVs using proximal policy optimization[C]//Proceedings of the 2019 International Conference on Unmanned Aircraft Systems. Piscataway: IEEE Press, 2019: 523-533. [21] 章胜, 杜昕, 肖娟, 等. 基于深度强化学习的固定翼飞行器六自由度飞行智能控制[J]. 指挥与控制学报, 2022, 8(2): 179-188.ZHANG S, DU X, XIAO J, et al. Fixed-wing aircraft 6-DOF flight control based on deep reinforcement learning[J]. Journal of Command and Control, 2022, 8(2): 179-188(in Chinese). [22] BEARD R W, MCLAIN T W. Small unmanned aircraft: theory and practice[M]. Princeton: Princeton University Press, 2012: 43-52. -

 下载:
下载:

 点击查看大图
点击查看大图
计量
- 文章访问数: 913
- HTML全文浏览量: 233
- PDF下载量: 76
- 被引次数: 0
