



Small object detection algorithm for aerial photography based on adaptive compound convolution
-
摘要:
针对航拍图像中小目标的比例较高且特征提取效果差等问题,提出一种在精度和存储资源消耗上相对平衡的航拍小目标检测算法。提出一种轻量化自适应复合卷积(LACC)模块,加强对细粒度特征的提取能力,并摒弃背景信息达到自适应调节有效特征的输出;基于LACC设计一种多尺度特征融合网络,进一步降低小目标漏检率;使用空间上下文金字塔(SCP)的子分支替代快速空间金字塔池化(SPPF)模块,减少信息混淆与冗余的同时还能适应小目标检测场景;构建一种WiseIou-V3-NMS非极大值抑制算法,考虑检测框具有对象但被删除的情况,使其有效提高网络对遮挡重叠目标的检测定位能力;提出轻量化共享卷积GN检测头,保持对多尺度特征信息敏感的同时减少参数量及模型大小。在VisDrone2019公开数据集上,所提算法的平均精度平均值MAP0.5为0.466,相比于基线算法YOLOv8s提升0.077,网络参数量减少21.6%,模型大小减少18.7%。
Abstract:To remedy the problem of aerial imagery, including the high proportion of small objects and the poor feature extraction effect, a small object detection algorithm with relatively balanced accuracy and storage resource consumption is proposed. To improve the capacity to extract fine-grained features and produce adaptable features without background information, a lightweight adaptive compound convolutional (LACC) module is first suggested. Then, a multi-scale feature fusion network based on LACC is designed to further reduce the missing rate of small targets. Secondly, the sub-branches of the spatial context pyramid (SCP) are used to replace the spatial pyramid pooling-fast (SPPF) module, which can reduce information confusion and redundancy, and adapt to small target detection scenarios. In order for the network to successfully increase the detection and positioning capabilities of occlusion-overlapping targets, a WiseIou-V3-NMS non-maximum suppression method is then built, taking into account that the detection frame contains objects but is erased. Finally, a lightweight shared convolutional GN detection head is proposed to keep the sensitivity to multi-scale feature information while reducing the number of parameters and computation. On the VisDrone2019 public dataset, the proposed algorithm achieves a mean accuracy MAP0.5 of 0.466, which is 0.077 higher than the baseline algorithm YOLOv8s, the number of network parameters is reduced by 21.6%, and the model size is reduced by 18.7%.
-
Key words:
- aerial images /
- small target detection /
- YOLOv8 /
- feature fusion /
- fine-grained features
-
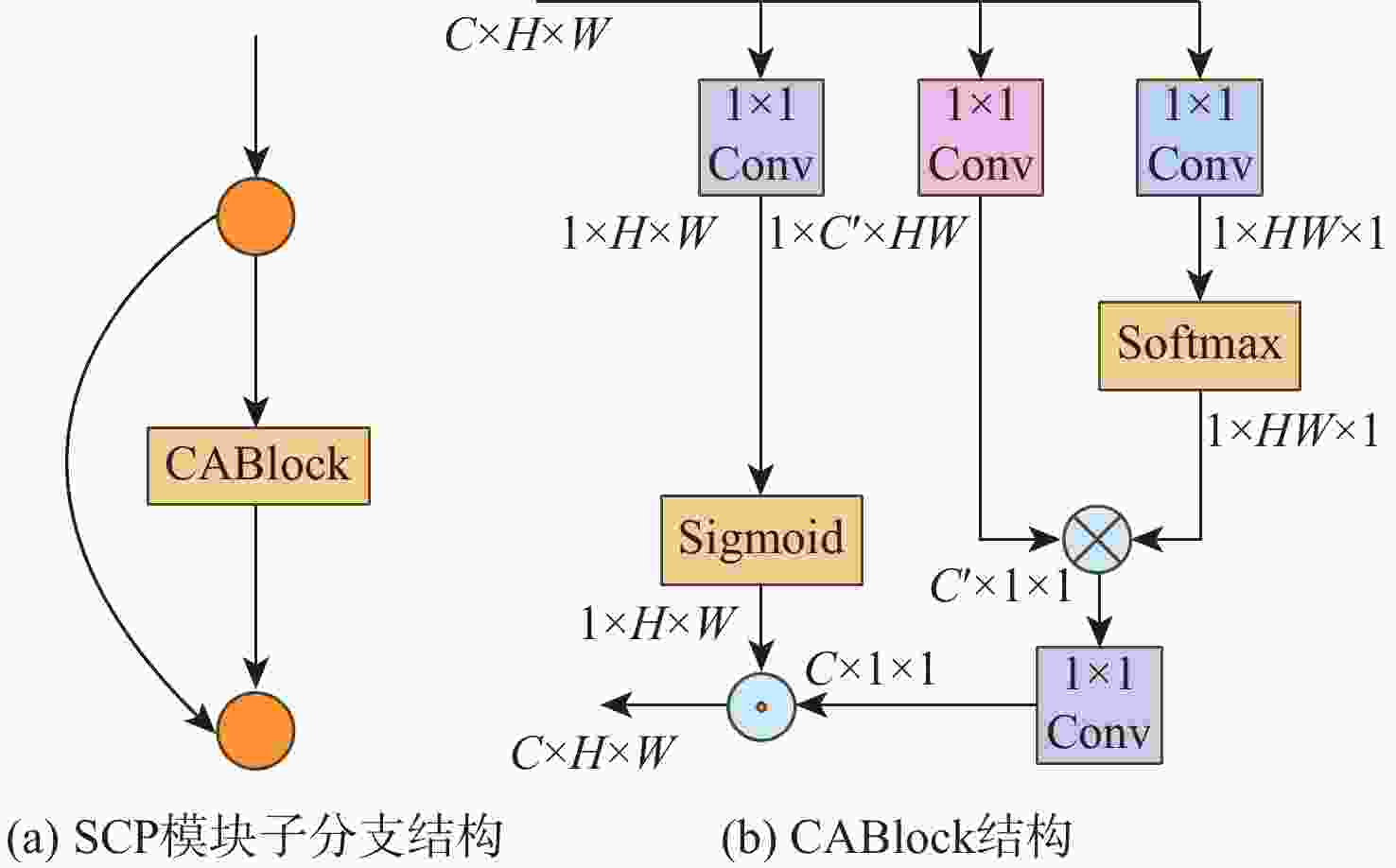
图 4 SCP模块子分支结构和CABlock结构
Figure 4. SCP module sub-branch structure and CABlock structure

图 6 遮挡重叠目标检测结果对比
Figure 6. Comparison of results of occlusion overlapping object detection

图 8 3种场景推理可视化结果对比
Figure 8. Comparison of visualization results from three scenario inferences
表 1 训练参数设置
Table 1. Training parameter setting
参数 设置 轮数 150 批次大小 4 优化器 SGD 预训练 False 冲量 0.937 权重衰减 5×10−4 马赛克数据增强
初始学习率
最终学习率1.0
1×10−2
1×10−4 下载: 导出CSV
下载: 导出CSV
表 2 输入图像不同分辨率训练结果
Table 2. Training results of input images with different resolutions
分辨率 批次大小 运行状态 最高占用显存/GB 每轮训练时长/s 640×640 4 Normal 3.26 82~91 1280 ×1280 4 Crash 1280 ×1280 2 Normal 7.18 234~243 1536 ×1536 4 Crash 1536 ×1536 2 Normal 8.81 337~350
下载: 导出CSV
表 3 LACC消融实验结果
Table 3. Results of LACC ablation experiment
数据集 N P R MAP0.5 MAP0.5:0.95 参数量 模型大小/MB 验证集 8 0.501 0.419 0.425 0.251 10.15×106 20.70 16 0.524 0.413 0.429 0.253 10.35×106 20.90 32 0.526 0.417 0.43 0.253 10.73×106 21.90 注:加粗字体为该列最优值。
下载: 导出CSV
表 4 总体消融实验结果
Table 4. Results of overall ablation experiment
数据集 模块 P R MAP0.5 MAP0.5:0.95 参数量 模型大小/MB 验证集 A 0.505 0.375 0.389 0.234 11.10×106 21.90 A+B 0.524 0.413 0.429 0.259 10.35×106 20.90 A+C 0.511 0.380 0.396 0.237 10.50×106 20.90 A+D 0.549 0.360 0.420 0.249 11.10×106 21.90 A+E 0.510 0.382 0.391 0.234 9.43×106 19.30 A+B+C 0.523 0.414 0.431 0.260 9.69×106 19.80 A+B+C+D 0.561 0.384 0.459 0.301 9.69×106 19.80 A+B+C+D+E 0.564 0.396 0.466 0.308 8.70×106 17.80 数据集 模块 P R MAP0.5 MAP0.5:0.95 测试集 A 0.435 0.335 0.312 0.177 A+B 0.446 0.364 0.343 0.193 A+C 0.438 0.334 0.316 0.177 A+D 0.489 0.301 0.375 0.258 A+E 0.434 0.339 0.314 0.177 A+B+C 0.452 0.365 0.344 0.199 A+B+C+D 0.532 0.320 0.427 0.290 A+B+C+D+E 0.532 0.300 0.430 0.290 注:加粗字体为该列最优值。
下载: 导出CSV
表 5 纵向对比实验结果
Table 5. Results of longitudinal comparison experiment
模型 AP MAP0.5 MAP0.5:0.95 参数量 模型大小/MB 行人 人 自行车 汽车 面包车 卡车 三轮车 遮阳篷
三轮车巴士 摩托车 YOLOv4[23] 0.248 0.126 0.086 0.643 0.224 0.227 0.114 0.076 0.443 0.217 0.307 0.166 9.12×106 18.20 YOLOv5s 0.390 0.313 0.112 0.735 0.354 0.295 0.205 0.111 0.431 0.37 0.332 0.174 7.03×106 18.10 YOLOv5l 0.478 0.377 0.178 0.782 0.426 0.403 0.268 0.131 0.547 0.453 0.404 0.216 46.15×106 YOLOX-l[24] 0.348 0.245 0.169 0.724 0.344 0.405 0.231 0.178 0.531 0.360 0.353 0.195 54.16×106 YOLOv7-tiny[13] 0.379 0.346 0.094 0.761 0.363 0.298 0.201 0.106 0.432 0.418 0.340 0.181 6.03×106 12.10 YOLOv8s 0.415 0.302 0.119 0.797 0.458 0.353 0.291 0.140 0.584 0.439 0.389 0.231 11.10×106 21.90 YOLOv9-C[25] 0.340 0.184 0.154 0.775 0.452 0.541 0.248 0.241 0.649 0.383 0.397 0.240 50.90×106 98.30 本文 0.482 0.432 0.35 0.772 0.505 0.418 0.372 0.242 0.579 0.455 0.466 0.308 8.70×106 17.80 注:加粗字体为该列最优值。
下载: 导出CSV
-
[1] LUO X D, WU Y Q, WANG F Y. Target detection method of UAV aerial imagery based on improved YOLOv5[J]. Remote Sensing, 2022, 14(19): 5063. [2] HE K M, ZHANG X Y, REN S Q, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916. [3] ZHOU H L, MA A T, NIU Y F, et al. Small-object detection for UAV-based images using a distance metric method[J]. Drones, 2022, 6(10): 308. [4] 何宇豪, 易明发, 周先存, 等. 基于改进的Yolov5的无人机图像小目标检测[J]. 智能系统学报, 2024, 19(3): 635-645.HE Y H, YI M F, ZHOU X C, et al. Small target detection in UAV image based on improved Yolov5[J]. CAAI Transactions on Intelligent Systems, 2024, 19(3): 635-645(in Chinese). [5] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2018: 3-19. [6] 韩俊, 袁小平, 王准, 等. 基于YOLOv5s的无人机密集小目标检测算法[J]. 浙江大学学报(工学版), 2023, 57(6): 1224-1233.HAN J, YUAN X P, WANG Z, et al. UAV dense small target detection algorithm based on YOLOv5s[J]. Journal of Zhejiang University (Engineering Science), 2023, 57(6): 1224-1233(in Chinese). [7] 刘一诺, 张琪, 王蓉, 等. 针对航拍小目标检测的YOLOv7改进方法[J]. 北京航空航天大学学报, 2025, 51(7): 2506-2512.LIU Y N, ZHANG Q, WANG R, et al. Improved YOLOv7 method for aerial small target detection in aerial photography[J]. Journal of Beijing University of Aeronautics and Astronautics, 2025, 51(7): 2506-2512(in Chinese). [8] SUNKARA R, LUO T. No more strided convolutions or pooling: a new CNN building block for low-resolution images and small objects[C]//Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Berlin: Springer, 2023: 443-459. [9] LOU H T, DUAN X H, GUO J M, et al. DC-YOLOv8: small-size object detection algorithm based on camera sensor[J]. Electronics, 2023, 12(10): 2323. [10] DU B W, HUANG Y C, CHEN J X, et al. Adaptive sparse convolutional networks with global context enhancement for faster object detection on drone images[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2023: 13435-13444. [11] ZHANG X X, WANG C Y, JIN J, et al. Object detection of VisDrone by stronger feature extraction Faster R-CNN[J]. Journal of Electronic Imaging, 2023, 32(1): 013018. [12] 薛珊, 安宏宇, 吕琼莹, 等. 复杂背景下基于YOLOv7-tiny的图像目标检测算法[J]. 红外与激光工程, 2024, 53(1): 20230472.XUE S, AN H Y, LV Q Y, et al. Image target detection algorithm based on YOLOv7-tiny in complex background[J]. Infrared and Laser Engineering, 2024, 53(1): 20230472(in Chinese). [13] WANG C Y, BOCHKOVSKIY A, LIAO H M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2023: 7464-7475. [14] LIU Y, LI H F, HU C, et al. Learning to aggregate multi-scale context for instance segmentation in remote sensing images[J]. IEEE Transactions on Neural Networks and Learning Systems, 2025, 36(1): 595-609. [15] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 936-944. [16] LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 8759-8768. [17] ZHU P F, WEN L Y, DU D W, et al. Detection and tracking meet drones challenge[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(11): 7380-7399. [18] BELLO I, ZOPH B, LE Q, et al. Attention augmented convolutional networks[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2020: 3285-3294. [19] SRINIVAS A, LIN T Y, PARMAR N, et al. Bottleneck Transformers for visual recognition[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 16514-16524. [20] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: ACM, 2017: 6000-6010. [21] TONG Z J, CHEN Y H, XU Z W, et al. Wise-IoU: bounding box regression loss with dynamic focusing mechanism[EB/OL]. (2023-04-08)[2024-03-01]. https://arxiv.org/abs/2301.10051. [22] TIAN Z, SHEN C H, CHEN H, et al. FCOS: a simple and strong anchor-free object detector[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(4): 1922-1933. [23] BOCHKOVSKIY A, WANG C Y, LIAO H M. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. (2020-04-23)[2024-03-01]. https://arxiv.org/abs/2004.10934. [24] GE Z, LIU S T, WANG F, et al. YOLOX: exceeding YOLO series in 2021[EB/OL]. (2021-08-06)[2024-03-01]. https://arxiv.org/abs/2107.08430. [25] WANG C Y, YEH I H, LIAO H M. YOLOv9: learning what you want to learn using programmable gradient information[EB/OL]. (2024-02-09)[2024-03-01]. https://arxiv.org/abs/2402.13616. [26] CAI Z W, VASCONCELOS N. Cascade R-CNN: delving into high quality object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 6154-6162. [27] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. [28] HUANG X B, LI Q F, SHEN L L, et al. CDNet: cross-frequency dual-branch network for face anti-spoofing[C]//Proceedings of the International Joint Conference on Neural Networks. Piscataway: IEEE Press, 2023: 1-9. [29] 李校林, 刘大东, 刘鑫满, 等. 改进YOLOv5的无人机航拍图像目标检测算法[J]. 计算机工程与应用, 2024, 60(11): 204-214.LI X L, LIU D D, LIU X M, et al. Improved target detection algorithm for UAV aerial image based on YOLOv5[J]. Computer Engineering and Applications, 2024, 60(11): 204-214(in Chinese). [30] 郭业才, 孙京东, AMITAVE S. 基于YOLOv5改进的航拍图像目标检测算法[J]. 系统仿真学报, 2025, 37(2): 551-562.GUO Y C, SUN J D, AMITAVE S. Improved target detection algorithm for aerial images based on YOLOv5[J]. Journal of System Simulation, 2025, 37(2): 551-562(in Chinese). [31] ZHU X K, LYU S C, WANG X, et al. TPH-YOLOv5: improved YOLOv5 based on Transformer prediction head for object detection on drone-captured scenarios[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops. Piscataway: IEEE Press, 2021: 2778-2788. [32] SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization[J]. International Journal of Computer Vision, 2020, 128(2): 336-359. -

 下载:
下载:









 点击查看大图
点击查看大图

计量
- 文章访问数: 374
- HTML全文浏览量: 165
- PDF下载量: 74
- 被引次数: 0
