



-
摘要:
在复杂的跟踪环境中,现有的跟踪器主要面临深度卷积特征冗余和目标跟踪过程正样本缺乏的问题。为去除深度卷积网络中的冗余特征,提出一种基于空间域和通道域融合的注意力机制模型,包括空间自注意力、通道注意力和空间注意力3个连续的子模块;以此为基础,构建一种适用于各种视觉算法的深度卷积网络;设计基于特征修正的提取目标深度卷积特征及特征增强策略,解决冗余特征负反馈及正样本缺乏等问题。实验结果表明:在主流残差网络(ResNet)目标分类任务中,加入特征修正模块可使Top-1和Top-5错误率明显降低,且不会造成额外的计算量或网络结构调整,实现轻量化插入;在多个相关跟踪算法中加入特征修正模块后实现了更加优秀的跟踪性能,并解决了判别器的过拟合问题。
Abstract:In a complex tracking environment, existing trackers mainly face the problems of deep convolutional feature redundancy and a lack of positive samples in the target tracking process. In order to remove redundant features in deep convolutional networks, an attention mechanism model based on the fusion of the spatial domain and channel domain, which includes three continuous sub-modules: spatial self-attention, channel attention and spatial attention. On this basis, a deep convolutional network suitable for various vision algorithms is constructed. A feature enhancement technique based on feature modification is meant to extract target deep convolutional features in order to address the issues of negative feedback of redundant features and lack of positive samples. The experimental results show that in the mainstream residual networks (ResNet) object classification tasks, the addition of the feature modification module can significantly reduce the Top-1 and Top-5 error rates, and will not cause additional calculation or network structure adjustment, achieving lightweight insertion. Several tracking methods are combined with the feature modification module to improve tracking performance and address the discriminator’s over-fitting issue.
-
Key words:
- object tracking /
- attention mechanism /
- feature modification /
- lightweight insertion /
- residual network
-
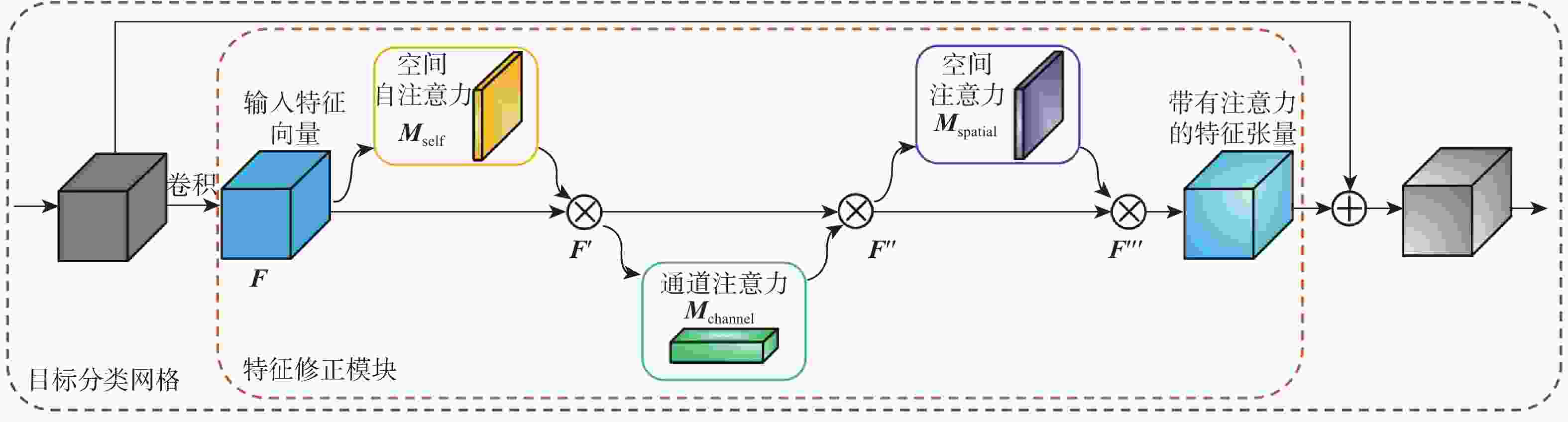
图 1 基于通道域和空间域融合的注意力机制模块整体结构
Figure 1. Overall structure of attention mechanism module based on fusion of channel and spatial domain

图 5 特征张量中有效特征的提取过程
Figure 5. Extraction process of effective features in feature tensor

图 6 ECO跟踪器在3种场景下不同层次卷积特征性能
Figure 6. Different levels of convolutional feature performance of ECO tracker in three scenarios

图 7 基于ECO跟踪器各层次特征增强后性能增益对比
Figure 7. Performance gain comparison based on feature enhancement at each level of ECO tracker

图 8 3种分类网络对目标识别的类激活热力图可视化比较
Figure 8. Visual comparison of class activation heatmaps of three classification networks for object recognition

图 9 OTB100基准上的成功率和精确率
Figure 9. Success rate plot and precision rate plot on the OTB100 benchmark

图 10 4种跟踪算法在OTB100数据集3个视频序列上的定性结果
Figure 10. Qualitative results of four tracking algorithms on three video sequences of OTB100

图 11 在VOT2018基准上修正后的跟踪算法及其基础算法的性能
Figure 11. Performance of corrected tracking algorithms and their baseline counterparts on VOT2018 benchmark

图 12 4种算法在VOT2018数据集3个视频序列上的定性结果
Figure 12. Qualitative results of four algorithms on three video sequences of VOT2018
表 1 基于ResNet的不同网络结构在ImageNet-1K上的分类结果
Table 1. Classification results of different network architectures based on ResNet on ImageNet-1K
网络结构 参数量/MB 浮点运算速度/109 s−1 Top-1 错误率/% Top-5 错误率/% ResNet18 11.69 1.814 29.60 10.55 ResNet18+SE 11.78 1.814 29.41 10.22 ResNet18+CBAM 11.78 1.815 29.27 10.09 ResNet18+空间自注意力 11.74 1.814 29.46 10.34 ResNet18+空间自注意力+通道注意力 11.76 1.814 29.23 10.07 ResNet18+特征修正 11.76 1.814 29.12 9.95 ResNet34 21.08 3.664 26.69 8.60 ResNet34+SE 21.96 3.664 26.13 8.35 ResNet34+CBAM 21.96 3.665 25.99 8.24 ResNet34+空间自注意力 21.95 3.664 26.02 8.50 ResNet34+空间自注意力+通道注意力 21.96 3.664 25.64 8.26 ResNet34+特征修正 21.96 3.664 25.45 8.11 ResNet50 25.56 3.858 24.56 7.50 ResNet50+SE 28.09 3.860 23.14 6.70 ResNet50+CBAM 28.09 3.864 22.66 6.31 ResNet50+空间自注意力 28.08 3.861 23.08 6.75 ResNet50+空间自注意力+通道注意力 28.09 3.862 21.69 6.20 ResNet50+特征修正 28.09 3.862 21.01 6.01 ResNet101 44.55 7.570 23.38 6.88 ResNet101+SE 49.33 7.575 23.35 6.19 ResNet101+CBAM 49.33 7.581 21.51 5.69 ResNet101+空间自注意力 49.32 7.579 22.48 6.24 ResNet101+空间自注意力+通道注意力 49.33 7.579 21.09 5.33 ResNet101+特征修正 49.33 7.579 20.69 5.07  下载: 导出CSV
下载: 导出CSV
表 2 VOT2018视频序列基准上的性能比较
Table 2. Performance comparison on VOT2018 video sequence benchmark
跟踪器 精确率 鲁棒性/次 EAO 帧率/(帧·s−1) ECO-M 0.5080 13.9009 0.3294 32 ECO[13] 0.4978 13.5112 0.3077 25 C-COT-M 0.5378 14.4228 0.3292 27 C-COT[12] 0.5057 15.2288 0.3039 18 DeepSRDCF-M 0.4804 20.9212 0.2541 13 DeepSRDCF[23] 0.5016 23.9644 0.2282 6 Staple-M 0.4985 14.6296 0.2890 34 Staple[30] 0.5405 19.8836 0.2733 28 DSST-M 0.4721 30.1225 0.1780 25 DSST[40] 0.4005 63.0723 0.0976 20
下载: 导出CSV
-
[1] ZHANG Y F, SUN P Z, JIANG Y, et al. ByteTrack: multi-object tracking by associating every detection box[C]//Proceedings of the Computer Vision-ECCV. Berlin: Springer, 2022: 1-21. [2] 黄煜杰, 陈凯, 王子源, 等. 多目视觉下基于融合特征的密集行人跟踪方法[J]. 北京航空航天大学学报, 2025, 51(7): 2513-2525.HUANG Y J, CHEN K, WANG Z Y, et al. A dense pedestrian tracking method based on fusion features under multi-vision[J]. Journal of Beijing University of Aeronautics and Astronautics, 2025, 51(7): 2513-2525(in Chinese). [3] STADLER D, BEYERER J. Improving multiple pedestrian tracking by track management and occlusion handling[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 10953-10962. [4] CHEN K, ZHU H H, TANG D B, et al. Future pedestrian location prediction in first-person videos for autonomous vehicles and social robots[J]. Image and Vision Computing, 2023, 134: 104671. [5] CHEN K, SONG X, YUAN H T, et al. Fully convolutional encoder-decoder with an attention mechanism for practical pedestrian trajectory prediction[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23(11): 20046-20060. [6] BERTINETTO L, VALMADRE J, HENRIQUES J F, et al. Fully-convolutional Siamese networks for object tracking[C]//Proceedings of the Computer Vision-ECCV Workshops. Berlin: Springer, 2016: 850-865. [7] WANG Q, GAO J, XING J L, et al. DCFNet: discriminant correlation filters network for visual tracking[EB/OL]. (2017-04-13)[2024-02-01]. https://arxiv.org/abs/1704.04057. [8] REAL E, SHLENS J, MAZZOCCHI S, et al. YouTube-boundingboxes: a large high-precision human-annotated data set for object detection in video[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 7464-7473. [9] RUSSAKOVSKY O, DENG J, SU H, et al. ImageNet large scale visual recognition challenge[J]. International Journal of Computer Vision, 2015, 115(3): 211-252. [10] ZHANG L, WANG Y J, SUN H H, et al. Robust visual correlation tracking[J]. Mathematical Problems in Engineering, 2015, 2015: 238971. [11] LUQUE-BAENA R M, ORTIZ-DE-LAZCANO-LOBATO J M, LÓPEZ-RUBIO E, et al. A competitive neural network for multiple object tracking in video sequence analysis[J]. Neural Processing Letters, 2013, 37(1): 47-67. [12] DANELLJAN M, ROBINSON A, SHAHBAZ KHAN F, et al. Beyond correlation filters: learning continuous convolution operators for visual tracking[C]//Proceedings of the Computer Vision-ECCV. Berlin: Springer, 2016: 472-488. [13] DANELLJAN M, BHAT G, KHAN F S, et al. ECO: efficient convolution operators for tracking[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 6931-6939. [14] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 770-778. [15] LI H X, LI Y, PORIKLI F. DeepTrack: learning discriminative feature representations online for robust visual tracking[J]. IEEE Transactions on Image Processing, 2016, 25(4): 1834-1848. [16] NAM H, HAN B. Learning multi-domain convolutional neural networks for visual tracking[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 4293-4302. [17] LI B, YAN J J, WU W, et al. High performance visual tracking with Siamese Region proposal network[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 8971-8980. [18] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[EB/OL]. (2015-04-10)[2024-02-01]. https://arxiv.org/abs/1409.1556. [19] LI Y H, ZHANG X F, CHEN D M. SiamVGG: visual tracking using deeper Siamese networks[EB/OL]. (2022-07-04)[2024-02-01]. https://arxiv.org/abs/1902.02804. [20] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[J]. communications of the ACM, 2017, 60(6): 84-90. [21] BOLME D S, BEVERIDGE J R, DRAPER B A, et al. Visual object tracking using adaptive correlation filters[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2010: 2544-2550. [22] DANELLJAN M, HÄGER G, KHAN F S, et al. Learning spatially regularized correlation filters for visual tracking[C]// Proceedings of the IEEE International Conference on Computer Vision.Piscataway: IEEE Press, 2016: 4310-4318. [23] DANELLJAN M, HÄGER G, KHAN F S, et al. Convolutional features for correlation filter based visual tracking[C]//Proceedings of the IEEE International Conference on Computer Vision Workshop. Piscataway: IEEE Press, 2016: 621-629. [24] HE Z Q, FAN Y R, ZHUANG J F, et al. Correlation filters with weighted convolution responses[C]//Proceedings of the IEEE International Conference on Computer Vision Workshops. Piscataway: IEEE Press, 2018: 1992-2000. [25] YU E, LI Z L, HAN S D, et al. RelationTrack: relation-aware multiple object tracking with decoupled representation[J]. IEEE Transactions on Multimedia, 2023, 25: 2686-2697. [26] ZENG F G, DONG B, ZHANG Y A, et al. MOTR: end-to-end multiple-object tracking withTransformer[C]//Proceedings of the Computer Vision-ECCV. Berlin: Springer, 2022: 659-675. [27] ZEILER M D, FERGUS R. Visualizing and understanding convolutional networks[C]//Proceedings of the Computer Vision-ECCV. Berlin: Springer, 2014: 818-833. [28] ZHOU B L, KHOSLA A, LAPEDRIZA A, et al. Learning deep features for discriminative localization[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 2921-2929. [29] LI H, LIN Z C. Accelerated proximal gradient methods for nonconvex programming[C]//Proceedings of the 29th International Conference on Neural Information Processing Systems-Volume 1. New York: ACM, 2015: 379-387. [30] BERTINETTO L, VALMADRE J, GOLODETZ S, et al. Staple: complementary learners for real-time tracking[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 1401-1409. [31] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 7132-7141. [32] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]//Proceedings of the Computer Vision-ECCV 2018. Berlin: Springer, 2018: 3-19. [33] SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization[J].International Journal of Computer Vision, 2020, 128(2): 336-359. [34] WU Y, LIM J, YANG M H. Object tracking benchmark[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1834-1848. [35] KRISTAN M, LEONARDIS A, MATAS J, et al. The visual object tracking VOT2016 challenge results[C]//Proceedings of the Computer Vision-ECCV Workshops. Berlin: Springer, 2016: 777-823. [36] KRISTAN M, LEONARDIS A, MATAS J, et al. The visual object tracking VOT2017 challenge results[C]//Proceedings of the IEEE International Conference on Computer Vision Workshops.Piscataway: IEEE Press, 2018: 1949-1972. [37] KRISTAN M, LEONARDIS A, MATAS J, et al. The sixth visual object tracking VOT2018 challenge results[C]// Proceedings of the Computer Vision-ECCV Workshops. Berlin: Springer, 2019: 3-53. [38] KRISTAN M, MATAS J, LEONARDIS A, et al. The seventh visual object tracking VOT2019 challenge results[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision Workshop. Piscataway: IEEE Press, 2020: 2206-2241. [39] MUELLER M, SMITH N, GHANEM B. A benchmark and simulator for UAV tracking[C]//Proceedings of the Computer Vision-ECCV. Berlin: Springer, 2016: 445-461. [40] CHEN Y T, WANG J, XIA R L, et al. The visual object tracking algorithm research based on adaptive combination kernel[J]. Journal of Ambient Intelligence and Humanized Computing, 2019, 10(12): 4855-4867. -

 下载:
下载:












 点击查看大图
点击查看大图

计量
- 文章访问数: 254
- HTML全文浏览量: 112
- PDF下载量: 38
- 被引次数: 0
