



-
摘要:
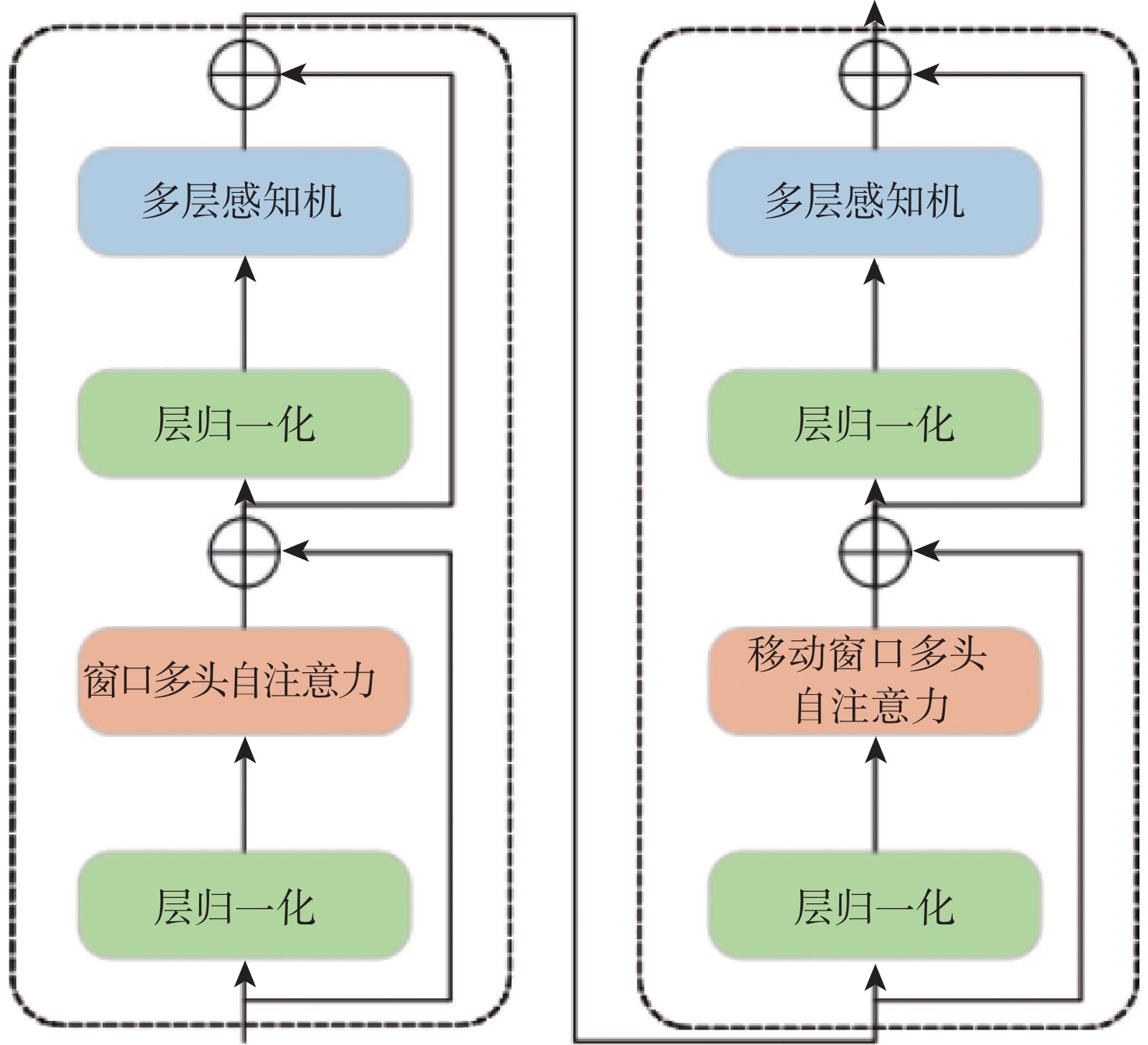
针对Swin Transformer模型在资源受限环境下的部署与执行挑战,采用自适应轮询式剪枝和搜索型无偏移量化技术,以降低模型复杂度和存储需求,同时保持模型准确度。通过自适应轮询式剪枝技术动态去除不重要的权重,减少模型的存储与计算需求。引入搜索型无偏移量化方法,优化权重与激活值的存储,进一步降低模型大小,同时尽量避免精度损失。提出了一种专为Swin Transformer模型优化的加速架构,通过硬件级别的优化提高数据处理速度和效率。实验结果显示:在应用剪枝和量化技术后,模型大小被压缩至原始的14.4%,且在ImageNet-1K数据集上的Top-1准确率达到77.4%。
-
关键词:
- 现场可编程逻辑门阵列 /
- 神经网络 /
- 模型剪枝 /
- 模型量化 /
- 硬件加速器
Abstract:This study used adaptive iterative pruning and search-based bias-free quantization approaches to minimize model complexity and storage requirements while preserving accuracy in response to the deployment and execution problems of Swin Transformer models in resource-constrained situations. Initially, Adaptive iterative pruning dynamically eliminated non-essential weights, reducing storage and computational demands. Subsequently, Search-based bias-Free quantization optimized the storage of weights and activation values, further minimizing model size with minimal accuracy loss. In terms of hardware design, an accelerator architecture tailored for Swin Transformer models was put out, improving data processing efficiency and speed via hardware-level adjustments. Experimental results indicated that after applying pruning and quantization, the model's size reduced to 14.4% of its original, achieving a Top-1 accuracy of 77.4% on the ImageNet-1K dataset.
-
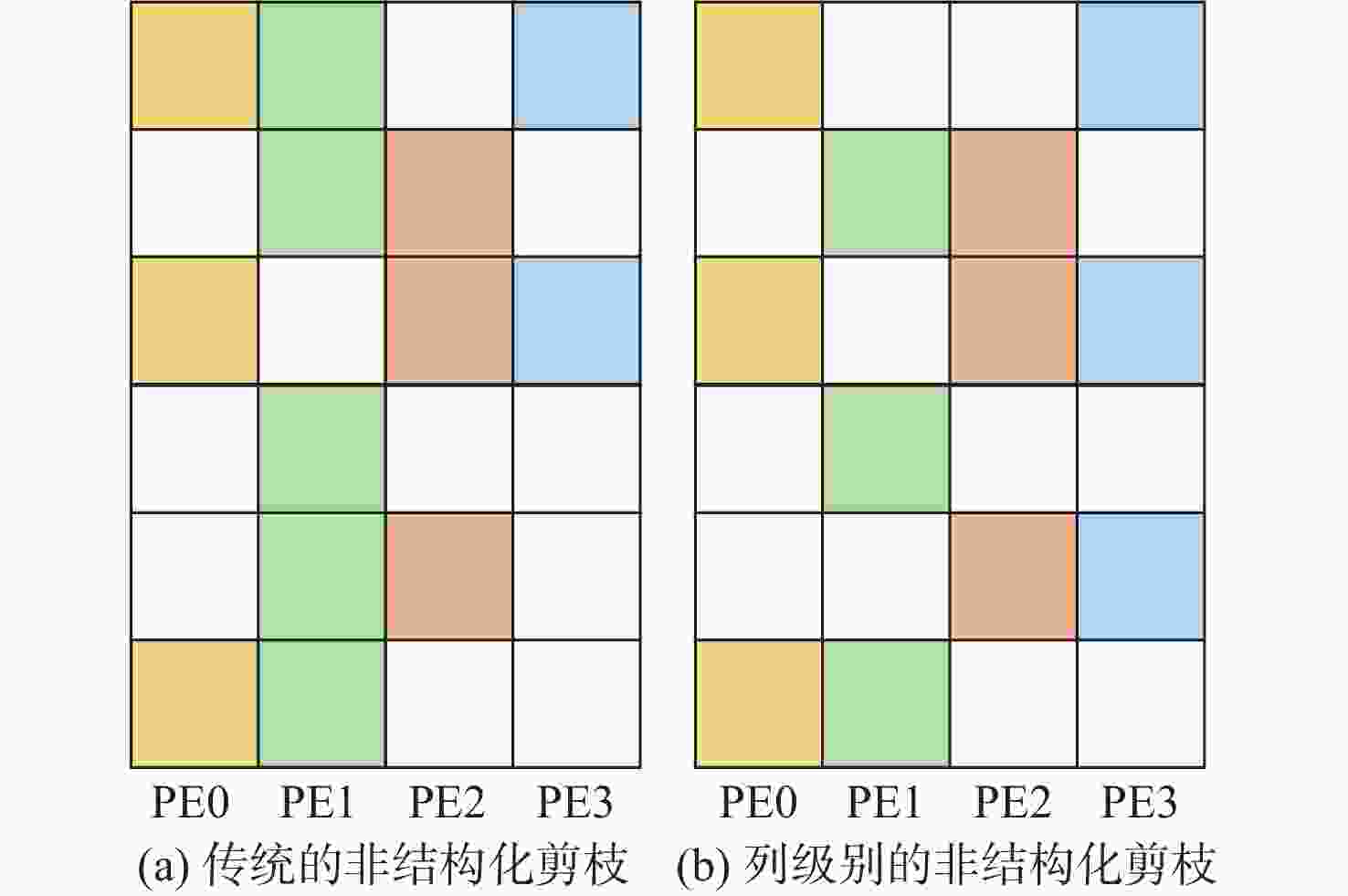
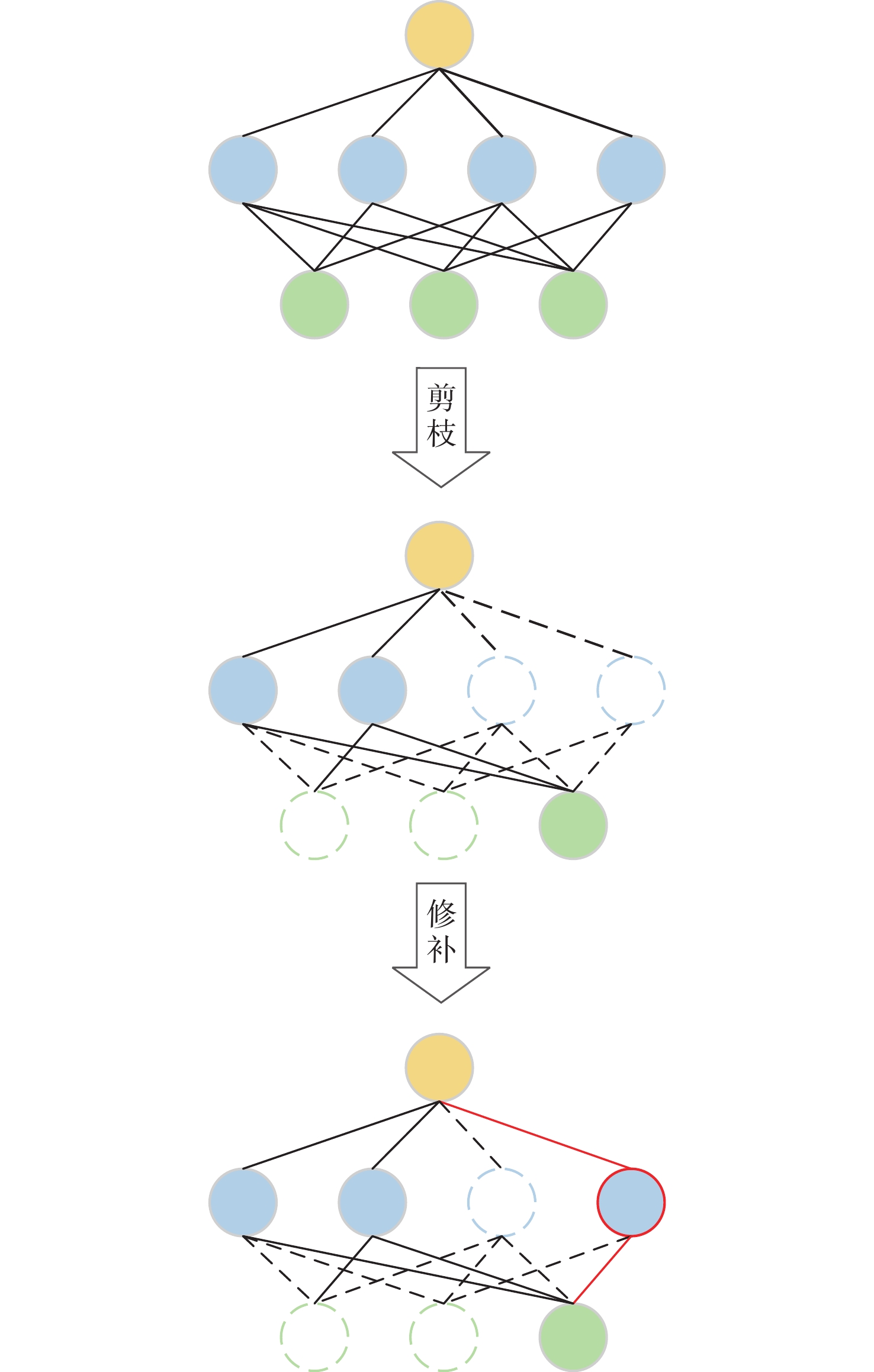
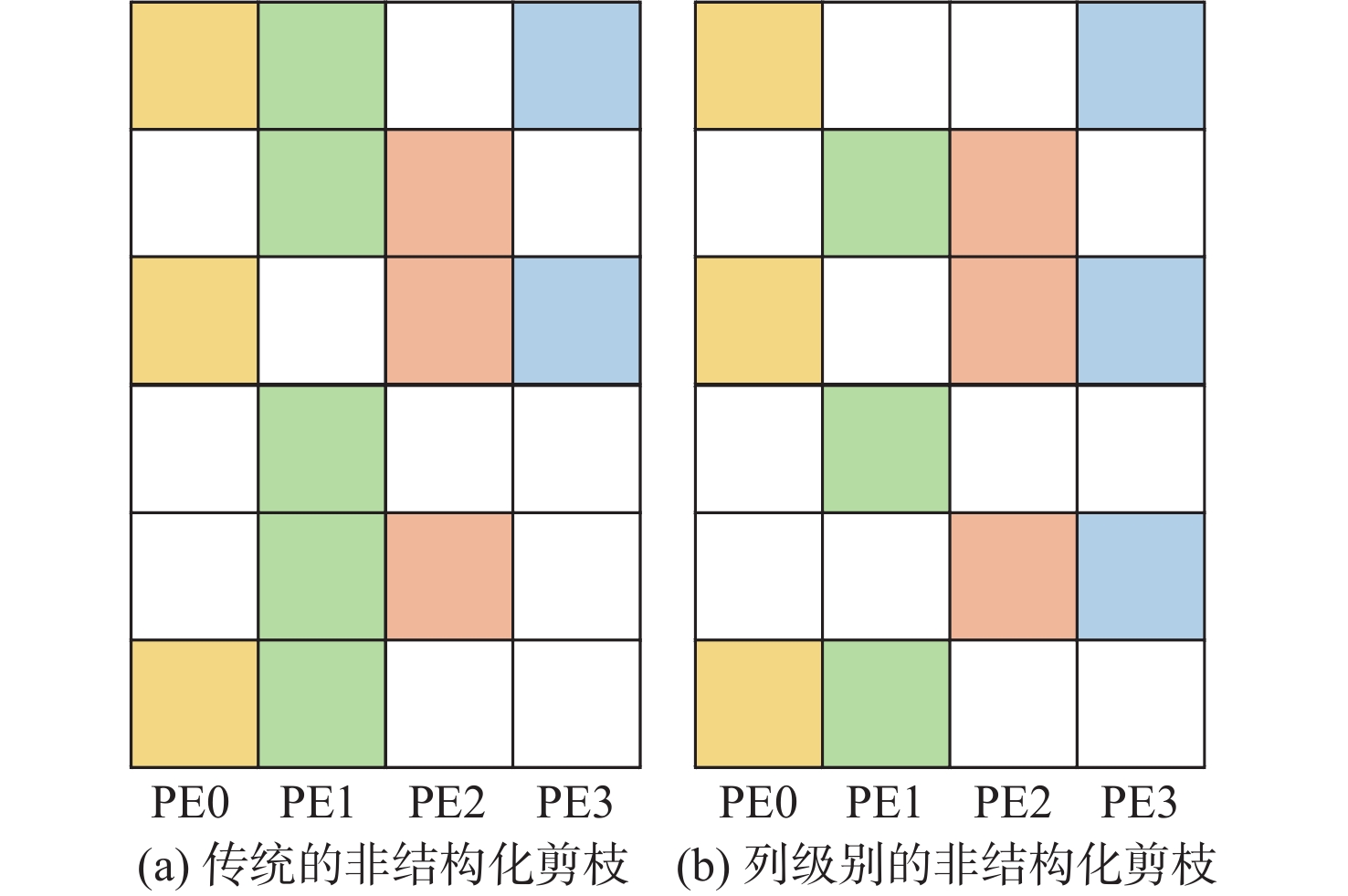
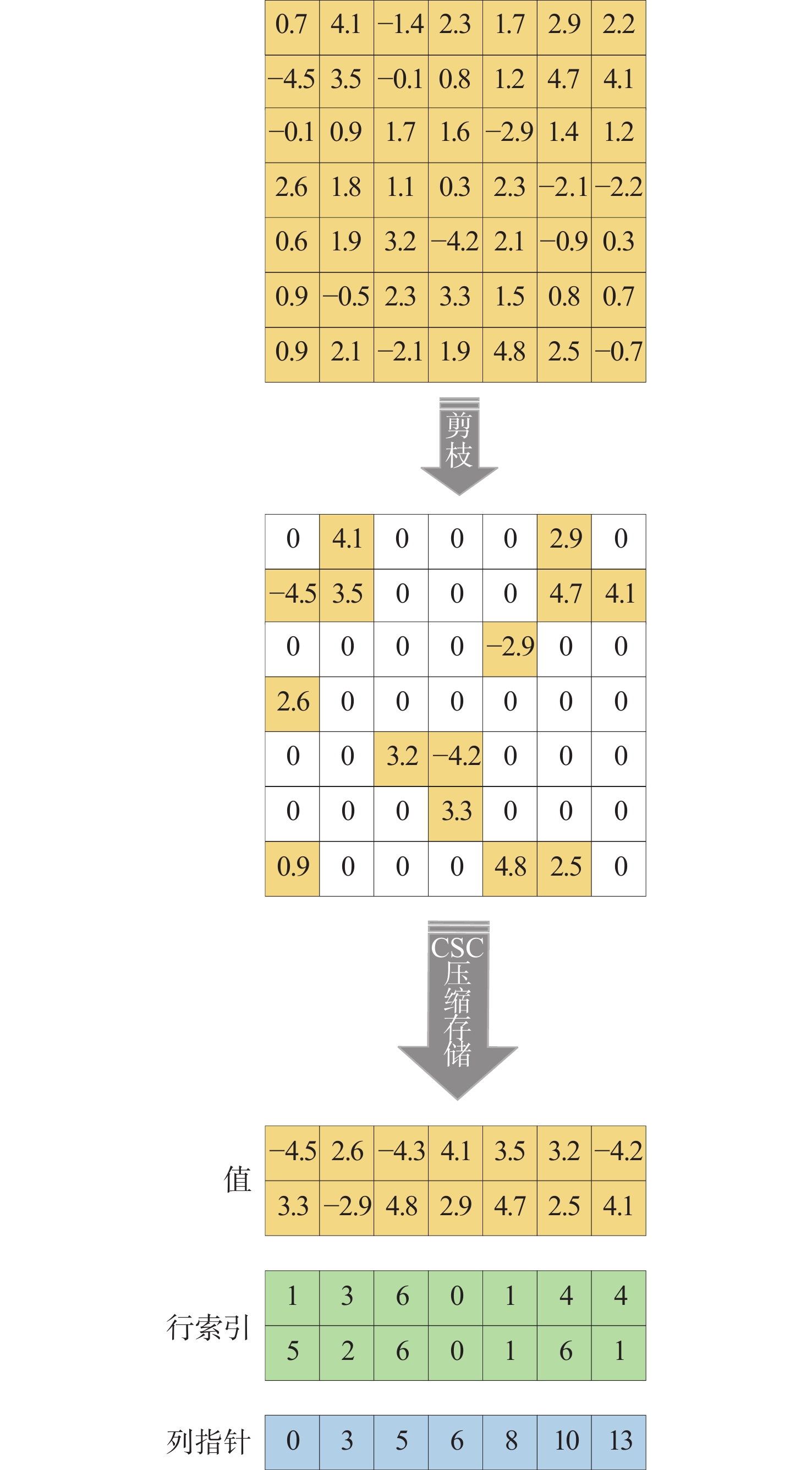
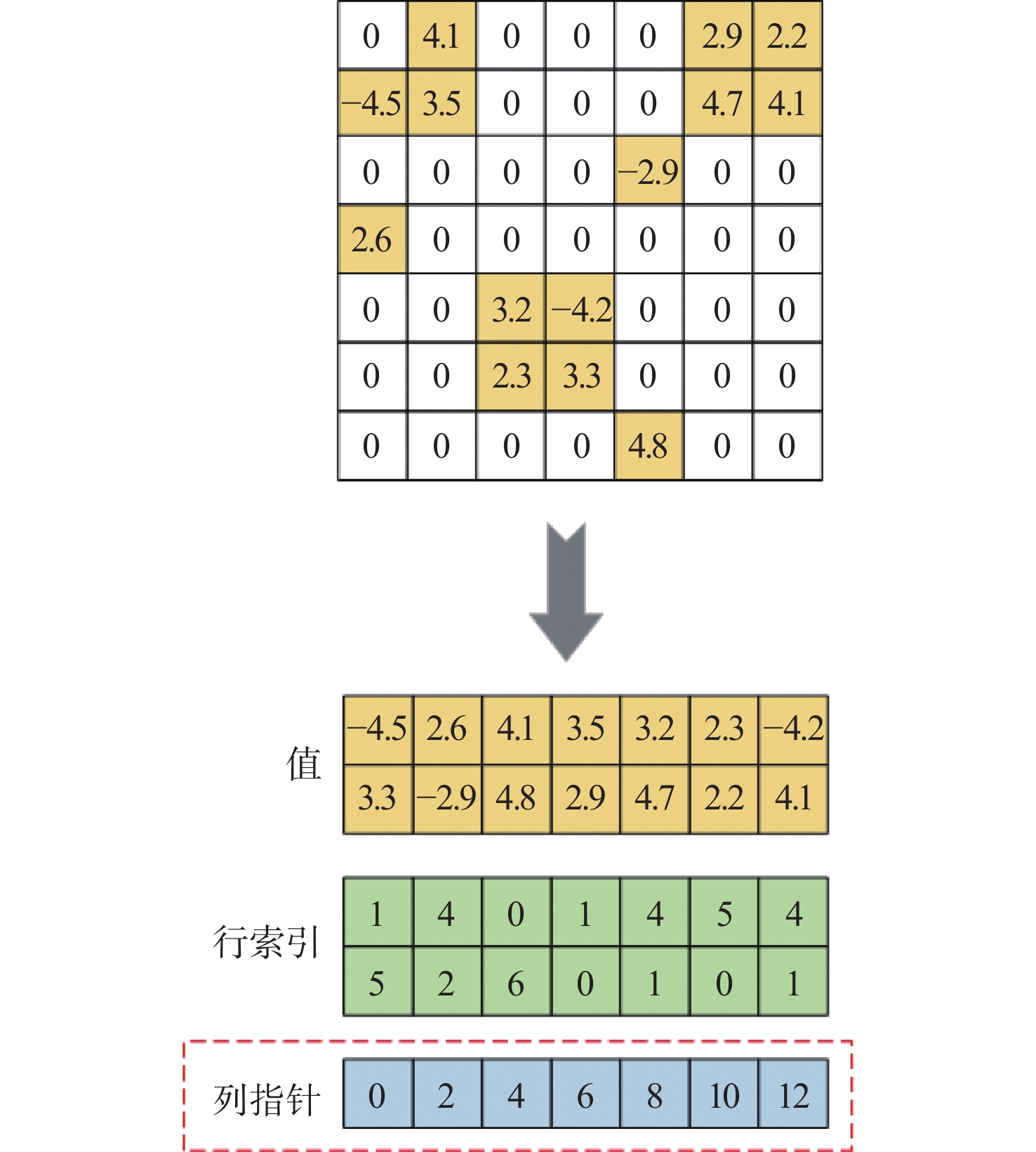
图 4 50%稀疏度下2种剪枝方法的工作负载均衡效果比较
Figure 4. Comparison of workload balancing effects of two pruning methods at 50% sparsity
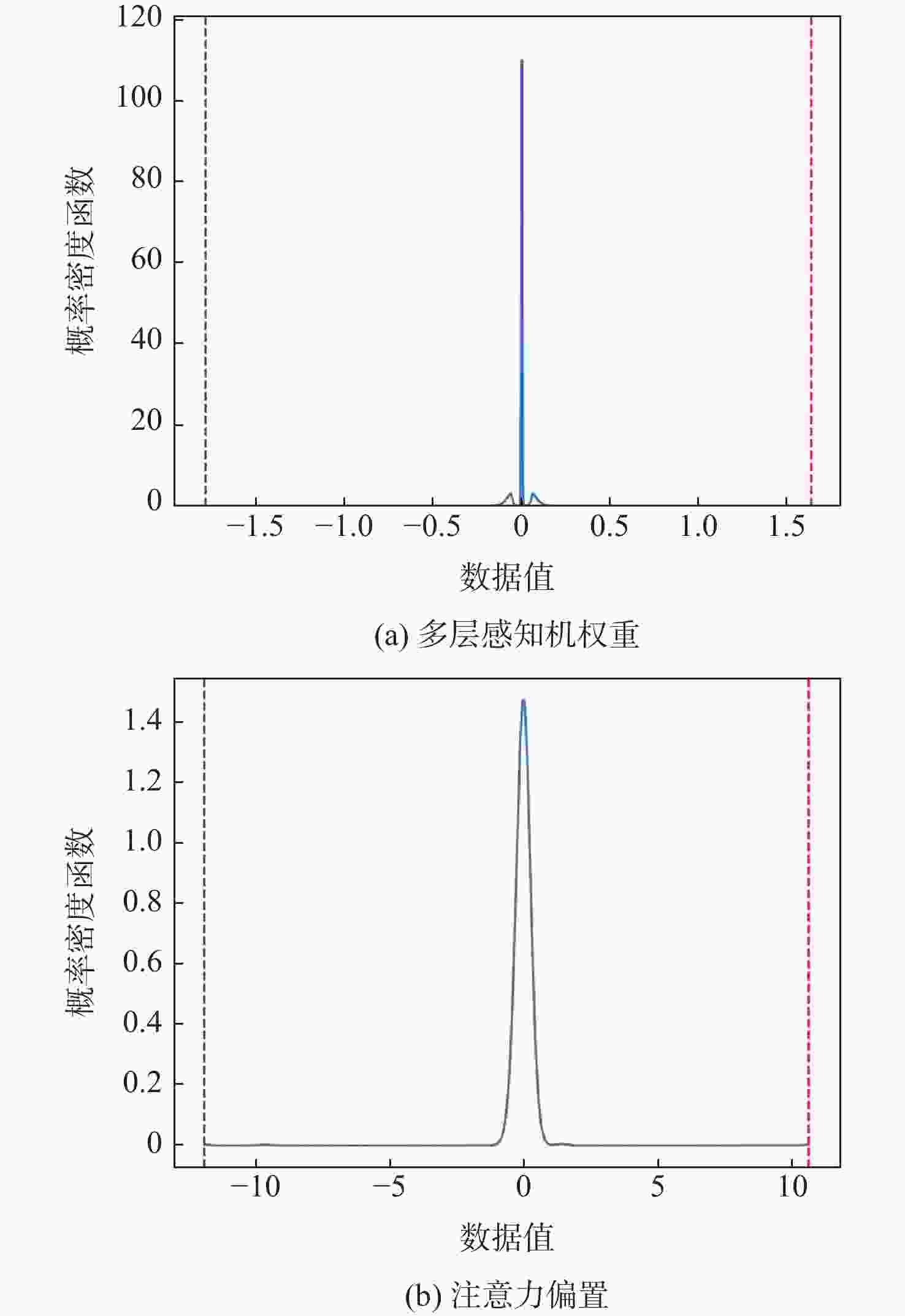
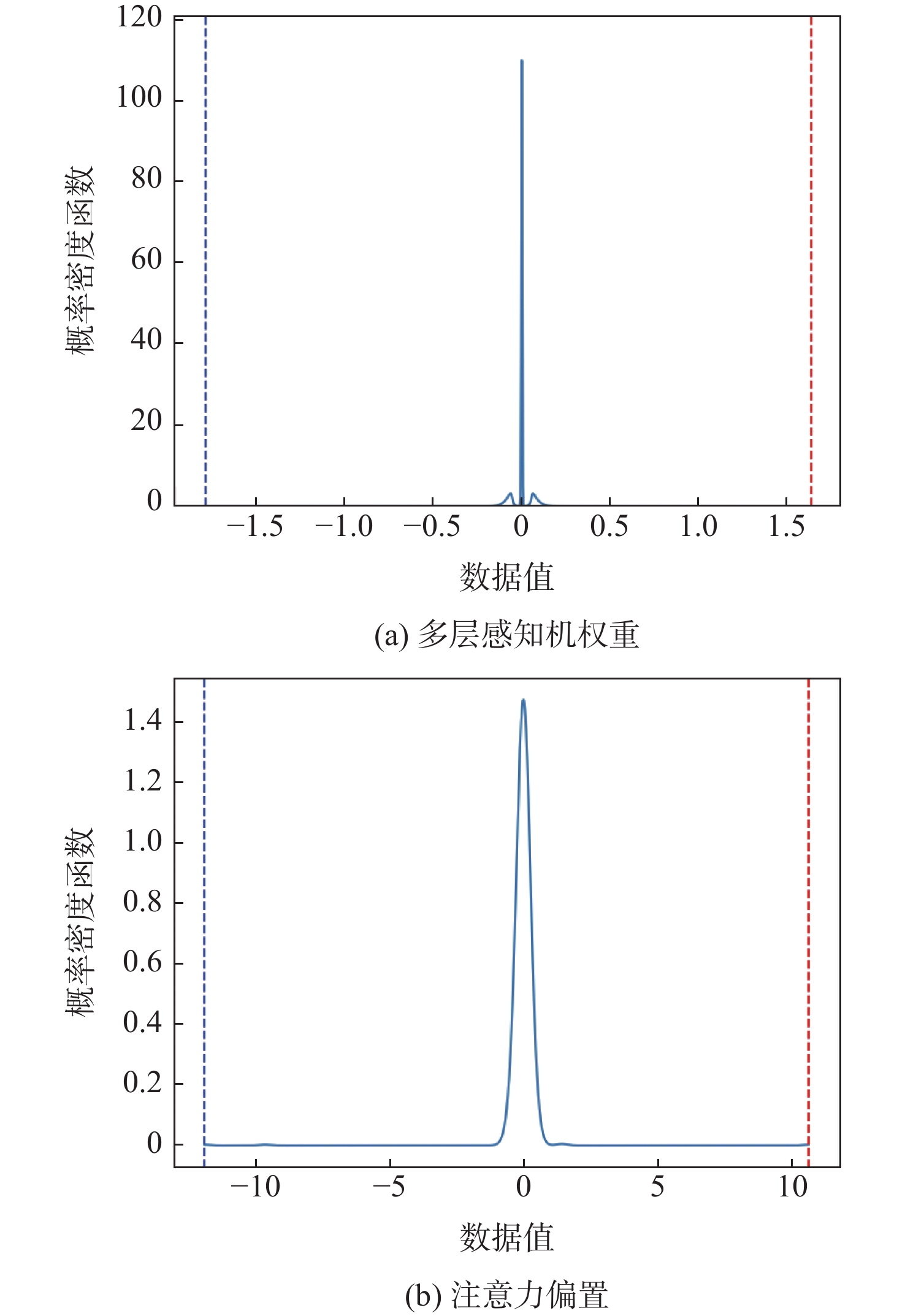
图 7 Swin Transformer量化前参数分布
Figure 7. Distribution of parameters before quantization of Swin Transformer
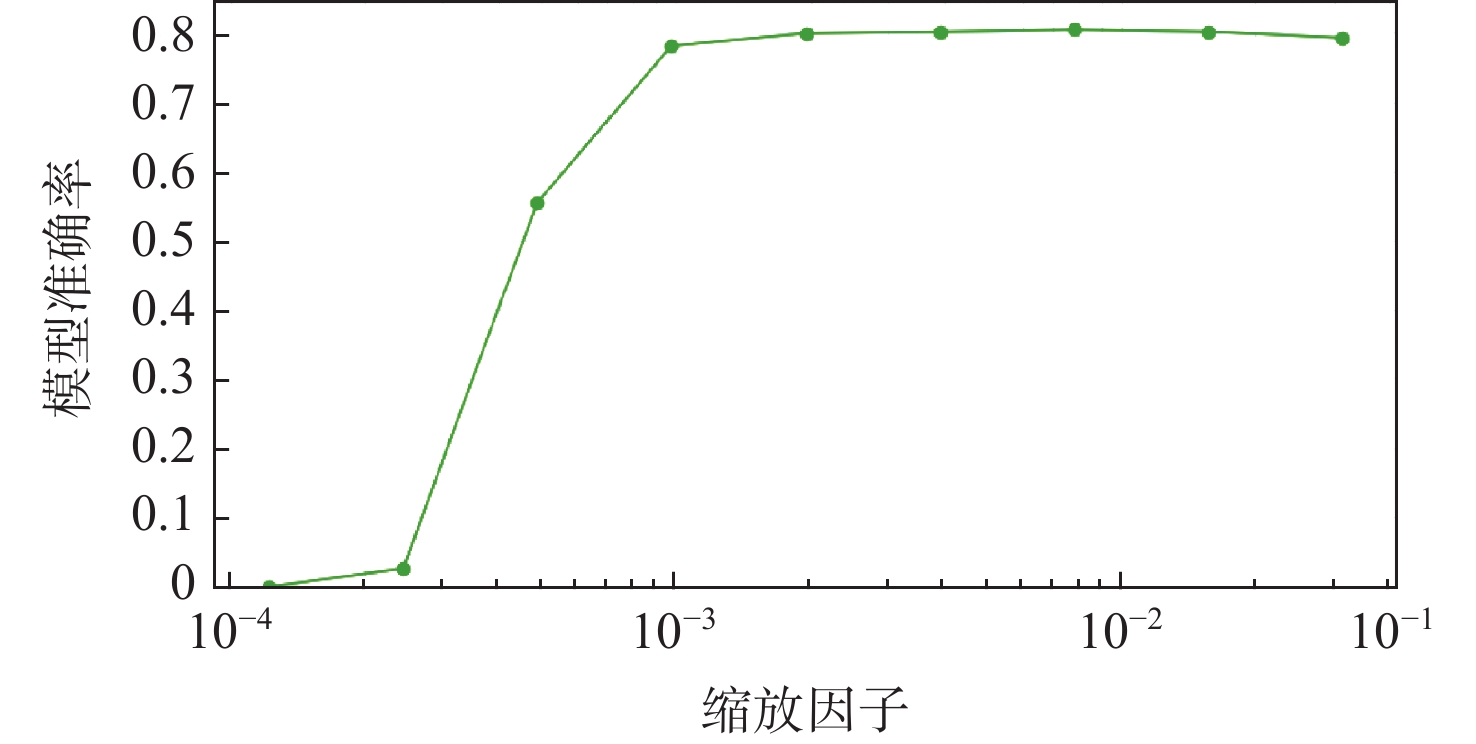
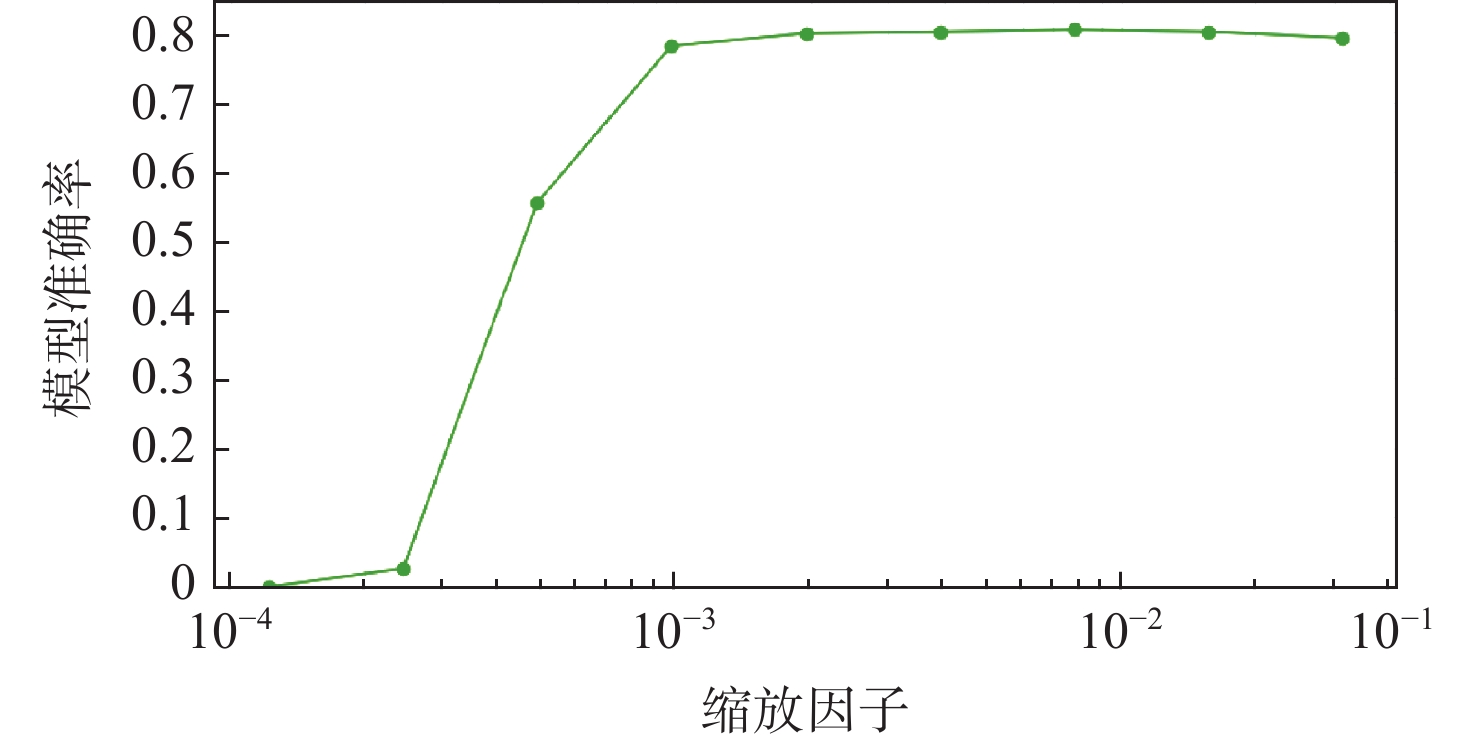
图 8 模型准确度与多层感知机权重的缩放因子的关系
Figure 8. Relationship between model accuracy and scaling factors of multilayer perceptron weights
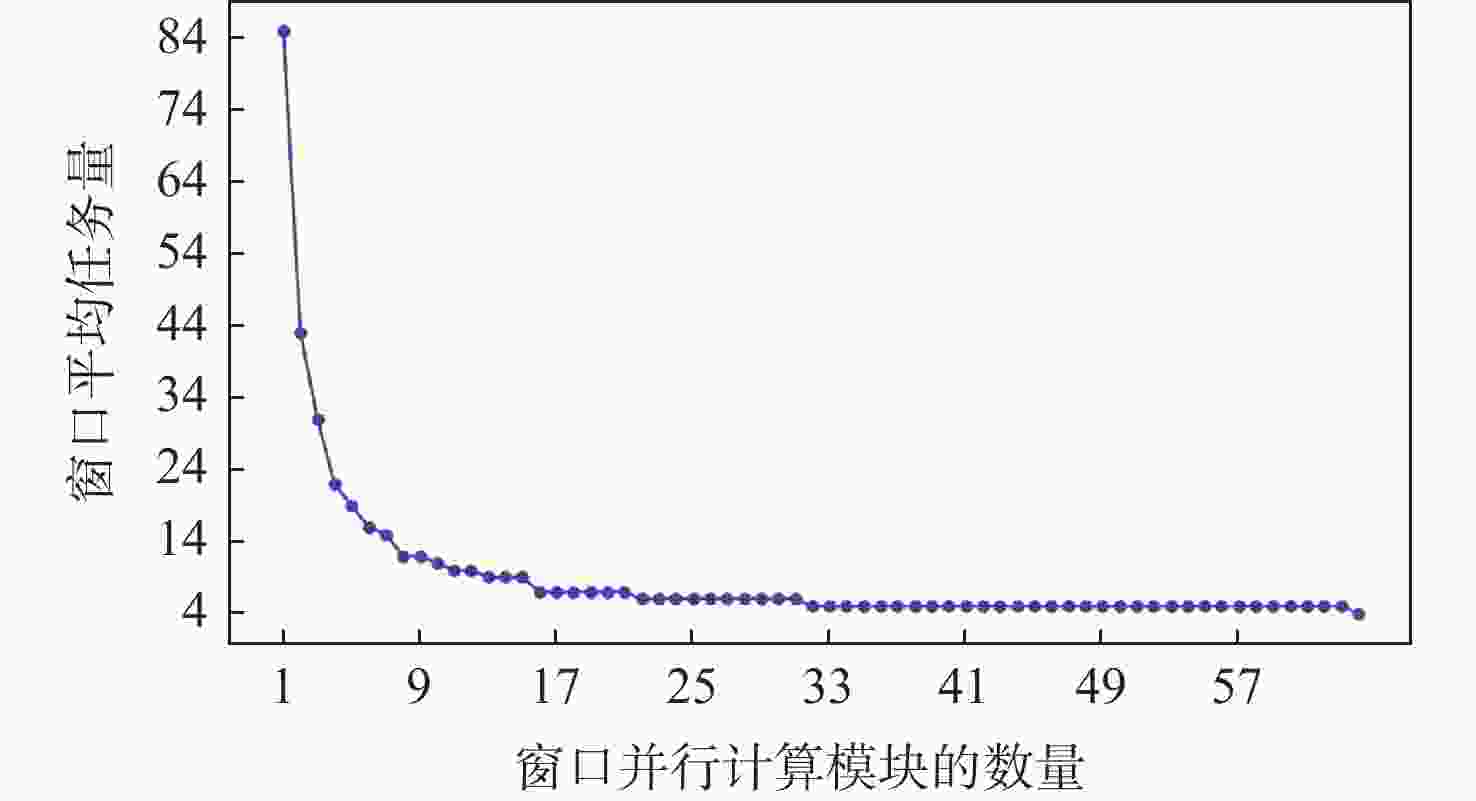
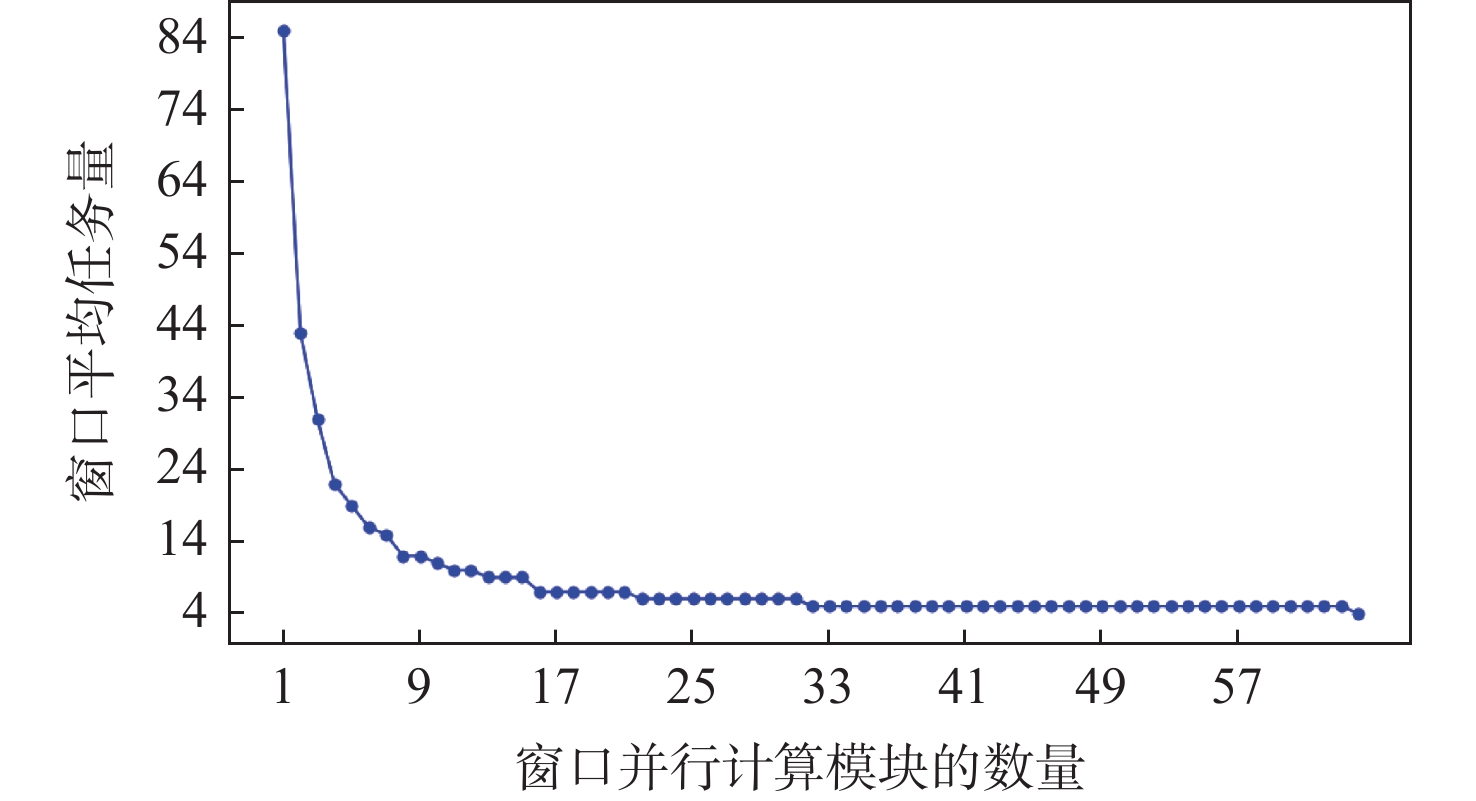
图 10 窗口并行计算资源优化策略的性能分析
Figure 10. Performance analysis of window parallel computation resource optimization strategy
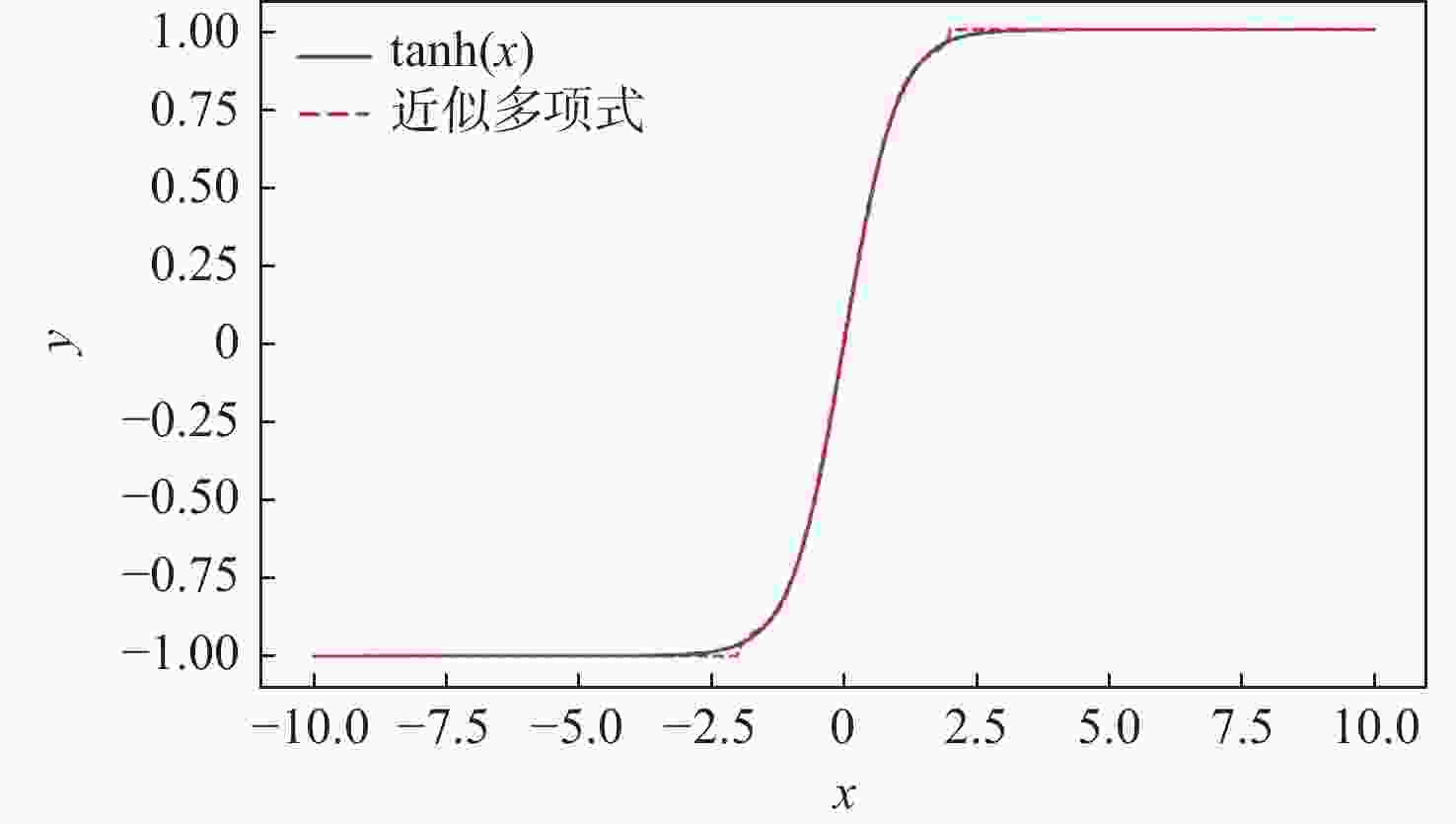
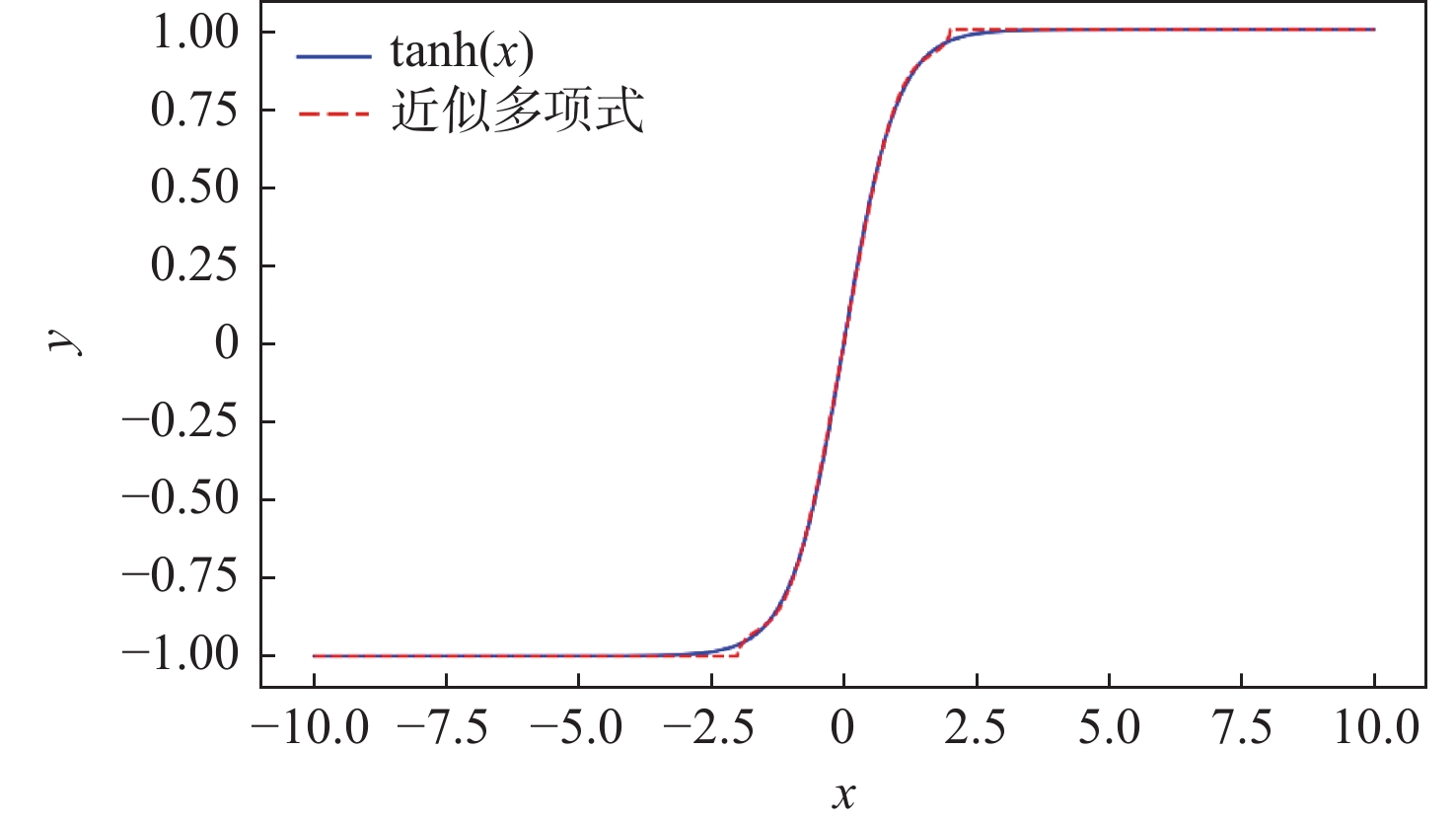
图 12 tanh函数与近似五阶多项式的对比
Figure 12. Comparison of the tanh function with an approximate fifth-order polynomial
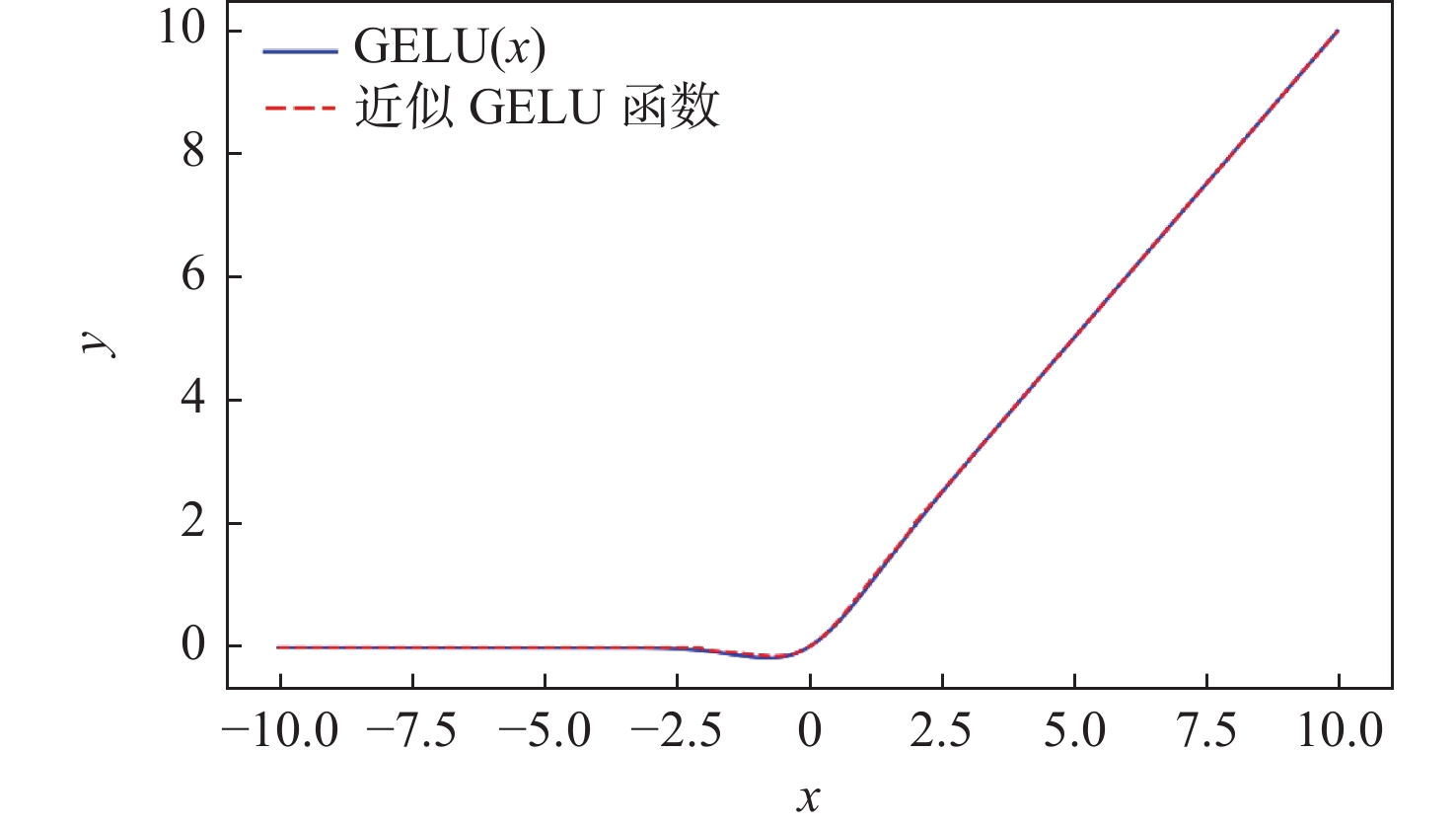
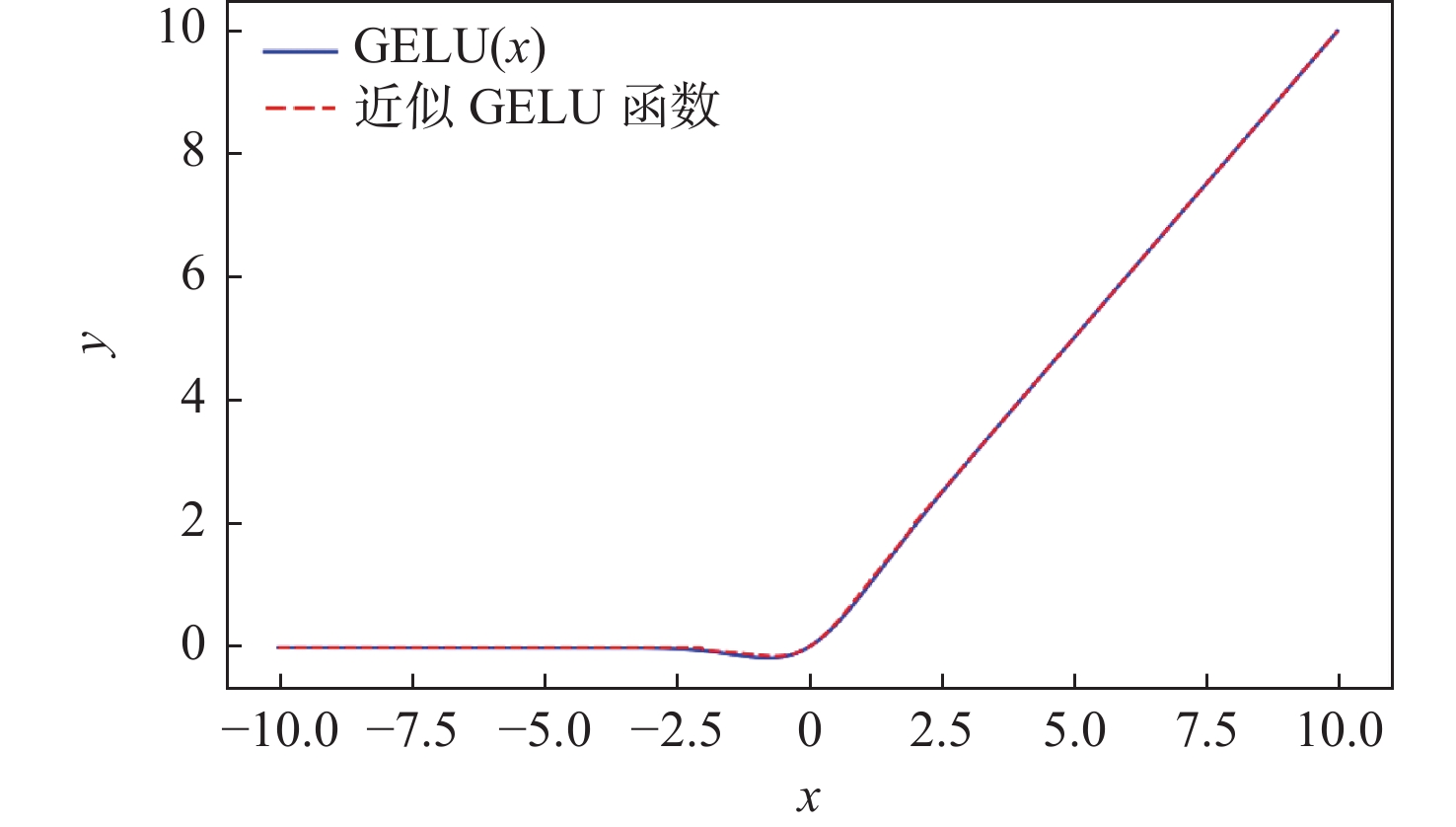
图 13 tanh函数替换前后GELU函数的对比
Figure 13. Comparison of the GELU function before and after replacement with the tanh function
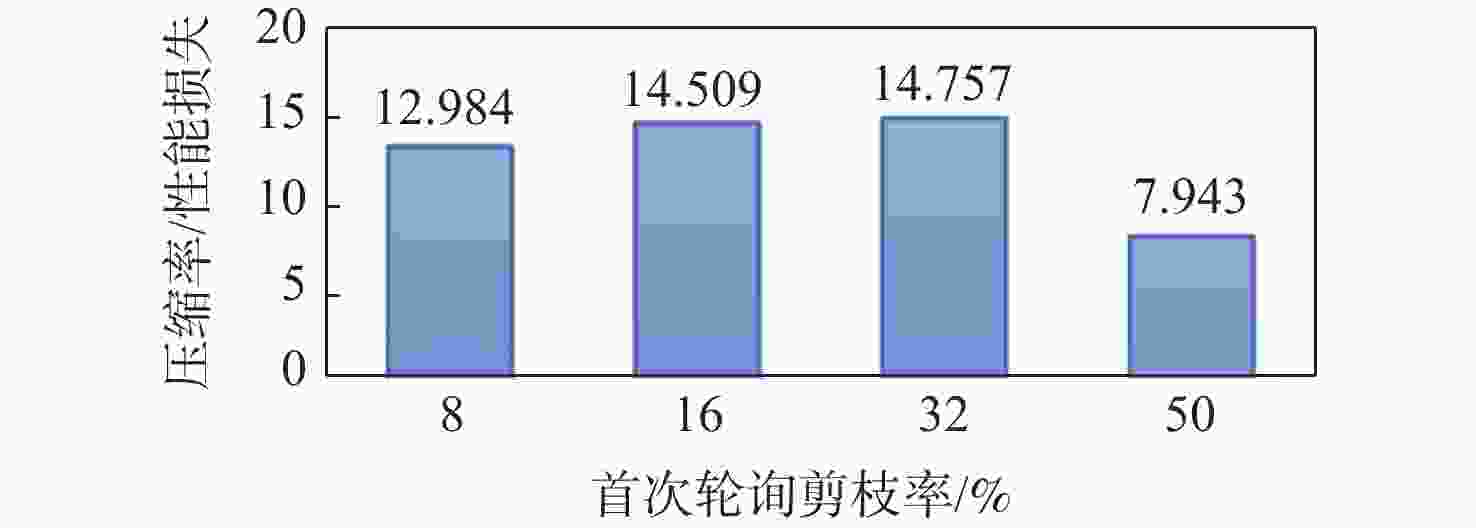
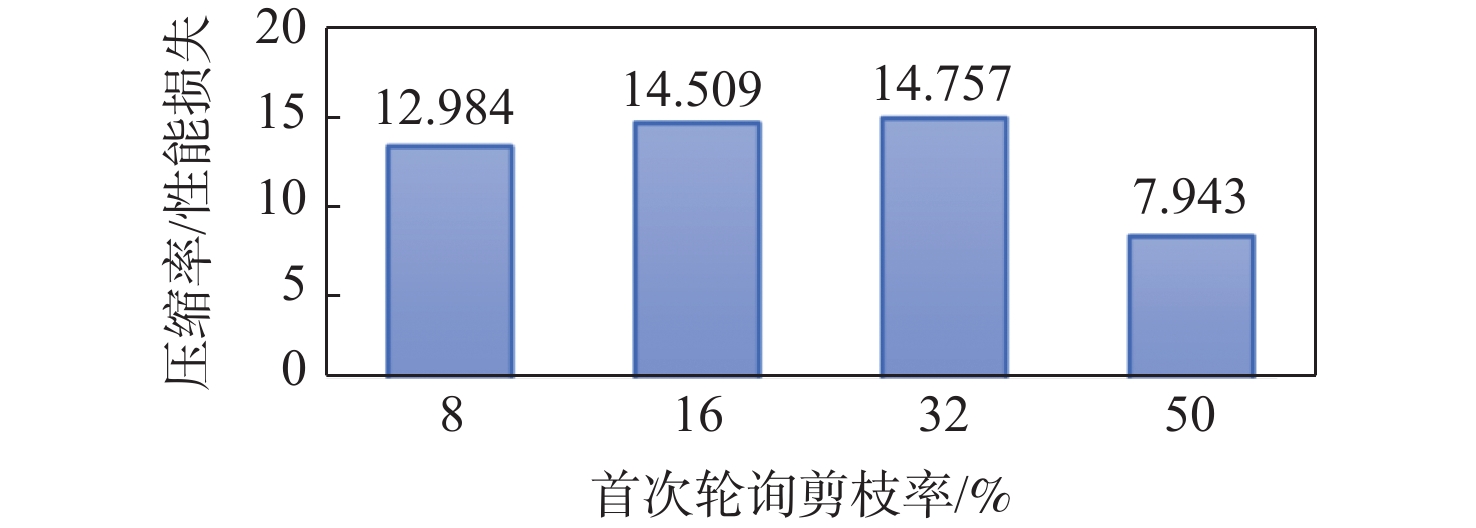
图 14 剪枝效果随首次轮询剪枝率的变化
Figure 14. Comparison of pruning effectiveness with changes in the initial polling pruning rate
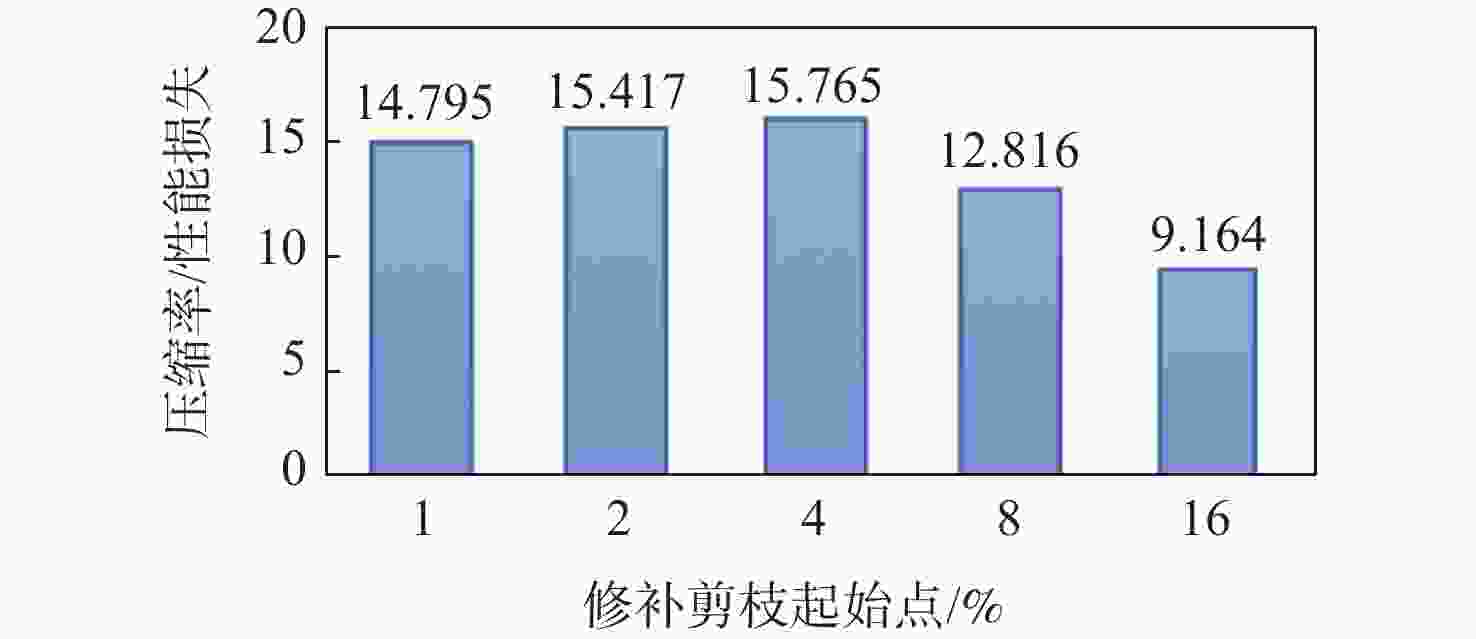
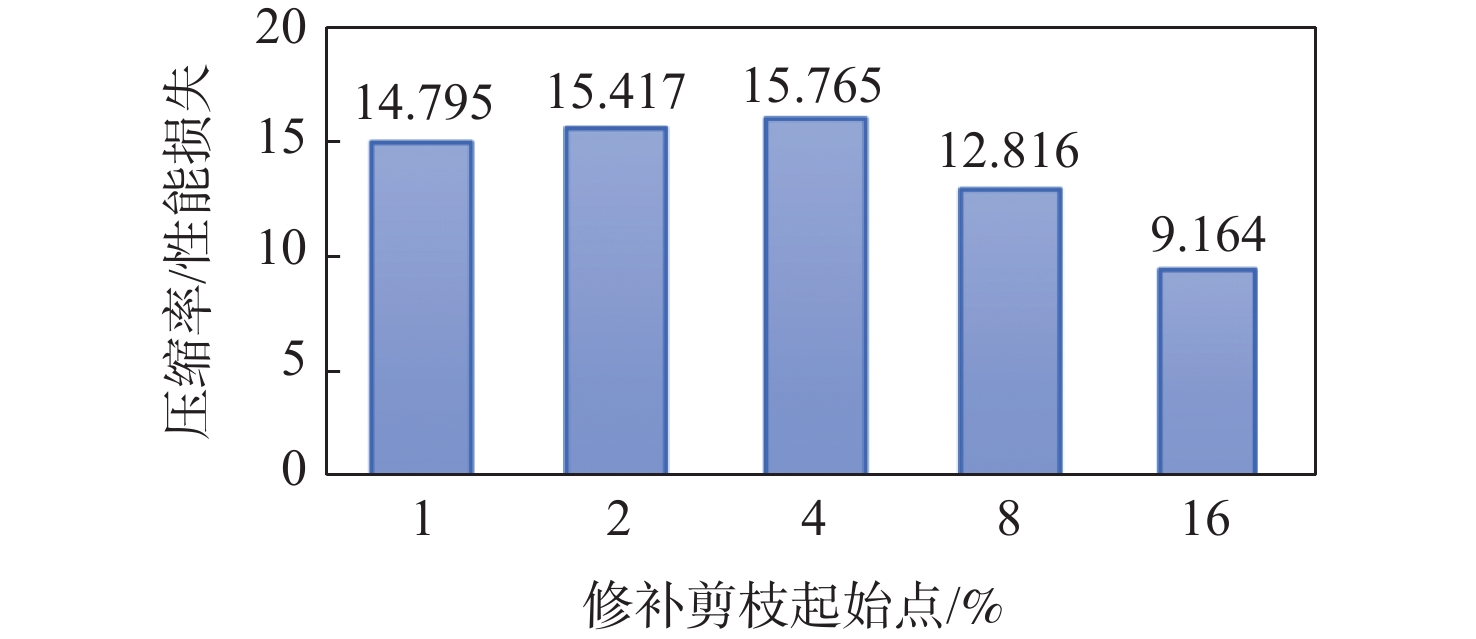
图 15 剪枝效果随修补剪枝率起始点的变化
Figure 15. Comparison of pruning effectiveness with the starting point of repair pruning rate
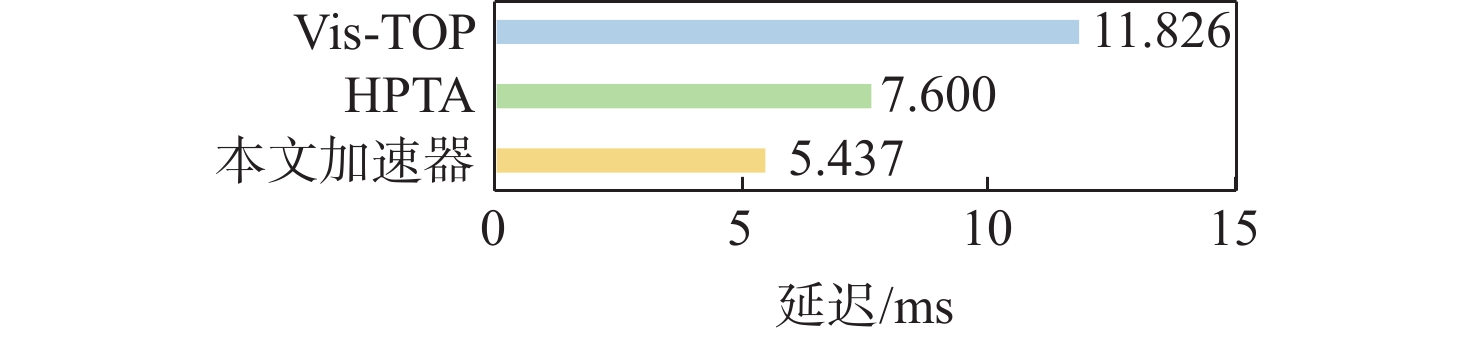
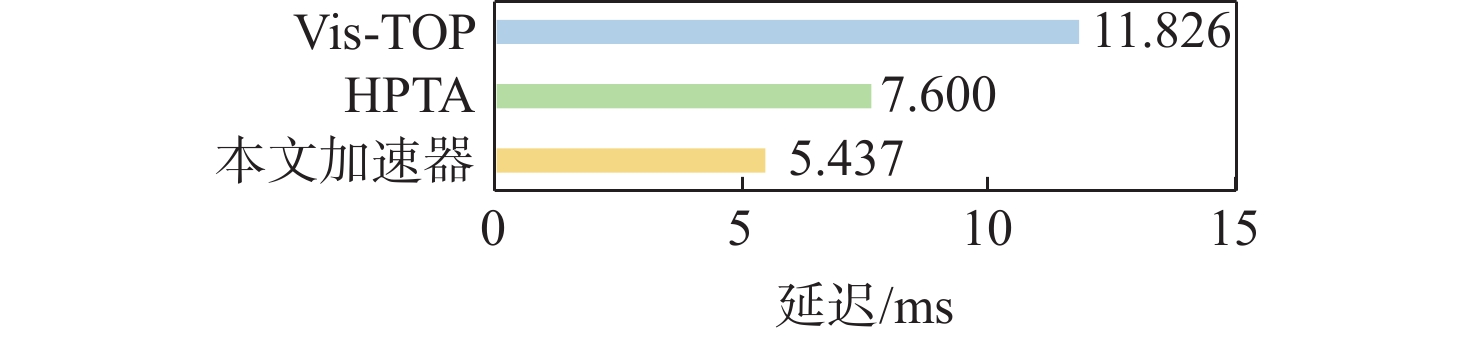
图 16 与已有相关FPGA加速器的推理延迟对比
Figure 16. Comparison of inference latency with existing FPGA accelerators
表 1 不同容忍阈值对模型剪枝效果的影响
Table 1. Impact of different tolerance thresholds on model pruning effectiveness
容忍阈值/% 压缩率/% 准确率损失/% 5 54.920 5.672 2 43.802 2.572 1 28.877 1.502  下载: 导出CSV
下载: 导出CSV
表 2 不同量化方法推理准确率对比
Table 2. Comparison of inference accuracy for different quantization methods
剪枝后量化方法 模型大小/MB 准确率/% 量化损失/% 未量化 62.4 78.34 有偏移量化 15.6 72.22 6.120 最大值截断的无偏移量化 15.6 75.68 2.660 搜索型无偏移量化 15.6 77.42 0.924
下载: 导出CSV
表 3 加速器资源消耗、功耗及性能评估
Table 3. Accelerator resource consumption, power consumption and performance evaluation
延迟/ms BRAM/块 DSP/个 LUT/个 FF/个 URAM/块 功耗/W 5.437 1402 3267 508787 682198 33 41
下载: 导出CSV
-
[1] ZHANG B W, GU S Y, ZHANG B, et al. StyleSwin: transformer-based GAN for high-resolution image generation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2022: 11294-11304. [2] NGUYEN L X, TUN Y L, TUN Y K, et al. Swin transformer-based dynamic semantic communication for multi-user with different computing capacity[J]. IEEE Transactions on Vehicular Technology, 2024, 73(6): 8957-8972. [3] WU H N, CHEN C F, LIAO L, et al. DisCoVQA: temporal distortion-content transformers for video quality assessment[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2023, 33(9): 4840-4854. [4] LIU Z, NING J, CAO Y, et al. Video swin transformer[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2022: 3192-3201. [5] ZHAO H, ZHANG C, ZHU B L, et al. S3T: self-supervised pre-training with swin transformer for music classification[C]//Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE Press, 2022: 606-610. [6] LIU Z, LIN Y T, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2022: 9992-10002. [7] LIN X F, KIM S, JOO J. FairGRAPE: fairness-aware GRAdient pruning mEthod forFace attribute classification[C]//Proceedings of the Computer Vision-ECCV 2022. Berlin: Springer, 2022: 414-432. [8] BLALOCK D, ORTIZ J J G, FRANKLE J, et al. What is the state of neural network pruning? [EB/OL]. (2020-03-06)[2024-02-16]. https://arxiv.org/abs/2003.03033. [9] PRAGNESH T, MOHAN B R. Compression of convolution neural network using structured pruning[C]//Proceedings of the IEEE 7th International Conference for Convergence in Technology. Piscataway: IEEE Press, 2022: 1-5. [10] LIU Z C, MU H Y, ZHANG X Y, et al. MetaPruning: meta learning for automatic neural network channel pruning[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2019: 3295-3304. [11] CHEN H L, YANG J F, MAO S A. Convolutional layers acceleration by exploring optimal filter structures[C]//Proceedings of the IEEE International Conference on Recent Advances in Systems Science and Engineering. Piscataway: IEEE Press, 2022: 1-6. [12] CARBALLO M V, KIL LEE B. Accuracy-aware structured filter pruning for deep neural networks[C]//Proceedings of the International Conference on Computational Science and Computational Intelligence. Piscataway: IEEE Press, 2021: 679-682. [13] JAYAKODY S, WANG J. EMBARK: memory bounded architectural improvement in CSR-CSC sparse matrix multiplication[C]//Proceedings of the IEEE 9th International Conference on Collaboration and Internet Computing. Piscataway: IEEE Press, 2024: 8-17. [14] WANG S, KANG Y. Gradient distribution-aware INT8 training for neural networks[J]. Neurocomputing, 2023, 541: 126269. [15] KIM J, LEE C, CHO E, et al. Towards next-level post-training quantization of hyper-scale transformers[EB/OL]. (2024-02-14)[2024-02-16]. https://arxiv.org/abs/2402.08958. [16] SCHABACK R. Convergence analysis of the general Gauss-Newton algorithm[J]. Numerische Mathematik, 1985, 46(2): 281-309. [17] ARBEL M, MENEGAUX R, WOLINSKI P. Rethinking Gauss-Newton for learning over-parameterized models[C]//Proceedings of the Advances in Neural Information Processing Systems 36. San Diego: Neural Information Processing Systems Foundation, Inc., 2023: 33379-33402. [18] HU W, XU D, FAN Z M, et al. Vis-TOP: visual transformer overlay processor[EB/OL]. (2021-10-21)[2024-02-16]. https://arxiv.org/abs/2110.10957. [19] HAN Y T, LIU Q. HPTA: a high performance transformer accelerator based on FPGA[C]//Proceedings of the 33rd International Conference on Field-Programmable Logic and Applications. Piscataway: IEEE Press, 2023: 27-33. -

 下载:
下载:

 点击查看大图
点击查看大图
计量
- 文章访问数: 366
- HTML全文浏览量: 116
- PDF下载量: 25
- 被引次数: 0
