



A multimodal sentiment analysis based on audio and video features optimization and cross-modal Transformer
-
摘要:
针对多模态情感分析中音视频模态特征质量较差、不同模态信息交互不够充分等问题,提出一种基于音视频特征优化与跨模态Transformer(CMT)的多模态情感分析方法。设计了一种音视频特征优化机制(AVFOM),通过与文本特征的协同作用,增加音视频特征的情感信息密度,提高音频和视频特征质量;设计了CMT结构,以文本为主,实现文本-音频、文本-视频模态的两两充分交互,学习不同模态的一致性信息。此外,引入基于自监督学习策略的标签生成方法,实现单模态情感预测任务,学习每个模态各自的特性。所提方法在CMU-MOSI和CMU-MOSEI这2个公开数据集上进行了大量实验验证与测试,结果表明:所提方法超越当前诸多性能先进的方法,有效提升了多模态情感分析的准确性。
-
关键词:
- 多模态 /
- 情感分析 /
- Transformer模型 /
- 自监督学习 /
- 音视频特征优化
Abstract:To solve problems including low-quality audio and video modal features and inadequate interaction between various modalities, a multimodal sentiment analysis approach based on cross-modal Transformer (CMT) and audio and video feature optimization is suggested. Firstly, we propose a audio and video features optimizing mechanism (AVFOM), which increases the density of sentiment information in audio and video features through synergistic interaction with textual features, thereby improving the quality of audio and video features. Secondly, in order to accomplish full interaction between text-audio and text-video modalities and learn consistent knowledge across various modalities, we construct a cross-modal Transformer structure with text as the dominant modality. Additionally, a label generation method based on the self-supervised learning strategy is introduced to perform single-modality sentiment prediction tasks, learning the characteristics of each modality separately. The proposed method is extensively validated and tested on two public datasets, CMU-MOSI and CMU-MOSEI, which surpass many currently advanced methods in terms of performance and effectively improve the accuracy of multimodal sentiment analysis.
-
表 1 实验设置
Table 1. Experimental setup
 下载: 导出CSV
下载: 导出CSV
表 2 在CMU-MOSI数据集上与其他基准模型的对比结果
Table 2. The results compared with other baseline models on the CMU-MOSI dataset
模型 MAE Corr Acc-2/% Acc-7/% F1/% TFN2[15] 0.901 0.698 */80.8 34.90 */80.7 MulT1[33] 0.871 0.698 */83.0 40.00 */82.8 Self-MM[32] 0.713 0.798 84.0/85.98 * 84.42/85.95 MISA[34] 0.783 0.761 81.8/83.4 42.30 81.7/83.6 MAG-Bert2[35] 0.731 0.798 82.5/84.3 * 82.6/84.3 MTSA[36] 0.696 0.806 */86.8 46.40 */86.8 TETFN[37] 0.717 0.800 84.05/86.10 * 83.83/86.07 MTAMW[38] 0.712 0.794 84.40/86.59 46.84 84.20/86.46 CRNet[39] 0.712 0.797 */86.4 47.40 */86.4 FRDIN[40] 0.682 0.813 85.8/87.4 46.59 85.3/87.5 MIBSA[41] 0.728 0.798 */87.00 43.10 */87.20 本文 0.592 0.862 86.90/89.11 50.30 86.96/89.12 注:MulT1模型表示结果来自(AOBERT)[20],TFN2,MAG-Bert2模型表示结果来自(VLP2MSA)[42],其他模型结果来自原论文;“*”表示原文未提供结果;对于Acc-2和F1,“/”的左边代表negative/non-negative的方法,右边代表negative/positive的方法;加粗数字表示最优值。
下载: 导出CSV
表 3 在CMU-MOSEI数据集上与其他基线模型对比的结果
Table 3. The results compared with other baseline models on the CMU-MOSEI dataset
模型 MAE Corr Acc-2/% Acc-7/% F1/% TFN2[15] 0.593 0.700 */82.50 50.20 */82.10 MulT1[33] 0.580 0.703 */82.50 51.80 */82.30 Self-MM[32] 0.530 0.765 82.81/85.17 * 82.53/85.30 MISA[34] 0.555 0.756 83.60/85.50 52.20 83.80/85.30 MAG-Bert2[35] 0.543 0.755 82.51/84.82 * 82.77/84.71 MTSA[36] 0.541 0.774 */85.50 52.90 */85.30 TETFN[37] 0.551 0.748 84.25/85.18 * 84.18/85.27 MTAMW[38] 0.525 0.782 83.09/86.49 53.73 83.48/86.45 CRNet[39] 0.541 0.771 */86.20 53.80 */86.10 FRDIN[40] 0.525 0.778 83.30/86.30 54.40 83.70/86.20 MIBSA[41] 0.568 0.753 */86.70 52.40 */85.80 本文 0.519 0.791 83.66/86.77 54.41 83.24/86.76 注:MulT1模型结果来自(AOBERT)[20],TFN2,MAG-Bert2模型结果来自(VLP2MSA)[42],其他模型结果来自原论文,“*”表示原文未提供结果,对于Acc-2和F1,“/”的左边代表negative/non-negative的方法,右边代表negative/positive的方法;加粗数字表示最优值。
下载: 导出CSV
表 4 在CMU-MOSI数据集上的消融实验
Table 4. The ablation experiments on the CMU-MOSI dataset
模型 MAE Corr Acc-2/% Acc-7/% F1/% 本文 0.592 0.862 86.90/89.11 50.30 86.96/89.12 w/o SentiLARE 0.837 0.743 82.14/84.14 39.43 82.20/84.13 w/o AVFOM 0.617 0.856 85.86/88.16 48.51 85.92/88.17 w/o CMT 0.613 0.854 85.71/87.38 47.47 85.78/87.41 w/o UPT 0.613 0.855 86.01/88.16 48.07 86.12/88.22 w/o audio 0.618 0.854 86.16/88.01 46.28 86.23/88.03 w/o video 0.621 0.847 85.86/88.01 49.40 85.89/87.99 w/o text 1.426 0.012 44.70/45.98 15.60 49.83/48.46
下载: 导出CSV
-
[1] GANDHI A, ADHVARYU K, PORIA S, et al. Multimodal sentiment analysis: a systematic review of history, datasets, multimodal fusion methods, applications, challenges and future directions[J]. Information Fusion, 2023, 91: 424-444. [2] HUANG C Q, ZHANG J L, WU X M, et al. TeFNA: text-centered fusion network with crossmodal attention for multimodal sentiment analysis[J]. Knowledge-Based Systems, 2023, 269: 110502. [3] CHEN C, HONG H S, GUO J, et al. Inter-intra modal representation augmentation with trimodal collaborative disentanglement network for multimodal sentiment analysis[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023, 31: 1476-1488. [4] CHEN Q P, HUANG G M, WANG Y B. The weighted cross-modal attention mechanism with sentiment prediction auxiliary task for multimodal sentiment analysis[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2022, 30: 2689-2695. [5] YUAN Z Q, LI W, XU H, et al. Transformer-based feature reconstruction network for robust multimodal sentiment analysis[C]//Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 4400-4407. [6] SUN H, CHEN Y W, LIN L F. TensorFormer: a tensor-based multimodal Transformer for multimodal sentiment analysis and depression detection[J]. IEEE Transactions on Affective Computing, 2023, 14(4): 2776-2786. [7] SUN Z K, SARMA P, SETHARES W, et al. Learning relationships between text, audio, and video via deep canonical correlation for multimodal language analysis[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(5): 8992-8999. [8] WU Y, LIN Z J, ZHAO Y Y, et al. A text-centered shared-private framework via cross-modal prediction for multimodal sentiment analysis[C]//Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Kerrville: Association for Computational Linguistics, 2021: 4730-4738. [9] HU G M, LIN T E, ZHAO Y, et al. UniMSE: Towards unified multimodal sentiment analysis and emotion recognition[EB/OL]. (2022-11-21)[2024-01-10]. https://doi.org/10.48550/arXiv.2211.11256. [10] MORENCY L P, MIHALCEA R, DOSHI P. Towards multimodal sentiment analysis: Harvesting opinions from the web[C]//Proceedings of the 13th International Conference on Multimodal Interfaces. New York: ACM, 2011: 169-176. [11] PORIA S, CAMBRIA E, GELBUKH A. Deep convolutional neural network textual features and multiple kernel learning for utterance-level multimodal sentiment analysis[C]//Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Kerrville: Association for Computational Linguistics, 2015: 2539-2544. [12] ZADEH A, LIANG P P, PORIA S, et al. Multi-attention recurrent network for human communication comprehension[C]//Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence. New York: ACM, 2018: 5642-5649. [13] KAMPMAN O, BAREZI E J, BERTERO D, et al. Investigating audio, visual, and text fusion methods for end-to-end automatic personality prediction[EB/OL]. (2018-05-16)[2024-01-12]. https:/doi.org/10.48550//arXiv.1805.00705. [14] NOJAVANASGHARI B, GOPINATH D, KOUSHIK J, et al. Deep multimodal fusion for persuasiveness prediction[C]//Proceedings of the 18th ACM International Conference on Multimodal Interaction. New York: ACM, 2016: 284-288. [15] ZADEH A, CHEN M H, PORIA S, et al. Tensor fusion network for multimodal sentiment analysis[EB/OL]. (2017-07-23)[2024-01-13]. https://doi.org/10.48550/arXiv.1707.07250. [16] LIU Z, SHEN Y, LAKSHMINARASIMHAN V B, et al. Efficient low-rank multimodal fusion with modality-specific factors[EB/OL]. (2018-05-31)[2024-01-13]. https://doi.org/10.48550/arXiv.1806.00064. [17] MAJUMDER N, HAZARIKA D, GELBUKH A, et al. Multimodal sentiment analysis using hierarchical fusion with context modeling[J]. Knowledge-Based Systems, 2018, 161: 124-133. [18] MAI S J, HU H F, XING S L. Divide, conquer and combine: hierarchical feature fusion network with local and global perspectives for multimodal affective computing[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Kerrville: Association for Computational Linguistics, 2019: 481-492. [19] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Proceedings of the Advances in Neural Information Processing Systems. Red Hook: Curran Associates, 2017: 5998-6008. [20] KIM K, PARK S. AOBERT: All-modalities-in-One BERT for multimodal sentiment analysis[J]. Information Fusion, 2023, 92(C): 37-45. [21] MA L Y, YAO Y, LIANG T, et al. Multi-scale cooperative multimodal Transformers for multimodal sentiment analysis in videos[EB/OL]. (2022-06-17)[2024-01-15]. https://doi.org/10.48550/arXiv.2206.07981. [22] XU M, LIANG F F, SU X Y, et al. CMJRT: cross-modal joint representation Transformer for multimodal sentiment analysis[J]. IEEE Access, 2022, 10: 131671-131679. [23] WANG L, PENG J J, ZHENG C Z, et al. A cross modal hierarchical fusion multimodal sentiment analysis method based on multi-task learning[J]. Information Processing & Management, 2024, 61(3): 103675. [24] FU Y P, ZHANG Z Y, YANG R D, et al. Hybrid cross-modal interaction learning for multimodal sentiment analysis[J]. Neurocomputing, 2024, 571: 127201. [25] KE P, JI H Z, LIU S Y, et al. SentiLARE: sentiment-aware language representation learning with linguistic knowledge[EB/OL]. (2020-09-24)[2024-01-17]. https://doi.org/10.48550/arXiv.1911.02493. [26] LIU Y H, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach[EB/OL]. (2019-07-26)[2024-01-17]. https://doi.org/10.48550/arXiv.1907.11692. [27] ZADEH A, ZELLERS R, PINCUS E, et al. MOSI: multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos[EB/OL]. (2016-08-12)[2024-01-18]. https://doi.org/10.48550/arXiv.1606.06259. [28] BAGHER ZADEH A, LIANG P P, PORIA S, et al. Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistic. Kerrville: Association for Computational Linguistics, 2018: 2236-2246. [29] DEGOTTEX G, KANE J, DRUGMAN T, et al. COVAREP: a collaborative voice analysis repository for speech technologies[C]//Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE Press, 2014: 960-964. [30] CHEONG J H, JOLLY E, XIE T K, et al. Py-Feat: python facial expression analysis toolbox[J]. Affective Science, 2023, 4(4): 781-796. [31] LIN H, ZHANG P L, LING J D, et al. PS-mixer: a polar-vector and strength-vector mixer model for multimodal sentiment analysis[J]. Information Processing & Management, 2023, 60(2): 103229. [32] YU W M, XU H, YUAN Z Q, et al. Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2021, 35(12): 10790-10797. [33] TSAI Y H H, BAI S J, LIANG P P, et al. Multimodal Transformer for unaligned multimodal language sequences[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Kerrville: Association for Computational Linguistics, 2019: 6558-6569. [34] HAZARIKA D, ZIMMERMANN R, PORIA S. MISA: Modality-invariant and-specific representations for multimodal sentiment analysis[C]//Proceedings of the 28th ACM International Conference on Multimedia. New York: ACM, 2020: 1122-1131. [35] RAHMAN W, HASAN M K, LEE S, et al. Integrating multimodal information in large pretrained Transformers [C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Kerrville: Association for Computational Linguistics, 2020: 2359-2369. [36] YANG B, SHAO B, WU L J, et al. Multimodal sentiment analysis with unidirectional modality translation[J]. Neurocomputing, 2022, 467: 130-137. [37] WANG D, GUO X T, TIAN Y M, et al. TETFN: a text enhanced Transformer fusion network for multimodal sentiment analysis[J]. Pattern Recognition, 2023, 136: 109259. [38] WANG Y F, HE J H, WANG D, et al. Multimodal Transformer with adaptive modality weighting for multimodal sentiment analysis[J]. Neurocomputing, 2024, 572: 127181. [39] SHI H, PU Y Y, ZHAO Z P, et al. Co-space representation interaction network for multimodal sentiment analysis[J]. Knowledge-Based Systems, 2024, 283: 111149. [40] ZENG Y F, LI Z X, CHEN Z B, et al. A feature-based restoration dynamic interaction network for multimodal sentiment analysis[J]. Engineering Applications of Artificial Intelligence, 2024, 127: 107335. [41] LIU W, CAO S C, ZHANG S. Multimodal consistency-specificity fusion based on information bottleneck for sentiment analysis[J]. Journal of King Saud University-Computer and Information Sciences, 2024, 36(2): 101943. [42] YI G F, FAN C H, ZHU K, et al. VLP2MSA: Expanding vision-language pre-training to multimodal sentiment analysis[J]. Knowledge-Based Systems, 2024, 283: 111136. -

 下载:
下载:
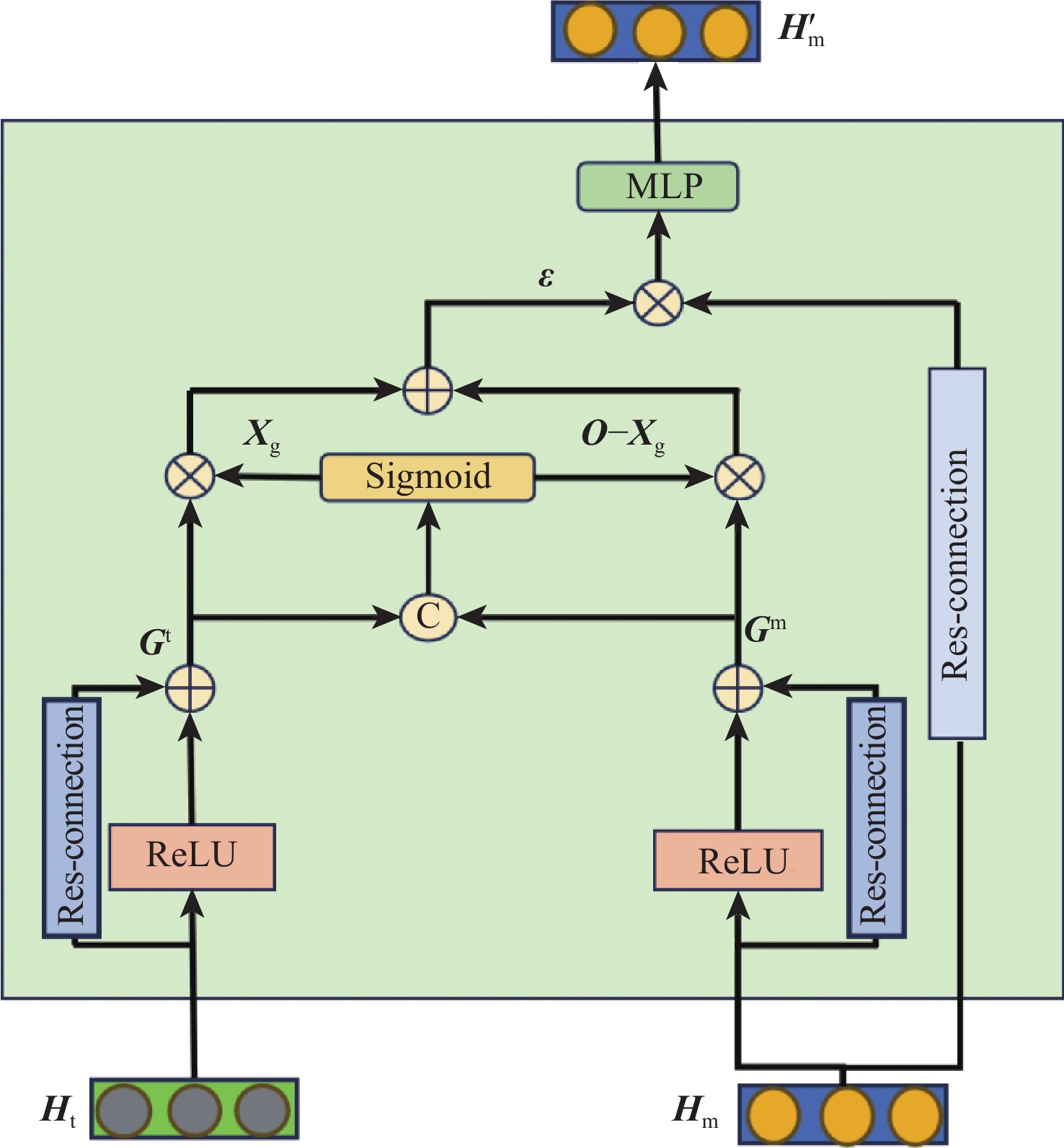
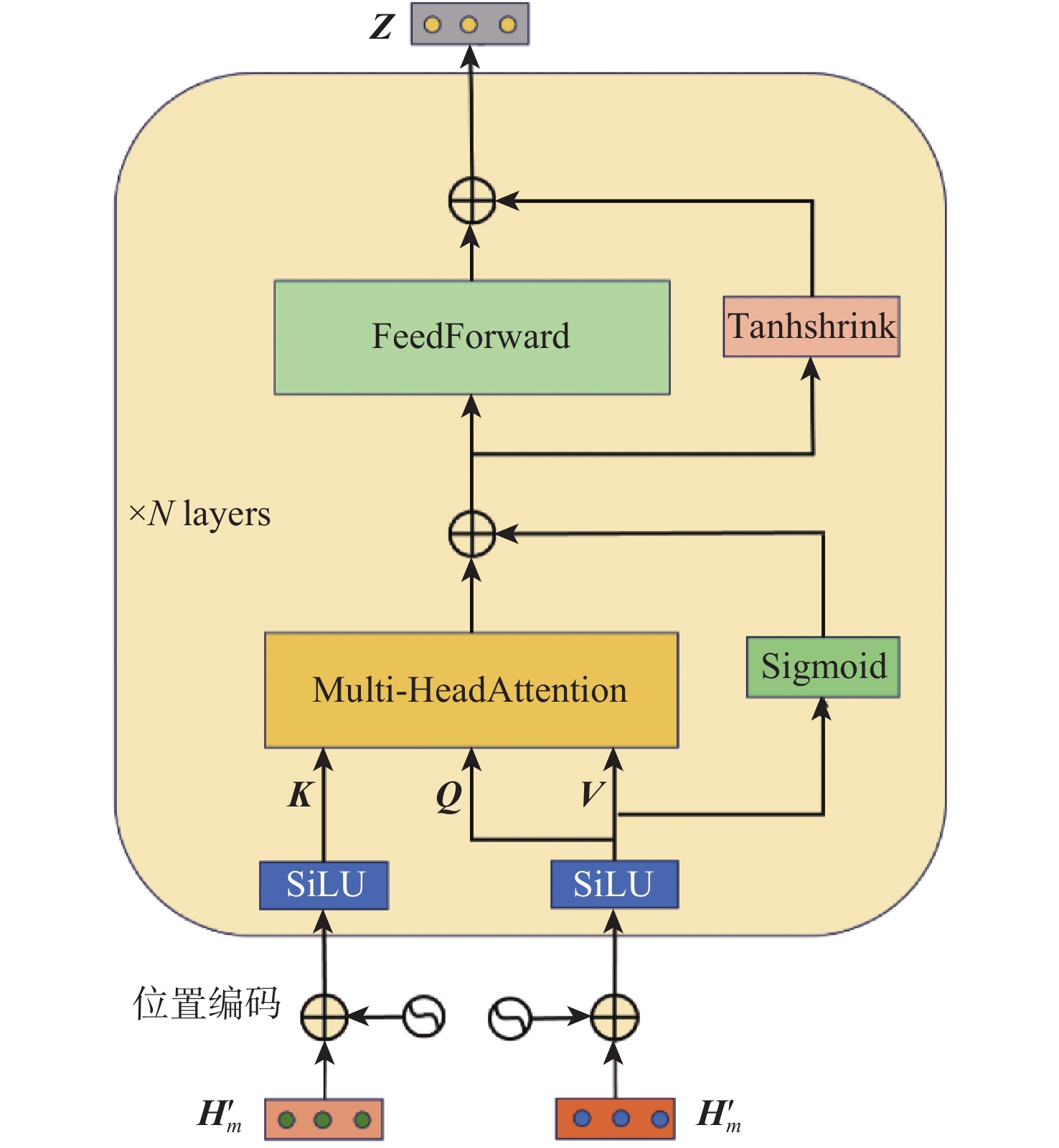
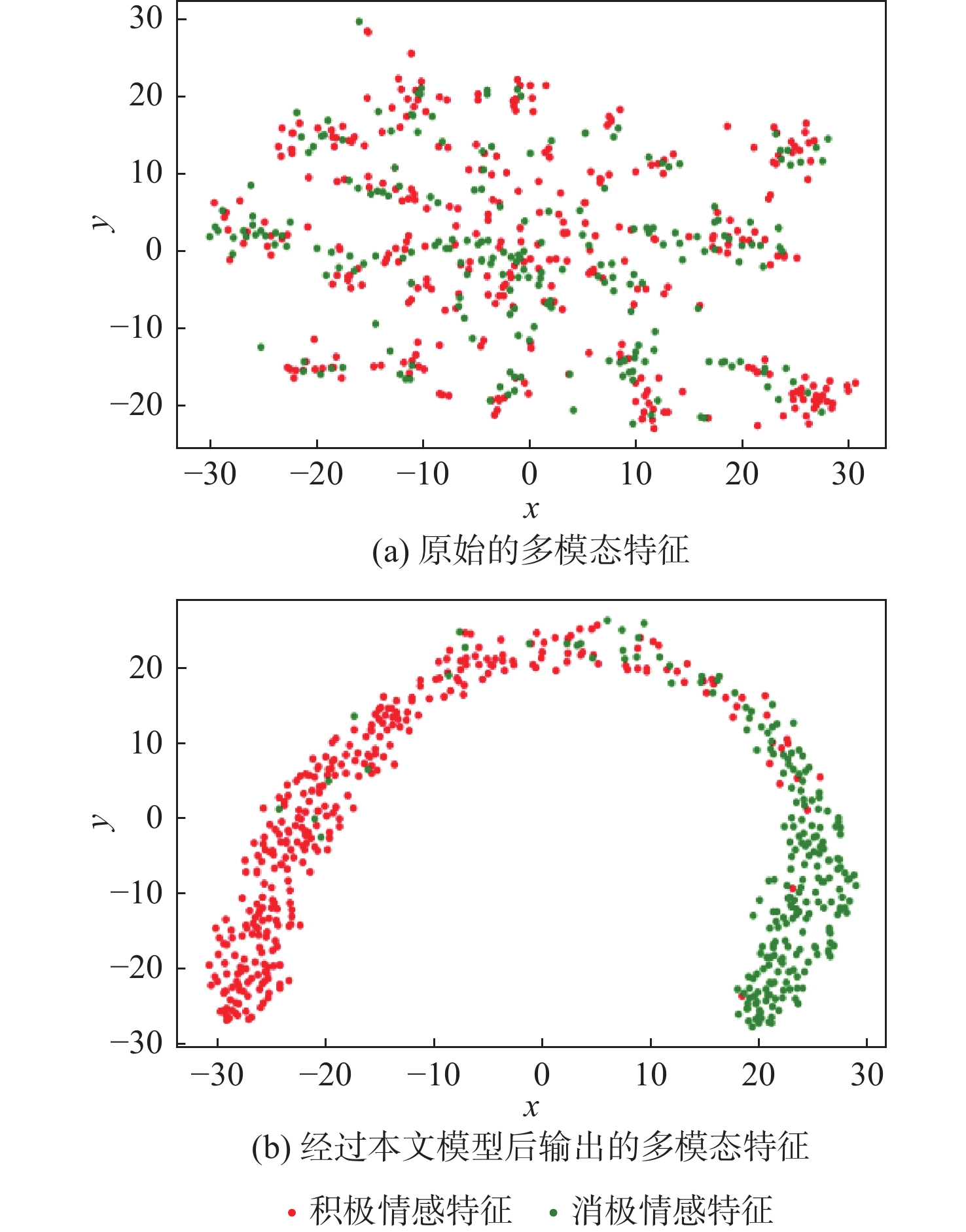

 点击查看大图
点击查看大图
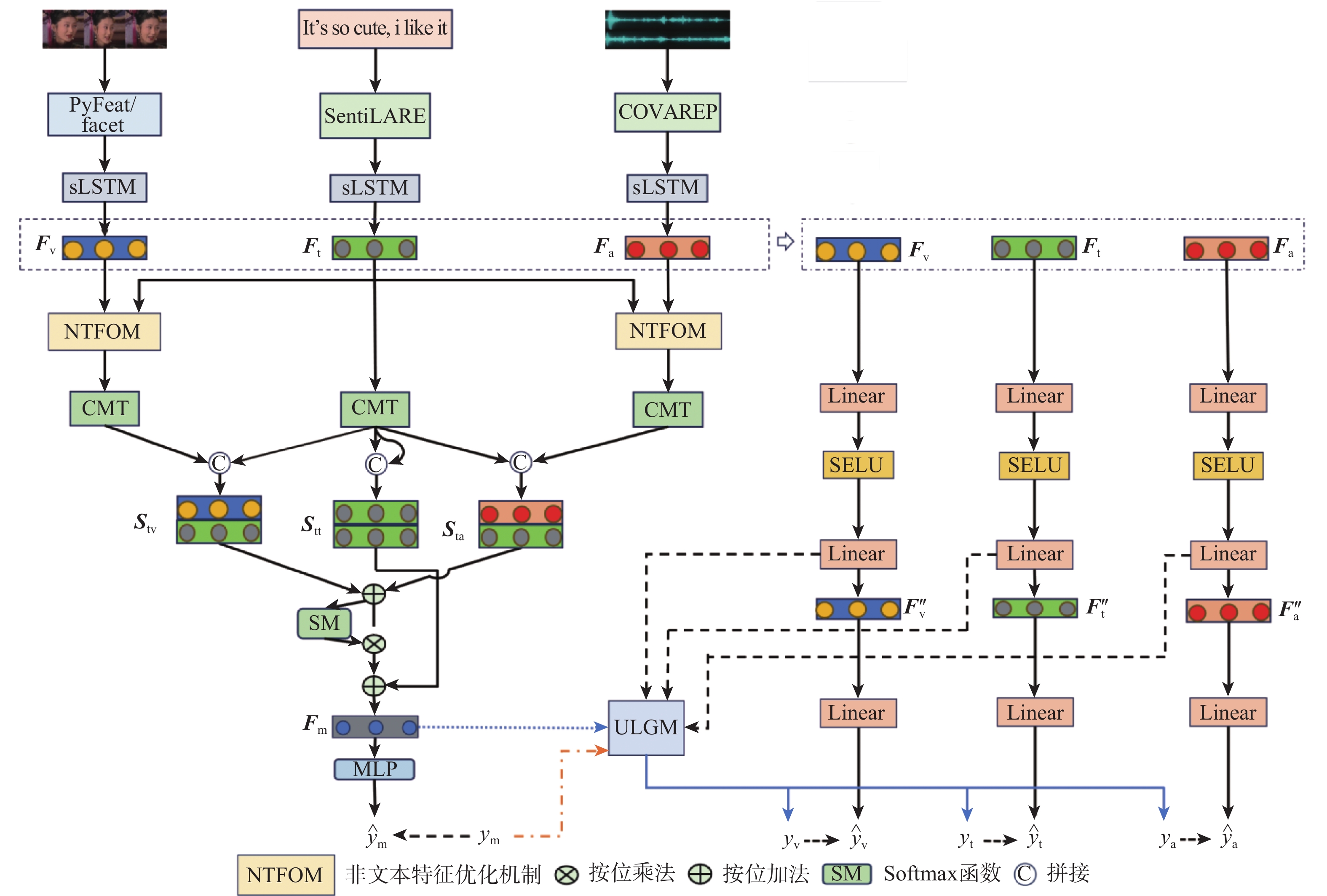
计量
- 文章访问数: 661
- HTML全文浏览量: 226
- PDF下载量: 22
- 被引次数: 0
