



-
摘要:
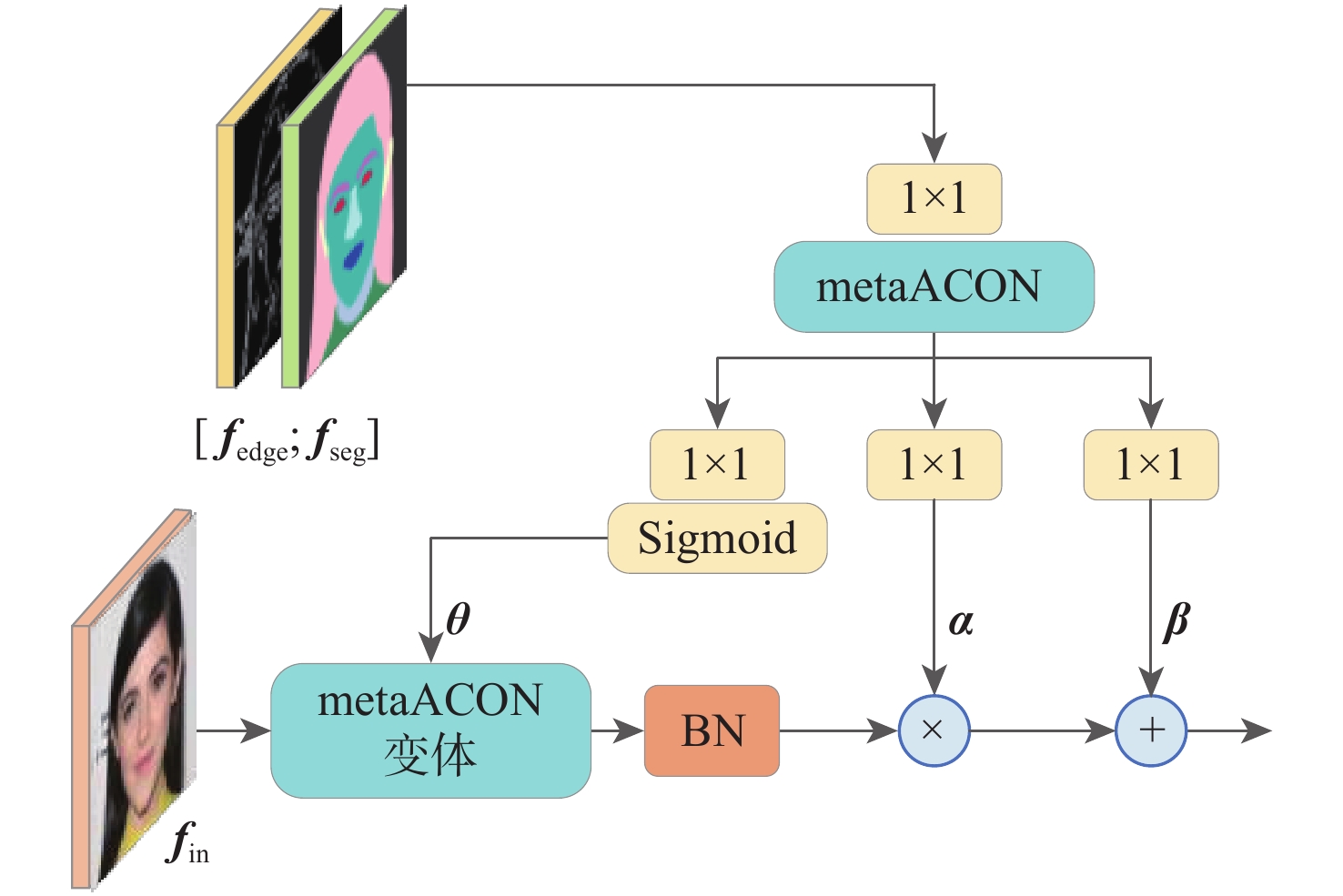
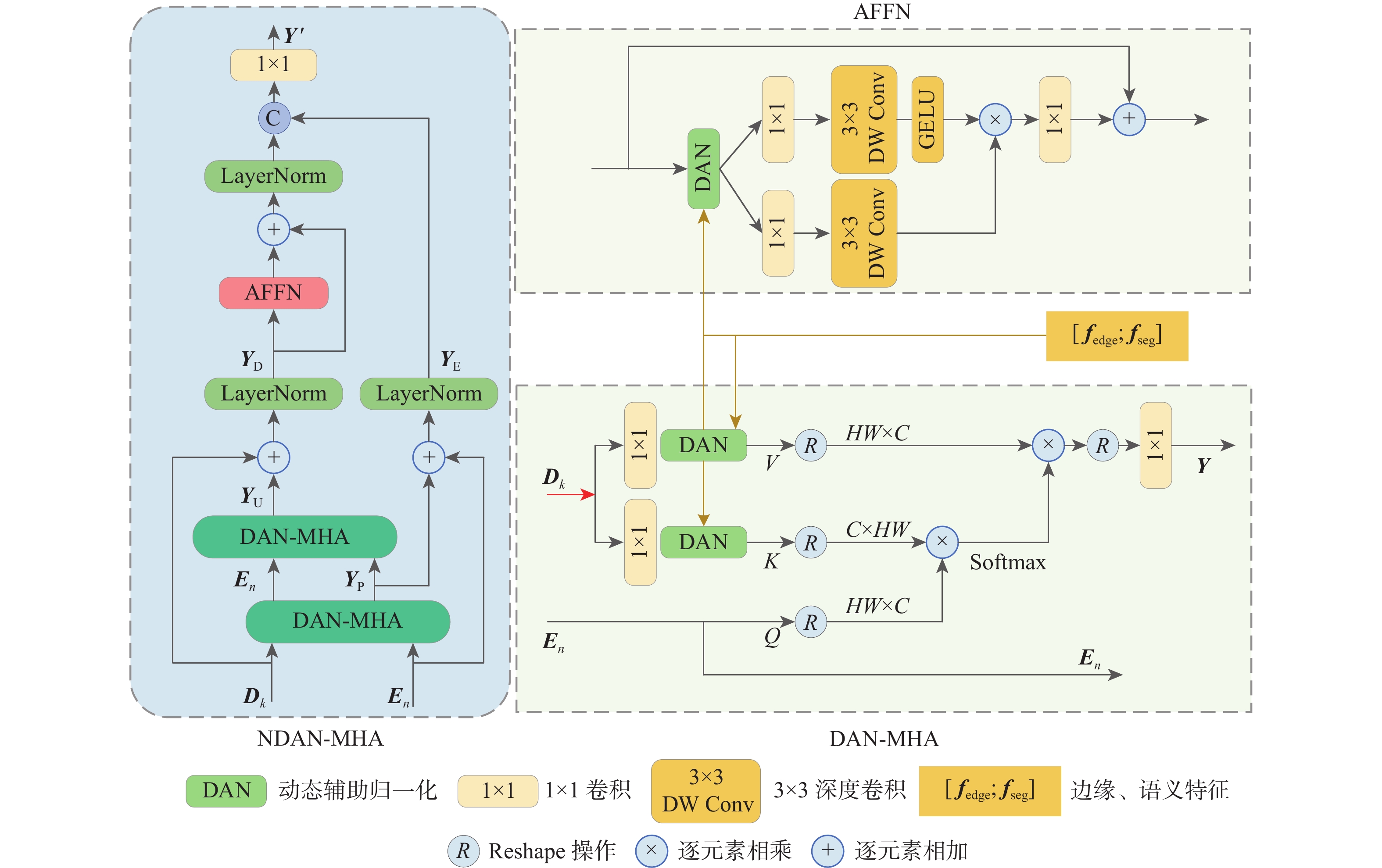
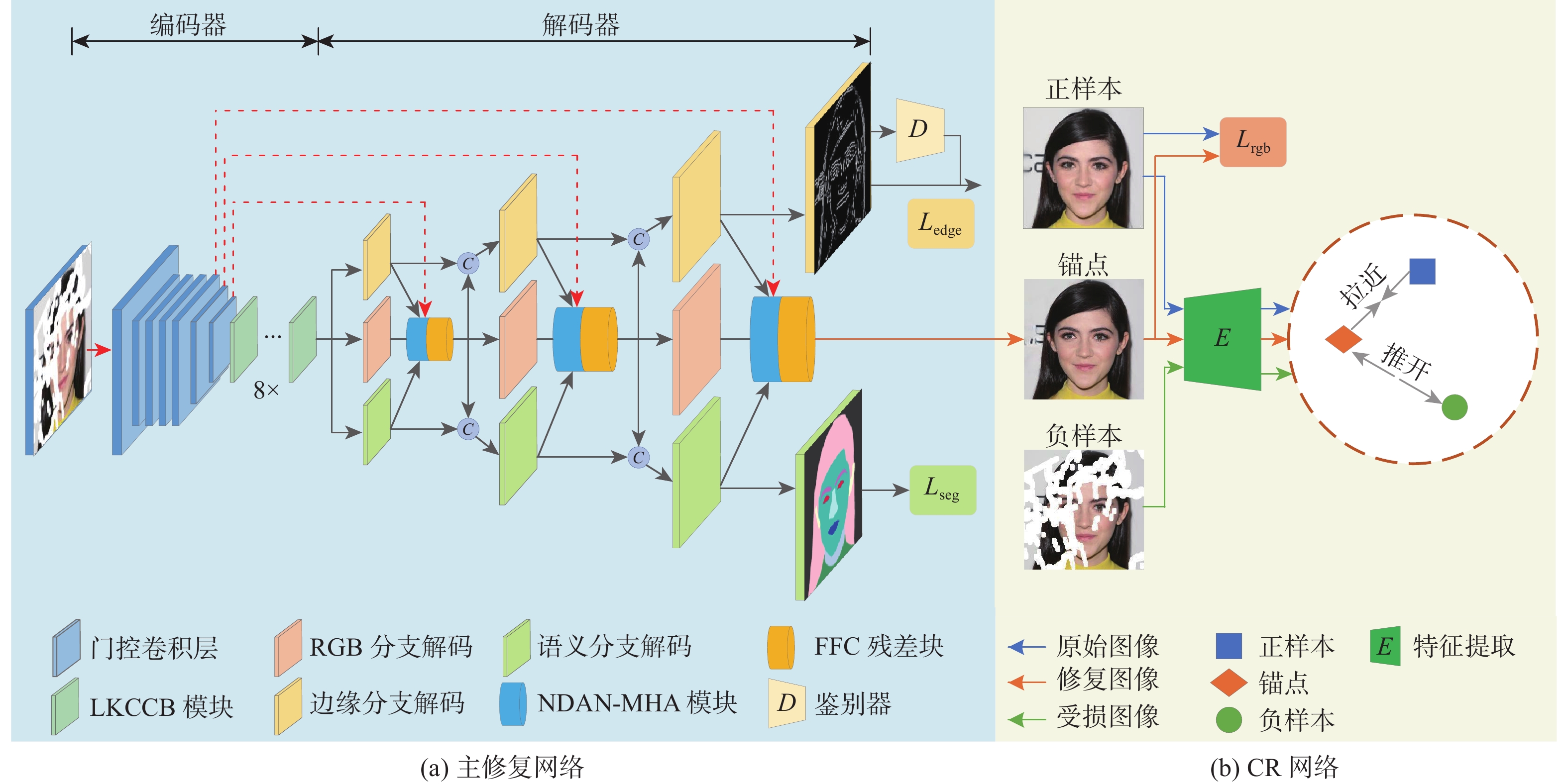
现有的图像修复方法通过预测辅助结构信息来填充逼真的补丁,但不准确的先验可能导致不合理的结构和模糊的纹理。同时,现有方法仅关注原始图像与修复图像之间的关系,未充分利用受损图像的信息。针对上述问题,提出一种端到端的Transformer人脸图像修复网络,利用语义分割和边缘纹理信息引导修复过程。其中,主修复网络包含一个RGB修复分支、2个用于语义分割和边缘纹理的辅助分支。在编码器中设计一组大核卷积上下文瓶颈(LKCCB)模块,以增加有效感受野和更好地上下文推理。为捕获遥远距离的上下文信息,提出嵌套动态辅助归一化多头注意力(NDAN-MHA)模块,其中,含有的动态辅助归一化(DAN)模块能够动态整合3个分支的结构特征,以此丰富语义一致性。此外,提出引入对比正则化(CR)网络来稳定和改进网络的训练,以生成更真实的修复图像。在CelebA-HQ和FFHQ数据集上进行定性和定量实验,结果表明:所提方法在主客观指标上均优于对比方法,能够合理地修复大面积不规则遮挡的人脸图像。
Abstract:Current picture inpainting techniques use auxiliary structural information prediction to fill realistic patches, however erroneous priors can result in unrealistic structures and blurry textures. Meanwhile, existing methods only focus on the relationship between the original image and the inpainted image, and do not fully utilize the information of the damaged image. To address the above problems, an end-to-end transformer face image inpainting network is proposed, which utilizes semantic segmentation and edge texture information to guide the inpainting process. The main inpainting network includes one RGB inpainting branch and two auxiliary branches for semantic segmentation and edge texture. A set of large kernel convolutional context bottleneck (LKCCB) modules is designed in the encoder to increase the effective receptive field and better contextual reasoning. In order to capture distant contextual information, a nested dynamic auxiliary normalization multi-head attention (NDAN-MHA) module is proposed, which contains a dynamic auxiliary normalization (DAN) module that can dynamically integrate the structural features of the three branches to enrich semantic consistency. Furthermore, a contrastive regularization (CR) network is proposed to stabilize and improve the training of the network to generate more realistic inpainted images. The CelebA-HQ and FFHQ datasets were used for both qualitative and quantitative trials. The findings demonstrate that the suggested method performs better than the comparative methods in both subjective and objective measures and that it can reasonably restore huge, irregularly occluded face photos.
-

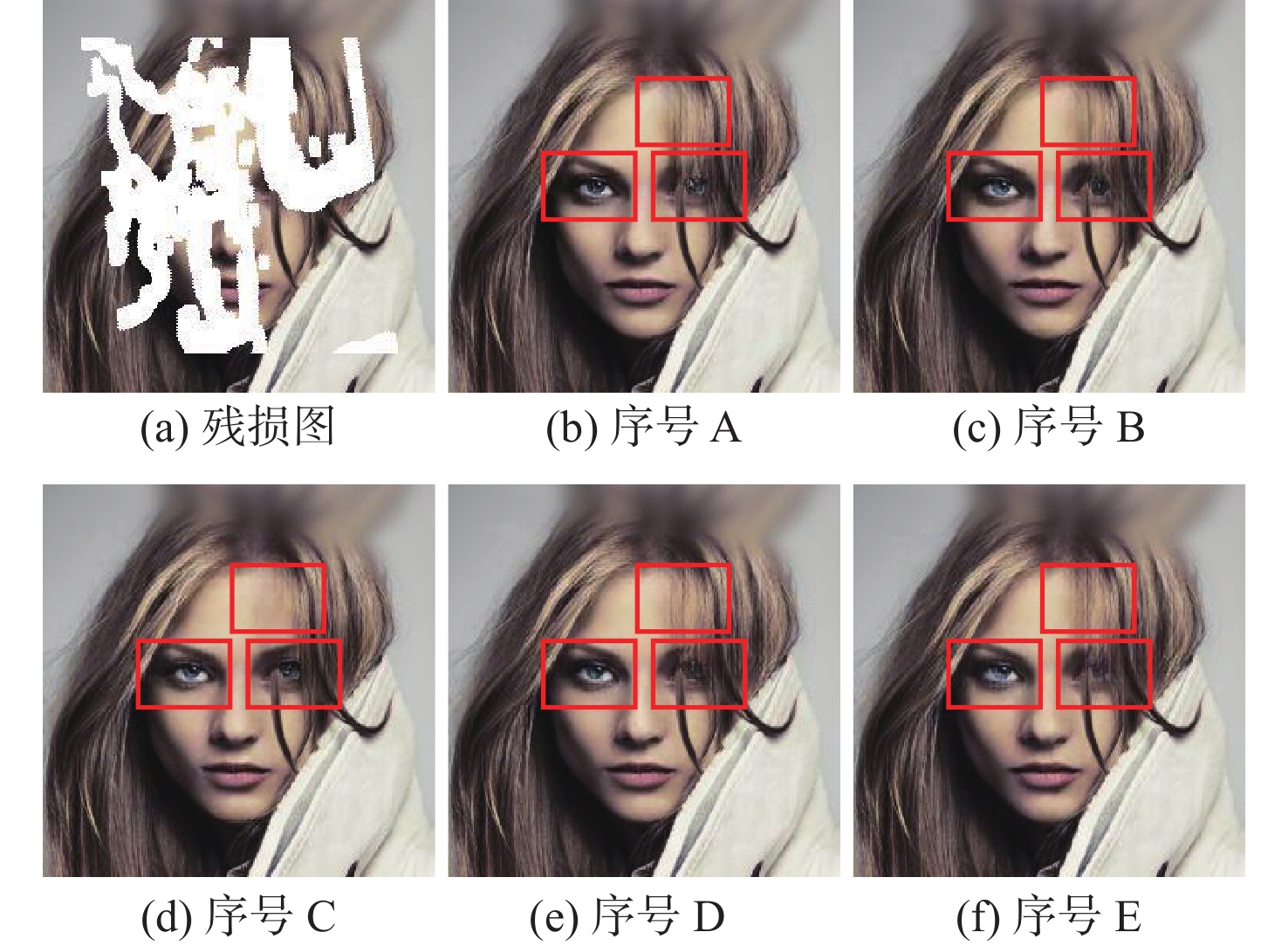
图 5 不同方法在2个数据集上的定性比较结果
Figure 5. Results of qualitative comparison of different methods on two datasets

图 6 不同模块在2个数据集上的定性消融结果
Figure 6. Qualitative ablation results of different modules on two datasets

图 8 CelebA-HQ数据集上瓶颈块的定性结果
Figure 8. Qualitative results of bottleneck blocks on the CelebA-HQ dataset

图 9 NDAN-MHA模块中不同组合定性结果
Figure 9. Qualitative results of different combinations in the NDAN-MHA module

图 11 不同权重值对修复效果的定性结果
Figure 11. Qualitative results of different weighting values on the effectiveness of restoration
表 1 不同方法在CelebA-HQ数据集上的定量比较结果
Table 1. Quantitative comparison results of different methods on the CelebA-HQ dataset
方法 PSNR/dB↑ SSIM↑ L1 ↓ FID↓ LPIPS↓ 掩码
比例
0.01~
0.2掩码
比例
0.2~
0.4掩码
比例
0.4~
0.6掩码
比例
0.01~
0.2掩码
比例
0.2~
0.4掩码
比例
0.4~
0.6掩码
比例
0.01~
0.2掩码
比例
0.2~
0.4掩码
比例
0.4~
0.6掩码
比例
0.01~
0.2掩码
比例
0.2~
0.4掩码
比例
0.4~
0.6掩码
比例
0.01~
0.2掩码
比例
0.2~
0.4掩码
比例
0.4~
0.6CTSDG[8] 38.00 33.18 26.43 0.984 0.947 0.846 0.003 0.008 0.021 1.258 2.895 10.475 0.018 0.059 0.161 HAN[24] 35.93 31.42 26.24 0.974 0.917 0.833 0.005 0.011 0.024 1.984 4.216 8.739 0.032 0.098 0.165 T-former[25] 36.14 31.44 26.18 0.974 0.915 0.830 0.005 0.011 0.024 1.572 4.630 9.576 0.025 0.098 0.166 MMT[21] 37.71 32.77 26.48 0.982 0.942 0.844 0.003 0.008 0.022 1.164 2.700 7.584 0.018 0.058 0.141 AOT[15] 35.07 31.59 24.59 0.963 0.921 0.792 0.009 0.014 0.033 2.427 4.642 19.654 0.035 0.085 0.223 HINT[26] 37.46 31.42 25.78 0.981 0.911 0.813 0.003 0.010 0.025 1.270 5.635 11.435 0.020 0.113 0.193 本文方法 38.56 33.47 26.82 0.985 0.949 0.852 0.003 0.008 0.021 0.932 2.071 6.318 0.015 0.049 0.129 注:“↑”表示该评价指标的值越高,图像修复效果越好;“↓”表示该评价指标的值越低,图像修复效果越好;各项指标的最优值用粗体表示。  下载: 导出CSV
下载: 导出CSV
表 2 不同方法在FFHQ数据集上的定量比较结果
Table 2. Quantitative comparison results of different methods on the FFHQ dataset
方法 PSNR/dB↑ SSIM↑ L1 ↓ FID↓ LPIPS↓ 掩码
比例
0.01~
0.2掩码
比例
0.2~
0.4掩码
比例
0.4~
0.6掩码
比例
0.01~
0.2掩码
比例
0.2~
0.4掩码
比例
0.4~
0.6掩码
比例
0.01~
0.2掩码
比例
0.2~
0.4掩码
比例
0.4~
0.6掩码
比例
0.01~
0.2掩码
比例
0.2~
0.4掩码
比例
0.4~
0.6掩码
比例
0.01~
0.2掩码
比例
0.2~
0.4掩码
比例
0.4~
0.6PRVS[6] 31.80 26.17 22.39 0.909 0.776 0.637 0.015 0.028 0.044 29.011 42.735 58.921 0.132 0.257 0.357 CTSDG[8] 37.36 31.70 25.12 0.981 0.937 0.822 0.003 0.008 0.024 0.613 2.125 10.116 0.020 0.069 0.182 HAN[24] 35.40 29.77 24.73 0.971 0.905 0.806 0.005 0.013 0.028 0.930 4.161 7.849 0.031 0.104 0.181 T-former[25] 35.98 30.29 25.07 0.974 0.912 0.815 0.005 0.012 0.026 0.546 2.359 5.793 0.023 0.086 0.163 MMT[21] 36.33 30.92 24.78 0.977 0.928 0.815 0.003 0.009 0.025 0.823 2.938 8.845 0.025 0.080 0.177 AOT[15] 34.07 30.33 23.57 0.952 0.908 0.770 0.011 0.016 0.037 1.498 3.884 25.273 0.040 0.090 0.244 本文方法 37.52 31.80 25.32 0.981 0.938 0.831 0.003 0.008 0.023 0.473 1.510 5.330 0.018 0.059 0.149 注:“↑”表示该评价指标的值越高,图像修复效果越好;“↓”表示该评价指标的值越低,图像修复效果越好;各项指标的最优值用粗体表示。
下载: 导出CSV
表 4 不同模块在2个数据集上的定量消融结果
Table 4. Quantitative ablation results for different modules on two datasets
序号 LKCCB模块 NDAN-MHA模块 CR模块 PSNR/dB↑ SSIM↑ L1↓ FID↓ LPIPS↓ 实验1 × × × 27.34 / 25.84 0.865 / 0.847 0.018 / 0.020 6.026 / 7.352 0.121 / 0.151 实验2 × √ × 27.54 / 26.06 0.868 / 0.850 0.017 / 0.020 5.947 / 6.323 0.116 / 0.145 实验3 √ √ × 27.67 / 26.13 0.870 / 0.851 0.017 / 0.020 5.697 / 6.121 0.115 / 0.143 实验4 √ √ √(无负样本) 27.98 / 26.38 0.875 / 0.856 0.016 / 0.019 4.902 / 4.276 0.105 / 0.128 本文方法 √ √ √ 28.09 / 26.59 0.878 / 0.860 0.016 / 0.018 4.575 / 3.657 0.102 / 0.121 注:“√”表示使用该模块;“×”表示未使用该模块;各指标值第1个为CelebA-HQ数据集的结果;第2个为FFHQ数据集的结果。
下载: 导出CSV
表 5 LKCCB中不同核大小K的消融实验
Table 5. Ablation experiments in LKCCB with different nucleus size K
K d PSNR/dB↑ SSIM↑ L1↓ FID↓ LPIPS↓ 6 2 28.08 0.877 0.0162 4.635 0.1028 15 3 28.05 0.877 0.0163 4.625 0.1026 21 3 28.09 0.878 0.0162 4.575 0.1023 28 4 28.08 0.878 0.0162 4.598 0.1030
下载: 导出CSV
表 6 CelebA-HQ数据集上瓶颈块的定量结果
Table 6. Quantitative results on bottleneck blocks on the CelebA-HQ dataset
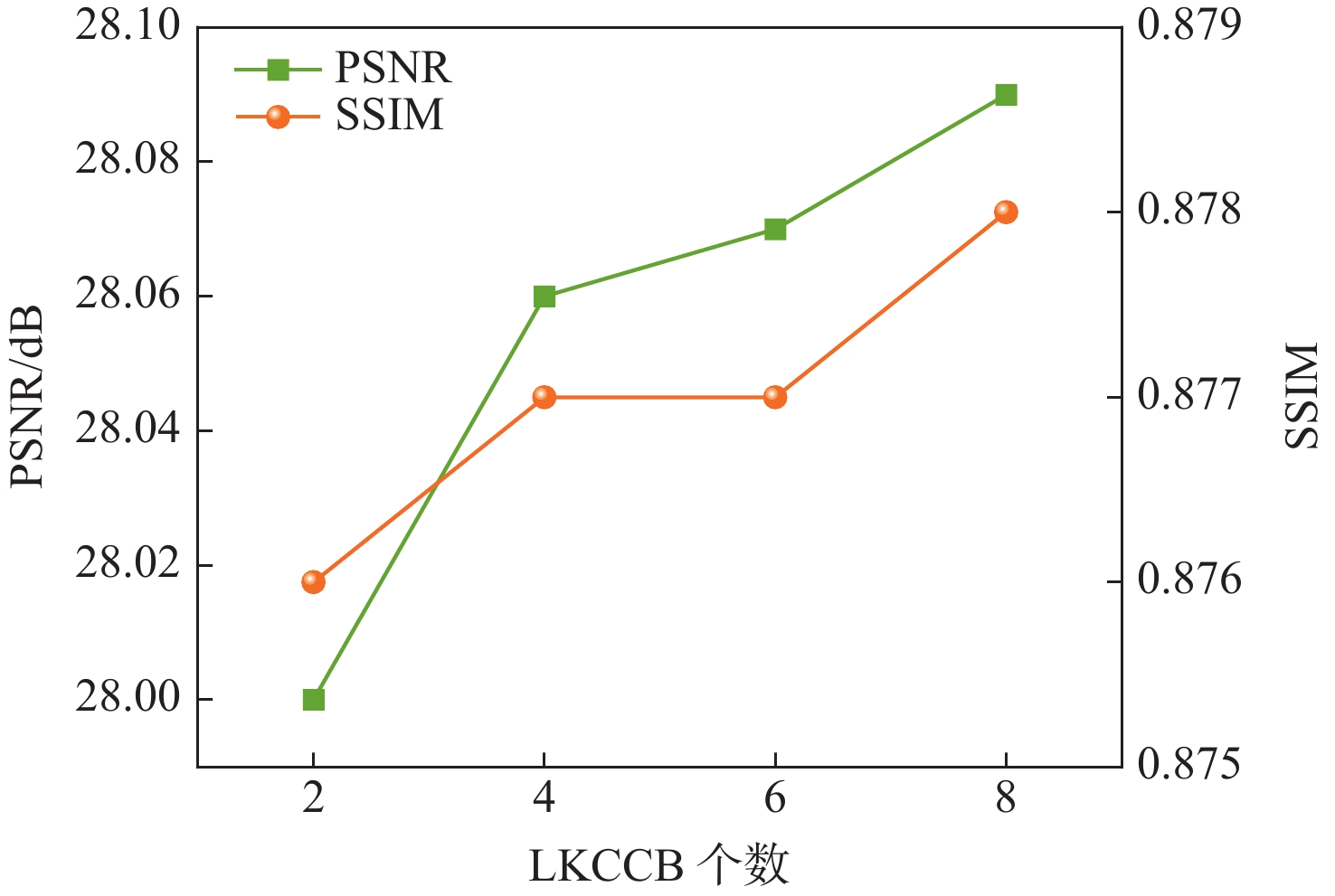
瓶颈块 PSNR/dB↑ SSIM↑ L1↓ FID↓ LPIPS↓ RES@8 28.00 0.877 0.0164 4.783 0.1049 AOT@8 27.97 0.876 0.0164 4.538 0.1032 LKCCB@8
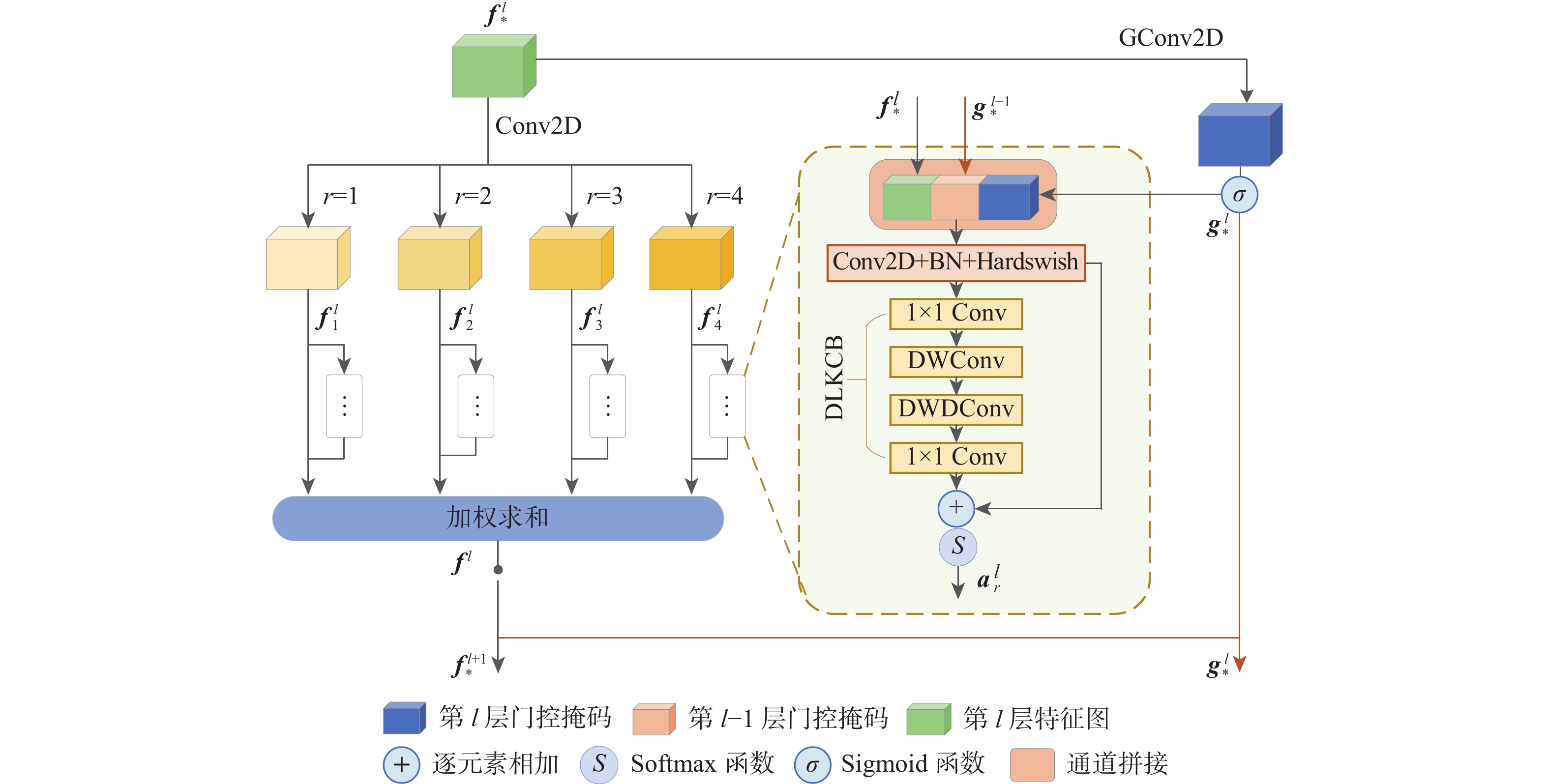
(-DLKCB)28.06 0.877 0.0163 4.702 0.1037 LKCCB@2 28.00 0.876 0.0164 4.654 0.1031 LKCCB@4 28.06 0.877 0.0163 4.576 0.1026 LKCCB@6 28.07 0.877 0.0162 4.556 0.1023 LKCCB@8 28.09 0.878 0.0162 4.575 0.1023 注:$ \mathrm{LKCCB}@L (L=2, 4, 6, 8) $表示使用$ L $个LKCCB模块进行实验;$ \mathrm{RES} $$ @8 $和$ \mathrm{AOT} @8 $分别表示8个ResNet模块和8个AOT模块;$ \mathrm{LKCCB}@8 $$ (-\mathrm{DLKCB}) $表示在8个LKCCB模块中去掉DLKCB进行实验。
下载: 导出CSV
表 7 NDAN-MHA模块中不同组合消融实验
Table 7. Ablation experiments with different combinations in the NDAN-MHA module
下载: 导出CSV
表 8 损失函数定量消融结果
Table 8. Loss function quantitative ablation results
损失函数 FID↓ LPIPS↓ 无损失函数 5.079 0.111 去除感知损失 4.874 0.106 去除风格+总变分损失 4.921 0.104 去除风格+重构损失 5.107 0.108 去除风格损失 4.834 0.102 本文方法 4.575 0.102
下载: 导出CSV
表 9 不同权重值对修复效果的定量结果
Table 9. Quantitative results of different weighting values on the effectiveness of restoration
权重设置 $ {\lambda }_{\text{edge}} $ $ {\lambda }_{\text{seg}} $ $ {\lambda }_{\text{contra}} $ PSNR/dB↑ FID↓ LPIPS↓ 设置1 1 1 1 27.84 5.187 0.109 设置2 0.5 0.5 0.5 27.85 5.216 0.109 设置3 0.5 0.5 2 28.03 4.741 0.104 最终设置 0.5 0.5 1 28.09 4.575 0.102
下载: 导出CSV
-
[1] NAZERI K, NG E, JOSEPH T, et al. EdgeConnect: structure guided image inpainting using edge prediction[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision Workshop. Piscataway: IEEE Press, 2019: 3265-3274. [2] YANG J, QI Z Q, SHI Y. Learning to incorporate structure knowledge for image inpainting[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020, 34(7): 12605-12612. [3] YAMASHITA Y, SHIMOSATO K, UKITA N. Boundary-aware image inpainting with multiple auxiliary cues[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE Press, 2022: 618-628. [4] 谭骏珊, 李雅芳, 秦姣华. 基于推理注意力机制的二阶段网络图像修复[J]. 电讯技术, 2022, 62(11): 1545-1553.TAN J S, LI Y F, QIN J H. Two-stage network image inpainting based on reasoning attention mechanism[J]. Telecommunication Engineering, 2022, 62(11): 1545-1553(in Chinese). [5] SHAO X R, YE H L, YANG B, et al. Two-stream coupling network with bidirectional interaction between structure and texture for image inpainting[J]. Expert Systems with Applications, 2023, 231: 120700. [6] LI J Y, HE F X, ZHANG L F, et al. Progressive reconstruction of visual structure for image inpainting[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2019: 5961-5970. [7] XU S X, LIU D, XIONG Z W. E2I: Generative inpainting from edge to image[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31(4): 1308-1322. [8] GUO X F, YANG H Y, HUANG D. Image inpainting via conditional texture and structure dual generation[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2021: 14114-14123. [9] 陈晓雷, 杨佳, 梁其铎. 结合语义先验和深度注意力残差的图像修复[J]. 计算机科学与探索, 2023, 17(10): 2450-2461.CHEN X L, YANG J, LIANG Q D. Image inpainting combining semantic priors and deep attention residuals[J]. Journal of Frontiers of Computer Science and Technology, 2023, 17(10): 2450-2461(in Chinese). [10] HORITA D, YANG J L, CHEN D, et al. A structure-guided diffusion model for large-hole image completion[EB/OL]. (2023-09-06)[2024-05-06]. https://doi.org/10.48550/arXiv.2211.10437. [11] NICHOL A Q, DHARIWAL P, RAMESH A, et al. GLIDE: Towards photorealistic image generation and editing with text-guided diffusion models[C]//Proceedings of the 39th International Conference on Machine Learning. New York: PMLR Press, 2022: 16784-16804. [12] MA X, ZHOU X Q, HUANG H B, et al. Free-form image inpainting via contrastive attention network[C]//Proceedings of the 25th International Conference on Pattern Recognition. Piscataway: IEEE Press, 2021: 9242-9249. [13] ZUO Z W, ZHAO L, LI A L, et al. Generative image inpainting with segmentation confusion adversarial training and contrastive learning[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2023, 37(3): 3888-3896. [14] LUO P J, XIAO G Q, GAO X B, et al. LKD-net: large kernel convolution network for single image dehazing[C]//Proceedings of the IEEE International Conference on Multimedia and Expo. Piscataway: IEEE Press, 2023: 1601-1606. [15] ZENG Y, FU J, CHAO H, et al. Aggregated contextual transformations for high-resolution image inpainting[J]. IEEE Transactions on Visualization and Computer Graphics, 2023, 29(7): 3266-3280. [16] SUVOROV R, LOGACHEVA E, MASHIKHIN A, et al. Resolution-robust large mask inpainting with fourier convolutions[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway: IEEE Press, 2022: 3172-3182. [17] PARK T, LIU M Y, WANG T C, et al. Semantic image synthesis with spatially-adaptive normalization[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 2332-2341. [18] MA N N, ZHANG X, LIU M Y, et al. Activate or not: learning customized activation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 8028-8038. [19] MA X Z, KONG X, WANG S N, et al. Luna: linear unified nested attention[EB/OL]. (2021-11-02)[2024-05-21]. https://doi.org/10.48550/arXiv.2106.01540. [20] LIU G L, REDA F A, SHIH K J, et al. Image inpainting for irregular holes using partial convolutions[C]//Proceedings of the 15th European Conference on Computer Vision. Berlin: Springer, 2018: 89-105. [21] YU Y S, DU D W, ZHANG L B, et al. Unbiased multi-modality guidance for image inpainting[C]//Proceedings of the 17th European Conference on Computer Vision. Berlin: Springer Press, 2022: 668-684. [22] KARRAS T, AILA T, LAINE S, et al. Progressive growing of GANs for improved quality, stability, and variation[EB/OL]. (2018-02-26)[2024-05-30]. https://doi.org/10.48550/arXiv.1710.10196. [23] KARRAS T, LAINE S, AILA T. A style-based generator architecture for generative adversarial networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 4401-4410. [24] DENG Y, HUI S Q, MENG R Y, et al. Hourglass attention network for image inpainting[C]//Proceedings of the 17th European Conference on Computer Vision. Berlin: Springer, 2022: 483-501. [25] DENG Y, HUI S Q, ZHOU S P, et al. T-former: an efficient transformer for image inpainting[C]//Proceedings of the 30th ACM International Conference on Multimedia. New York: ACM Press, 2022: 6559-6568. [26] CHEN S, ATAPOUR-ABARGHOUEI A, SHUM H P H. HINT: high-quality inpainting transformer with mask-aware encoding and enhanced attention[J]. IEEE Transactions on Multimedia, 2024, 26: 7649-7660. [27] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 770-778. [28] HUANG X, BELONGIE S. Arbitrary style transfer in real-time with adaptive instance normalization[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 1510-1519. -

 下载:
下载:






 点击查看大图
点击查看大图
计量
- 文章访问数: 243
- HTML全文浏览量: 125
- PDF下载量: 8
- 被引次数: 0
