



Reinforcement learning guidance law for maneuvering target interception based on imitation learning
-
摘要:
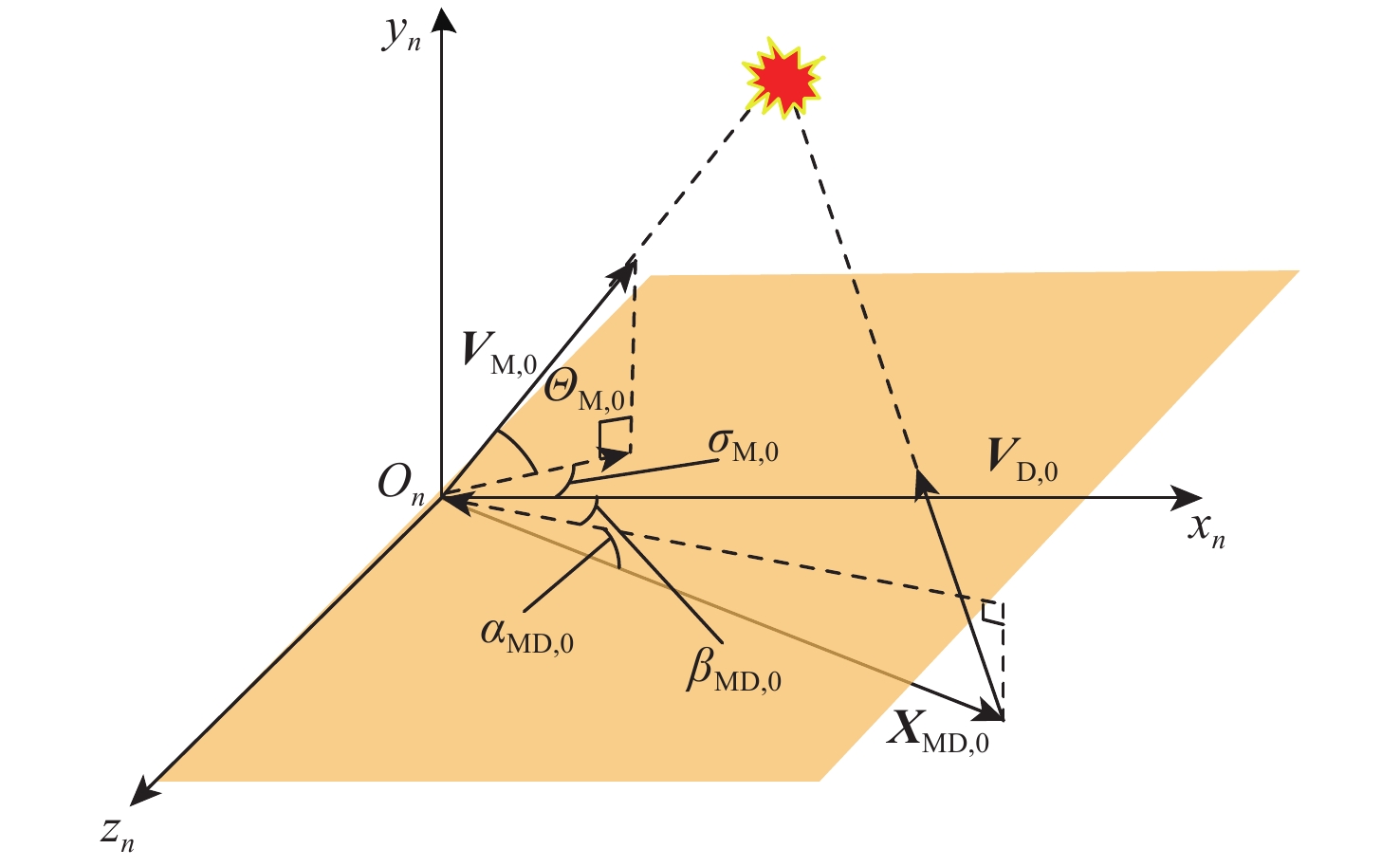
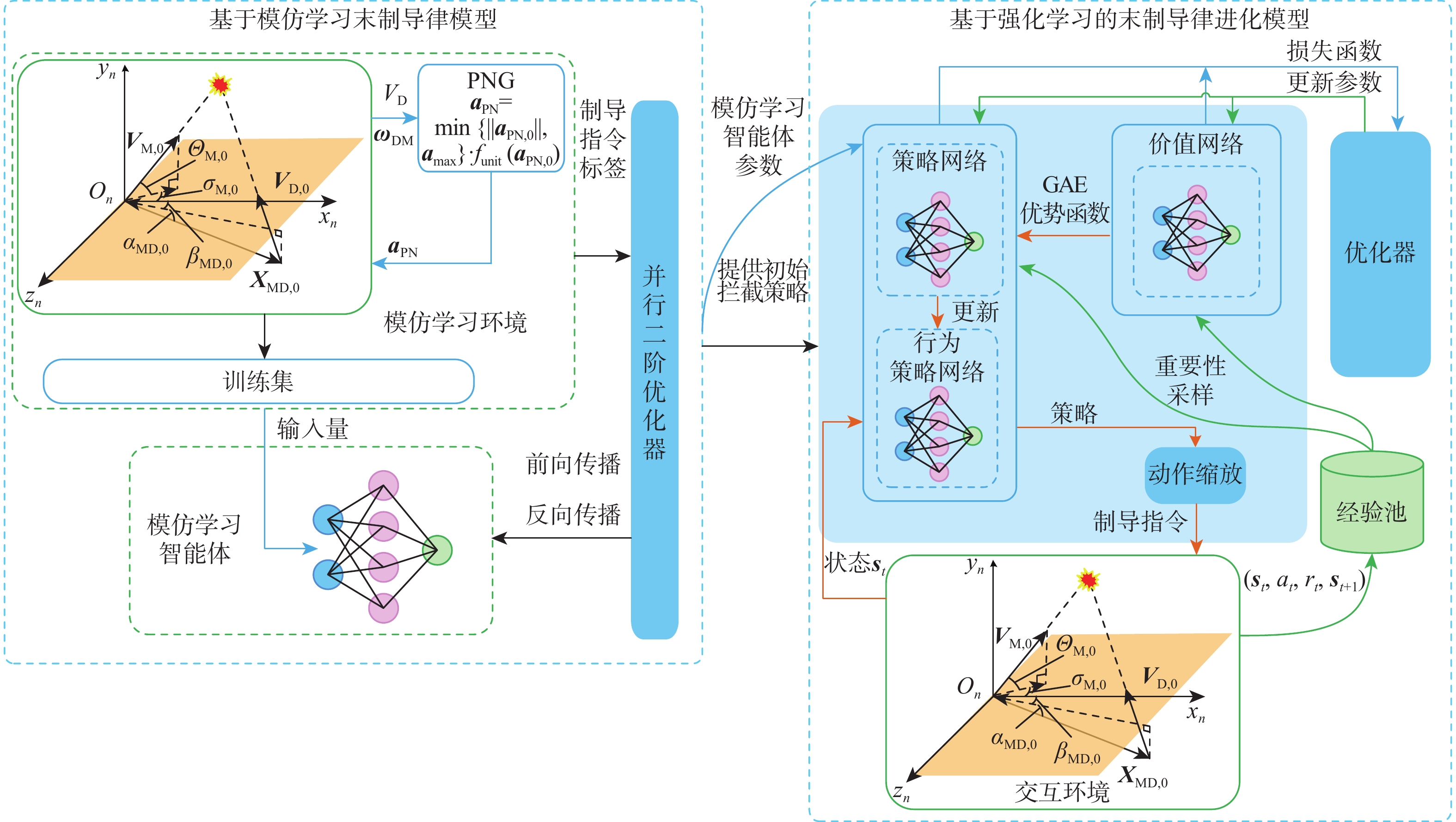
机动突防技术的发展对拦截制导律性能提出了更高的要求。为提高机动目标拦截概率、降低能量消耗、提升算法鲁棒性,提出了“基于模仿学习(IL)末制导律模型→基于强化学习的末制导律进化模型”的梯次智能制导框架。以拦截碰撞三角为基础,建立机动目标和拦截器三维不确定对抗模型;采用IL方法挖掘比例导引(PNG)规律,为后续强化学习制导律学习提供良好的初始策略;建立了马尔可夫决策模型,并设置包含能量消耗的过程奖励和包含“过渡段”的“软”终端奖励模型,利用近端策略优化(PPO)算法充分探索高性能拦截策略。蒙特卡罗仿真结果表明:新型制导律鲁棒性好,稳定性高,实现了比传统制导算法更高的拦截概率和更低的能量消耗,且单次决策耗时仅0.32 ms,具有一定的工程应用价值。
Abstract:The advancement of maneuver penetration technology necessitates an improvement in the design of interception guidance laws to a higher level. An echelon intelligent guidance framework of “terminal guidance law model based on imitation learning (IL) → terminal guidance law evolution model based on reinforcement learning” is proposed to increase the interception probability, decrease the energy consumption, and improve the robustness of the guidance law for intercepting maneuvering targets. Firstly, a three-dimensional uncertain confrontation model between the maneuvering target and interceptor is established based on the interception collision triangle. Secondly, the IL method is used to mine the proportional navigation guidance (PNG) law, which provides a good initial policy for the subsequent reinforcement learning guidance law. Finally, a Markov decision model is established, and a process reward of energy consumption and a “soft” terminal reward model, including a “transition section,” are proposed. The proximal policy optimization (PPO) algorithm is used to fully explore the high-performance interception strategy. The findings of the Monte Carlo simulation show that the new guidance law is very stable and resilient, outperforming the conventional guidance algorithm in terms of interception probability and energy usage. Additionally, the single decision time is only 0.32 ms, making it of certain engineering value.
-
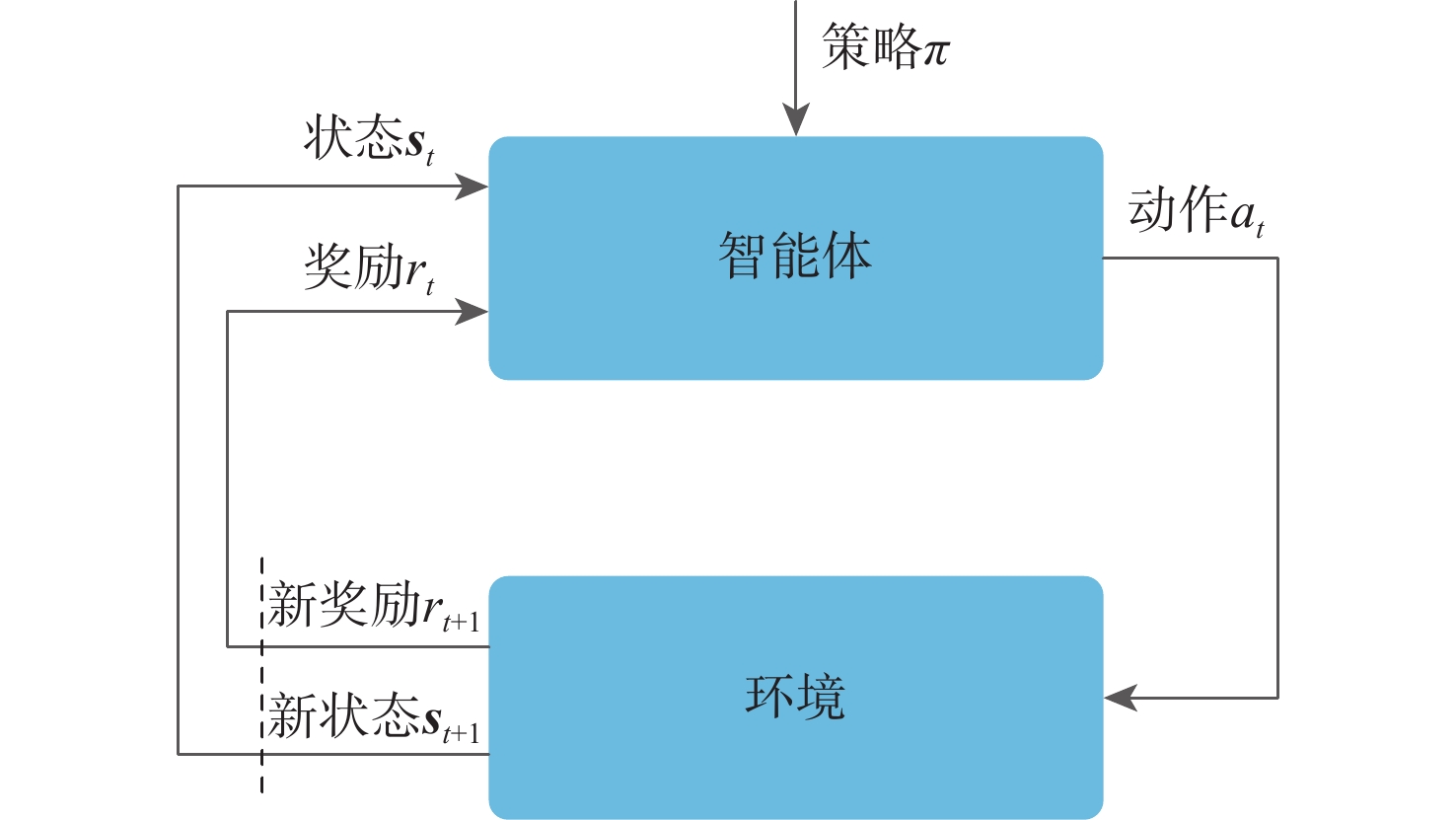
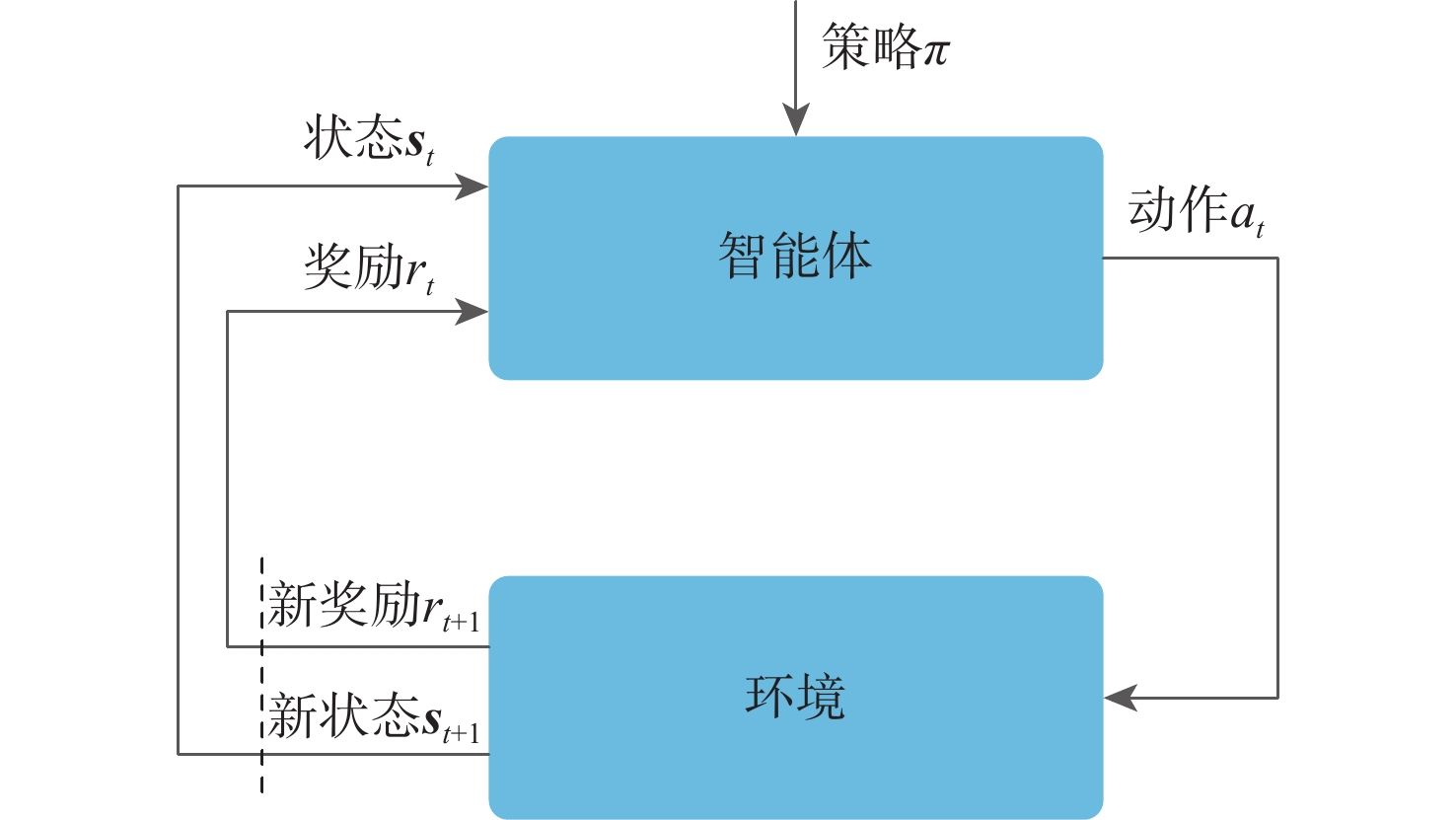
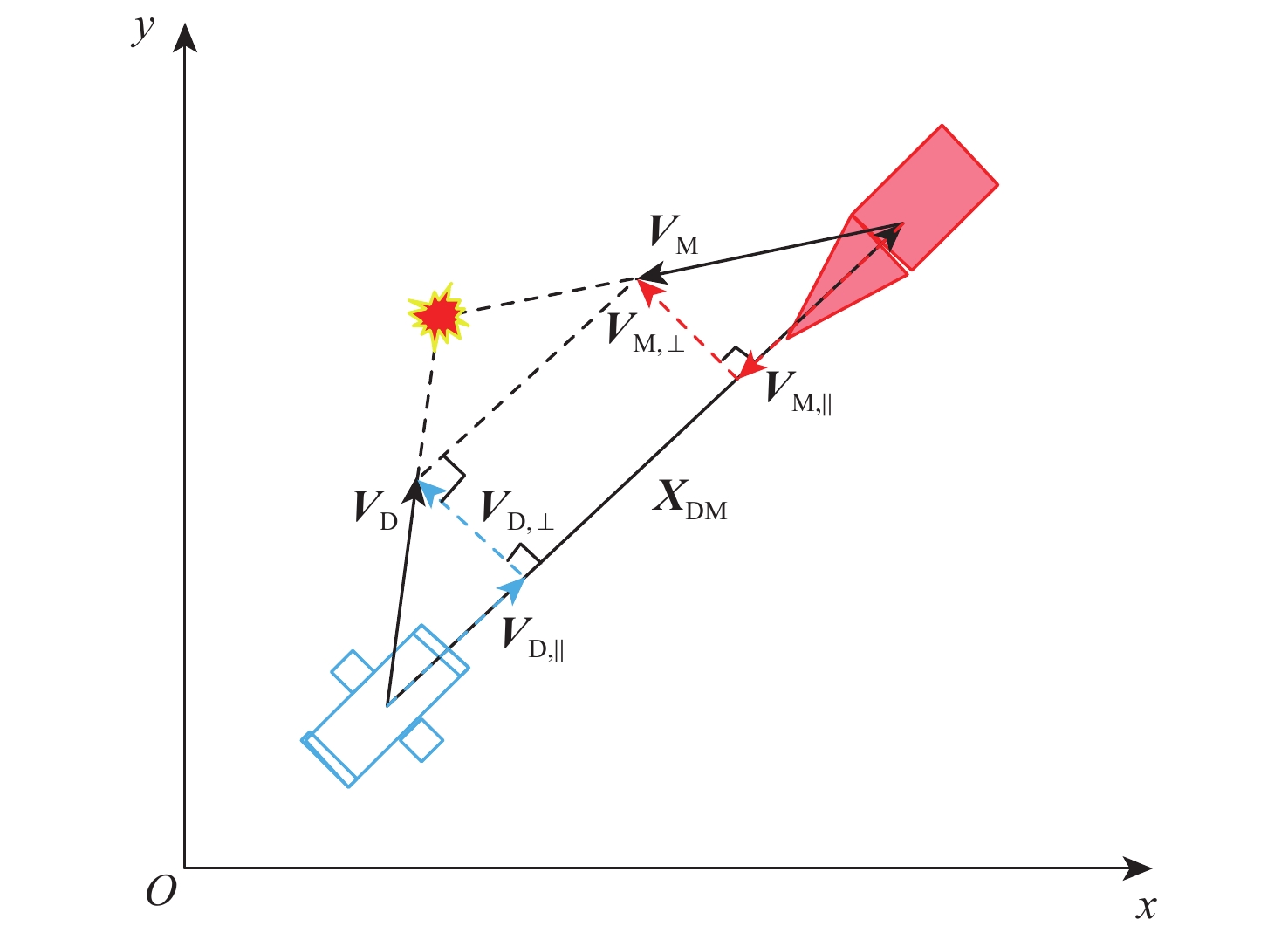
图 2 强化学习智能体与环境交互示意
Figure 2. Schematic diagram of reinforcement learning agent interaction with environment
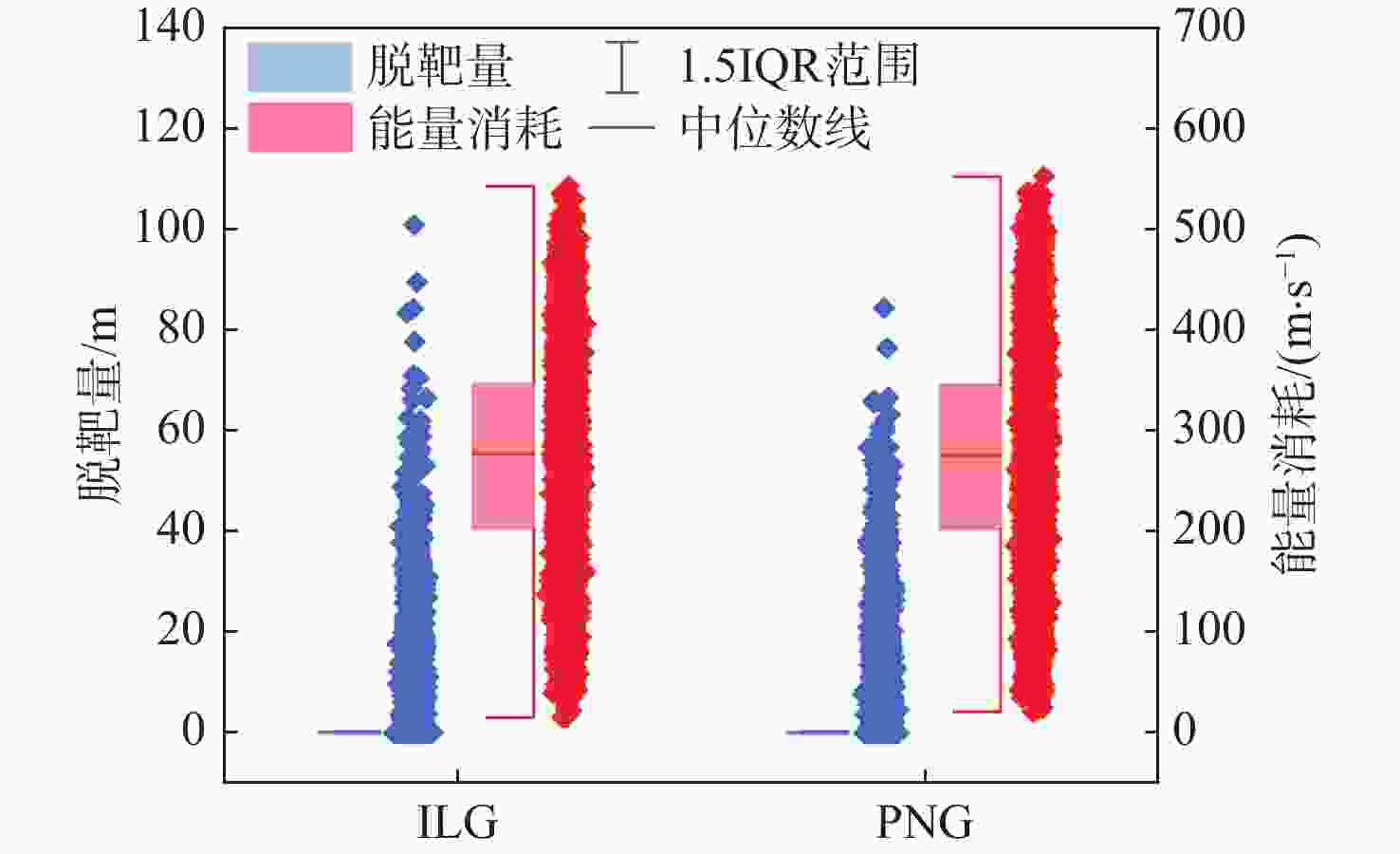
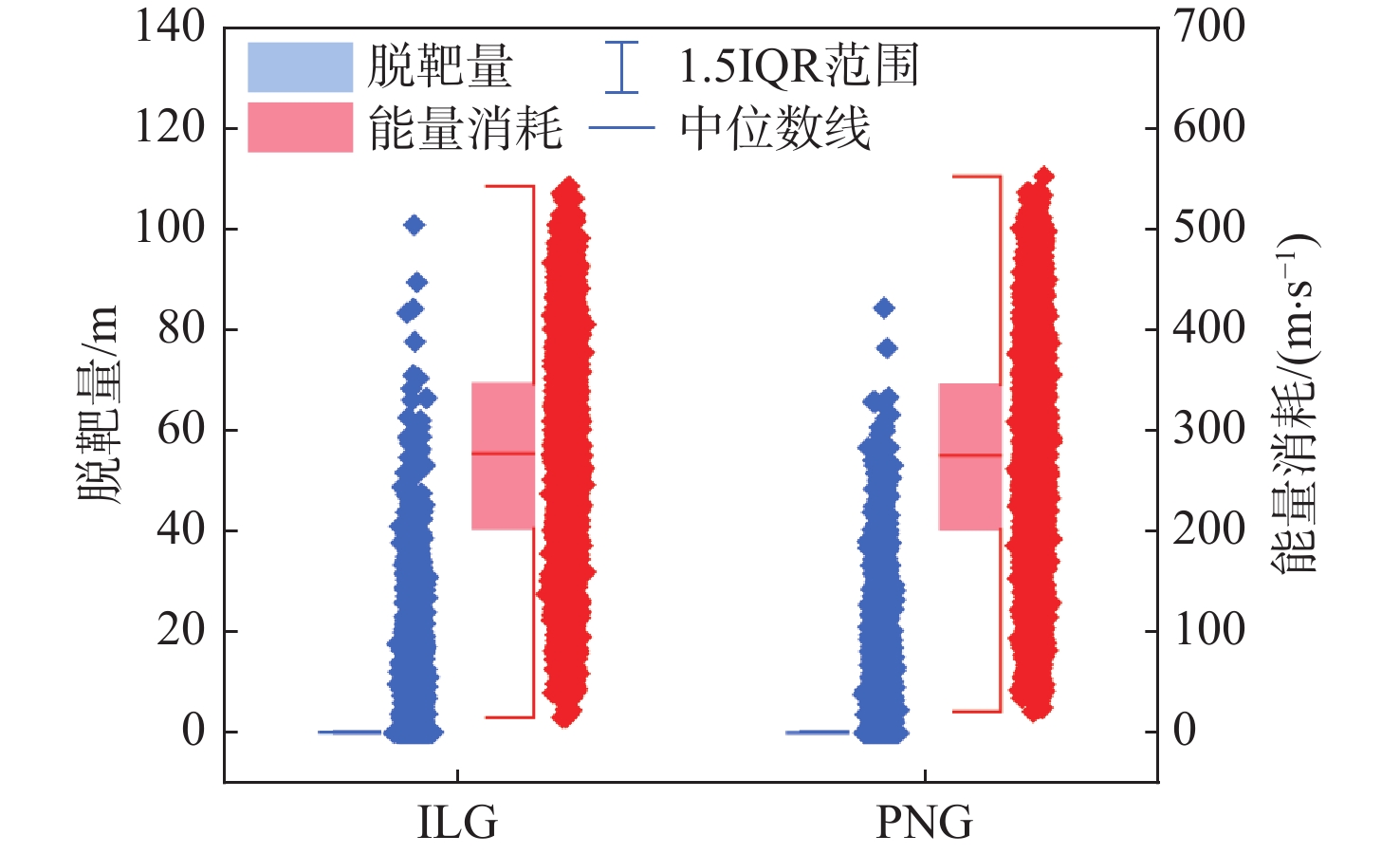
图 10 ILG和PNG能量消耗和脱靶量箱线
Figure 10. Boxplot of energy consumption and miss distance for ILG and PNG
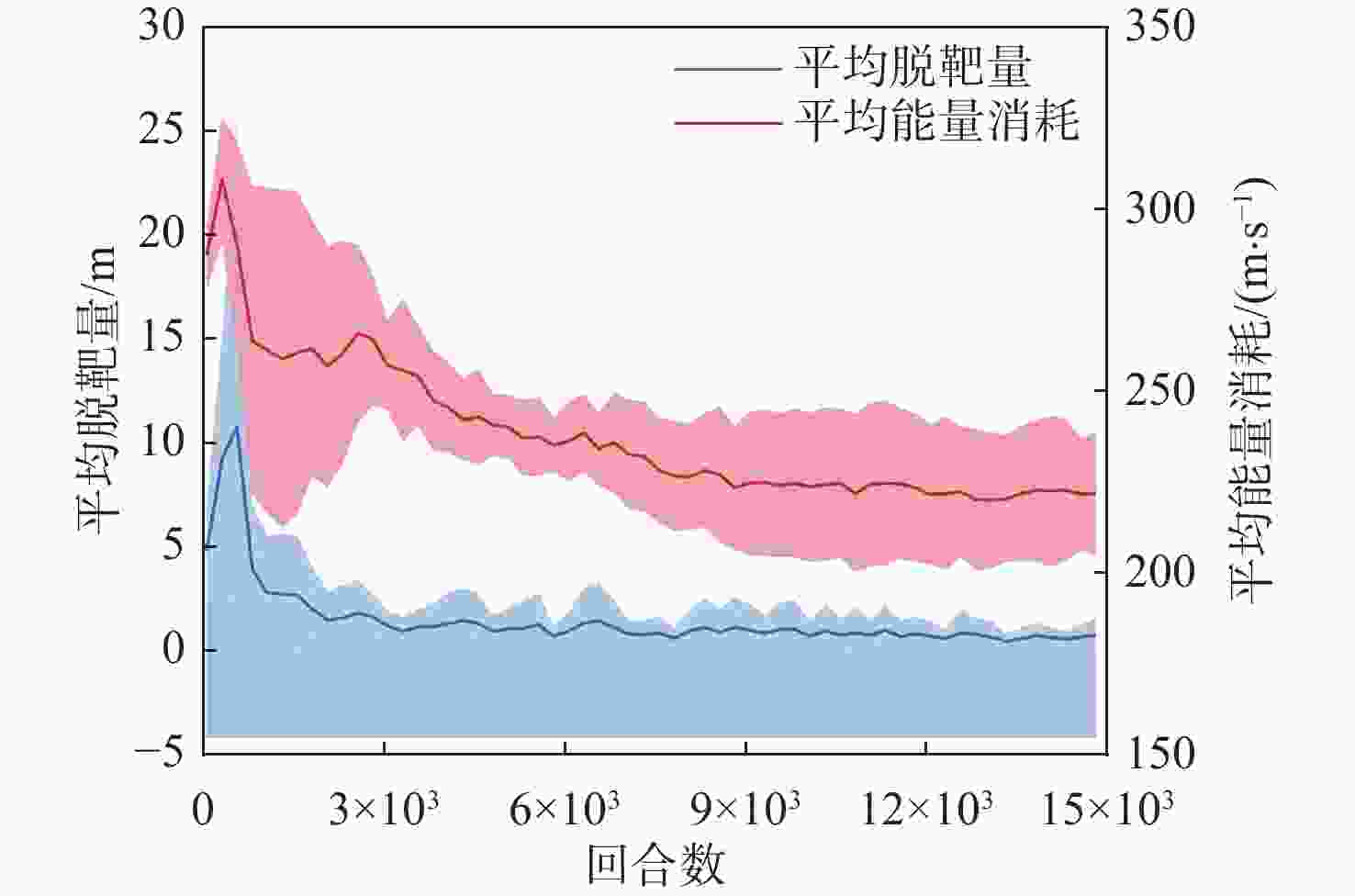
图 12 脱靶量和能量消耗随训练代数变化曲线
Figure 12. Miss distance and energy consumption curves varing with training epoch
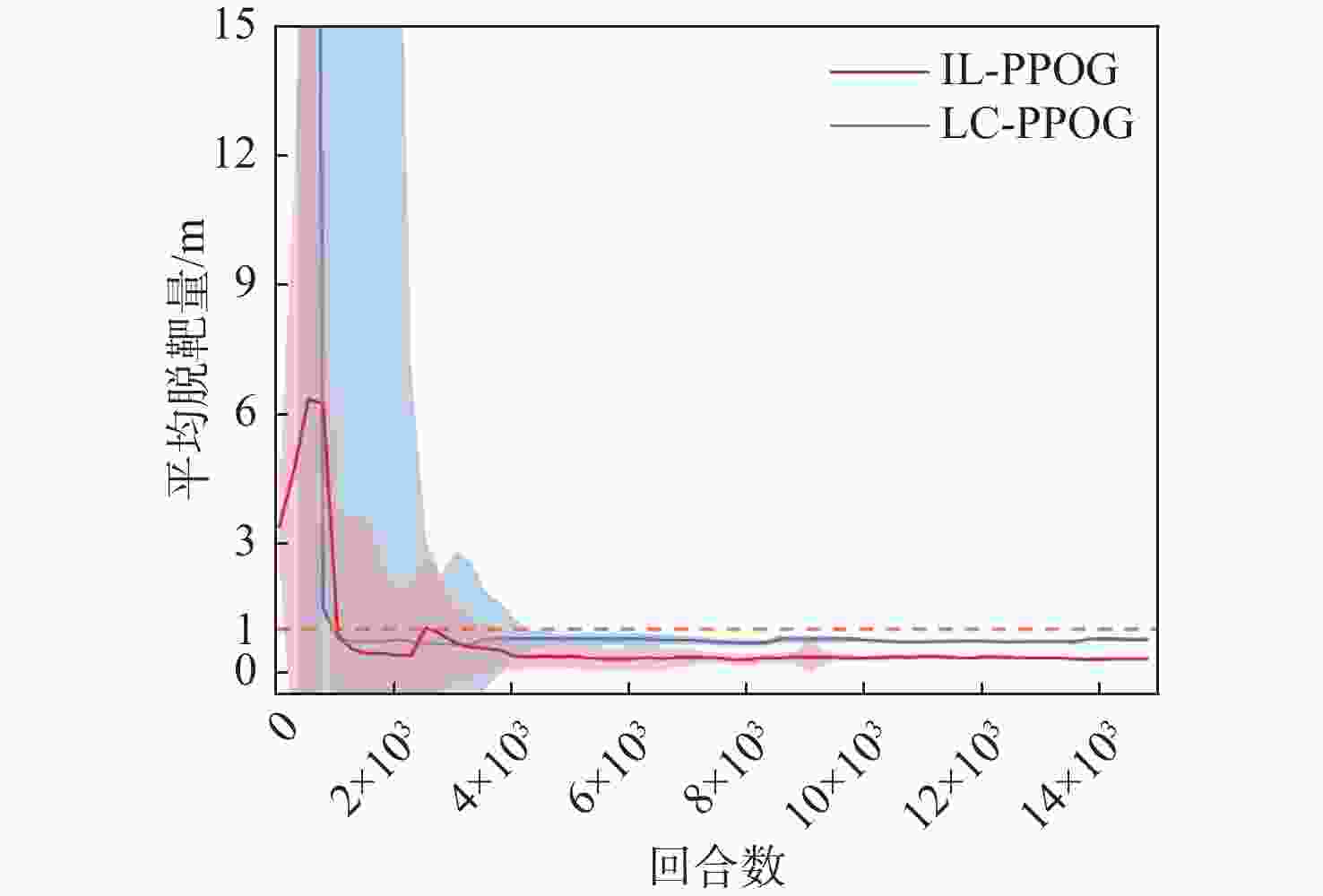
图 13 不同算法脱靶量随训练代数变化曲线
Figure 13. Curves of miss distance versus training epoch for different algorithms
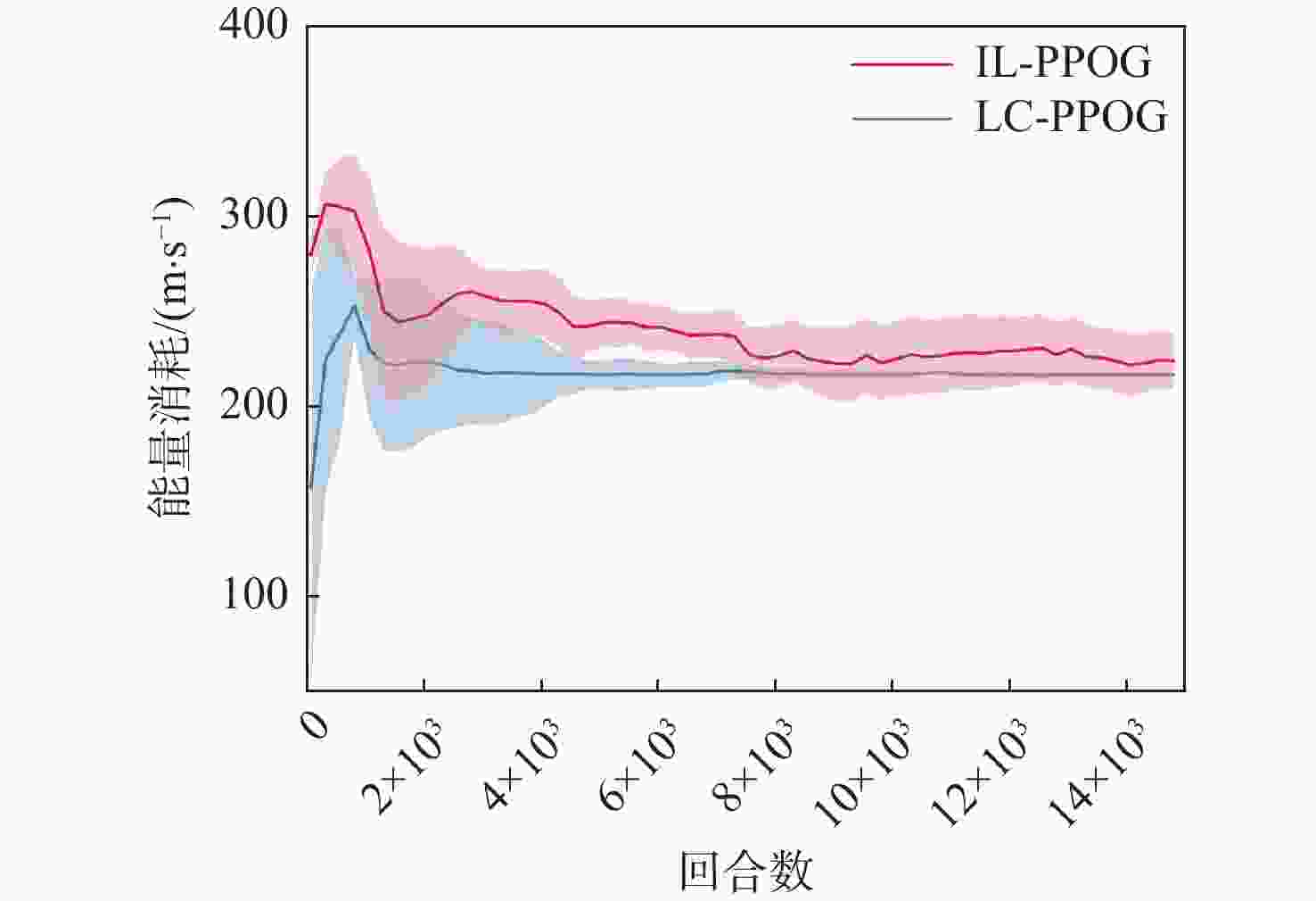
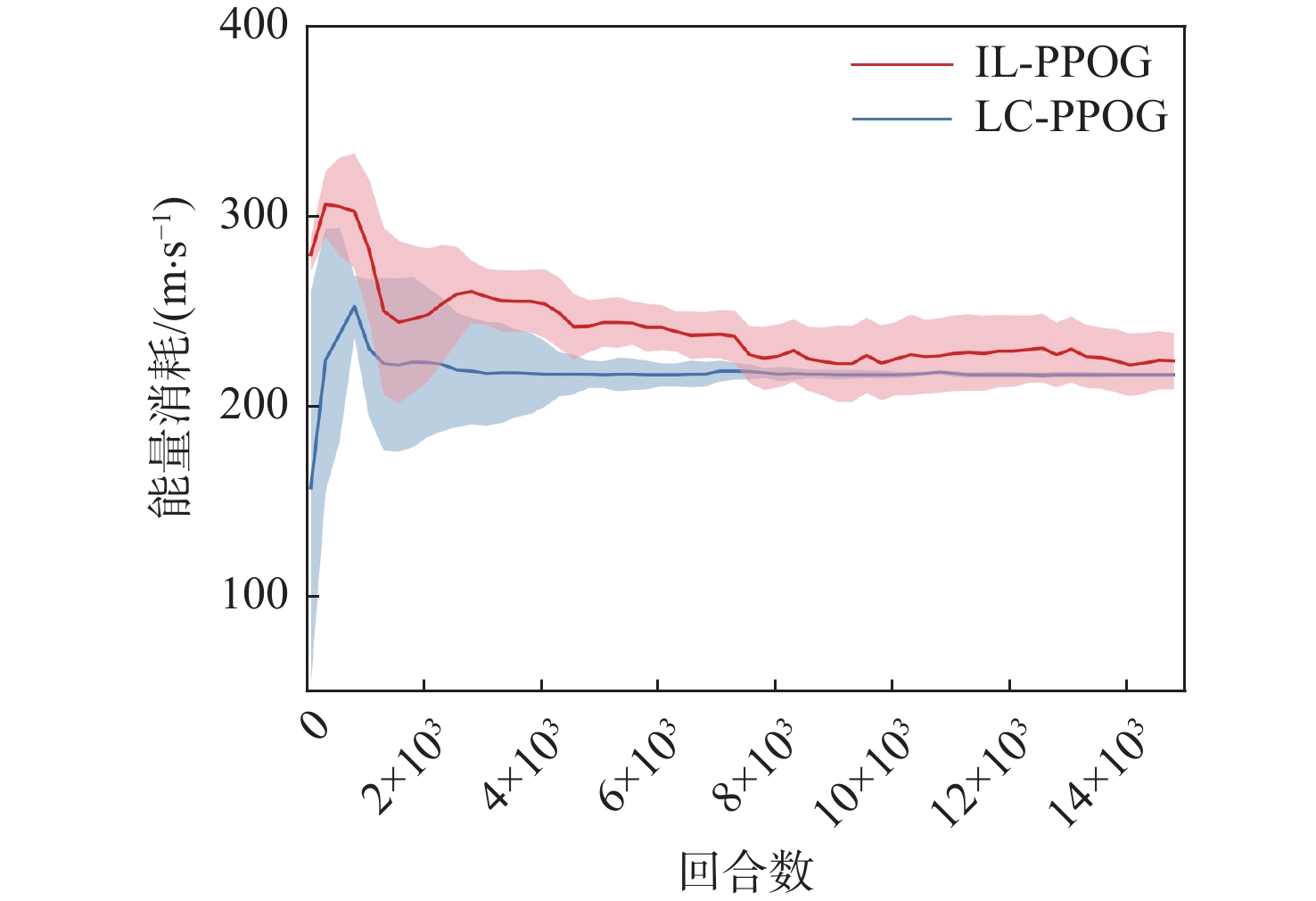
图 14 不同算法能量消耗随训练代数变化曲线
Figure 14. Curves of energy consumption versus training epoch for different algorithms
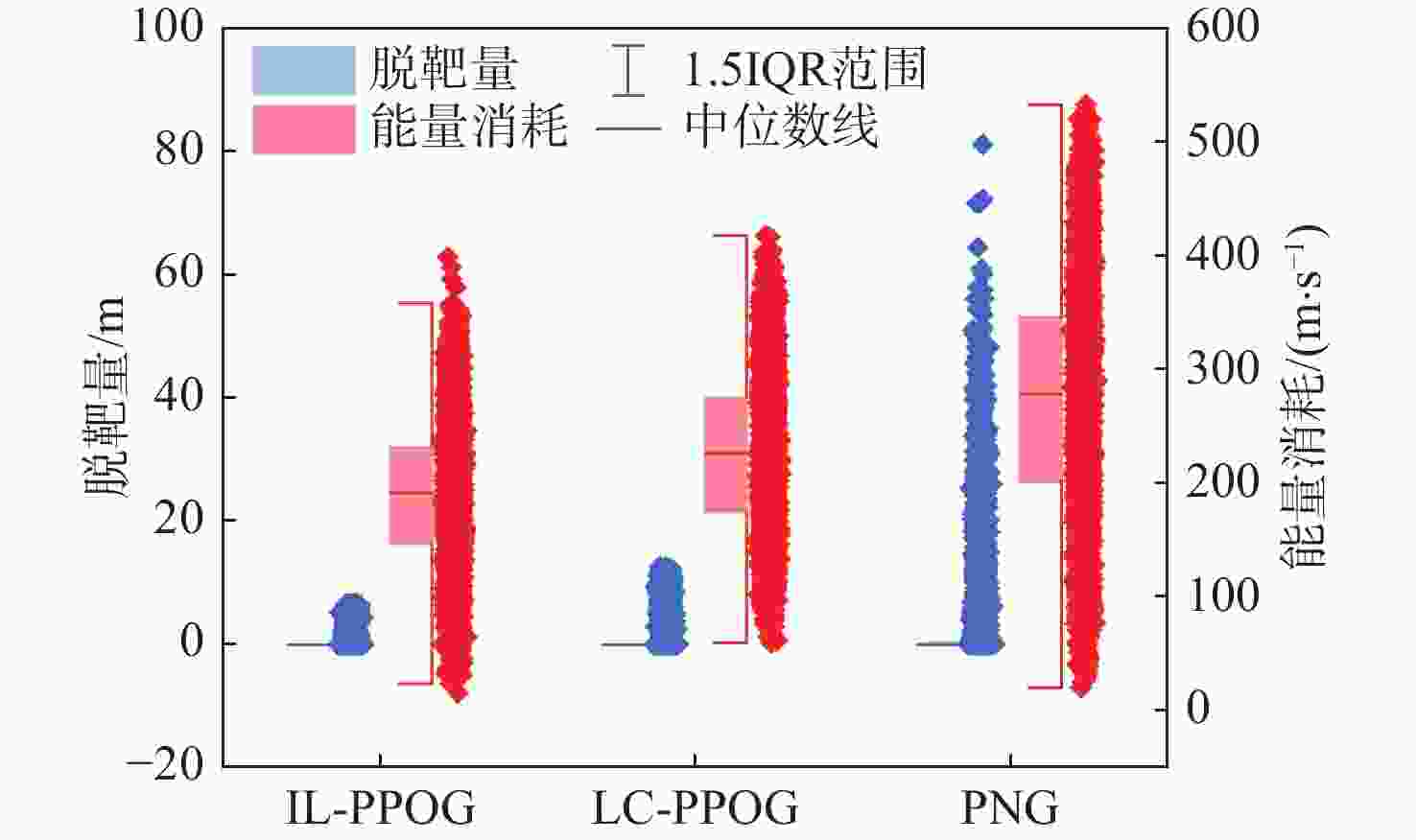
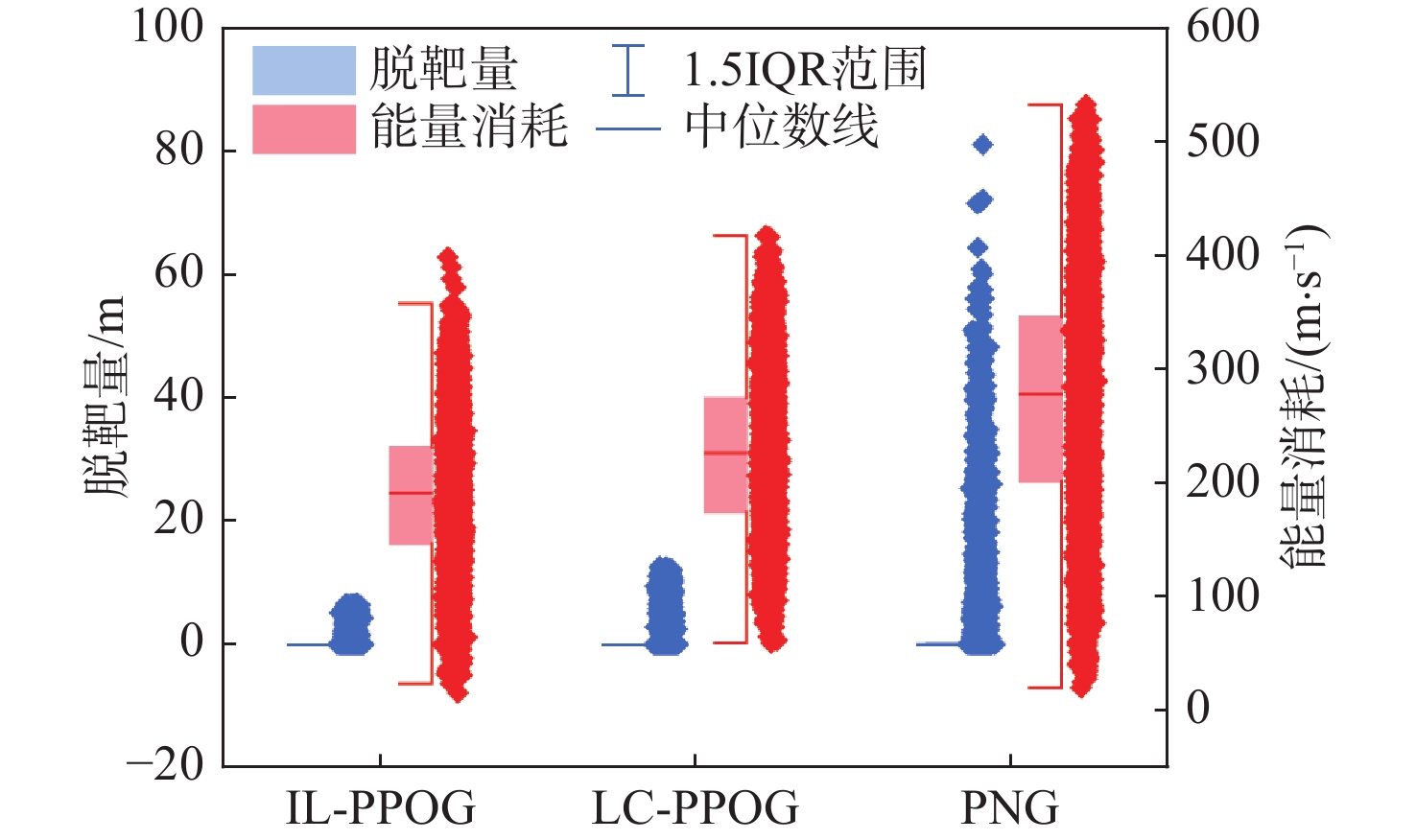
图 15 不同算法能量消耗和脱靶量箱线
Figure 15. Boxplots of energy consumption and miss distance for different algorithms
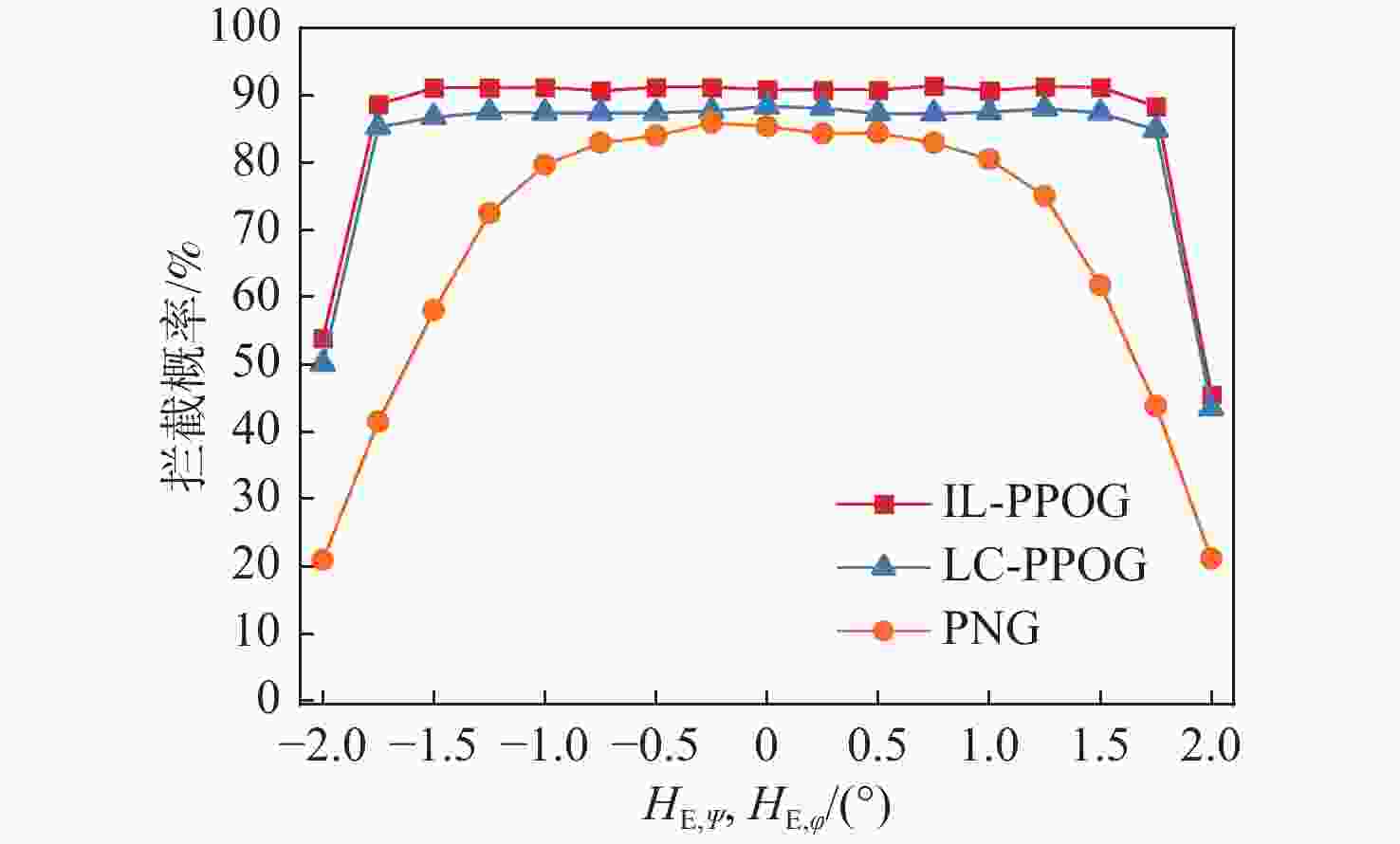
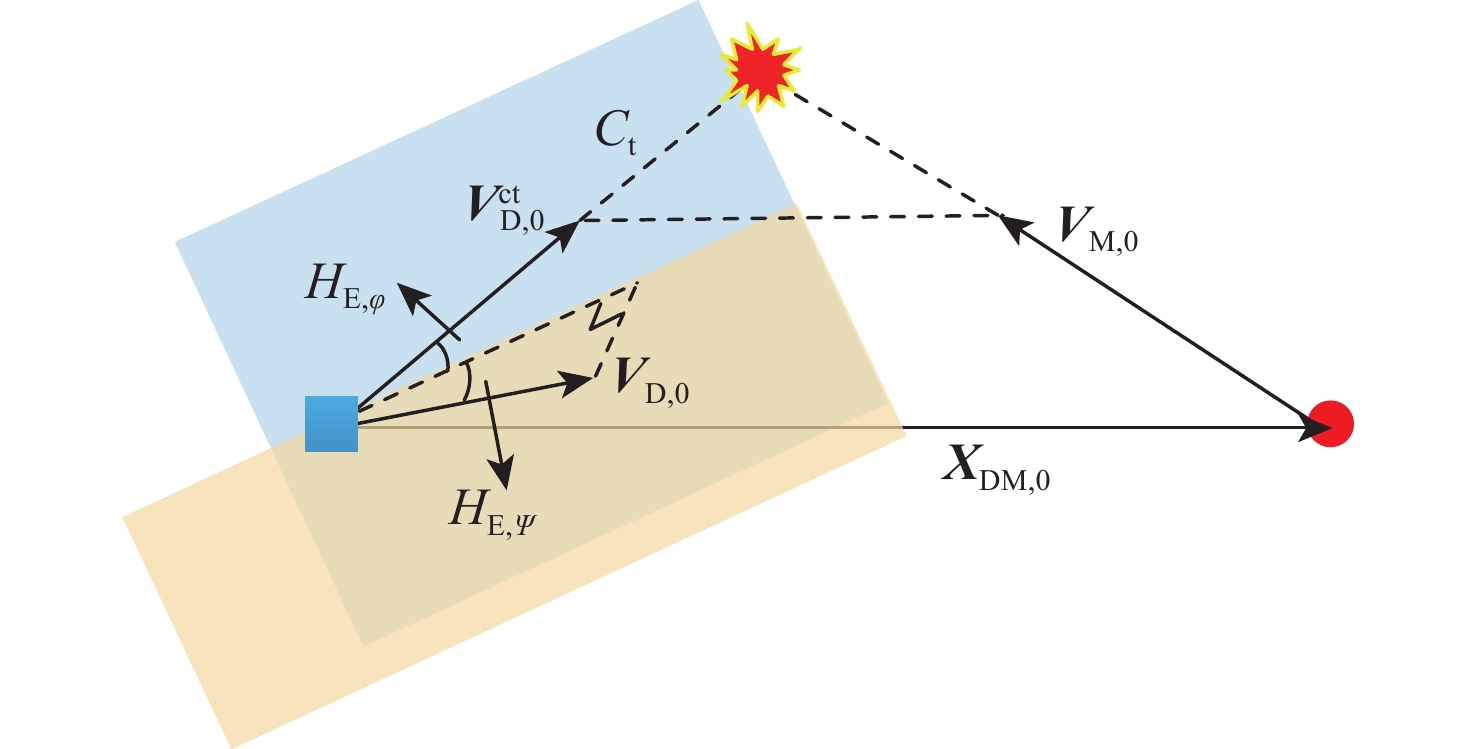
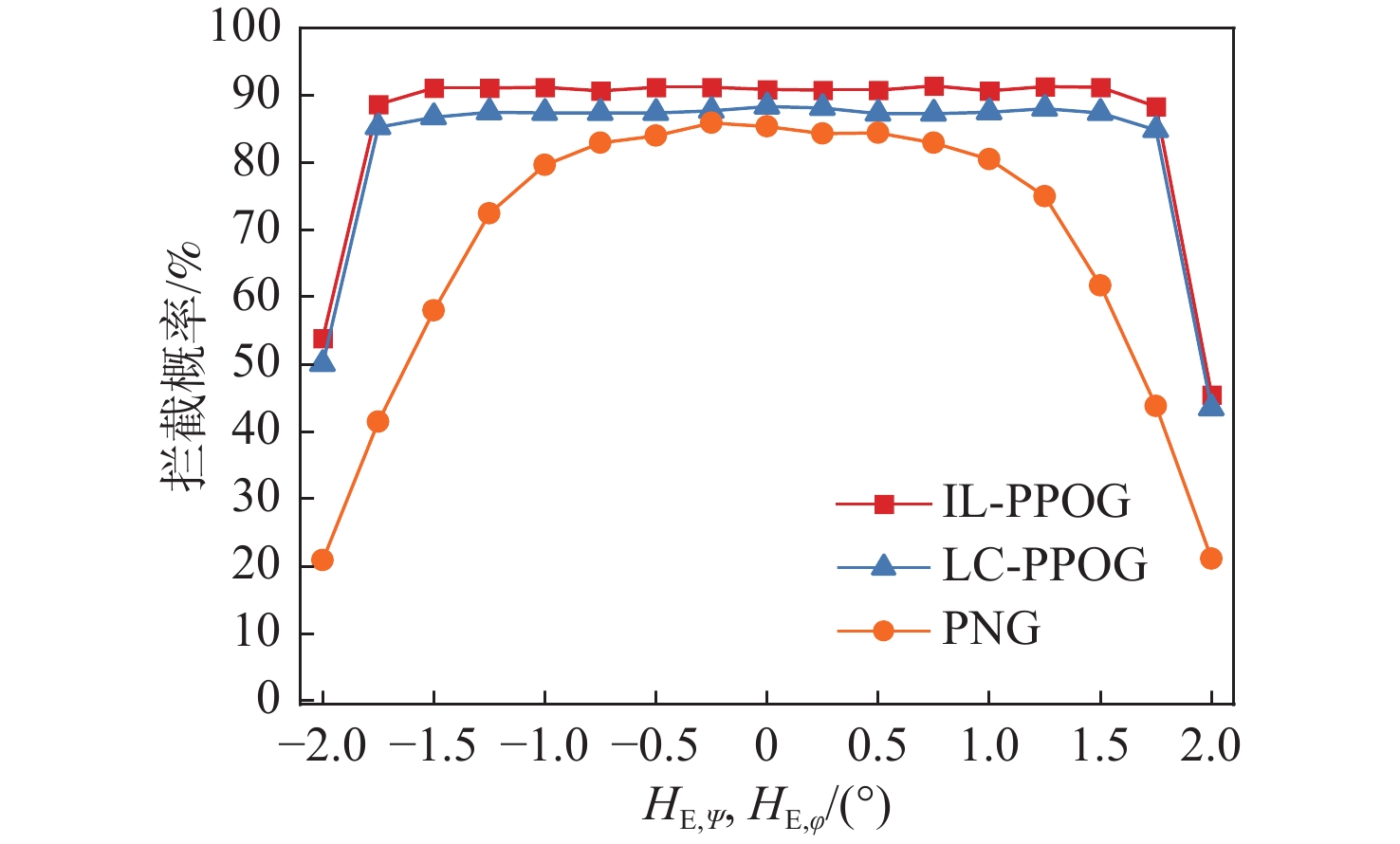
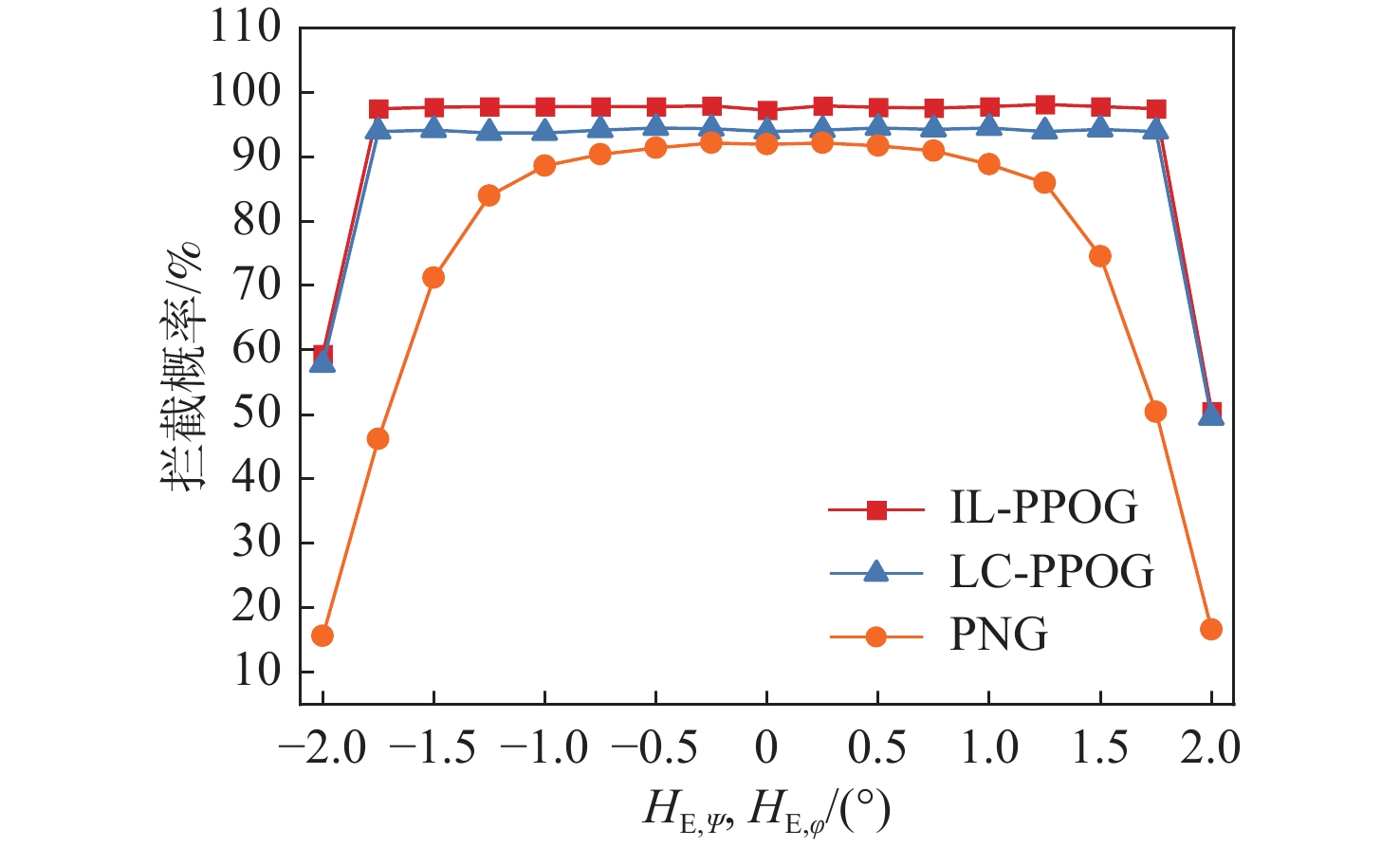
图 16 不同$ H_{\text{E},\psi }^{} $和$ H_{\text{E},\varphi }^{} $情况下拦截概率
Figure 16. Interception probability under different $ H_{\text{E},\psi }^{} $ and $ H_{\text{E},\varphi }^{} $ conditions
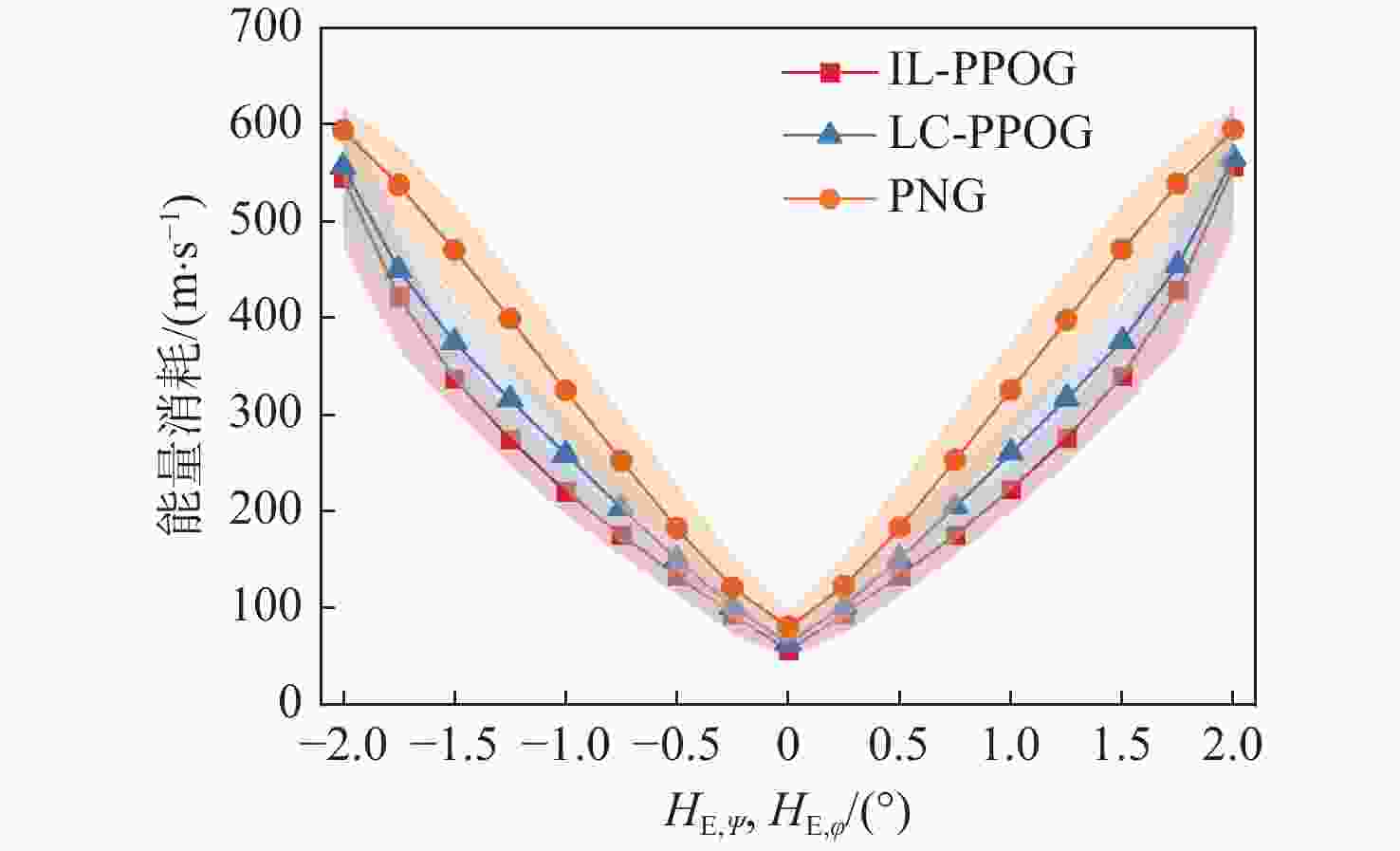
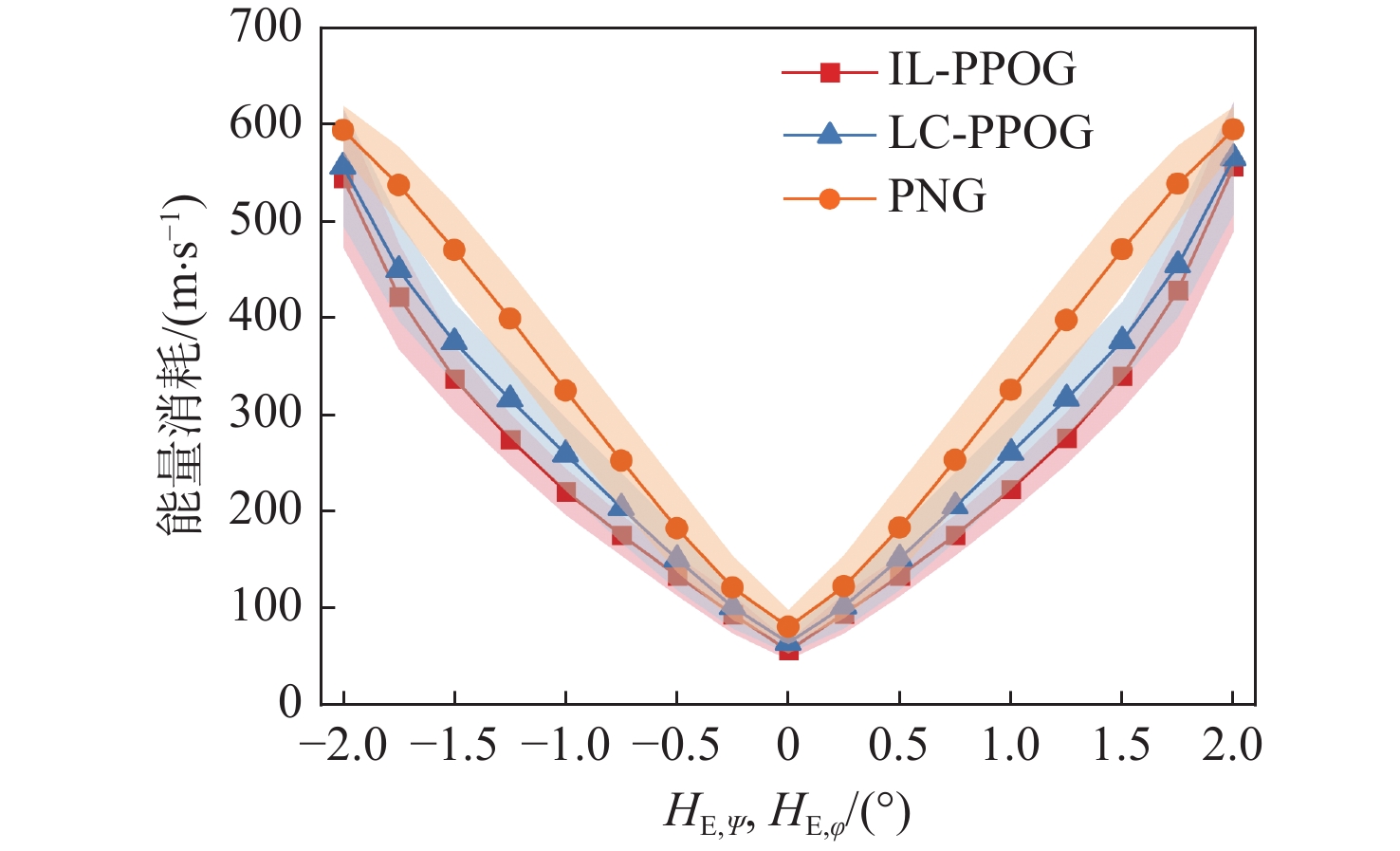
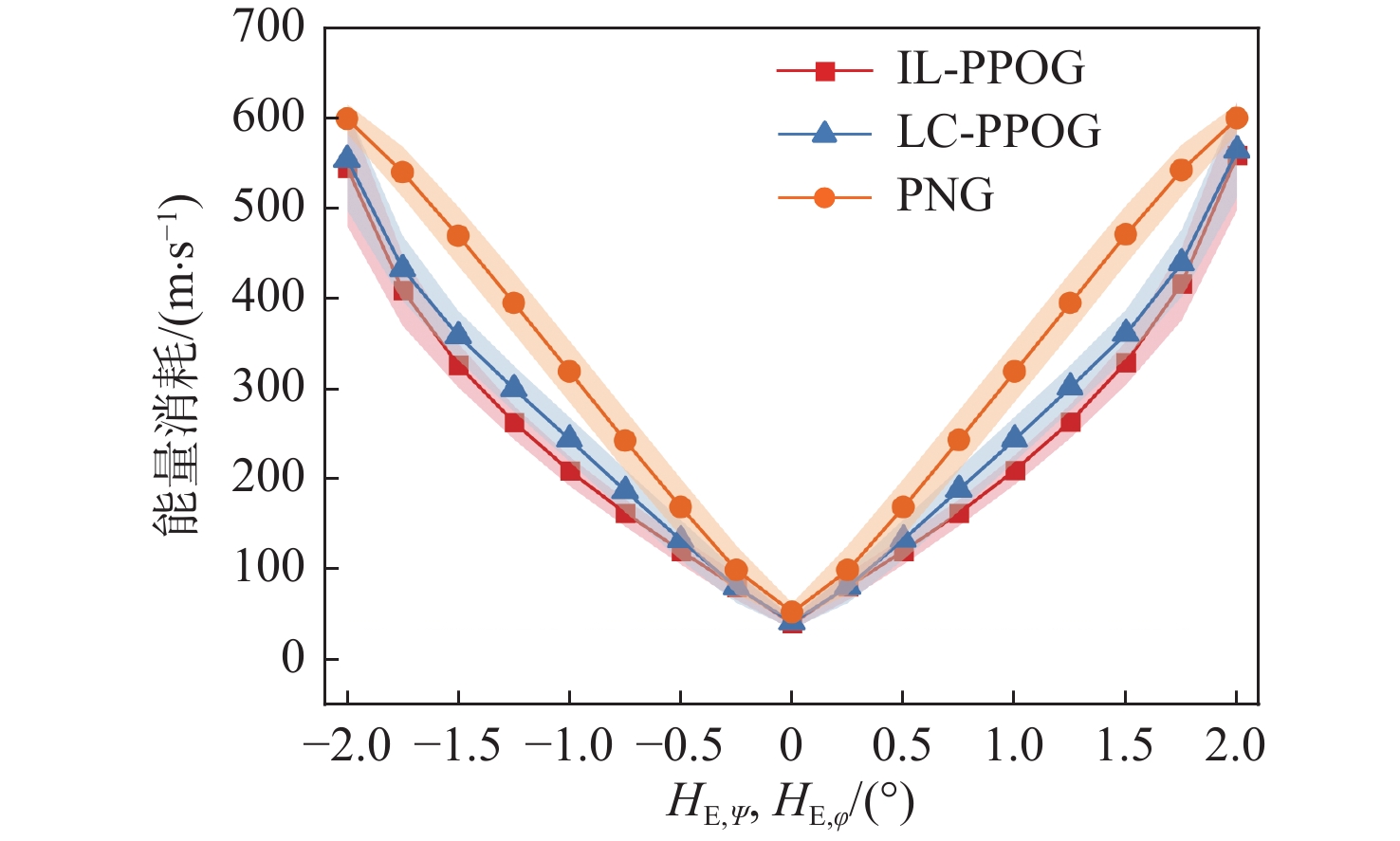
图 17 不同$ H_{\text{E},\psi }^{} $和不同$ H_{\text{E},\varphi }^{} $情况下能量消耗
Figure 17. Energy consumption under different $ H_{\text{E},\psi }^{} $ and different $ H_{\text{E},\varphi }^{} $ conditions
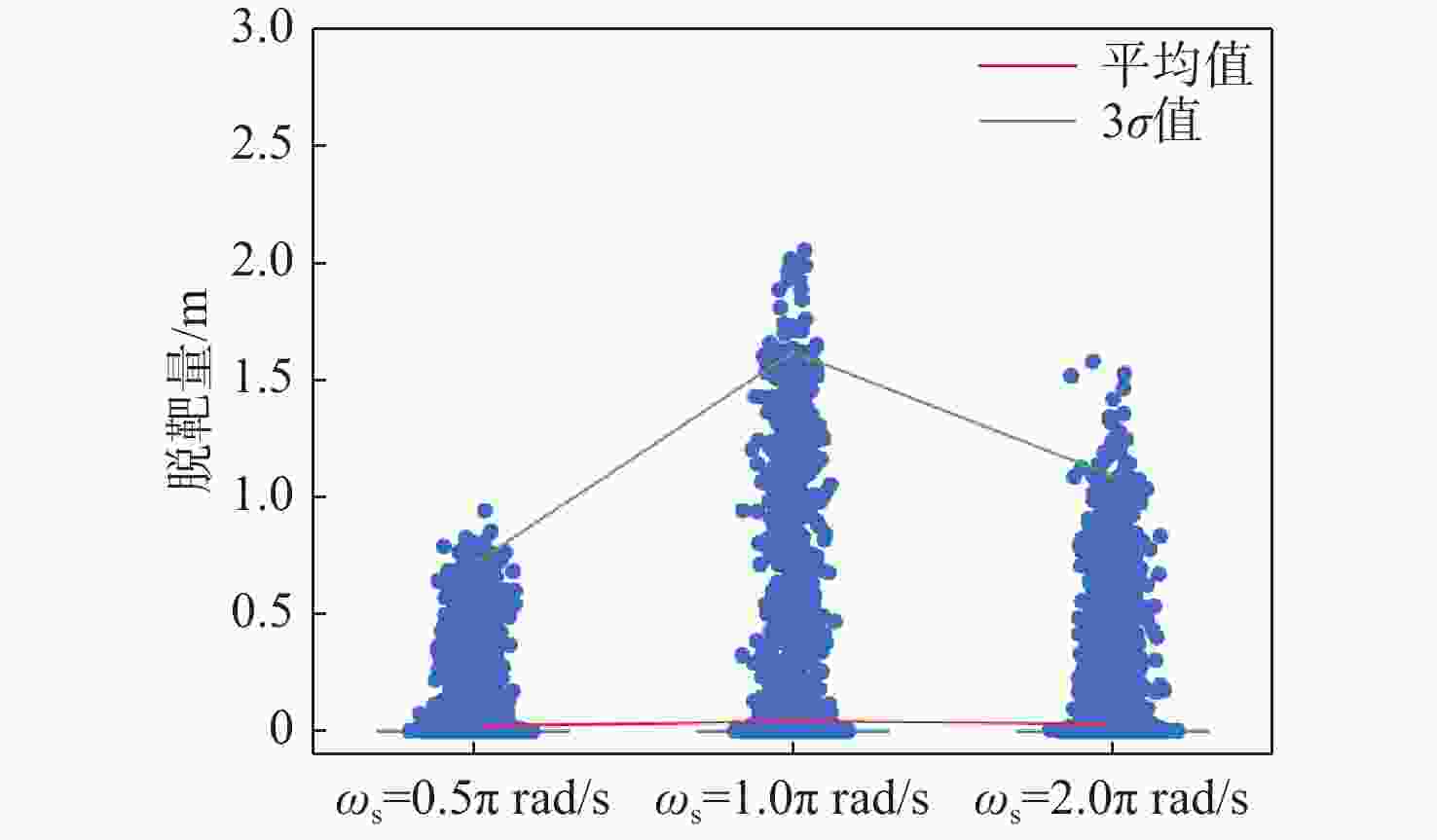
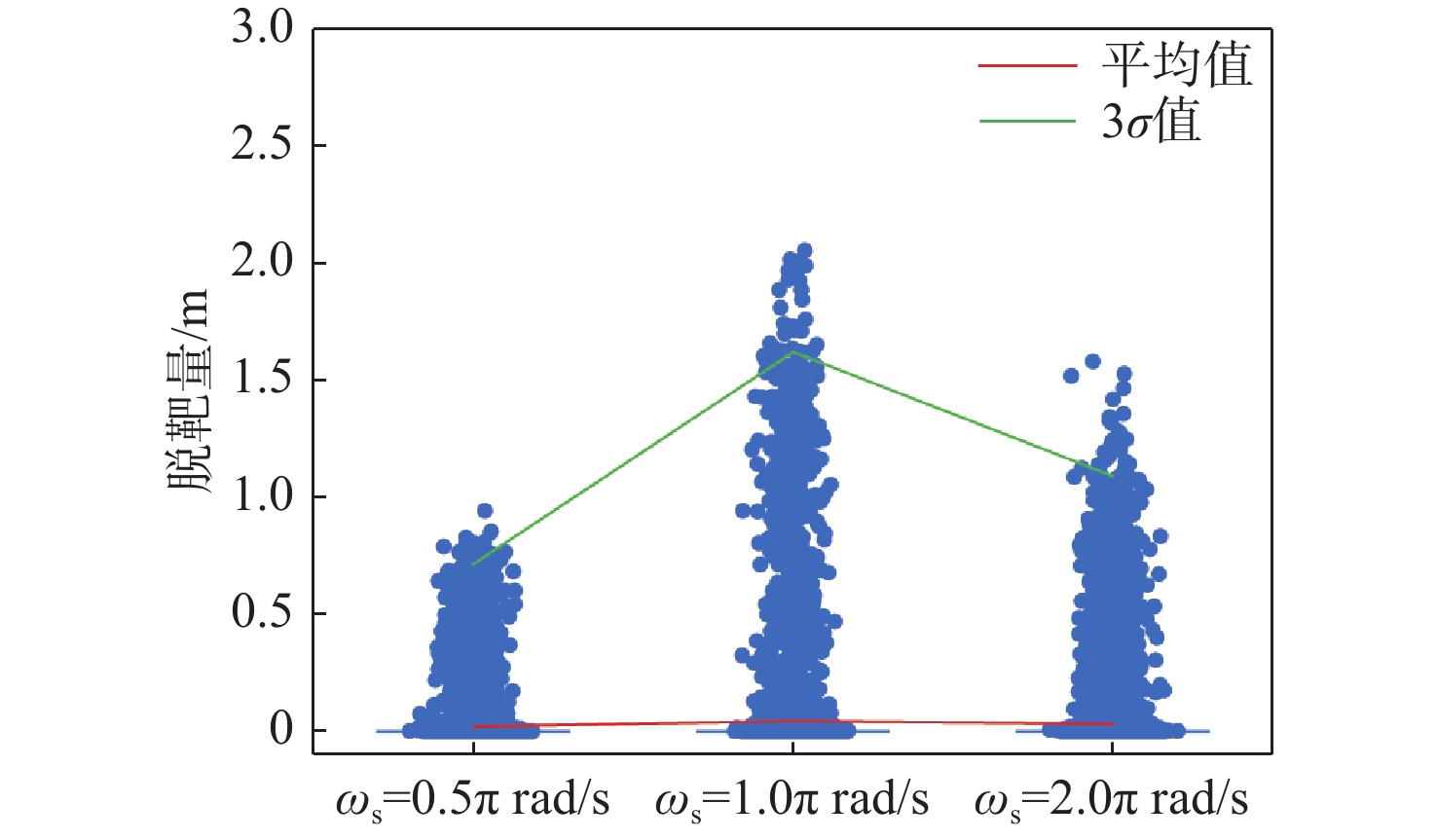
图 22 IL-PPOG在不同$ {\omega }_{\text{s}} $情况下脱靶量
Figure 22. Miss distance of IL-PPOG under different $ {\omega }_{\text{s}} $
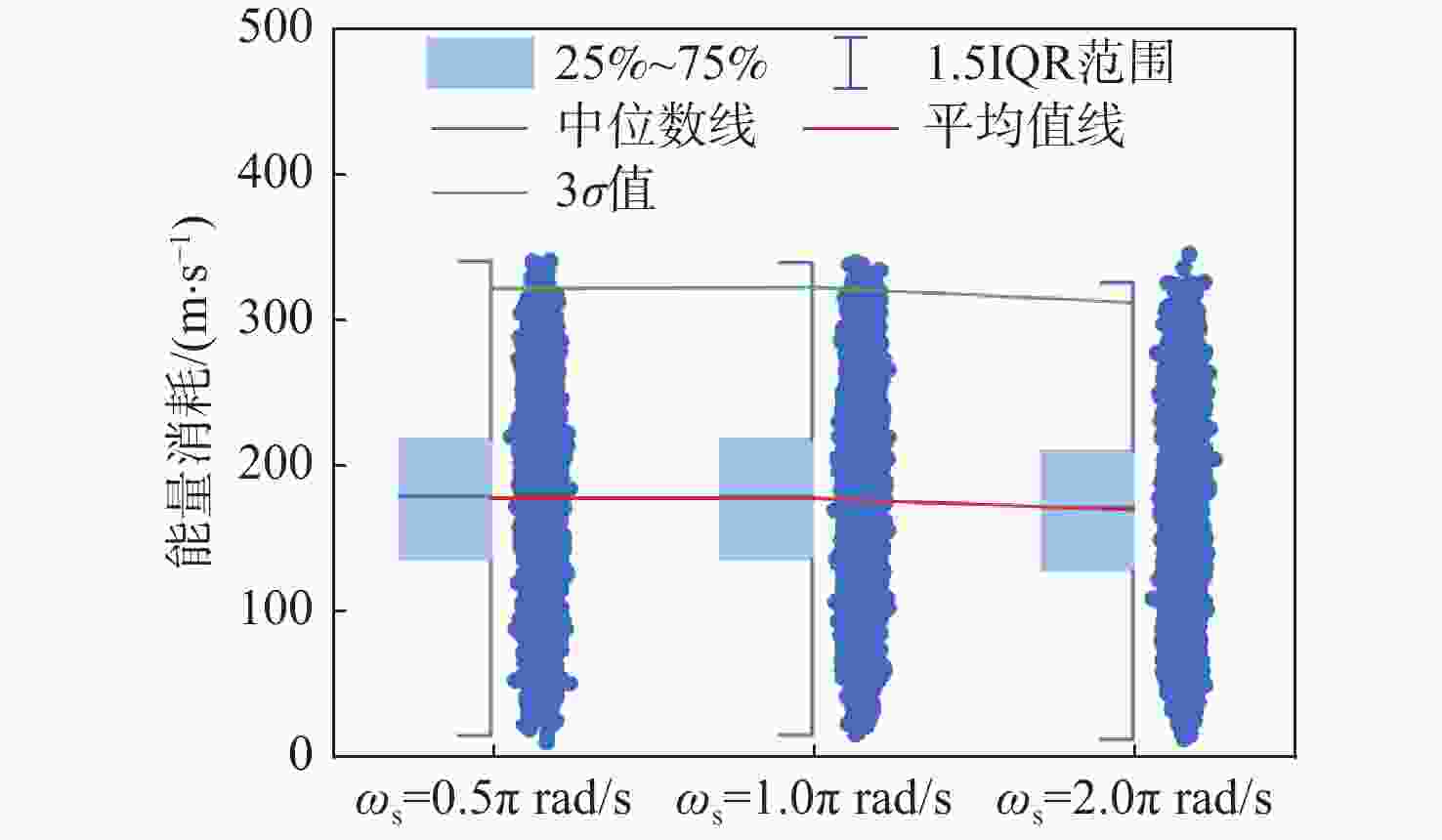
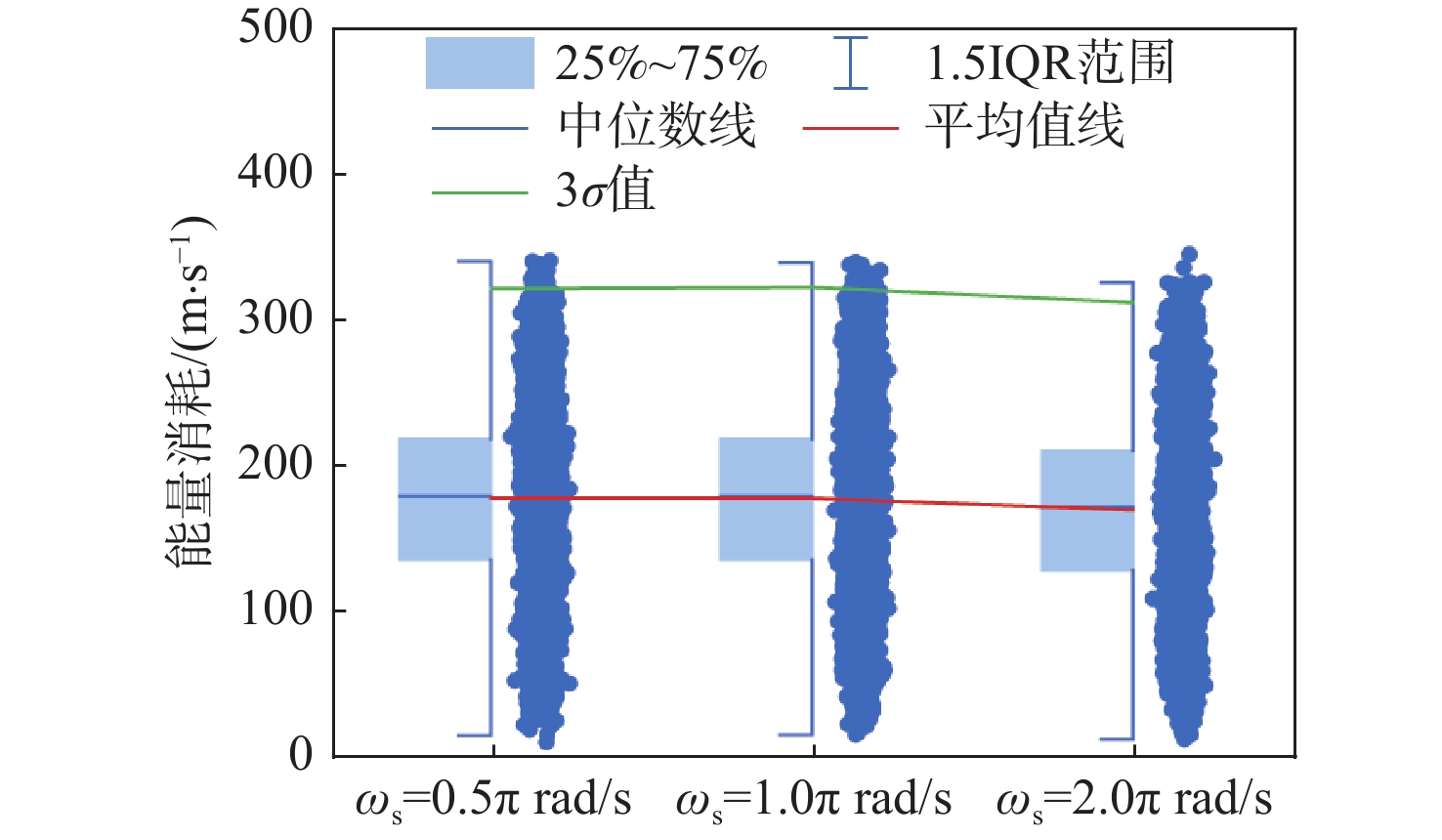
图 23 IL-PPOG在不同$ {\omega }_{\text{s}} $情况下能量消耗
Figure 23. Energy consumption of IL-PPOG under different $ {\omega }_{\text{s}} $
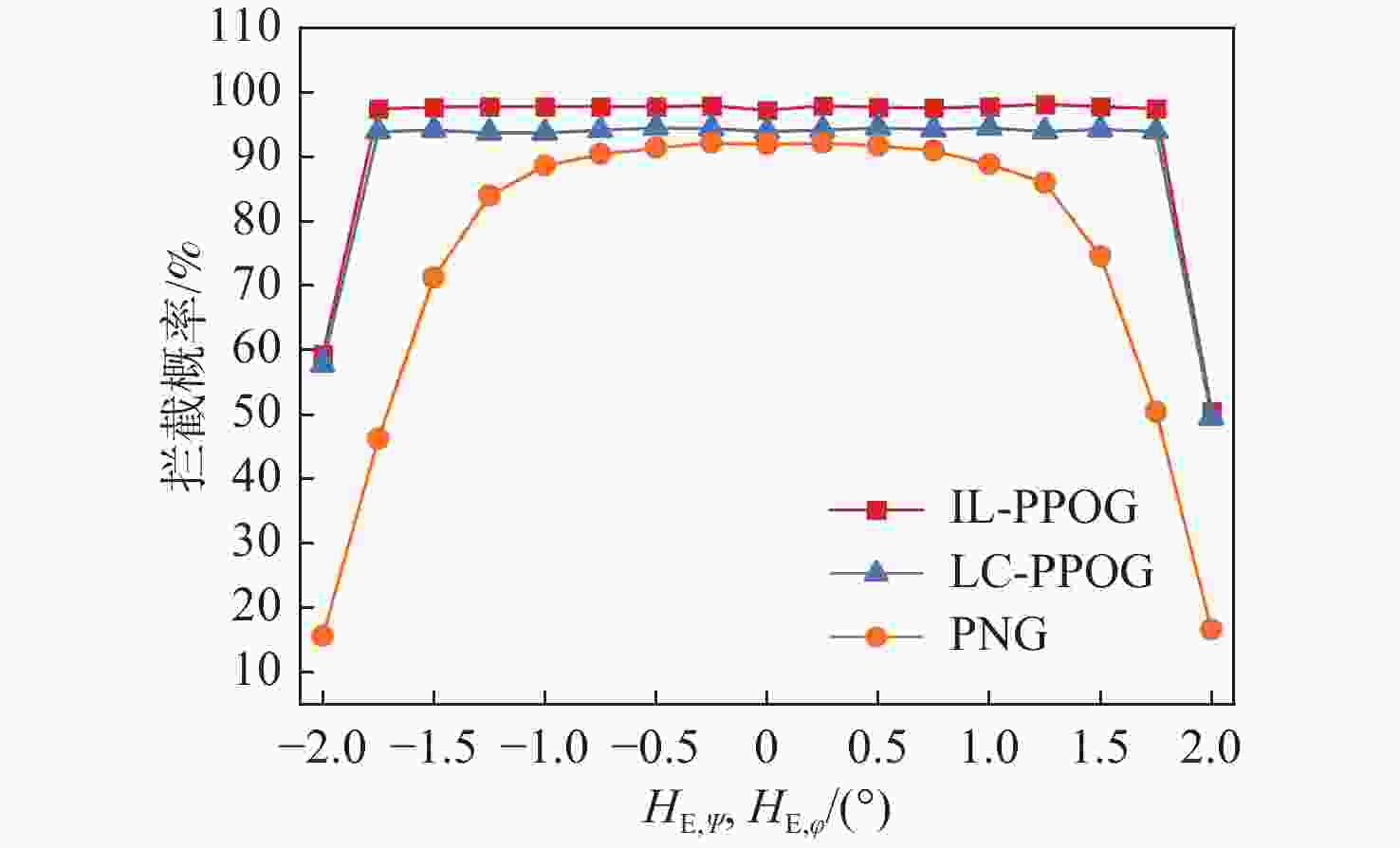
图 24 不同$ {H}_{\text{E,}\psi } $和$ {H}_{\text{E,}\varphi } $情况下拦截概率($ {\omega }_{\text{s}}={\text{π}} $ rad/s)
Figure 24. Interception probability under different $ {H}_{\text{E,}\psi } $ and $ {H}_{\text{E,}\varphi } $ conditions ($ {\omega }_{\text{s}}={\text{π}} $ rad/s)
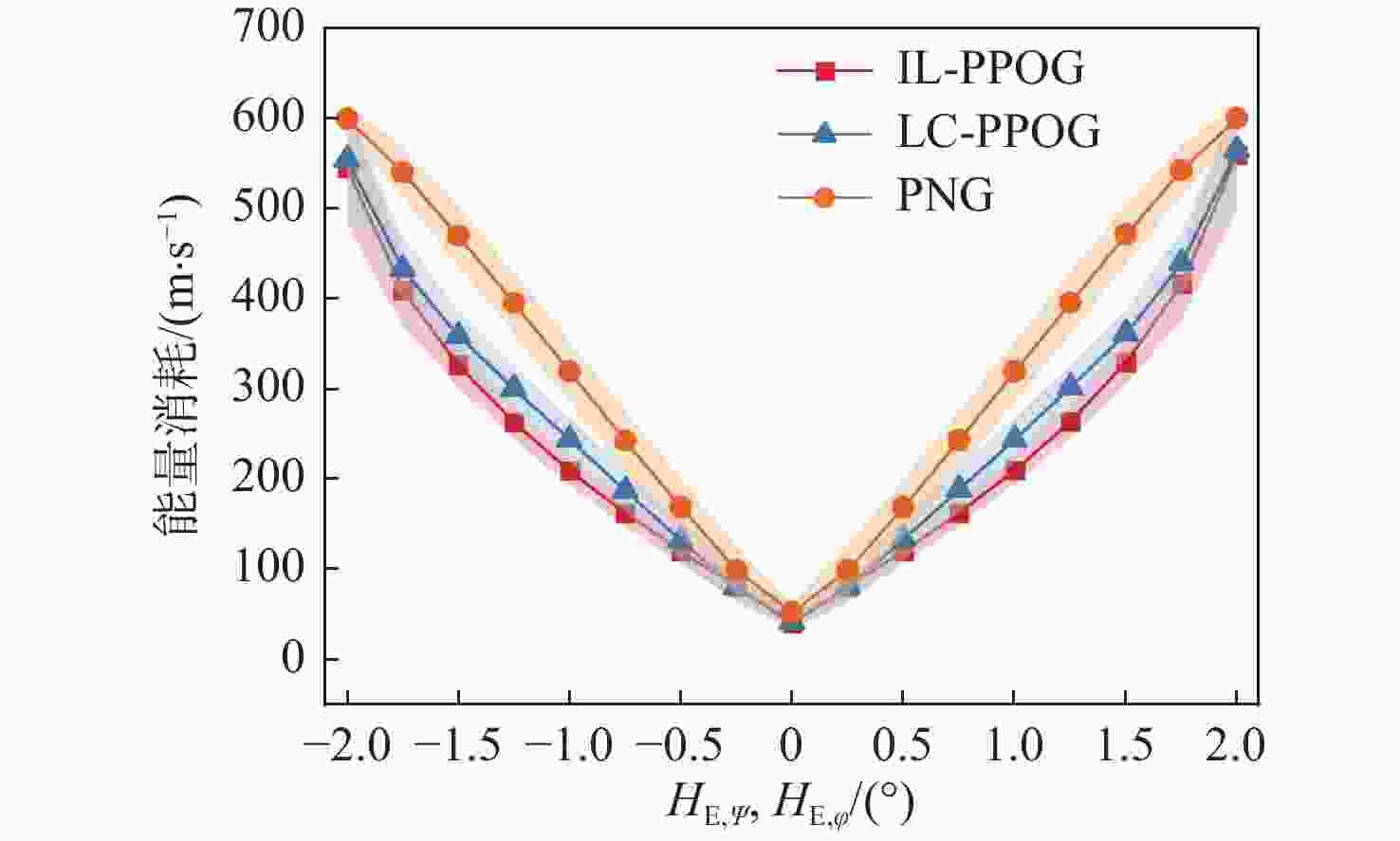
图 25 不同$ {H}_{\text{E,}\psi } $和$ {H}_{\text{E,}\varphi } $情况下能量消耗($ {\omega }_{\text{s}}={\text{π}} $ rad/s)
Figure 25. Energy consumption under different $ {H}_{\text{E,}\psi } $ and $ {H}_{\text{E,}\varphi } $ conditions ($ {\omega }_{\text{s}}={\text{π}} $ rad/s)
表 1 训练场景参数边界
Table 1. Training scenario parameter boundaries
边界 $ \left\|{\boldsymbol{V}}_{\text{M,0}}\right\| $/
(m·s−1)$ {\mathit{\Theta }}_{\text{M},0} $/
(°)$ {\sigma }_{\text{M},0} $/
(°)$ \Delta {\alpha }_{\text{MD},0} $/
(°)$ \Delta {\beta }_{\text{MD},0} $/
(°)$ \left\|{\boldsymbol{V}}_{\text{D},\text{0}}\right\| $/
(m·s−1)最小值 6 500.0 −5.0 0.0 −5.0 −10.0 6 000.0 最大值 7 000.0 5.0 90.0 −1.0 10.0 6 500.0  下载: 导出CSV
下载: 导出CSV
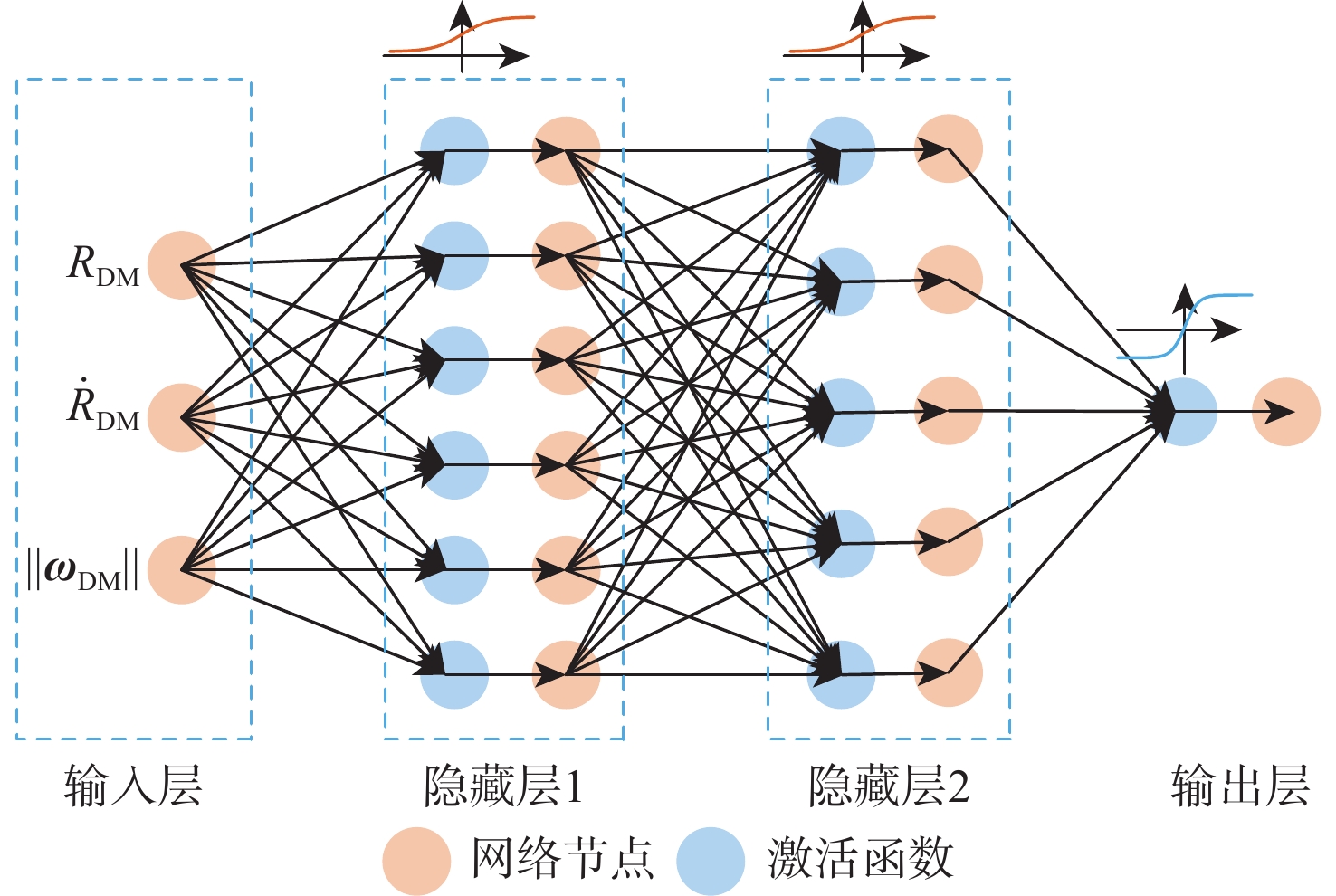
表 2 PPO网络结构和参数
Table 2. PPO network structure and parameters
网络 层级 单元数 激活函数 策略网络 输入层 3 隐藏层1 6 S-Sigmoid 隐藏层2 5 S-Sigmoid 输出层 1 Linear 价值网络 输入层 3 隐藏层1 6 S-Sigmoid 隐藏层2 5 S-Sigmoid 输出层 1 Linear
下载: 导出CSV
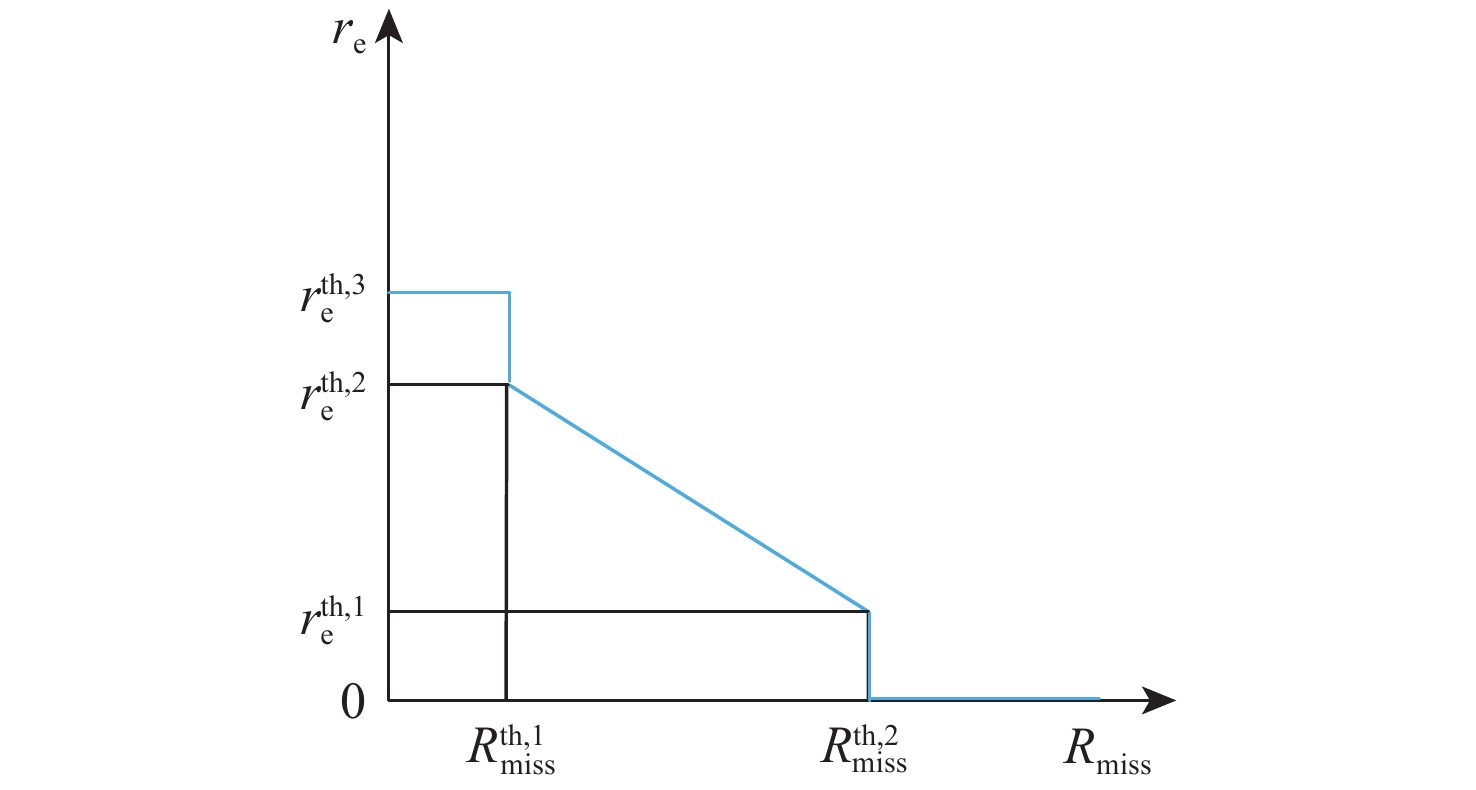
表 3 超参数设计
Table 3. Hyper-parameter design
超参数 数值 超参数 数值 $ {N}_{\text{IL}} $ 10 000 $ {\beta }_{\text{lr,0}} $ 0.001 $ N_{\text{epoch}}^{\text{IL}} $ 1 000 $ {N}_{\text{epoch}} $ 300 $ {k}_{\text{s}} $ 0.1 $ {N}_{\text{update}} $ 1 000 $ r_{\text{e}}^{\text{th},1} $ 10.0 $ {N}_{\text{rollout}} $ 50 $ r_{\text{e}}^{\text{th},2} $ 50.0 $ {N}_{\text{m}} $ 4.0 g $ r_{\text{e}}^{\text{th},3} $ 51.0 $ \Delta {T}_{\text{m}} $ /s 1.0 $ R_{\text{miss}}^{\text{th,1}} $ 1.0 $ {a}_{\max } $ 4.0 g $ R_{\text{miss}}^{\text{th,2}} $ 10.0 $ H_{\text{E},\psi }^{\min } $ /(°) −1.5 $ \left| {\mathcal{D}} \right| $ 75 000 $ H_{\text{E},\psi }^{\max } $ /(°) 1.5 $ \left| \mathcal{B}\right| $ 256 $ H_{\text{E},\varphi }^{\min } $ /(°) −1.5 $ \gamma $ 0.99 $ {H}_{\text{E},\varphi } $ /(°) 1.5 $ \lambda $ 0.95 $ \left\|{\boldsymbol{X}}_{\text{MD,0}}\right\| $ /km 200.0 $ {c}_{\text{VF}} $ 0.25 $ \delta _{{R}_{\text{DM}}}^{} $ /% 1.0 $ {c}_{\text{s}} $ 0.01 $ \delta _{{\dot{R}}_{\text{DM}}}^{} $ /% 0.5 $ {g}_{\max } $ 0.5 $ \delta _{\left\|{\text{ω}}_{\text{DM}}\right\|}^{} $ /% 3.0 $ \varepsilon $ 0.2 $ \sigma _{a}^{} $ /% 5/3 $ {\alpha }_{\text{lr,0}} $ 0.001
下载: 导出CSV
-
[1] GUELMAN M. A qualitative study of proportional navigation[J]. IEEE Transactions on Aerospace and Electronic Systems, 1971, AES-7(4): 637-643. [2] GHAWGHAWE S N, GHOSE D. Pure proportional navigation against time-varying target manoeuvres[J]. IEEE Transactions On Aerospace and Electronic Systems, 1996, 32(4): 1336-1347. [3] CHEN W X, GAO C S, JING W X. Proximal policy optimization guidance algorithm for intercepting near-space maneuvering targets[J]. Aerospace Science and Technology, 2023, 132: 108031. [4] CHEN Z, SHIMA T. Nonlinear optimal guidance for intercepting a stationary target[J]. Journal of Guidance, Control, and Dynamics, 2019, 42(11): 2418-2431. [5] HE L, YAN X D, TANG S. Spiral-diving trajectory optimization for hypersonic vehicles by second-order cone programming[J]. Aerospace Science and Technology, 2019, 95: 105427. [6] HE L, YAN X D. Adaptive terminal guidance law for spiral-diving maneuver based on virtual sliding targets[J]. Journal of Guidance, Control, and Dynamics, 2018, 41(7): 1591-1601. [7] YANUSHEVSKY R. Analysis of optimal weaving frequency of maneuvering targets[J]. Journal of Spacecraft and Rockets, 2004, 41(3): 477-479. [8] QIU X Q, LAI P, GAO C S, et al. Recorded recurrent deep reinforcement learning guidance laws for intercepting endoatmospheric maneuvering missiles[J]. Defence Technology, 2024, 31: 457-470. [9] KUMAR S R, RAO S, GHOSE D. Nonsingular terminal sliding mode guidance with impact angle constraints[J]. Journal of Guidance, Control, and Dynamics, 2014, 37(4): 1114-1130. [10] EBRAHIMI B, BAHRAMI M, ROSHANIAN J. Optimal sliding-mode guidance with terminal velocity constraint for fixed-interval propulsive maneuvers[J]. Acta Astronautica, 2008, 62(10-11): 556-562. [11] HE S M, LIN D F, WANG J. Robust terminal angle constraint guidance law with autopilot lag for intercepting maneuvering targets[J]. Nonlinear Dynamics, 2015, 81(1): 881-892. [12] ASHER R B, MATUSZEWSKI J P. Optimal guidance with maneuvering targets[J]. Journal of Spacecraft and Rockets, 1974, 11(3): 204-206. [13] CHO H, RYOO C K, TSOURDOS A, et al. Optimal impact angle control guidance law based on linearization about collision triangle[J]. Journal of Guidance, Control, and Dynamics, 2014, 37(3): 958-964. [14] LIANG H Z, WANG J Y, WANG Y H, et al. Optimal guidance against active defense ballistic missiles via differential game strategies[J]. Chinese Journal of Aeronautics, 2020, 33(3): 978-989. [15] SHALUMOV V. Optimal cooperative guidance laws in a multiagent target-missile-defender engagement[J]. Journal of Guidance, Control, and Dynamics, 2019, 42(9): 1993-2006. [16] LIANG H, WANG J, LIU J, et al. Guidance strategies for interceptor against active defense spacecraft in two-on-two engagement[J]. Aerospace Science and Technology, 2020, 96: 105529. [17] XU Z Y, CHEN Y K, XU Z X. Optimal guidance and collision avoidance for docking with the rotating target spacecraft[J]. Advances in Space Research, 2019, 63(10): 3223-3234. [18] ZHENG Y, CHEN Z, SHAO X M, et al. Time-optimal guidance for intercepting moving targets with impact-angle constraints[J]. Chinese Journal of Aeronautics, 2022, 35(7): 157-167. [19] GAUDET B, FURFARO R. Missile homing-phase guidance law design using reinforcement learning[C]//Proceedings of the AIAA Guidance, Navigation, and Control Conference. Minneapolis, Reston: AIAA, 2012: 4470. [20] LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[EB/OL]. (2019-07-15)[2024-01-10]. https://doi.org/10.48550/arXiv.1509.02971. [21] MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing Atari with deep reinforcement learning[EB/OL]. (2013-12-19)[2024-01-05]. https://doi.org/10.48550/arXiv.1312.5602. [22] SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL]. (2017-08-28)[2024-01-12]. https://doi.org/10.48550/arXiv.1707.06347. [23] HAARNOJA T, ZHOU A, ABBEEL P, et al. Soft actor-critic: off-policy maximum entropy deep reinforcement learning with a stochastic actor[EB/OL]. (2018-08-08)[2024-01-13]. https://doi.org/10.48550/arXiv.1801.01290. [24] SILVER D, HUANG A, MADDISON C J, et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016, 529(7587): 484-489. [25] SILVER D, SCHRITTWIESER J, SIMONYAN K, et al. Mastering the game of Go without human knowledge[J]. Nature, 2017, 550(7676): 354-359. [26] MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533. [27] VINYALS O, BABUSCHKIN I, CZARNECKI W M, et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning[J]. Nature, 2019, 575(7782): 350-354. [28] WANG X, WANG S, LIANG X X, et al. Deep reinforcement learning: a survey[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(4): 5064-5078. [29] ARULKUMARAN K, DEISENROTH M P, BRUNDAGE M, et al. Deep reinforcement learning: a brief survey[J]. IEEE Signal Processing Magazine, 2017, 34(6): 26-38. [30] GAUDET B, LINARES R, FURFARO R. Deep reinforcement learning for six degree-of-freedom planetary landing[J]. Advances in Space Research, 2020, 65(7): 1723-1741. [31] GAUDET B, LINARES R, FURFARO R. Adaptive guidance and integrated navigation with reinforcement meta-learning[J]. Acta Astronautica, 2020, 169: 180-190. [32] FURFARO R, SCORSOGLIO A, LINARES R, et al. Adaptive generalized ZEM-ZEV feedback guidance for planetary landing via a deep reinforcement learning approach[J]. Acta Astronautica, 2020, 171: 156-171. [33] SCORSOGLIO A, FURFARO R, LINARES R, et al. Relative motion guidance for near-rectilinear lunar orbits with path constraints via actor-critic reinforcement learning[J]. Advances in Space Research, 2023, 71(1): 316-335. [34] GONG X P, CHEN W C, CHEN Z Y. All-aspect attack guidance law for agile missiles based on deep reinforcement learning[J]. Aerospace Science and Technology, 2022, 127: 107677. [35] HONG D, KIM M, PARK S, et al. Study on reinforcement learning-based missile guidance law[J]. Applied Sciences, 2020, 10(18): 6567. [36] YUAN H, LI D X. Deep reinforcement learning for rendezvous guidance with enhanced angles-only observability[J]. Aerospace Science and Technology, 2022, 129: 107812. [37] HE X J, CHEN Z H, JIA F, et al. Guidance law based on zero effort miss and Q-learning algorithm[C]//Proceedings of the Seventh Symposium on Novel Photoelectronic Detection Technology and Applications. Bellinham: SPIE, 2021: 117. [38] HE X J, WU M Y, CHEN Z H, et al. Guidance law based on deep Q network algorithm[J]. Journal of Physics: Conference Series, 2022, 2235(1): 012107. [39] HE S M, SHIN H S, TSOURDOS A. Computational missile guidance: a deep reinforcement learning approach[J]. Journal of Aerospace Information Systems, 2021, 18(8): 571-582. [40] DU M J, PENG C, MA J J. Deep reinforcement learning based missile guidance law design for maneuvering target interception[C]//Proceedings of the 2021 40th Chinese Control Conference. Piscataway: IEEE Press, 2021: 3733-3738. [41] 张秦浩, 敖百强, 张秦雪. Q-learning强化学习制导律[J]. 系统工程与电子技术, 2020, 42(2): 414-419.ZHANG Q H, AO B Q, ZHANG Q X. Reinforcement learning guidance law of Q-learning[J]. Systems Engineering and Electronics, 2020, 42(2): 414-419(in Chinese). [42] 刘扬, 何泽众, 王春宇, 等. 基于DDPG算法的末制导律设计研究[J]. 计算机学报, 2021, 44(9): 1854-1865.LIU Y, HE Z Z, WANG C Y, et al. Terminal guidance law design based on DDPG algorithm[J]. Chinese Journal of Computers, 2021, 44(9): 1854-1865(in Chinese). [43] TANG J, BAI Z H, LIANG Y G, et al. An exoatmospheric homing guidance law based on deep Q network[J]. International Journal of Aerospace Engineering, 2022, 2022(1): 1544670. [44] LIANG Y G, TANG J, BAI Z H, et al. Homing guidance law design against maneuvering targets based on DDPG[J]. International Journal of Aerospace Engineering, 2023, 2023(1): 4188037. [45] WANG W W, WU M Y, CHEN Z H, et al. Integrated guidance-and-control design for three-dimensional interception based on deep-reinforcement learning[J]. Aerospace, 2023, 10(2): 167. [46] LUO W L, CHEN L, LIU K X, et al. Optimizing constrained guidance policy with minimum overload regularization[J]. IEEE Transactions on Circuits and Systems I: Regular Papers, 2022, 69(7): 2994-3005. [47] GAUDET B, FURFARO R, LINARES R. Reinforcement learning for angle-only intercept guidance of maneuvering targets[J]. Aerospace Science and Technology, 2020, 99: 105746. [48] GAUDET B, FURFARO R, LINARES R, et al. Reinforcement metalearning for interception of maneuvering exoatmospheric targets with parasitic attitude loop[J]. Journal of Spacecraft and Rockets, 2021, 58(2): 386-399. [49] 邱潇颀, 高长生, 荆武兴. 拦截大气层内机动目标的深度强化学习制导律[J]. 宇航学报, 2022, 43(5): 685-695.QIU X Q, GAO C S, JING W X. Deep reinforcement learning guidance law for intercepting endo-atmospheric maneuvering targets[J]. Journal of Astronautics, 2022, 43(5): 685-695 (in Chinese). [50] 陈文雪, 高长生, 荆武兴. 拦截机动目标的信赖域策略优化制导算法[J]. 航空学报, 2023, 44(11): 327596.CHEN W X, GAO C S, JING W X. Trust region policy optimization guidance algorithm for intercepting maneuvering target[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(11): 327596(in Chinese). [51] FUJIMOTO S, VAN HOOF H, MEGER D. Addressing function approximation error in actor-critic methods[C]//Proceedings of the International Conference on Machine Learning. Cambridge: PMLR, 2018: 1587-1596. [52] JOHN SCHULMAN S L P M. Trust region policy optimization[EB/OL]. (2017-04-20)[2024-03-15]. https://doi.org/10.48550/arXiv.1502.05477. [53] SCHULMAN J, MORITZ P, LEVINE S, et al. High-dimensional continuous control using generalized advantage estimation[EB/OL]. (2018-08-20)[2024-03-16]. https://doi.org/10.48550/arXiv.1506.02438. [54] XIE J W, CHEN W C. Switching logic design for divert and attitude control system of exoatmospheric kill vehicle[C]//Proceedings of the 2017 IEEE International Conference on Cybernetics and Intelligent Systems and IEEE Conference on Robotics, Automation and Mechatronics. Piscataway: IEEE Press, 2017: 194-200. [55] GOLDMAN R. Understanding quaternions[J]. Graphical Models, 2011, 73(2): 21-49. [56] XIAN Y, REN L L, XU Y J, et al. Impact point prediction guidance of ballistic missile in high maneuver penetration condition[J]. Defence Technology, 2023, 26: 213-230. [57] KARLIK B, OLGAC A V. Performance analysis of various activation functions in generalized MLP architectures of neural networks[J]. International Journal of Artificial Intelligence and Expert Systems, 2011, 1(4): 111-122. [58] YU J, HESTHAVEN J S. Flowfield reconstruction method using artificial neural network[J]. AIAA Journal, 2019, 57(2): 482-498. [59] ENGSTROM L, ILYAS A, SANTURKAR S, et al. Implementation matters in deep policy gradients: a case study on PPO and TRPO[EB/OL]. (2020-05-25)[2024-04-20]. https://doi.org/10.48550/arXiv.2005.12729. [60] ZIPFEL P H, SCHIEHLEN W. Modeling and simulation of aerospace vehicle dynamics[J]. Applied Mechanics Reviews, 2001, 54(6): B101-B102. [61] SAXE A M, MCCLELLAND J L, GANGULI S. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks[EB/OL]. (2014-02-19)[2024-03-22]. https://doi.org/10.48550/arXiv.1312.6120. [62] 任乐亮, 鲜勇, 李少朋, 等. 基于改进二阶优化器并行学习的弹道导弹神经网络落点预测方法[J]. 航空学报, 2023, 44(14): 227-245.REN L L, XIAN Y, LI S P, et al. A neural network model for impact point prediction of ballistic missile based on improved second-order optimizer with parallel learning[J]. Acta Aeronautica et Astronautica Sinica, 2023, 44(14): 227-245(in Chinese). -

 下载:
下载:
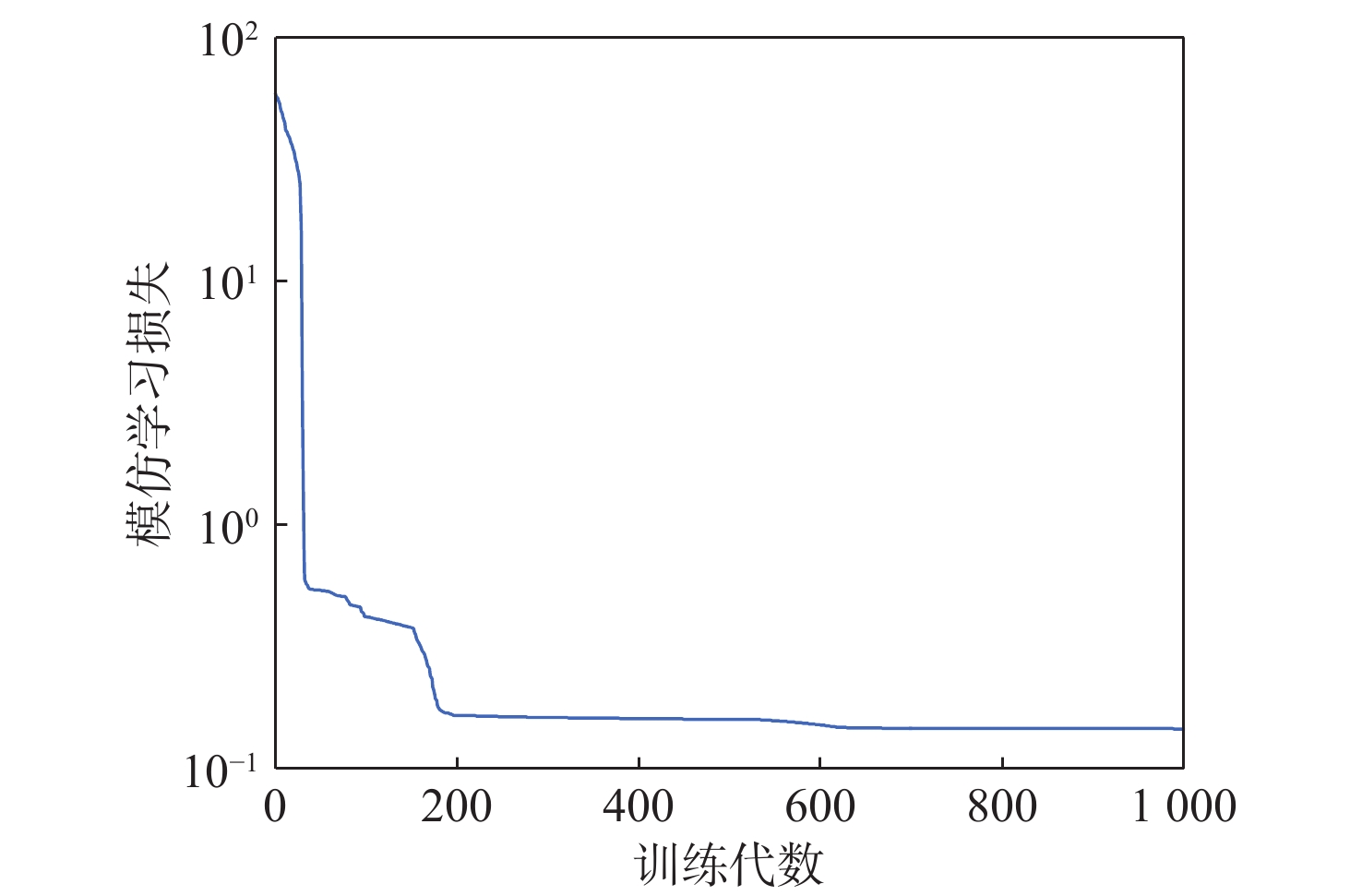
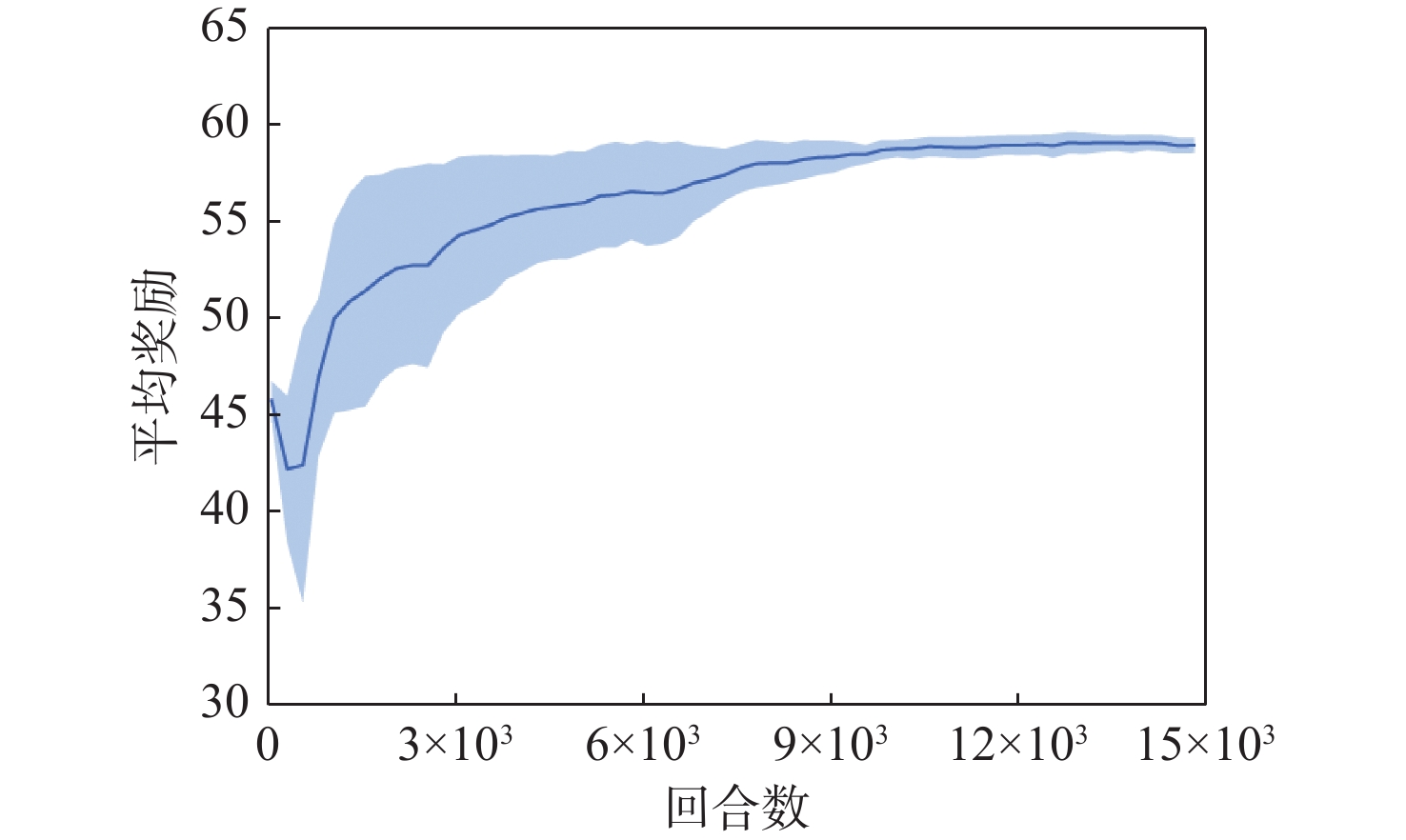
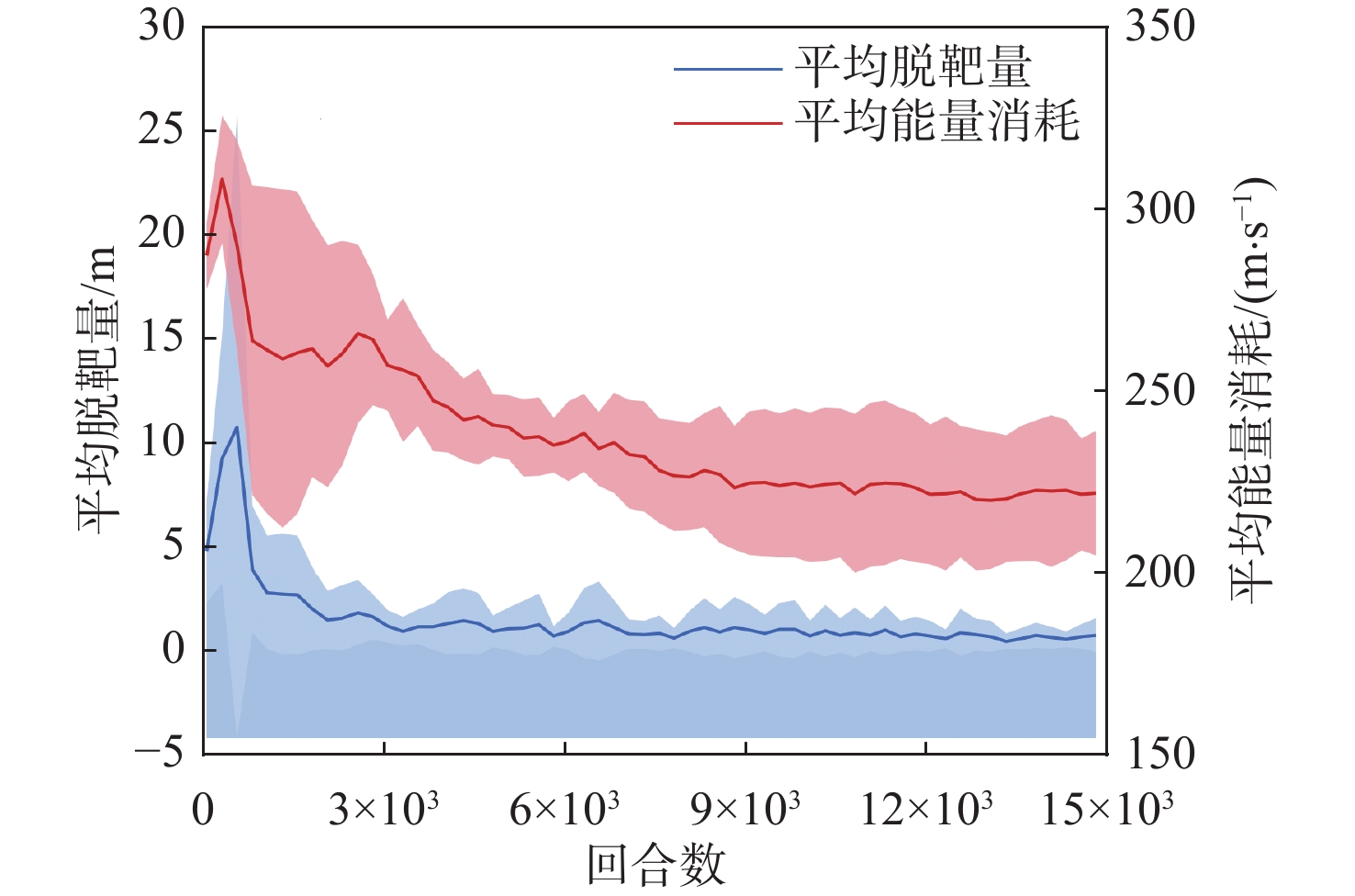
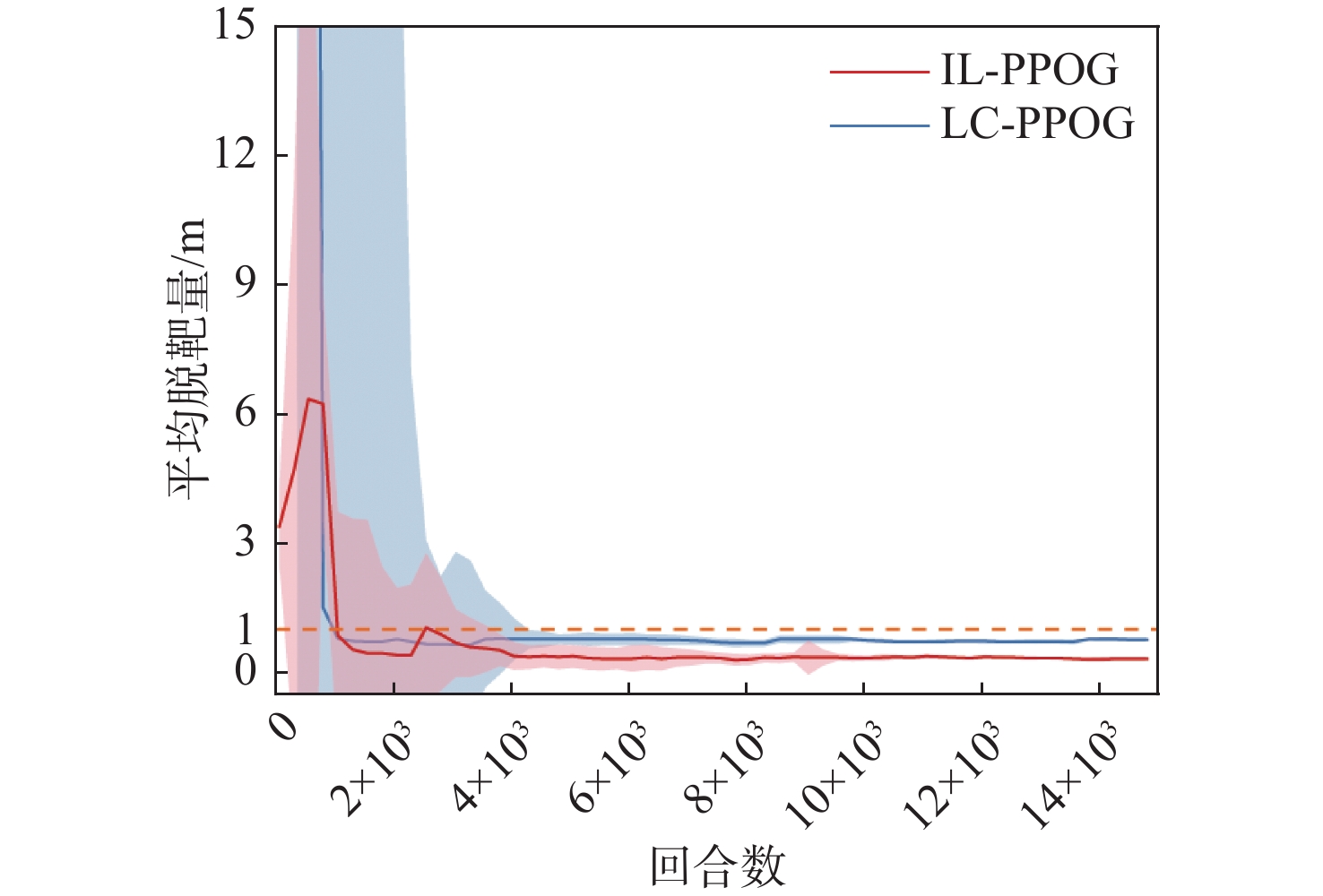
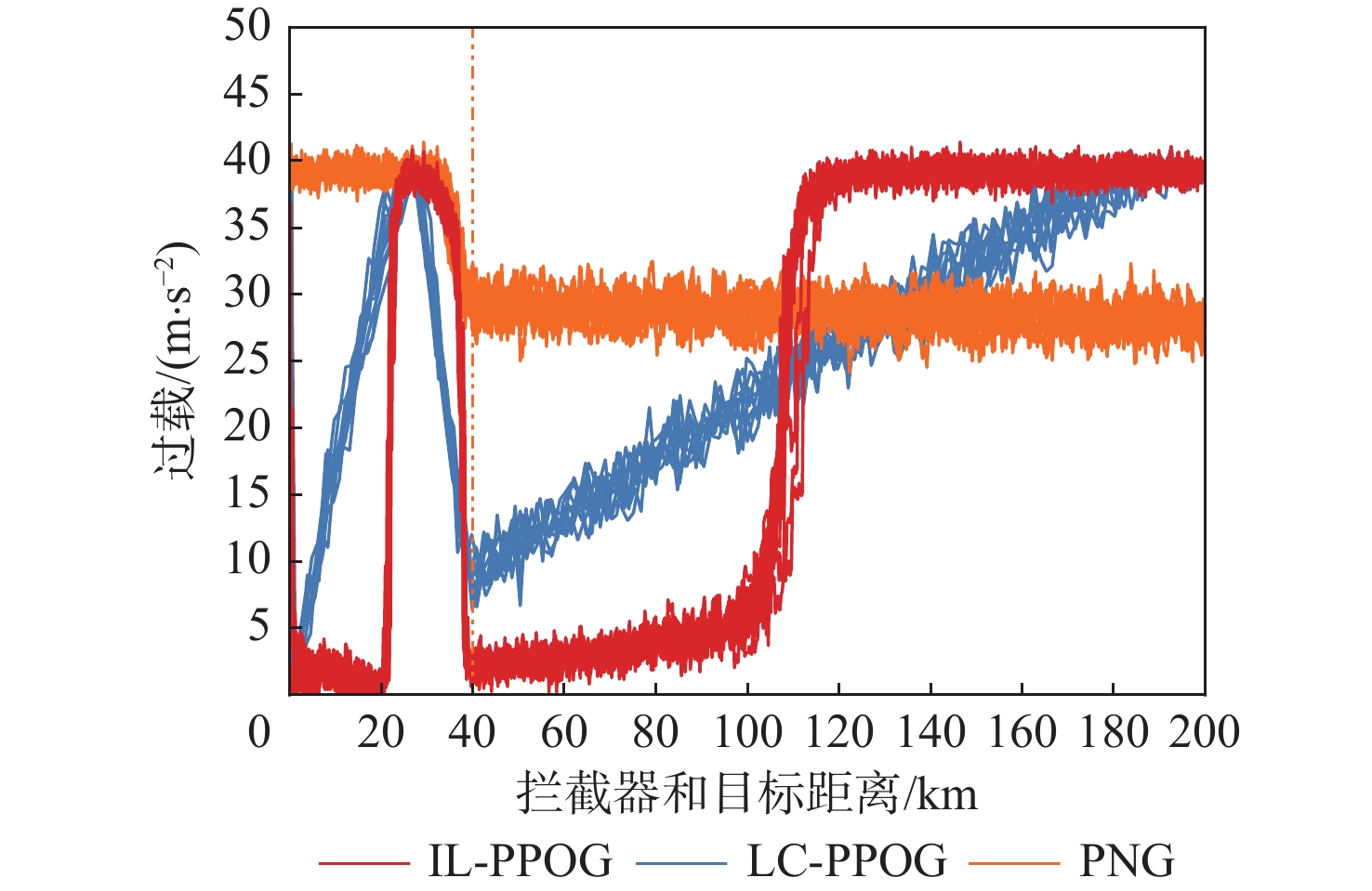
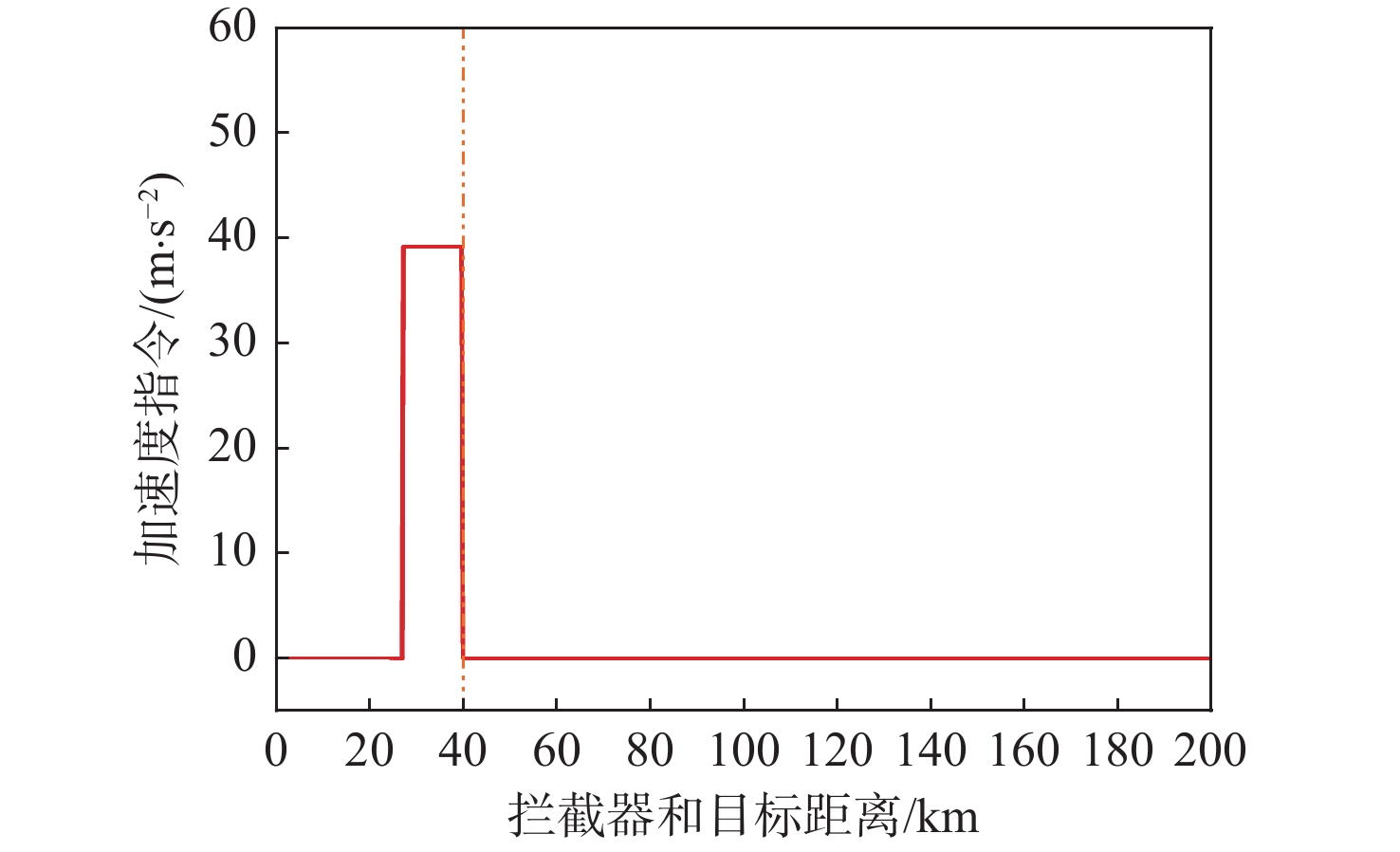
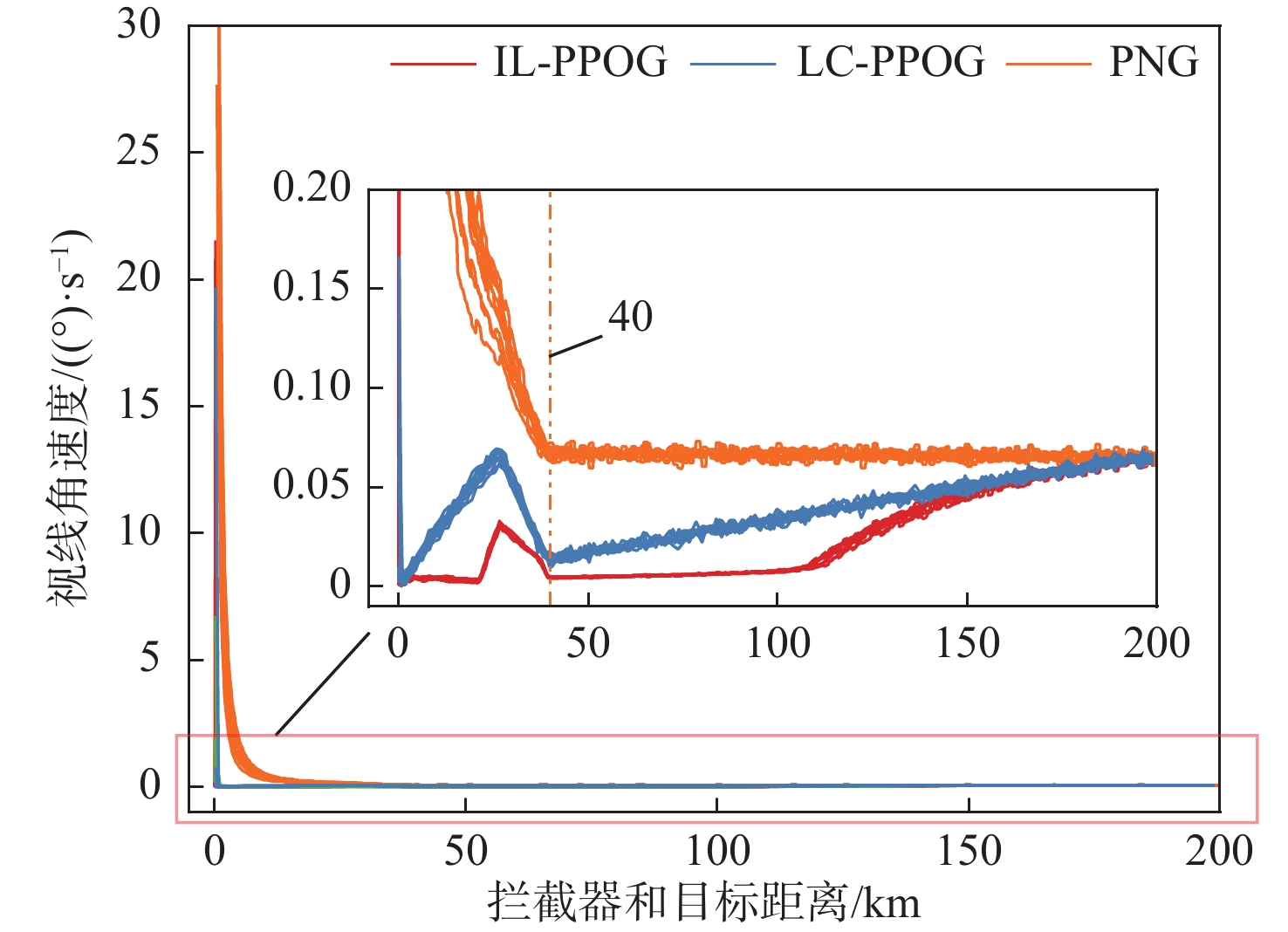
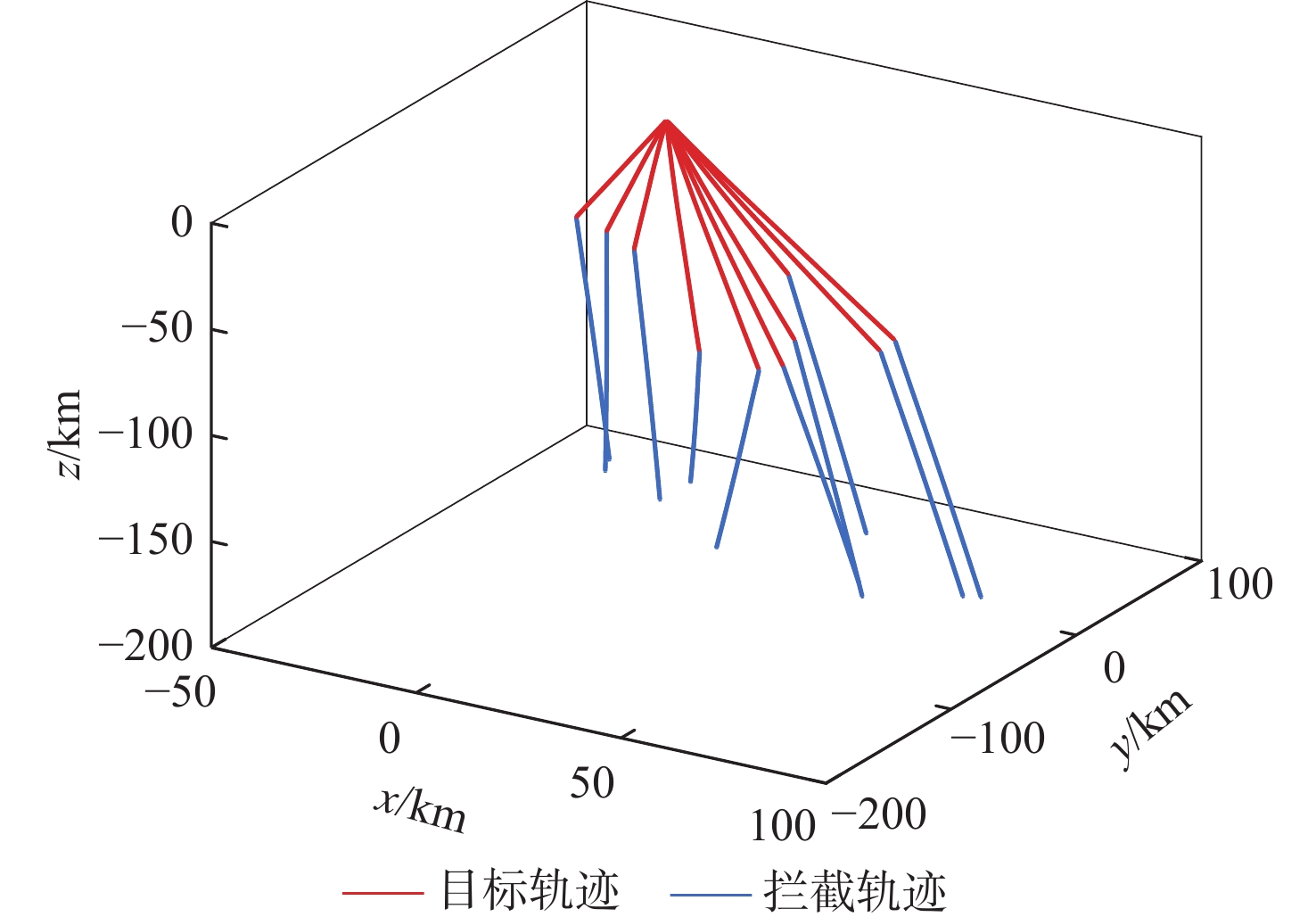

 点击查看大图
点击查看大图
计量
- 文章访问数: 310
- HTML全文浏览量: 104
- PDF下载量: 25
- 被引次数: 0
