



Deep separable convolutional neural networks based on structural reparameterization
-
摘要:
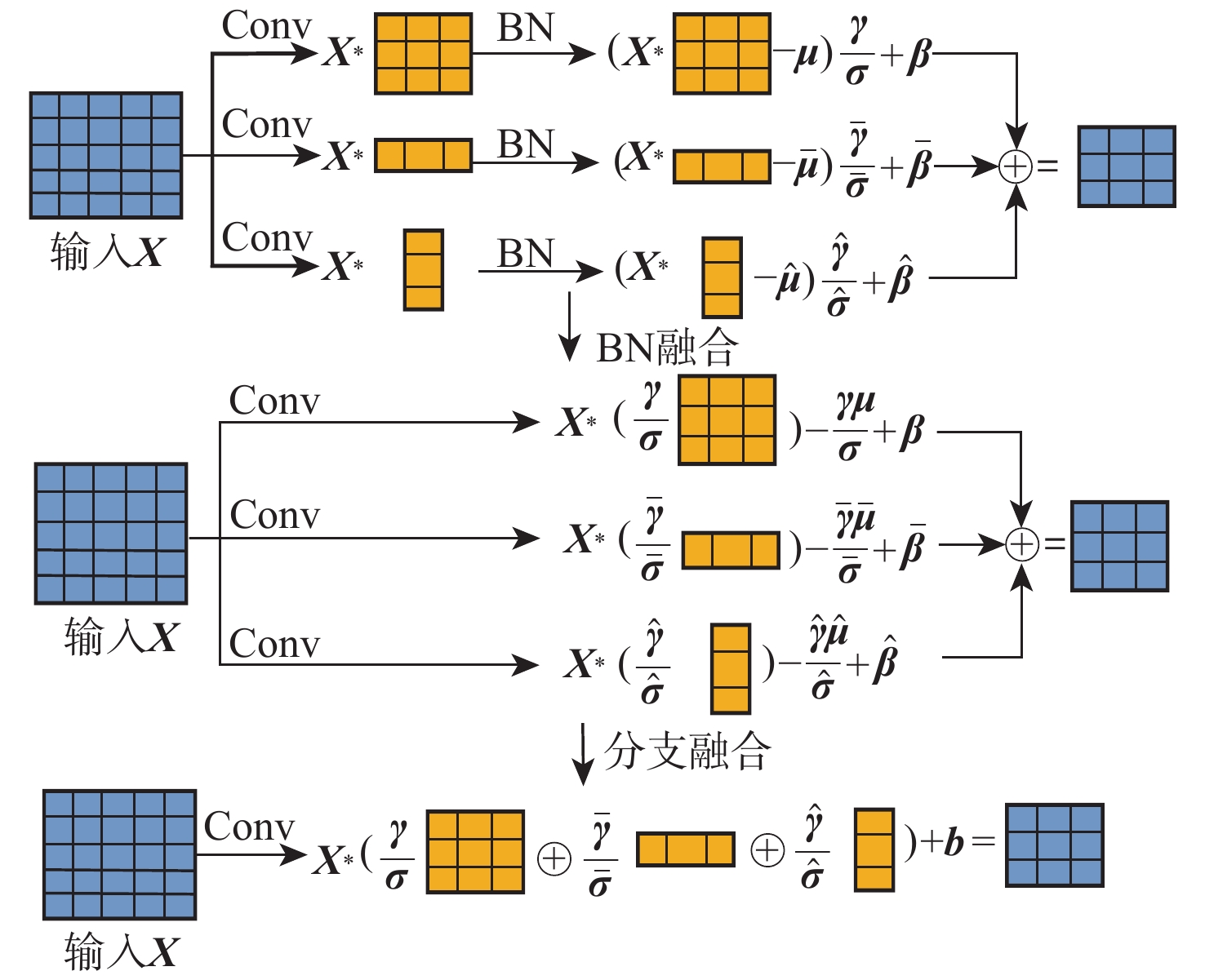
针对目前卷积神经网络(CNN)模型大部分采用的单分支深度卷积方法影响模型的表达能力、占用大量参数和Flops的问题,提出一种新的轻量级CNN模型——基于结构重参数化的深度可分离卷积神经网络(DSCNN)。该模型的特征提取模块结构重参数化混合深度卷积(RepMiX)能融合不同通道和空间位置之间的信息,实现多尺度特征融合;基于结构重参数化的DSCNN中的重参数化非对称空间算子(RepASO)通过具有不同功能的多分支结构来学习不同信道特征信息,提高模型特征学习能力;RepMiX和RepASO均结合结构重参数化技术和深度可分离卷积(DS-Conv)思想,实现了训练和推理阶段的结构解耦,在减少模型参数和Flops的同时加速模型推理;在Tiny-ImageNet-200、CIFAR-10、CIFAR-100数据集及自建铝锭表面缺陷分类数据集上进行了对比实验,结果表明:基于结构重参数化的DSCNN实现了更高的浮点运算速度,并保持了具有竞争力的精度。
Abstract:A new lightweight convolutional neural network (CNN) model called the deep separable convolutional neural network (DSCNN) based on structural reparameterization is proposed, aiming at the single-branch deep convolutional approach used in the majority of the current CNN models, which not only affects the expressive ability of the model but also occupies a large number of parameters and Flops. Firstly, the feature extraction module (reparameterization MiXer, RepMiX) of the model can fuse information between different channels and spatial locations, realizing multi-scale feature fusion. Secondly, the reparameterized asymmetric spatial operator (RepASO) in the DSCNN learns different channel feature information through a multi-branch structure with different functions, which improves the model feature learning ability; meanwhile, both RepMiX and RepASO combine the structural reparameterization technique and the idea of depth wise separable convolution (DS-Conv) to realize structural decoupling in the training and inference phases, which accelerates the model inference while reducing the model parameters and Flops. Finally, comparative experiments are carried out on the Tiny-imagenet-200, CIFAR-10, and CIFAR-100 datasets in addition to a self-constructed dataset for the classification of aluminum ingot surface defects. The experimental results demonstrate that the DSCNN maintains competitive accuracy while achieving higher floating-point speeds.
-
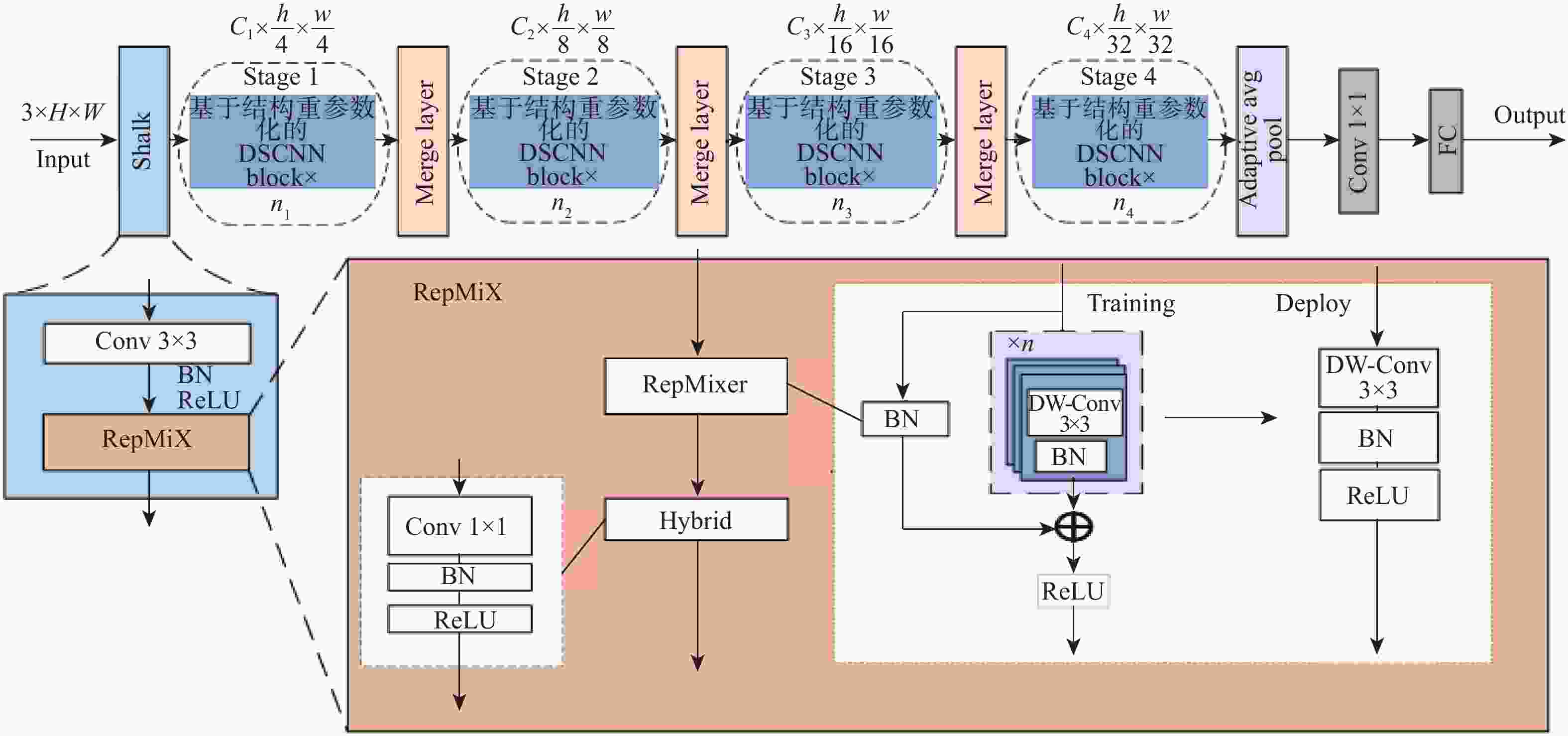
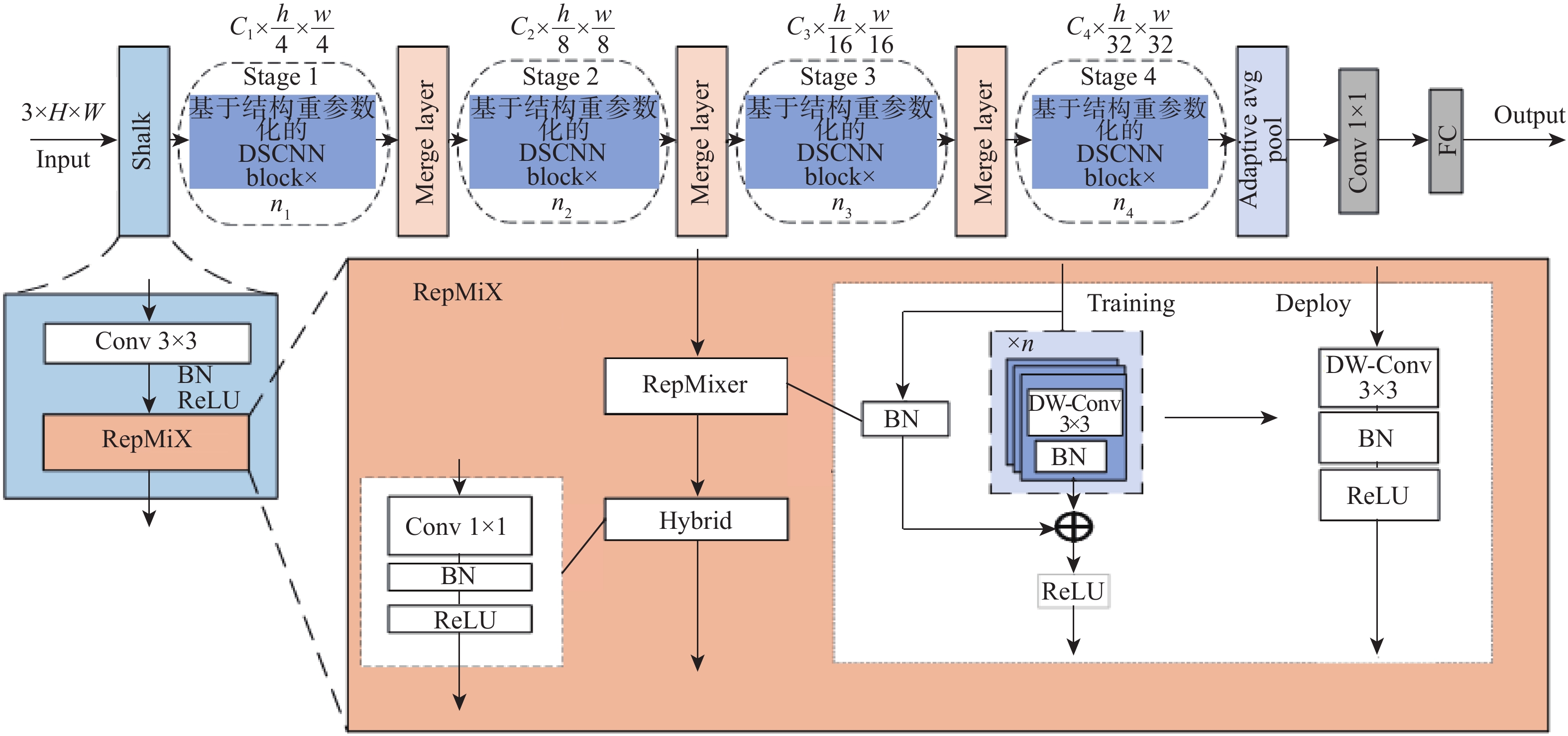
图 1 基于结构重参数化的DSCNN的整体架构
Figure 1. Overall architecture of DSCNN based on structural reparameterization
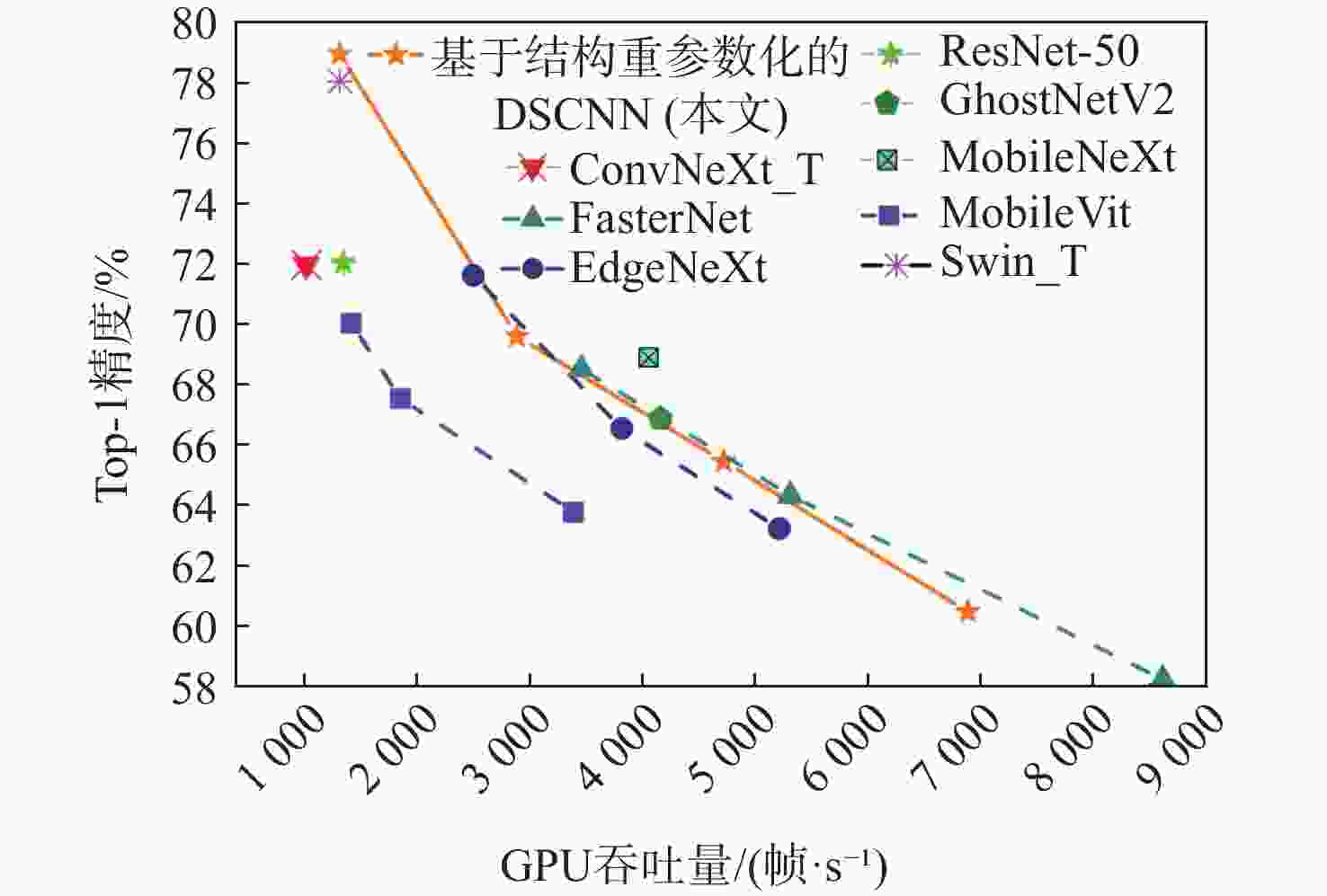
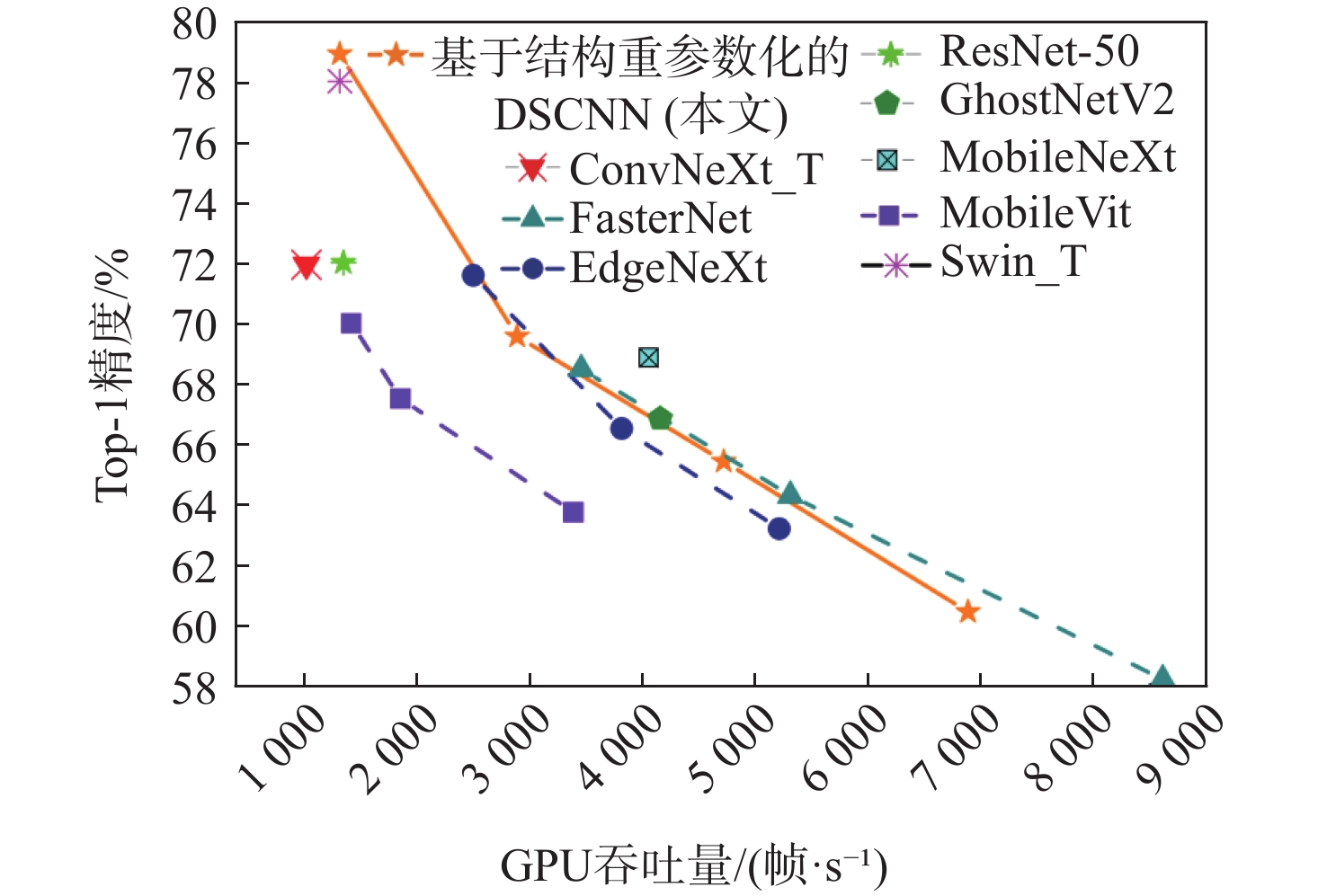
图 4 DSCNN与其他轻量模型的性能对比
Figure 4. Performance comparison between DSCNN and other lightweight models
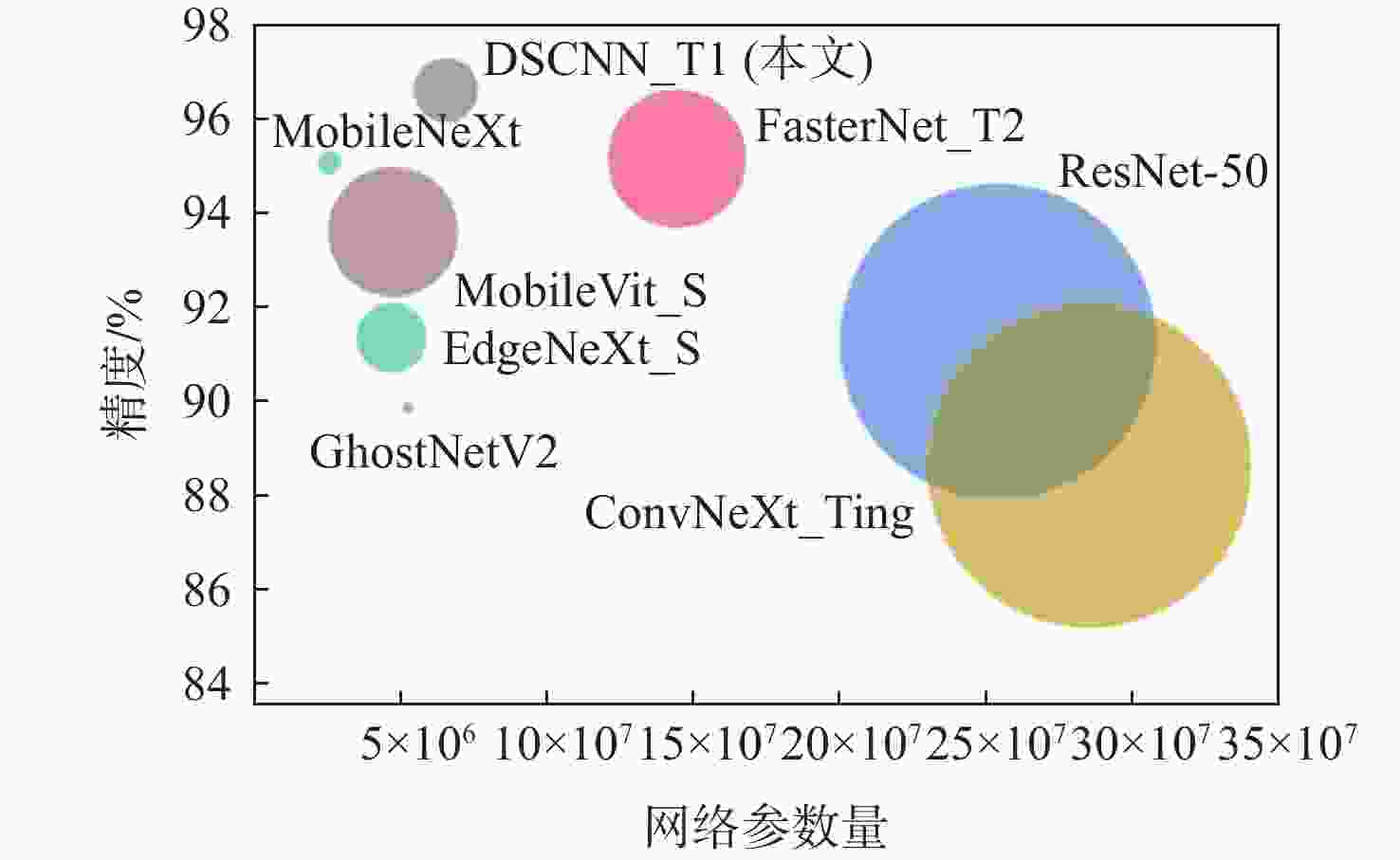
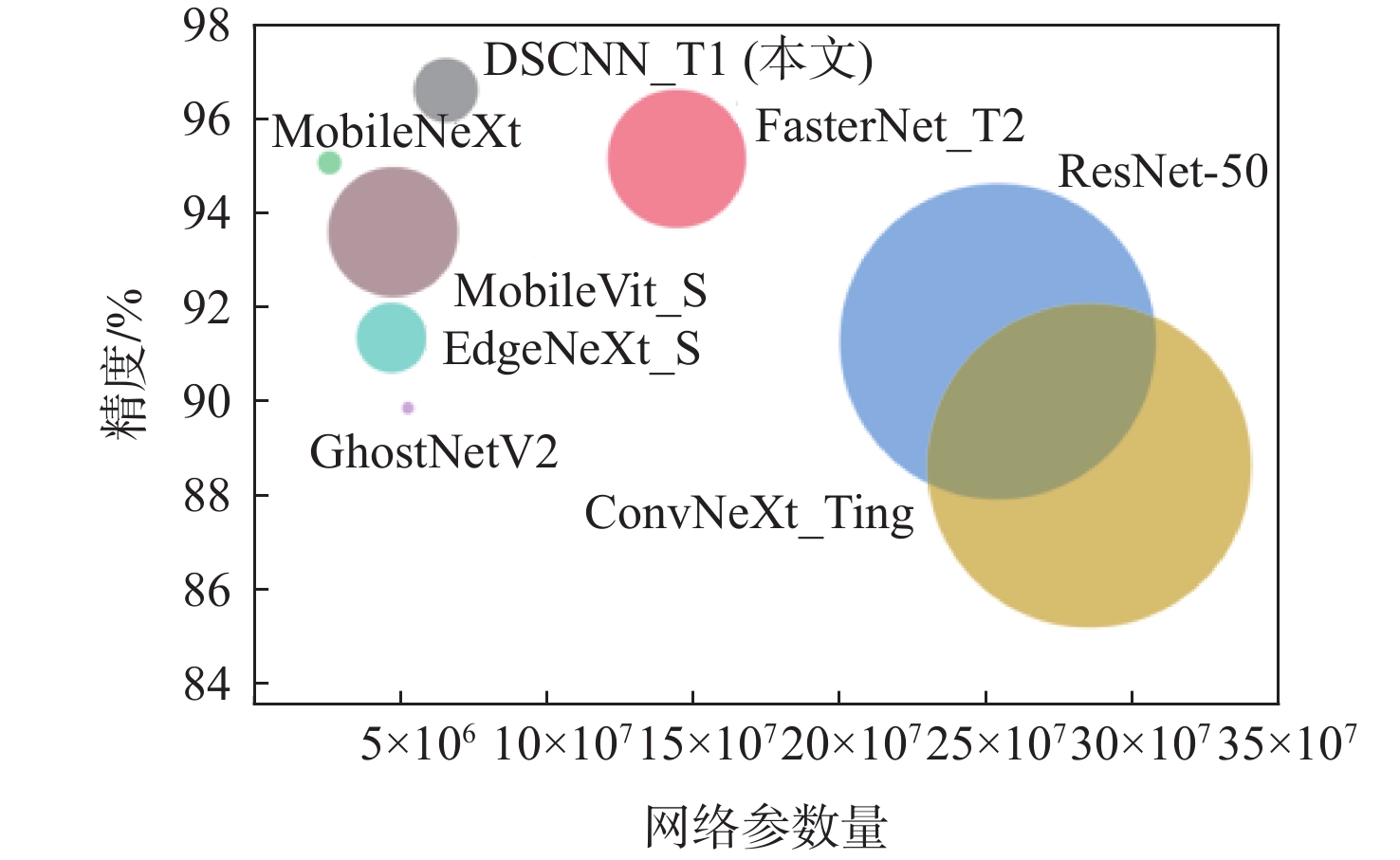
图 7 基于结构重参数化的DSCNN和多个轻量级CNN模型在铝锭表面缺陷分类数据集上的性能比较
圆圈大小代表Flops
Figure 7. Performance comparison of DSCNN based on structural reparameterization and multiple light-weight CNN models on aluminum ingot defect detection dataset
表 1 基于结构重参数化的DSCNN网络架构
Table 1. Architecture of DSCNN based on structural reparameterization
名称 输出大小 模型 数量 Stalk $ \dfrac{h}{4}\times \dfrac{w}{4} $ $ \left.\begin{matrix}3 \times 3 & 40 \\\text {RepMixer} & 40 \\\text {FFN} & 40\end{matrix}\right. $ 1 Stage 1 $ \dfrac{h}{4}\times \dfrac{w}{4} $ $ \left.\begin{matrix}1 \times 1 & 80 \\\text {RepASO} & 80 \\1 \times 1 & 40\end{matrix}\right. $ 1 Merge layer $ \dfrac{h}{8}\times \dfrac{w}{8} $ $ \left.\begin{matrix}2\times 2\;\text{Conv} & \text{步长2}\\\text{BN} & \mathrm{Re}\text{LU}\end{matrix}\right. $ 1 Stage 2 $ \dfrac{h}{8}\times \dfrac{w}{8} $ $ \left.\begin{matrix}1 \times 1 & 160 \\\text {RepASO} & 160 \\1 \times 1 & 80\end{matrix}\right. $ 2 Merge layer $ \dfrac{h}{16}\times \dfrac{w}{16} $ $ \left.\begin{matrix}2\times 2\;\text{Conv} & \text{步长2}\\\text{BN} & \mathrm{Re}\text{LU}\end{matrix}\right. $ 1 Stage 3 $ \dfrac{h}{16}\times \dfrac{w}{16} $ $ \left.\begin{matrix}1 \times 1 & 320 \\\text {RepASO} & 320 \\1 \times 1 & 160\end{matrix}\right. $ 8 Merge layer $ \dfrac{h}{32}\times \dfrac{w}{32} $ $ \left.\begin{matrix}2\times 2\;\text{Conv} & \text{步长2}\\\text{BN} & \mathrm{Re}\text{LU}\end{matrix}\right. $ 1 Stage 4 $ 7\times 7 $ $ \left.\begin{matrix}1 \times 1 & 640 \\\text {RepASO} & 640 \\1 \times 1 & 320\end{matrix}\right. $ 2 Head $ 1\times 1 $ $ \left.\begin{matrix}7 \times 7 \;\text {AvgPool2d} & 320 \\1 \times 1 & 1\;280 \\\text {FC} & 1\;000\end{matrix}\right. $ 1  下载: 导出CSV
下载: 导出CSV
表 2 实验环境
Table 2. Experimental environment
序号 环境 版本 1 Use the system Ubuntu 22.04 LTS 2 PyTorch 1.13.1 3 CUDA 11.6 4 GPU NVIDIA RTX3090Ti 5 CPU i9-12900KF 6 PyCharm 2022 Community 7 Python 3.9 8 RAM 32 GB 9 SSD 500 GB
下载: 导出CSV
表 3 基于结构重参数化的DSCNN与其他轻量级CNN模型在Tiny-ImageNet-200数据集上的性能比较
Table 3. The performance comparison of DSCNN based on structural reparameterization and other light-weight CNN models on the Tiny-ImageNet-200 dataset
模型 参数量 浮点运算数 GPU吞吐量/(帧·s−1) 浮点运算速度/109 s−1 Top-1精度/% EdgeNeXt_XXS 1.3×106 0.20×109 5 268 29.62 63.26 MobileVit_XXS 1.3×106 0.37×109 3 472 27.21 63.81 FasterNet_T0 3.9×106 0.34×109 8 609 50.21 58.30 DSCNN_T0 3.7×106 0.32×109 6 912 44.02 60.52 EdgeNeXt_XS 2.34×106 0.41×109 3 894 32.16 66.56 MobileVit_XS 2.39×106 0.92×109 1 964 33.37 67.55 GhostNetV2 6.13×106 0.17×109 4 228 14.84 66.89 FasterNet_T1 7.61×106 0.85×109 5 364 56.17 64.35 DSCNN_T1 7.38×106 0.89×109 4 782 50.57 65.48 ConvNeXt_Tiny 28.59×106 3.47×109 1 143 43.15 71.96 ResNet-50 25.55×106 3.33×109 1 466 42.56 72.03 MobileNeXt 3.51×106 0.31×109 4 128 32.04 68.90 EdgeNeXt_S 5.59×106 0.97×109 2 598 41.93 71.61 MobileVit_S 5.64×106 1.79×109 1 535 41.07 70.30 FasterNet_T2 14.98×106 1.91×109 3 541 61.19 68.52 DSCNN_T2 14.19×106 1.90×109 2 981 55.15 69.60 Swin_T 28.3×106 4.51×109 600 36.49 78.11 DSCNN_S 29.1×106 4.38×109 1 435 63.25 78.90
下载: 导出CSV
表 4 在CIFAR-10和CIFAR-100数据集上比较基于结构重参数化的DSCNN与其他轻量级CNN模型
Table 4. Comparing DSCNN based on structural reparameterization with other light-weight CNN models on CIFAR-10 and CIFAR-100 datasets
模型 参数量 浮点运算数 CIFAR-10
精度/%CIFAR-100
精度/%EdgeNeXt_XS 1.83×106 0.41×109 86.97 62.83 ShuffleNetV1 2.28×106 0.16×109 85.98 61.35 MobileNeXt 2.51×106 0.31×109 86.77 54.30 GhostNetV2 6.13×106 0.17×109 86.17 62.43 MobileVit_XXS 1.30×106 0.37×109 84.31 56.53 DSCNN_T0 3.45×106 0.32×109 90.42 65.99 FasterNet_T0 3.66×106 0.34×109 89.41 64.85 ConvNeXt_Tiny 27.97×106 3.47×109 89.07 64.76 ResNet-50 25.55×106 3.33×109 90.57 65.76 MobileVit_XS 5.12×106 0.92×109 90.79 65.17
下载: 导出CSV
表 5 不同配置的RepASO在各个数据集上的实验结果比较
Table 5. Comparison of experimental results on various datasets with different configurations of RepASO
序号 卷积个数 身份映射 CIFAR-10
精度/%CIFAR-100
精度/%Tiny-ImageNet
Top-1精度/%铝锭表面缺陷分类
数据集精度/%7×7 5×5 3×3 3×1 1×3 1×1 A 1 0 0 0 0 0 0 88.18 61.75 58.92 92.89 B 0 1 0 0 0 0 0 88.24 62.80 59.07 92.95 C 0 0 1 0 0 0 0 88.44 63.24 59.20 93.15 D 0 0 3 0 0 0 0 88.85 63.24 59.32 93.44 E 0 0 3 0 0 1 0 88.87 63.34 59.37 93.54 F 0 0 3 0 0 0 1 88.57 63.13 59.42 93.47 G 0 0 3 1 1 0 0 88.88 63.60 59.29 93.34 H 0 0 3 1 1 1 0 88.89 63.68 60.31 94.14 I 0 0 3 1 1 0 1 88.78 63.51 59.32 94.38 J 0 0 3 1 1 1 1 90.42 65.99 60.52 96.50
下载: 导出CSV
表 6 RepMixer中不同r值的RepMiX在CIFAR-10和 CIFAR-100数据集上的定量实验结果
Table 6. Quantitative experimental results of the RepMiX with different r values in RepMixer on CIFAR-10 and CIFAR-100 datasets
r 原始模型参数量 CIFAR-10精度/% CIFAR-100精度/% 1 3.46×106 89.03 63.52 2 3.52×106 89.33 63.83 3 3.58×106 90.42 65.99 4 3.64×106 88.17 63.55
下载: 导出CSV
-
[1] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 770-778. [2] DING X H, ZHANG X Y, HAN J G, et al. Scaling up your kernels to 31×31: revisiting large kernel design in cnns[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2022: 11953-11965. [3] TAN M X, LE Q V. EfficientNetV2: smaller models and faster training[EB/OL]. (2021-06-23)[2024-01-05]. https://doi.org/10.48550/arXiv.2104.00298. [4] LIU Z, MAO H, WU C Y, et al. A ConvNet for the 2020s[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2022: 11966-11976. [5] YU W H, ZHOU P, YAN S C, et al. InceptionNeXt: when inception meets ConvNext[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2024: 5672-5683. [6] SANDLER M, HOWARD A, ZHU M L, et al. MobileNetV2: inverted residuals and linear bottlenecks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 4510-4520. [7] ZHANG J N, LI X T, LI J, et al. Rethinking mobile block for efficient attention-based models[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2024: 1389-1400. [8] LIU S W, CHEN T L, CHEN X H, et al. More ConvNets in the 2020s: Scaling up kernels beyond 51×51 using sparsity[EB/OL]. (2023-03-03)[2024-01-07]. https://doi.org/10.48550/arXiv.2207.03620. [9] ZHANG X Y, ZHOU X Y, LIN M X, et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 6848-6856. [10] SUN K, LI M J, LIU D, et al. IGCV3: interleaved low-rank group convolutions for efficient deep neural networks[EB/OL]. (2018-07-20)[2024-01-08]. https://doi.org/10.48550/arXiv.1806.00178. [11] GAO H Y, WANG Y, CAI L, et al. ChannelNets: compact and efficient convolutional neural networks via channel-wise convolutions[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(8): 2570-2581. [12] DING X H, ZHANG X Y, MA N N, et al. RepVGG: making VGG-style ConvNets great again[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 13728-13737. [13] DING X H, GUO Y C, DING G G, et al. ACNet: strengthening the kernel skeletons for powerful CNN via asymmetric convolution blocks[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2020: 1911-1920. [14] VASU P K A, GABRIEL J, ZHU J, et al. MobileOne: an improved one millisecond mobile backbone[EB/OL]. (2023-03-28)[2024-01-10]. https://doi.org/10.48550/arXiv.2206.04040. [15] LIU Z, HU H, LIN Y T, et al. Swin transformer V2: scaling up capacity and resolution[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2022: 11999-12009. [16] TROCKMAN A, KOLTER J Z. Patches are all you need?[EB/OL]. (2022-01-24)[2024-01-12]. https://doi.org/10.48550/arXiv.2201.09792. [17] WANG A, CHEN H, LIN Z J, et al. RepViT: Revisiting mobile CNN from ViT perspective[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2024: 15909-15920. [18] 邱云飞, 张家欣, 兰海, 等. 融合张量合成注意力的改进ResNet图像分类模型[J]. 激光与光电子学进展, 2023, 60(6): 0610008.QIU Y F, ZHANG J X, LAN H, et al. Improved ResNet image classification model based on tensor synthesis attention[J]. Laser & Optoelectronics Progress, 2023, 60(6): 0610008(in Chinese). [19] 朱逢乐, 刘益, 乔欣, 等. 基于多尺度级联卷积神经网络的高光谱图像分析[J]. 吉林大学学报(工学版), 2023, 53(12): 3547-3557.ZHU F L, LIU Y, QIAO X, et al. Analysis of hyperspectral image analysis based on multi-scale cascaded convolutional neural network[J]. Journal of Jilin University (Engineering and Technology Edition), 2023, 53(12): 3547-3557 (in Chinese). [20] 程小辉, 李钰, 康燕萍. 基于中间图特征提取的卷积网络双标准剪枝[J]. 计算机工程, 2023, 49(3): 105-112.CHENG X H, LI Y, KANG Y P. Double standard pruning of convolution network based on feature extraction of intermediate graph[J]. Computer Engineering, 2023, 49(3): 105-112(in Chinese). [21] SZEGEDY C, LIU W, JIA Y Q, et al. Going deeper with convolutions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2015: 1-9. [22] 赵利, 王雷全, 张俊三, 等. 基于双通道特征增强的高光谱图像分类[J]. 激光与光电子学进展, 2023, 60(12): 1210012.ZHAO L, WANG L Q, ZHANG J S, et al. Hyperspectral image classification based on dual-channel feature enhancement[J]. Laser & Optoelectronics Progress, 2023, 60(12): 1210012(in Chinese). [23] CHEN J R, KAO S H, HE H, et al. Run, don’t walk: chasing higher FLOPS for faster neural networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2023: 12021-12031. -

 下载:
下载:
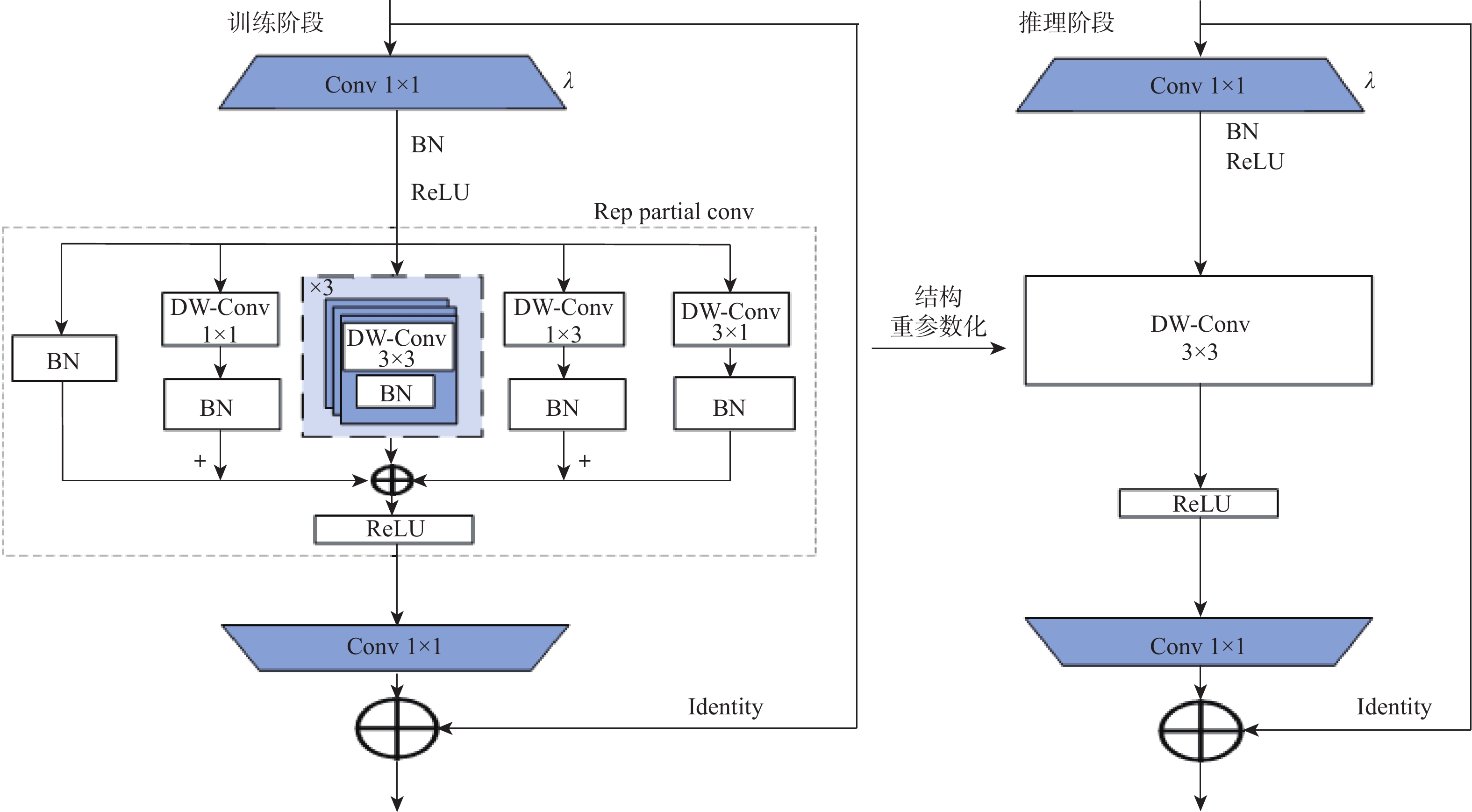




 点击查看大图
点击查看大图
计量
- 文章访问数: 487
- HTML全文浏览量: 127
- PDF下载量: 21
- 被引次数: 0
