



Self-supervised optical fiber sensing signal separation based on linear convolutive mixing process
-
摘要:
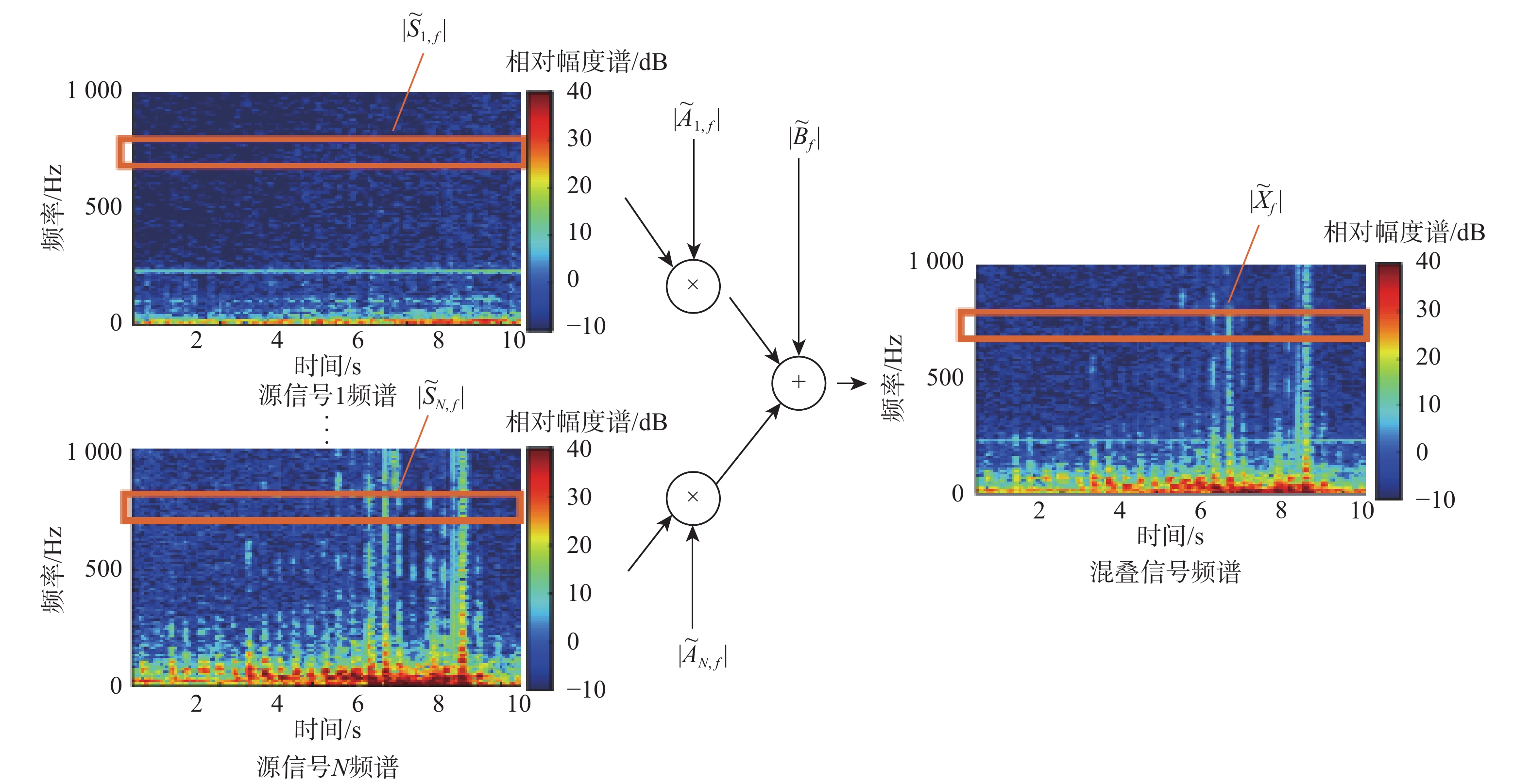
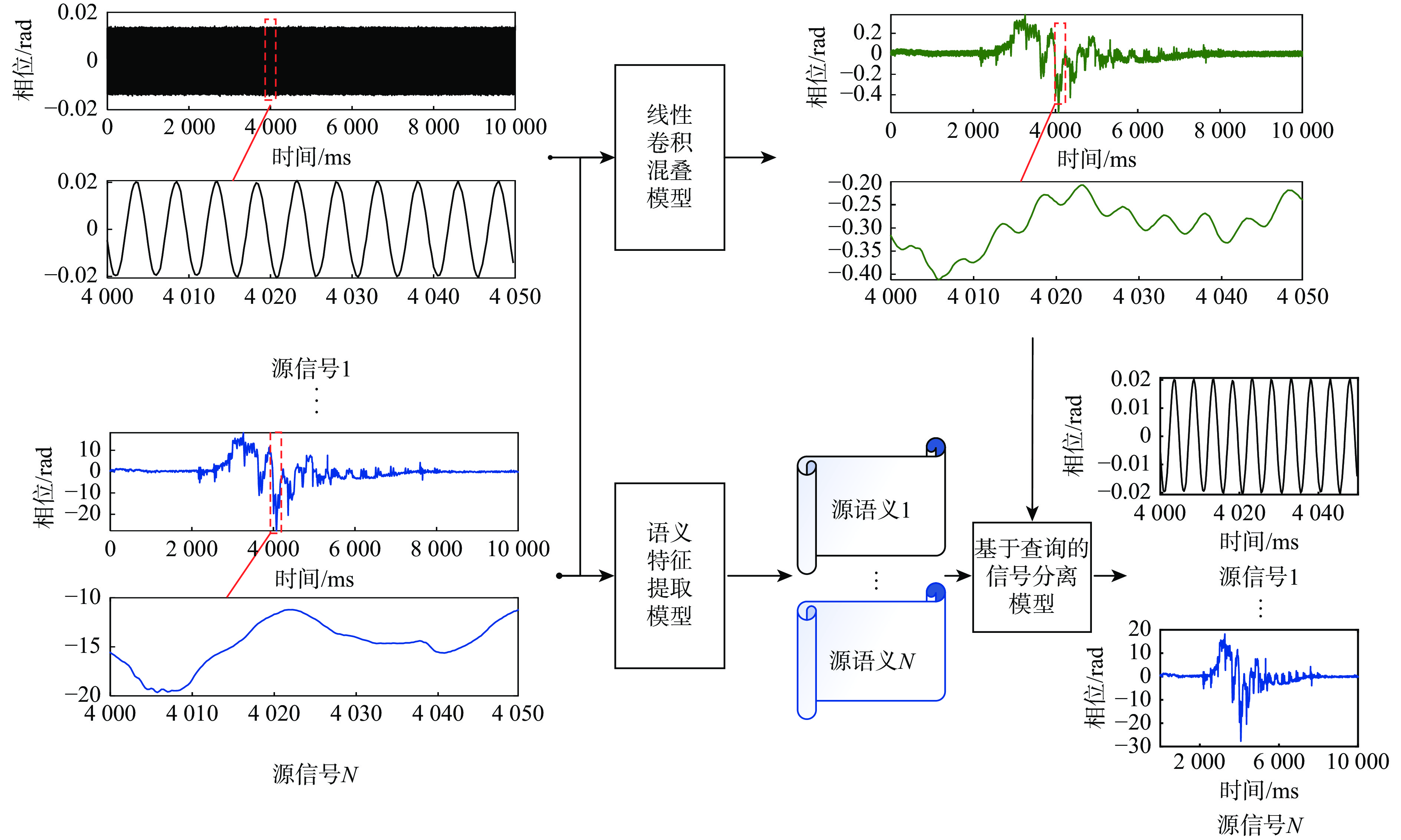
针对光纤传感信号分离问题,提出一种基于线性卷积混叠过程的自监督式信号分离方法,其主要包含3部分:线性卷积混叠模型、语义特征提取模型和基于查询的信号分离模型。在模型训练过程中,相比于线性叠加模型,线性卷积混叠模型可依据更贴合实际传感过程的线性卷积混叠方式对输入的多个子信号进行混叠,动态生成混叠信号,服务于后续基于查询的信号分离模型的自监督式学习;利用语义特征提取模型将某一子信号映射至特征空间;将其特征作为查询因子,并与混叠信号一起输入到基于查询的信号分离模型中,最终输出目标子信号,在可成倍扩充训练样本的同时,也可实现零样本条件下的目标信号分离。为验证所提方法的有效性,在室内环境下开展实验并采集了跑步时及单频正弦振动下的光纤传感信号及两者的混叠信号,且在该实测数据上的实验结果表明了所提方法的有效性。
Abstract:This paper proposeds a self-supervised signal separation method based on a linear convolutive mixing process. The method comprises three components: a linear convolutive mixer, a semantic token extractor, and a query-based signal separator. During the training phase, source signals undergo convolutional mixing within the mixer, which is a better mimic of the realistic optical fiber sensing process when compared with the linear simultaneous mixing process, resulting in a mixed signal that could be used for the self-supervised learning of the separator. The source signals' embeddings are then produced by the semantic token extractor and used as query tokens in the separator. Finally, mixed signal and source embeddings are combined and fed into the separator to produce the target source signal. The proposed method could be even used in a zero-shot setting. And the number of training samples could be expanded with this random combination of mixed signal and source embedding. In an interior setting, experimental optical fiber sensor data are gathered, including cyclical vibrations and human motions like jogging. The results of the signal separation experiments demonstrate the effectiveness of the proposed method.
-
Key words:
- signal separation /
- self-supervised /
- convolutive mixing /
- optical fiber sensing /
- zero-shot
-
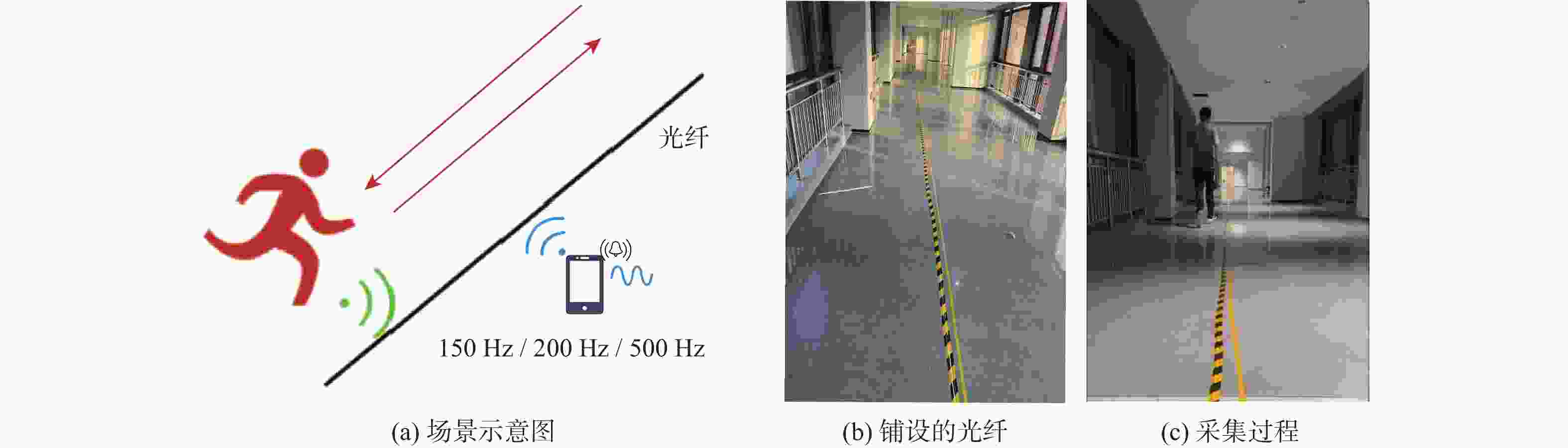
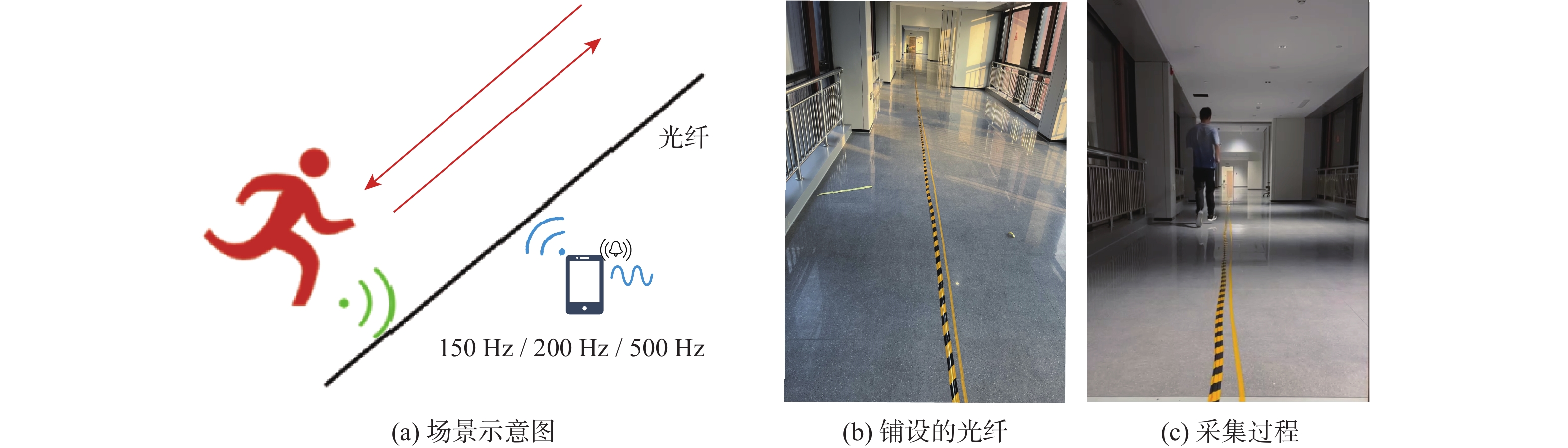
图 3 光纤传感数据采集场景
Figure 3. Experimental scenario for optical fiber sensing data collection
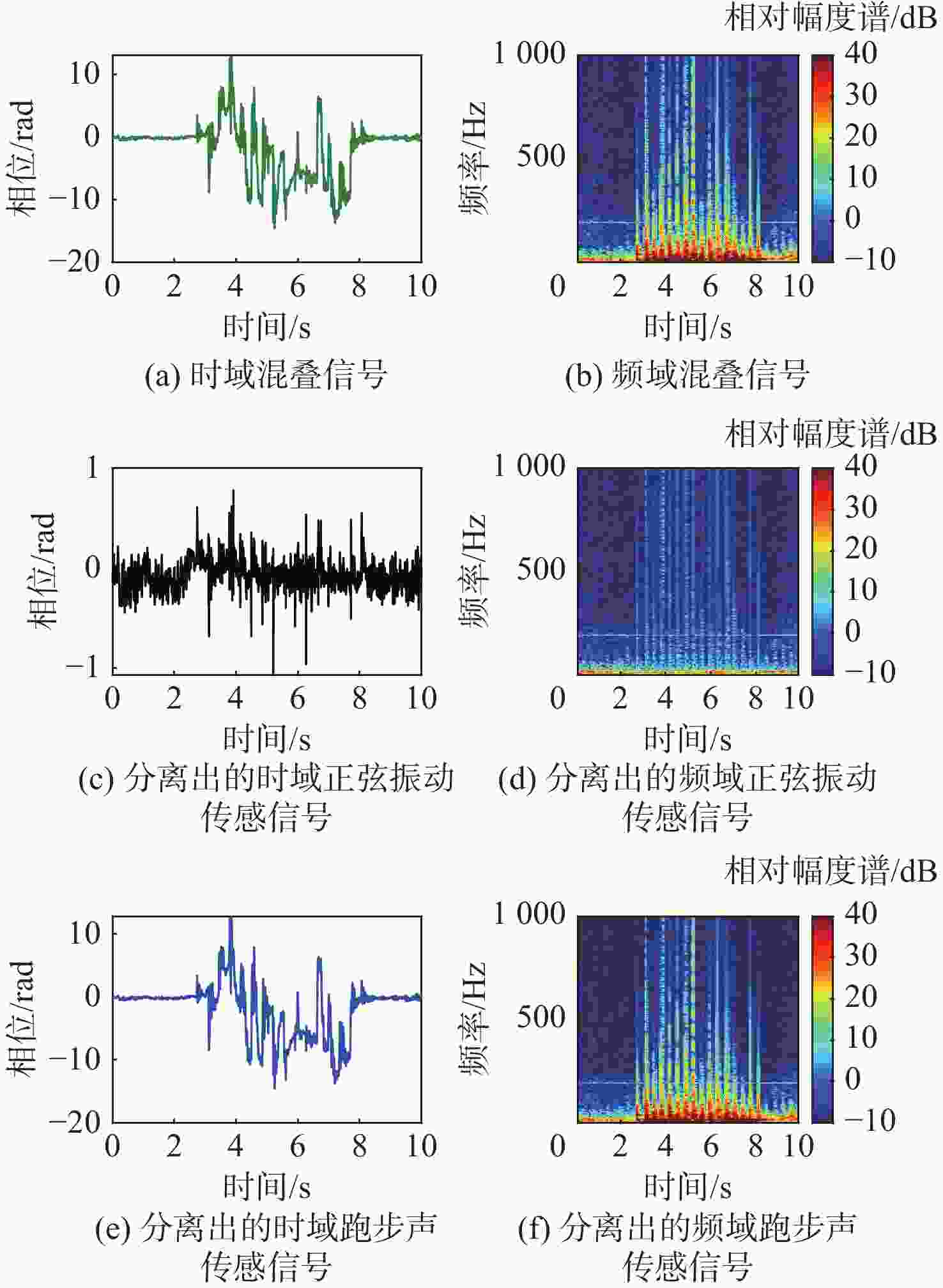
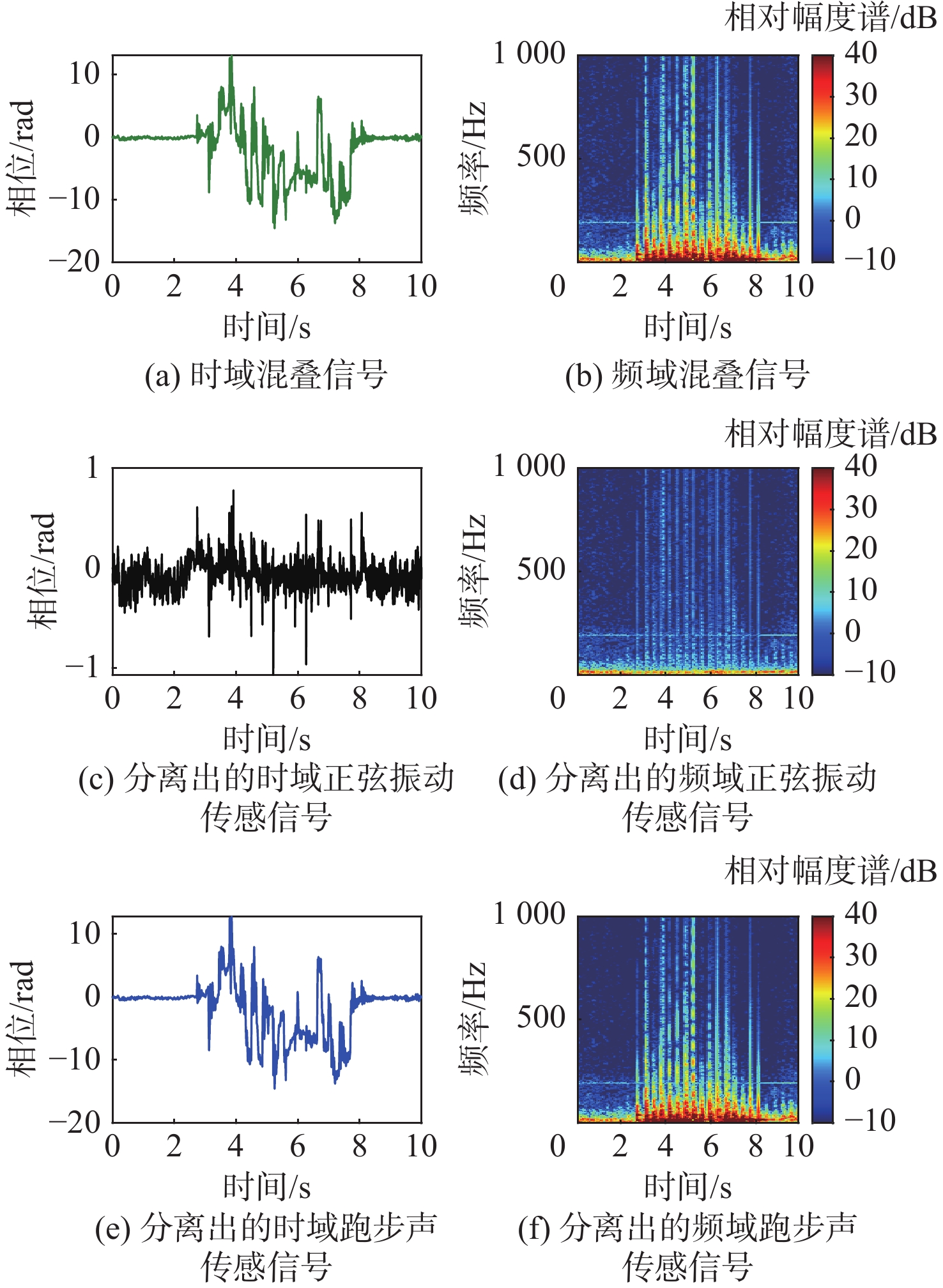
图 4 实测光纤传感混叠信号分离结果
Figure 4. Signal separation results on experimental optical fiber mixture signal
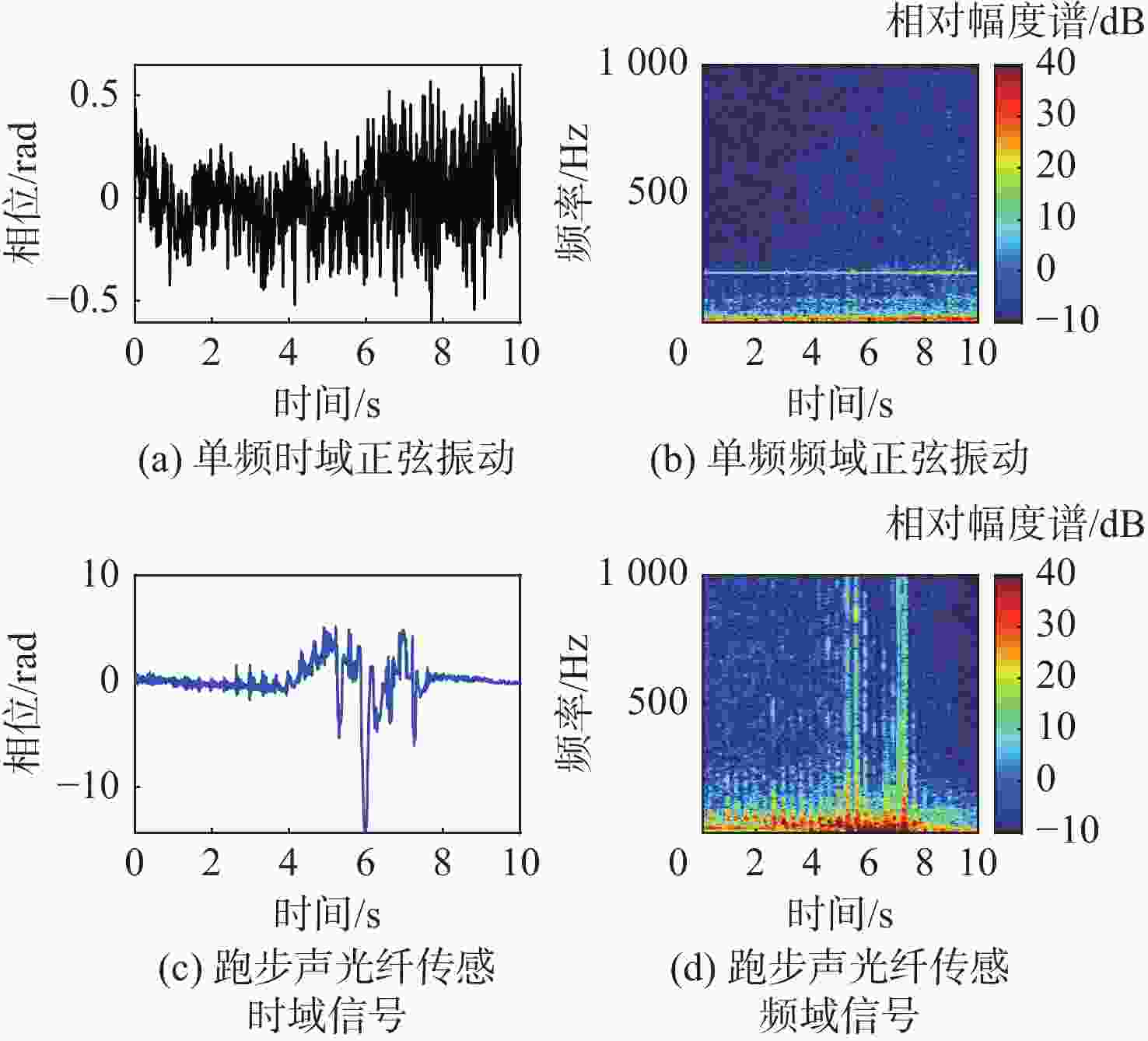
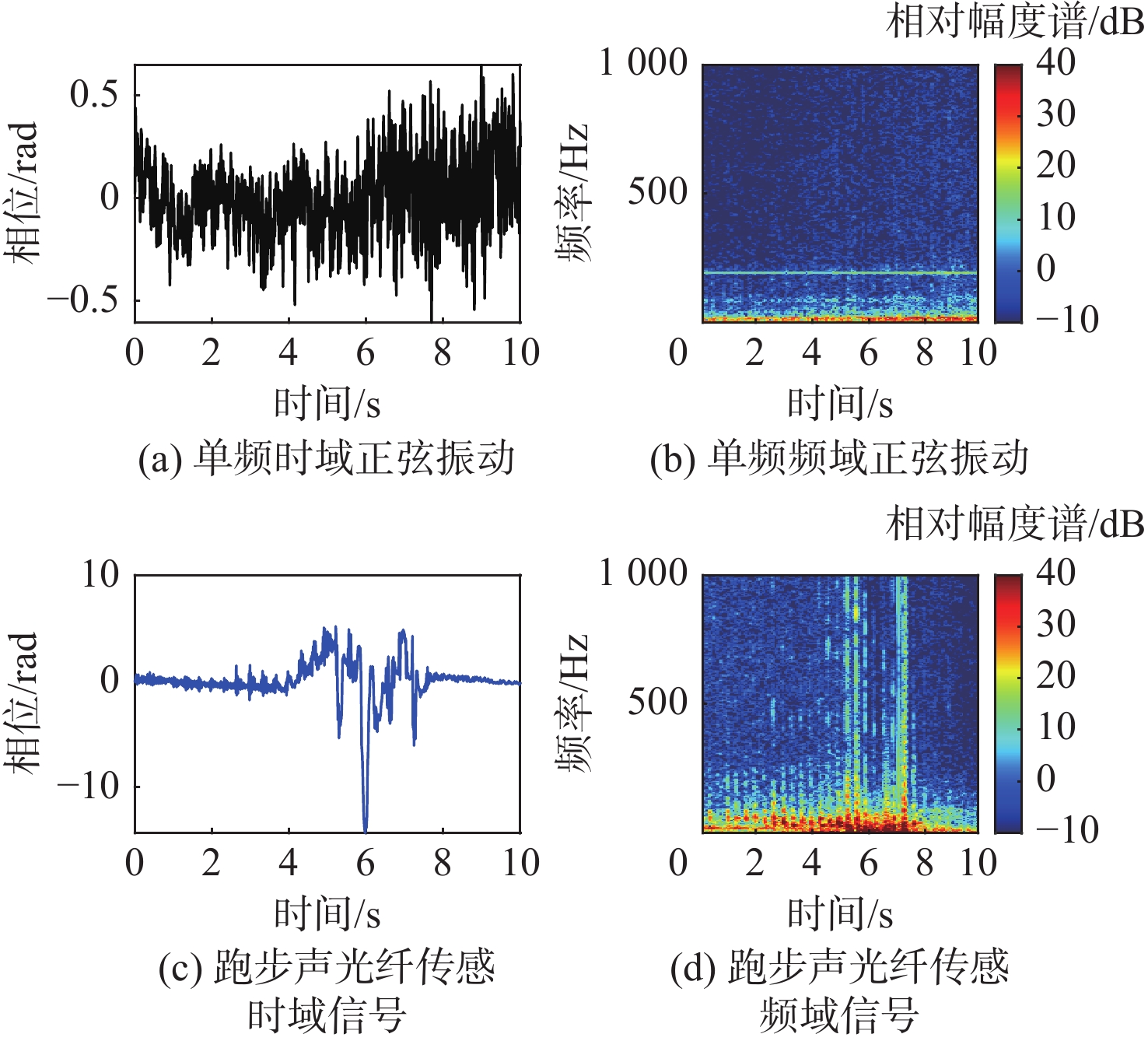
图 5 实测单频正弦振动和跑步声光纤传感信号实测
Figure 5. Experimental mono-frequency sinusodial sensing signal and jogging sensing singal
表 1 原始信号实验数据数量统计
Table 1. Statistic on quantity of information of original signals experimental data
传感目标 数量 单条数据长度/s 单频正弦振动 10 21 跑步声 72 10 单频正弦振动+跑步声 84 10  下载: 导出CSV
下载: 导出CSV
-
[1] LYU C G, HUO Z Q, LIU Y G, et al. Robust intrusion events recognition methodology for distributed optical fiber sensing perimeter security system[J]. IEEE Transactions on Instrumentation and Measurement, 2020, 70: 9505109. [2] JOUSSET P, REINSCH T, RYBERG T, et al. Dynamic strain determination using fibre-optic cables allows imaging of seismological and structural features[J]. Nature Communications, 2018, 9(1): 2509. doi: 10.1038/s41467-018-04860-y [3] LINDSEY N J, DAWE T C, AJO-FRANKLIN J B. Illuminating seafloor faults and ocean dynamics with dark fiber distributed acoustic sensing[J]. Science, 2019, 366(6469): 1103-1107. doi: 10.1126/science.aay5881 [4] 钟翔, 张春熹, 林文台, 等. 基于小波变换的光纤周界定位系统[J]. 北京航空航天大学学报, 2013, 39(3): 396-400.ZHONG X, ZHANG C X, LIN W T, et al. Fiber-optic perimeter location system based on wavelet transformation[J]. Journal of Beijing University of Aeronautics and Astronautics, 2013, 39(3): 396-400(in Chinese). [5] RAO Y J, WANG Z N, WU H J, et al. Recent advances in phase-sensitive optical time domain reflectometry (Ф-OTDR)[J]. Photonic Sensors, 2021, 11(1): 1-30. doi: 10.1007/s13320-021-0619-4 [6] WU H J, LIU Y M, TU Y L, et al. Multi-source separation under two “blind” conditions for fiber-optic distributed acoustic sensor[J]. Journal of Lightwave Technology, 2022, 40(8): 2601-2611. doi: 10.1109/JLT.2022.3142020 [7] STARK M, WOHLMAYR M, PERNKOPF F. Source–filter-based single-channel speech separation using pitch information[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2011, 19(2): 242-255. doi: 10.1109/TASL.2010.2047419 [8] SMARAGDIS P. Convolutive speech bases and their application to supervised speech separation[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2007, 15(1): 1-12. doi: 10.1109/TASL.2006.876726 [9] SCHMIDT M N, OLSSON R K. Single-channel speech separation using sparse non-negative matrix factorization[EB/OL]. (2006-09-21)[2024-05-30]. https://www.isca-archive.org/interspeech_2006/schmidt06_interspeech.pdf. [10] HU K, WANG D L. An unsupervised approach to cochannel speech separation[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2013, 21(1): 122-131. doi: 10.1109/TASL.2012.2215591 [11] NACHMANI E, ADI Y, WOLF L. Voice separation with an unknown number of multiple speakers[EB/OL]. (2020-09-01. )[2024-05-30]. https://arxiv.org/abs/2003.01531. [12] LUO Y, MESGARANI N. TaSNet: time-domain audio separation network for real-time, single-channel speech separation[C]//Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE Press, 2018: 696-700. [13] KOLBÆK M, YU D, TAN Z H, et al. Multitalker speech separation with utterance-level permutation invariant training of deep recurrent neural networks[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2017, 25(10): 1901-1913. doi: 10.1109/TASLP.2017.2726762 [14] 王振宇, 向泽锐, 支锦亦, 等. 多谱自适应小波和盲源分离耦合的生理信号降噪方法[J]. 北京航空航天大学学报, 2025, 51(3): 910-921.WANG Z Y, XIANG Z R, ZHI J Y, et al. Multi-spectrum adaptive wavelet coupling with blind source separation for physiological signal denoising[J]. Journal of Beijing University of Aeronautics and Astronautics, 2025, 51(3): 910-921(in Chinese). [15] 孙环宇, 杨志鹏, 王艺玮, 等. 基于自适应参数优化RSSD-CYCBD的行星齿轮箱多故障耦合信号分离及诊断[J]. 北京航空航天大学学报, 2024, 50(10): 3139-3150.SUN H Y, YANG Z P, WANG Y W, et al. Multi-fault coupling signal separation and diagnosis of planetary gearbox based on adaptive parameter optimization RSSD-CYCBD[J]. Journal of Beijing University of Aeronautics and Astronautics, 2024, 50(10): 3139-3150(in Chinese). [16] 李靖卿, 冯存前, 张栋, 等. 基于时频域增强和全变差的群目标信号分离[J]. 北京航空航天大学学报, 2016, 42(2): 375-382.LI J Q, FENG C Q, ZHANG D, et al. Group-target signal separation based on time-frequency enhancement and total variation[J]. Journal of Beijing University of Aeronautics and Astronautics, 2016, 42(2): 375-382(in Chinese). [17] VIRTANEN T. Speech recognition using factorial hidden Markov models for separation in the feature space[C]//Proceedings of the INTERSPEECH 2006-ICSLP, Ninth International Conference on Spoken Language Processing. Pittsburg: DBLP , 2006. [18] HERSHEY J R, CHEN Z, LE ROUX J, et al. Deep clustering: discriminative embeddings for segmentation and separation[C]//Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE Press, 2016: 31-35. [19] CHEN K, DU X J, ZHU B L, et al. Zero-shot audio source separation through query-based learning from weakly-labeled data[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Menlo Park: AAAI, 2022, 36(4): 4441-4449. [20] OZEROV A, FEVOTTE C. Multichannel nonnegative matrix factorization in convolutive mixtures for audio source separation[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2010, 18(3): 550-563. doi: 10.1109/TASL.2009.2031510 [21] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: transformers for image recognition at scale[EB/OL]. (2021-06-03)[2024-05-30]. https://arxiv.org/abs/2010.11929. [22] LIU Z, LIN Y T, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2021: 9992-10002. [23] LIU X B, KONG Q Q, ZHAO Y, et al. Separate anything you describe[EB/OL]. (2023-08-09)[2024-05-30]. https://arxiv.org/abs/2308.05037. -

 下载:
下载:

 点击查看大图
点击查看大图
计量
- 文章访问数: 197
- HTML全文浏览量: 48
- PDF下载量: 22
- 被引次数: 0
