



High-precision real-time object detection model and benchmark for X-ray security inspection images
-
摘要:
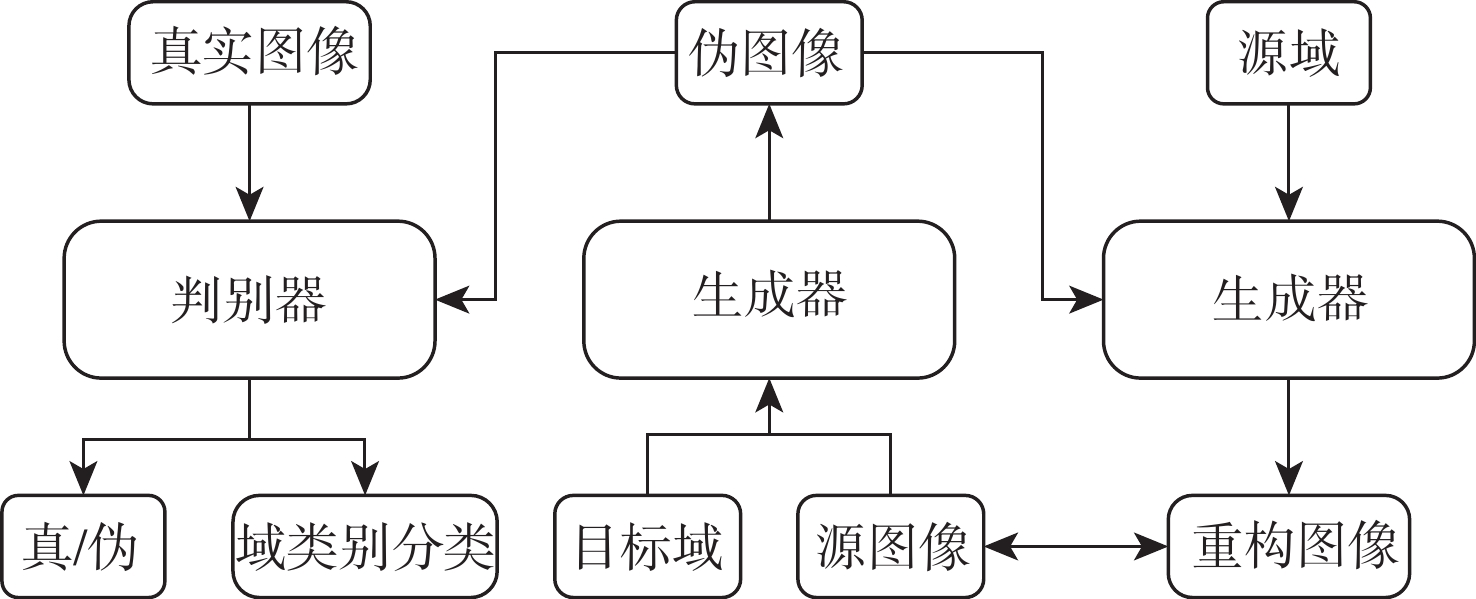
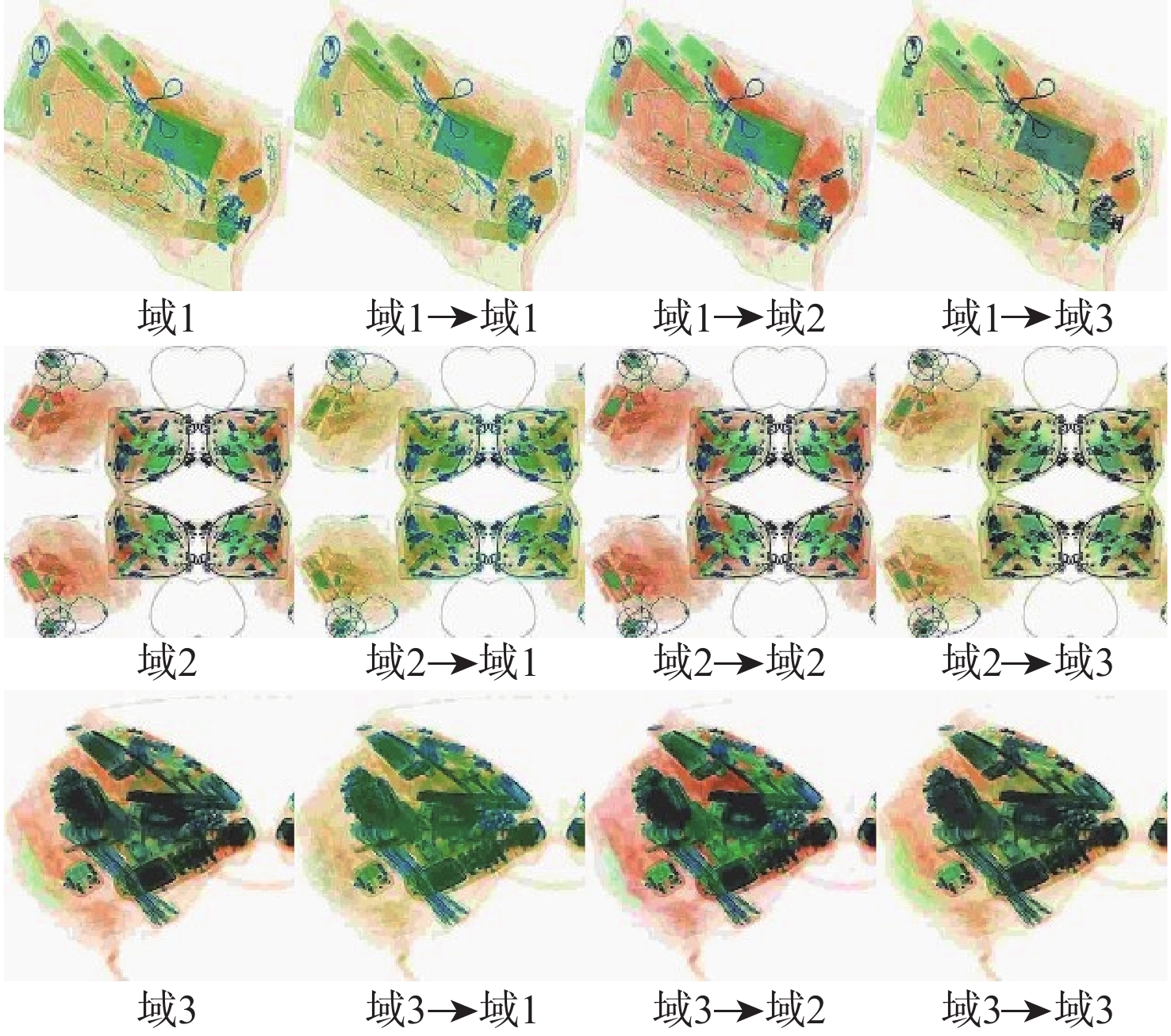
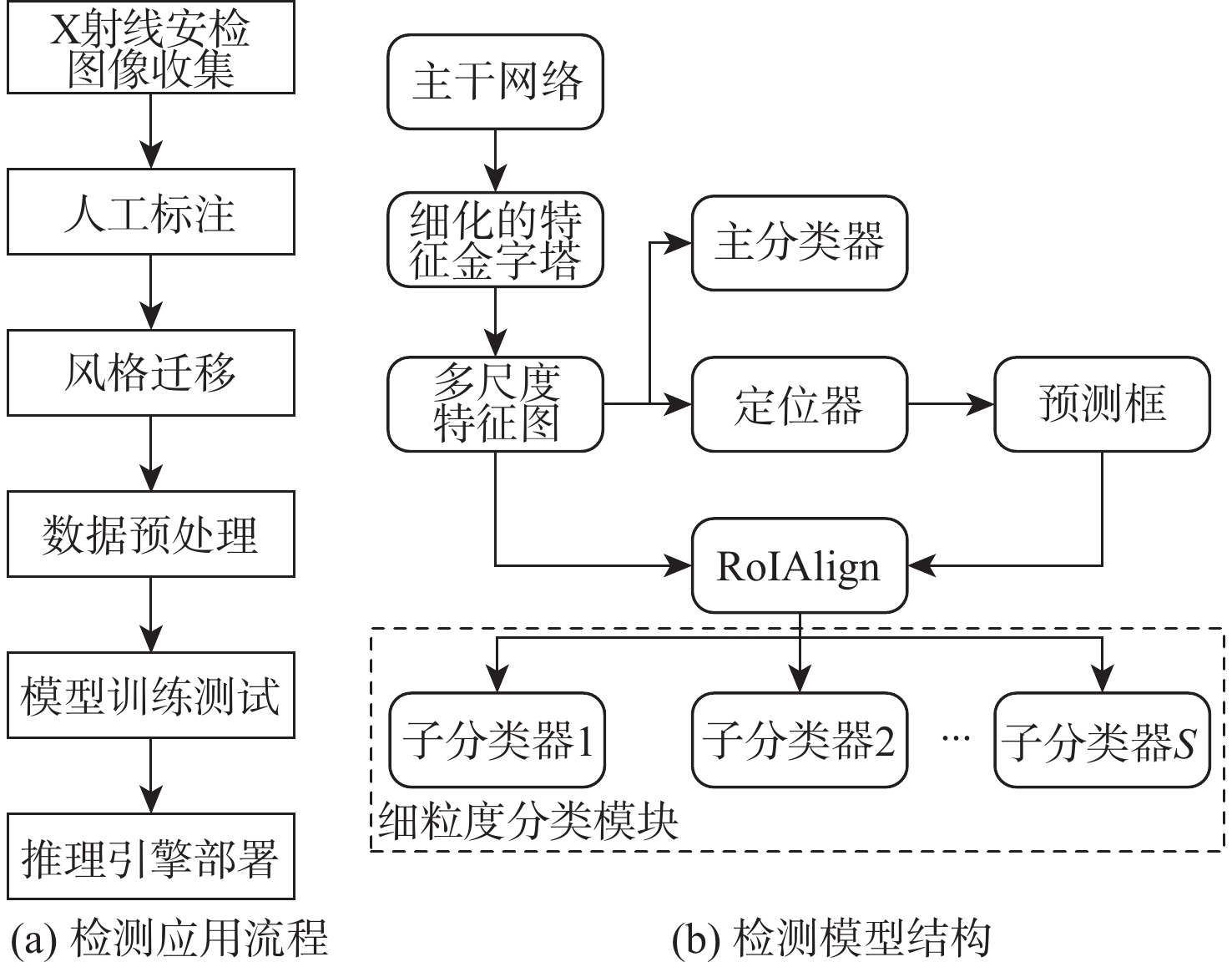
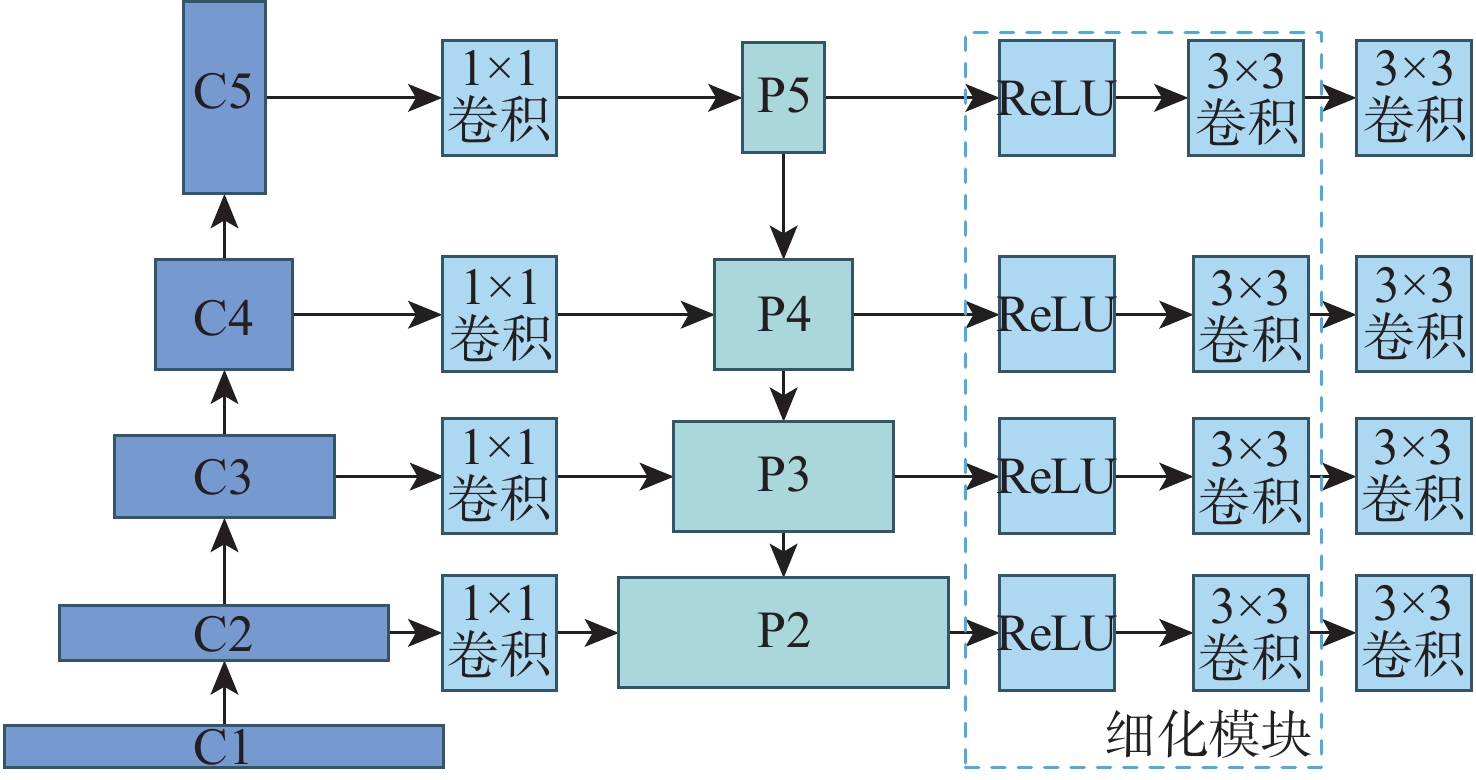
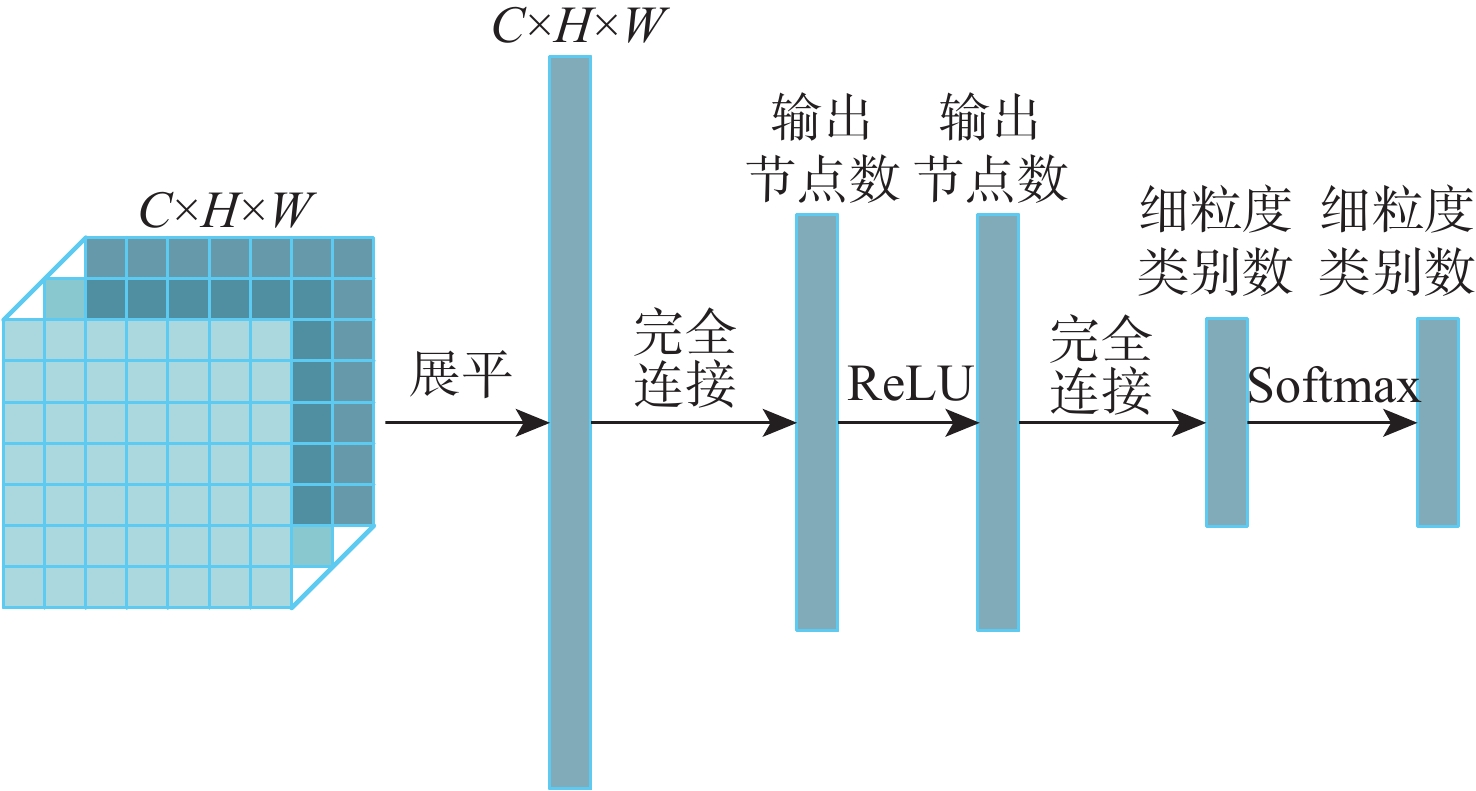
图像目标检测技术辅助提高了安检工作效率,进一步保障了公共安全。然而,不同型号安检机成像的差异性、X射线安检图像的复杂性及昂贵的数据标注成本制约了X射线安检图像目标检测技术的深入研究。为此,针对不同安检机厂商相同物质X射线成像颜色的差异,基于风格迁移算法进行数据集扩充,提高目标检测算法的泛化性;针对X射线安检图像中同类待识别物品尺寸的明显差异,提出一种细化的特征金字塔网络结构提取更加丰富的不同层次语义信息;为进一步提高检测精度,提出一个易于集成的细粒度分类模块,该模块能很好地适配主流目标检测模型。同时,构造一个大规模的基准数据集,包含
56659 张X射线安检图像,37种违禁品,每张图像均进行高质量标注。该公开X射线安检图像数据集包含的违禁品种类和图像数量较多。基于该X射线违禁品数据集进行对比实验,结果显示,所提模型结构较基线模型YOLOX-L的均值平均精度(mAP)提高约0.056。Abstract:Image object detection technology has greatly improved the work efficiency of the security inspection and further guaranteed public security. However, the differences in imaging standards among different types of security inspection machines, the complexity of X-ray images, and the expensive cost of data annotation have constrained further research of object detection technology based on X-ray security inspection images. To improve the universality of our item detection system, we extend the dataset using a style transfer approach to account for variations in X-ray imaging hues of the same substance across various security equipment manufacturers. A refined feature pyramid network structure is proposed to extract richer semantic information from different levels in response to the significant differences in the size of similar objects to be recognized in X-ray images. A fine-grained classification module, which is simple to plug into the general object detectors, is what we suggest in order to increase detection accuracy even more. Meanwhile, this dataset contains
56659 X-ray images, featuring 37 types of contraband, with each image being high-quality annotated. This is a larger publicly available X-ray image dataset in terms of both the variety of contraband types and the number of images. Based on comparative experiments conducted on this X-ray contraband dataset, the model structure proposed in this article achieved an approximate 0.056 improvement in mean average precision (mAP) compared to the baseline model. -

图 1 部分违禁品示例X射线安检图像
Figure 1. Example X-ray security inspection images of some prohibited items
表 1 数据集样本信息
Table 1. Sample information of the dataset
大类标签 细类标签 样本数 刀具 刀片 2935 美工刀 2448 特殊刀片 844 全金属折叠刀 2539 非全金属折叠刀 383 全金属柄刀 1561 非全金属柄刀 785 线形刀 52 厨刀 462 刮胡刀 309 玻璃容器 玻璃瓶 58307 酒瓶 1417 有机物容器 饮料瓶 19057 易拉罐 1086 电脑 3816 充电宝 5344 小电子设备 16328 枪 104 压力罐 3418 工具 钳子 6568 扳手 3416 锤子 578 抹泥板 1607 斧头 36 锯条 71 螺丝刀 6796 铅坠 281 凿子 192 指虎 85 手铐 56 甩棍 38 雨伞 8010 剪刀 4683 打火机 8403 金属杯 7553 打火机油罐 63 弹弓 26  下载: 导出CSV
下载: 导出CSV
表 2 各数据集对比
Table 2. Comparison of various datasets
下载: 导出CSV
表 3 各检测模型实验结果
Table 3. Experimental results of each detection model
大类标签 样本数 平均精度 Cascade R-CNN[4] YOLOX-L[18] YOLOX-L-FG 刀具 2453 0.326 0.696 0.744 工具 3776 0.478 0.730 0.773 玻璃容器 11867 0.747 0.887 0.870 有机物容器 3975 0.633 0.828 0.826 电脑 784 0.937 0.971 0.898 充电宝 1139 0.731 0.863 0.850 小电子设备 3378 0.790 0.904 0.867 枪 23 0.351 0.333 0.517 压力罐 669 0.410 0.574 0.731 指虎 19 0.506 0.657 0.789 手铐 9 0.722 0.749 0.495 雨伞 1664 0.922 0.968 0.897 剪刀 891 0.488 0.619 0.731 打火机 1657 0.583 0.741 0.773 金属杯 1507 0.947 0.974 0.899 打火机油罐 4 0.250 0.250 0.545 弹弓 8 0.042 0.198 0.432 甩棍 7 0.071 0.429 0.732 注:mAP为表中所有18个类别平均精度的算术平均值;Cascade R-CNN、YOLOX-L、YOLOX-L-FG的mAP分别为0.552、0.687、0.743。
下载: 导出CSV
表 4 FG模块集成前后均值平均精度对比
Table 4. Comparison of mean average precision before and after FG module integration
下载: 导出CSV
-
[1] GAUS Y F A, BHOWMIK N, AKCAY S, et al. Evaluating the transferability and adversarial discrimination of convolutional neural networks for threat object detection and classification within X-ray security imagery[C]//Proceedings of the 2019 18th IEEE International Conference on Machine Learning and Applications. Piscataway: IEEE Press, 2019: 420-425. [2] 张顺, 龚怡宏, 王进军. 深度卷积神经网络的发展及其在计算机视觉领域的应用[J]. 计算机学报, 2019, 42(3): 453-482. doi: 10.11897/SP.J.1016.2019.00453ZHANG S, GONG Y H, WANG J J. The development of deep convolution neural network and its applications on computer vision[J]. Chinese Journal of Computers, 2019, 42(3): 453-482(in Chinese). doi: 10.11897/SP.J.1016.2019.00453 [3] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector[C]//Proceedings of the Computer Vision-ECCV 2016. Berlin: Springer, 2016: 21-37. [4] CAI Z W, VASCONCELOS N. Cascade R-CNN: delving into high quality object detection[C]//Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 6154-6162. [5] 王坤, 冯康威. 基于改进YOLOv5的交通场景小目标检测算法[J/OL]. 北京航空航天大学学报, 2024(2024-03-12)[2024-06-19]. https://link.cnki.net/doi/10.13700/j.bh.1001-5965.2024.0003.WANG K, FENG K W. Small target detection algorithm for traffic scene based on improved YOLOv5[J/OL]. Journal of Beijing University of Aeronautics and Astronautics, 2024 (2024-03-12)[2024-06-19]. https://link.cnki.net/doi/10.13700/j.bh.1001-5965.2024.0003(in Chinese). [6] JIAO L C, ZHANG F, LIU F, et al. A survey of deep learning-based object detection[J]. IEEE Access, 2019, 7: 128837-128868. doi: 10.1109/ACCESS.2019.2939201 [7] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2014: 580-587. [8] HE K M, ZHANG X Y, REN S Q, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916. doi: 10.1109/TPAMI.2015.2389824 [9] GIRSHICK R. Fast R-CNN[C]//Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2016: 1440-1448. [10] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 779-788. [11] ARKIN E, YADIKAR N, XU X B, et al. A survey: object detection methods from CNN to Transformer[J]. Multimedia Tools and Applications, 2023, 82(14): 21353-21383. doi: 10.1007/s11042-022-13801-3 [12] VASANTHI P, MOHAN L. Multi-Head-Self-Attention based YOLOv5X-Transformer for multi-scale object detection[J]. Multimedia Tools and Applications, 2024, 83(12): 36491-36517. [13] LIU J Y, LENG X X, LIU Y. Deep convolutional neural network based object detector for X-ray baggage security imagery[C]//Proceedings of the IEEE 31st International Conference on Tools with Artificial Intelligence. Piscataway: IEEE Press, 2020: 1757-1761. [14] WANG B Y, ZHANG L B, WEN L Y, et al. Towards real-world prohibited item detection: a large-scale X-ray benchmark[C]//Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2022: 5392-5401. [15] LIANG K J, SIGMAN J B, SPELL G P, et al. Toward automatic threat recognition for airport X-ray baggage screening with deep convolutional object detection[EB/OL]. (2019-12-13)[2024-06-19]. https://arxiv.org/abs/1912.06329. [16] MERY D, RIFFO V, ZSCHERPEL U, et al. GDXray: the database of X-ray images for nondestructive testing[J]. Journal of Nondestructive Evaluation, 2015, 34(4): 42. doi: 10.1007/s10921-015-0315-7 [17] WEI Y L, TAO R S, WU Z J, et al. Occluded prohibited items detection: an X-ray security inspection benchmark and de-occlusion attention module[C]//Proceedings of the 28th ACM International Conference on Multimedia. New York: ACM, 2020: 138-146. [18] GE Z, LIU S T, WANG F, et al. YOLOX: exceeding YOLO series in 2021[EB/OL]. (2021-08-06)[2024-06-19]. https://arxiv.org/abs/2107.08430. -

 下载:
下载:

 点击查看大图
点击查看大图

计量
- 文章访问数: 323
- HTML全文浏览量: 57
- PDF下载量: 12
- 被引次数: 0
