



-
摘要:
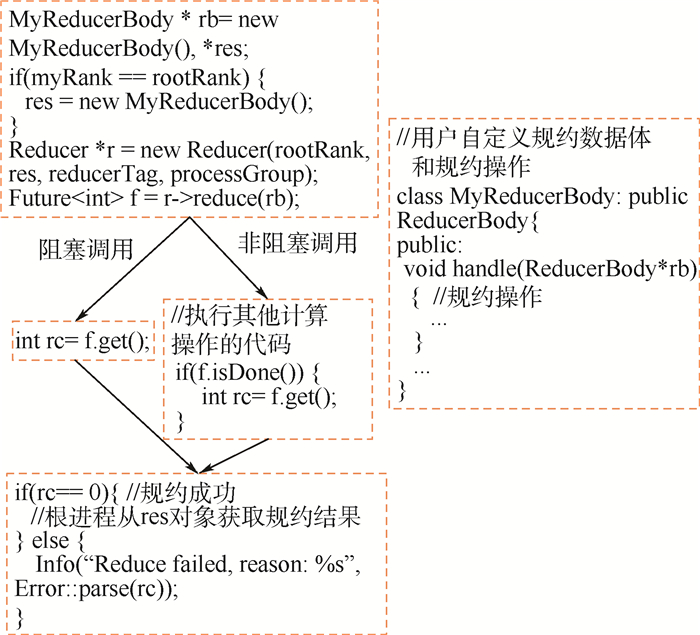
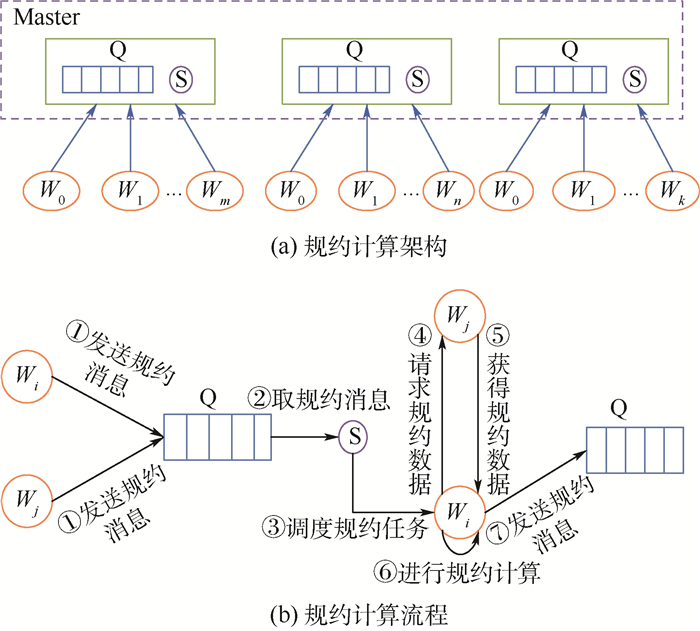
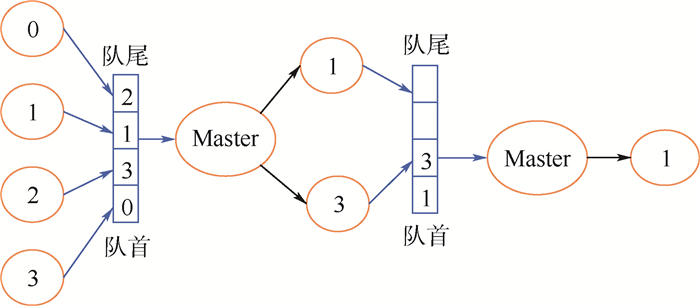
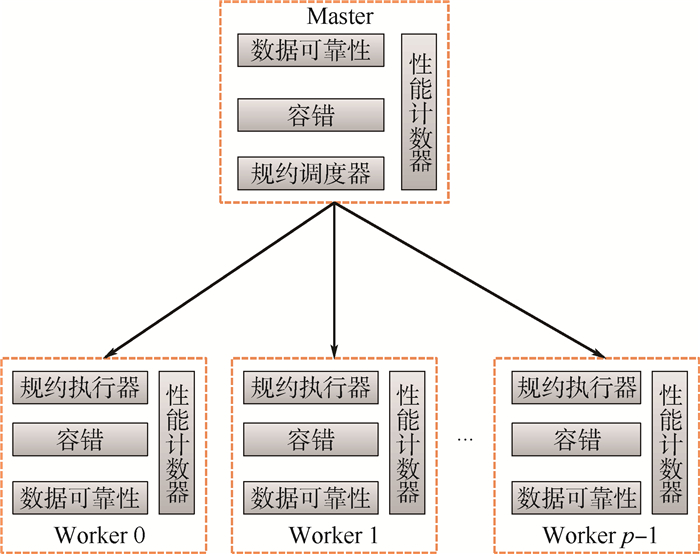
规约是并行应用最常用的集合通信操作之一,现存规约算法存在2方面主要问题。第一,不适应复杂环境,当计算环境出现干扰时,规约效率显著降低。第二,不支持容错,当节点发生故障时,规约被迫中断。针对上述问题,提出一种基于任务并行的高性能分布式规约框架。首先,该框架将规约拆分为一系列独立的计算任务,使用任务调度器以保证就绪任务被优先调度到具有较高性能的节点上执行,从而有效避免了慢节点对整体性能的影响。其次,该框架基于规约数据的可靠性存储和故障侦听机制,以任务为粒度,可在应用不退出的前提下实现故障恢复。在复杂环境中的实验结果表明,分布式规约框架具有高可靠性,与现有规约算法相比,规约性能最高提升了2.2倍,并发规约性能最高提升了4倍。
Abstract:Reduction is one of the most commonly used collective communication operations for parallel applications. There are two problems for the existing reduction algorithms:First, they cannot adapt to complex environment. When interferences appear in computing environment, the efficiency of reduction degrades significantly. Second, they are not fault tolerant. The reduction operation is interrupted when a node failure occurs. To solve these problems, this paper proposes a task-based parallel high-performance distributed reduction framework. Firstly, each reduction operation is divided into a series of independent computing tasks. The task scheduler is adopted to guarantee that ready tasks will take precedence in execution and each task will be scheduled to the computing node with better performance. Thus, the side effect of slow nodes on the whole efficiency can be reduced. Secondly, based on the reliability storage for reduction data and fault detecting mechanism, fault tolerance can be implemented in tasks without stopping the application. The experimental results in complex environment show that the distributed reduction framework promises high availability and, compared with the existing reduction algorithm, the reduction performance and concurrent reduction performance of distributed reduction framework are improved by 2.2 times and 4 times, respectively.
-
Key words:
- reduction /
- collective communication /
- complex environment /
- interference /
- fault tolerance /
- parallel computing
-

图 6 理想环境中规约性能及并发规约性能对比
Figure 6. Comparison of reduction performance and concurrent reduction performance in ideal environment

图 7 受控复杂环境中规约性能对比
Figure 7. Comparison of reduction performance in controlled complex environment

图 8 受控复杂环境中并发规约性能对比
Figure 8. Comparison of concurrent reduction performance in controlled complex environment

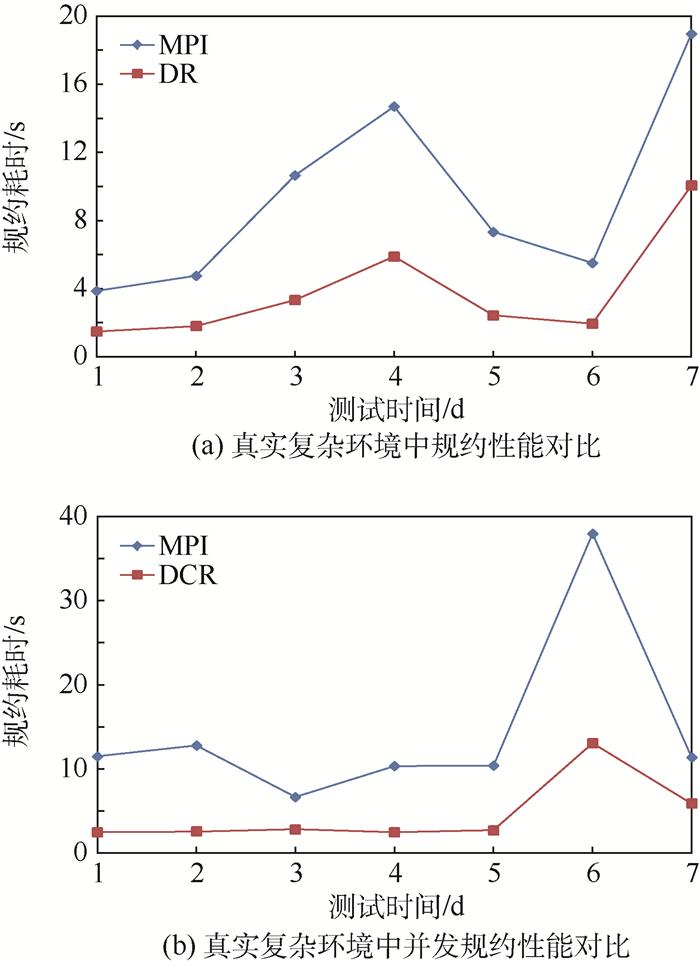
图 9 真实复杂环境中规约性能及并发规约性能对比
Figure 9. Comparison of reduction performance and concurrent reduction performance in real complex environment
表 1 规约过程中各项指标的平均值
Table 1. Average value of various indexes during reduction
数据规模/B 接收消息/(次·s-1) 发送消息/(次·s-1) 接收带宽/(B·s-1) 发送带宽/(B·s-1) 217 5 220 2 604 605 167 374 907 218 5 005 2 496 580 282 359 489 219 4 996 2 492 579 242 358 845 220 4 460 2 225 517 104 320 350 221 3 957 1 973 458 693 284 164 222 3 302 1 647 382 835 237 169 223 2 400 1 197 278 278 172 396 224 1 543 769 178 854 110 802 225 923 461 107 060 66 325 226 479 239 55 484 34 373 227 250 124 29 026 17 982  下载: 导出CSV
下载: 导出CSV
表 2 分布式规约的容错实验结果
Table 2. Experimental fault tolerant results of distributed reduction
实验编号 运行次数 无法恢复故障数量 1 100 2 2 100 1 3 100 0 4 100 2 5 100 3 6 100 1 7 100 2
下载: 导出CSV
-
[1] GROPP W, LUSK E, DOSS N, et al.A high-performance, portable implementation of the MPI message passing interface standard[J].Parallel Computing, 1996, 22(6):789-828. doi: 10.1016/0167-8191(96)00024-5 [2] RABENSEIFNER R.Automatic MPI counter profiling of all users: First results on a CRAY T3E 900-512[C]//Proceedings of the Message Passing Interface Developer's and User's Conference.Piscataway, NJ: IEEE Press, 1999: 77-85 [3] CHAN W E, HEIMLICH F M, PURAKAYASTHA A, et al.On optimizing collective communication[C]//Proceedings of the IEEE International Conference on Cluster Computing.Piscataway, NJ: IEEE Press, 2004: 145-155. http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=1392612 [4] GROPP W, LUSK E.Users guide for mpich, a portable implementation of MPI[J].Office of Scientific & Technical Information Technical Reports, 1996, 1996(17):2096-2097. http://cn.bing.com/academic/profile?id=64fad27e4303ac564329122091eadcbb&encoded=0&v=paper_preview&mkt=zh-cn [5] THAKUR R, RABENSEIFNER R, GROPP W.Optimization of collective communication operations in MPICH[J].International Journal of High Performance Computing Applications, 2005, 19(1):49-66. http://cn.bing.com/academic/profile?id=79fa16e26fbe582c2633beae0863758d&encoded=0&v=paper_preview&mkt=zh-cn [6] HUSBANDS P, HOE J C.MPI-StarT: Delivering network performance to numerical applications[C]//Proceedings of the ACM/IEEE Conference on Supercomputing.Piscataway, NJ: IEEE Press, 1998: 1-15. http://ieeexplore.ieee.org/document/1437304/ [7] VADHIYAR S S, FAGG E G, DONGARRA J.Automatically tuned collective communications[C]//Proceedings of the ACM/IEEE Conference on Supercomputing.Piscataway, NJ: IEEE Press, 2000: 3-13. http://dl.acm.org/citation.cfm?id=370055 [8] GONG Y, HE B, ZHONG J.An overview of CMPI:Network performance aware MPI in the cloud[J].ACM SIGPLAN Notices, 2012, 47(8):297-298. doi: 10.1145/2370036 [9] GONG Y, HE B, ZHONG J.Network performance aware MPI collective communication operations in the cloud[J].IEEE Transactions on Parallel and Distributed Systems, 2015, 26(11):3079-3089. doi: 10.1109/TPDS.2013.96 [10] MAKPAISIT P, ICHIKAWA K, UTHAYOPAS P, et al.MPI_reduce algorithm for open flow-enabled network[C]//Proceedings of the IEEE International Symposium on Communications and Information Technologies.Piscataway, NJ: IEEE Press, 2015: 261-264. http://ieeexplore.ieee.org/document/7458357/ [11] HASANOV K, LASTOVETSKY A.Hierarchical optimization of MPI reduce algorithms[J].Lecture Notes in Computer Science, 2015, 9251:21-34. doi: 10.1007/978-3-319-21909-7 [12] KIELMANN T, HOFMAN R F H, BAl H E, et al.MagPIe:MPI's collective communication operations for clustered wide area systems[J].ACM SIGPLAN Notices, 1999, 34(8):131-140. doi: 10.1145/329366 [13] HEIEN E, KONDO D, GAINARU A, et al.Modeling and tolerating heterogeneous failures in large parallel systems[C]//Proceedings of International Conference for High Performance Computing, Networking, Storage and Analysis.Piscataway, NJ: IEEE Press, 2001: 1-11. doi: 10.1145/2063384.2063444 [14] SCHROEDER B, GIBSON G.Understanding failures in petascale computers[C]//Journal of Physics: Conference Series.Philadelphia, PA: IOP Publishing, 2007: 12-22. http://adsabs.harvard.edu/abs/2007JPhCS..78a2022S [15] ELNOZAHY E, ALVISI L, WANG Y, et al.A survey of rollback-recovery protocols in message-passing systems[J].ACM Computing Surveys(CSUR), 2002, 34(3):375-408. doi: 10.1145/568522.568525 [16] BRONEVETSKY G, MARQUES D, PINGALI K, et al.C3:A system for automating application-level checkpointing of MPI Programs[J].Lecture Notes in Computer Science, 2003, 2958:357-373. http://d.old.wanfangdata.com.cn/Periodical/qhdxxb-zr201306013 [17] FAGG E G, DONGARRA J.FT-MPI:Fault tolerant MPI, supporting dynamic applications in a dynamic world[M].Berlin:Springer, 2000:346-353. [18] HURSEY J, GRAHAM R L.Analyzing fault aware collective performance in a process fault tolerant MPI[J].Parallel Computing, 2012, 38(1):15-25. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=JJ0226205679 [19] WANG R, YAO E, CHEN M, et al.Building algorithmically nonstop fault tolerant MPI programs[C]//Proceedings of IEEE International Conference on High Performance Computing (HiPC).Piscataway, NJ: IEEE Press, 2011: 1-9. http://ieeexplore.ieee.org/document/6152716/ [20] CHEN Z, DONGARRA J.Algorithm-based fault tolerance for fail-stop failures[J].IEEE Transactions on Parallel and Distributed Systems, 2008, 19(12):1628-1641. doi: 10.1109/TPDS.2008.58 [21] GORLATCH S.Send-receive considered harmful:Myths and realities of message passing[J].ACM Transactions on Programming Languages & Systems, 2004, 26(1):47-56. http://cn.bing.com/academic/profile?id=69d1c8c7a75a074f254e3132a84064ba&encoded=0&v=paper_preview&mkt=zh-cn [22] LI C, ZHAO C, YAN H, et al.Event-driven fault tolerance for building nonstop active message programs[C]//Proceedings of IEEE International Conference on High Performance Computing.Piscataway, NJ: IEEE Press, 2013: 382-390. http://ieeexplore.ieee.org/document/6831944/ [23] LI C, WANG Y, ZHAO C, et al.Parallel Kirchhoff pre-stack depth migration on large high performance clusters[M].Berlin:Springer, 2015:251-266. -

 下载:
下载:





 点击查看大图
点击查看大图
计量
- 文章访问数: 531
- HTML全文浏览量: 46
- PDF下载量: 361
- 被引次数: 0
