



-
摘要:
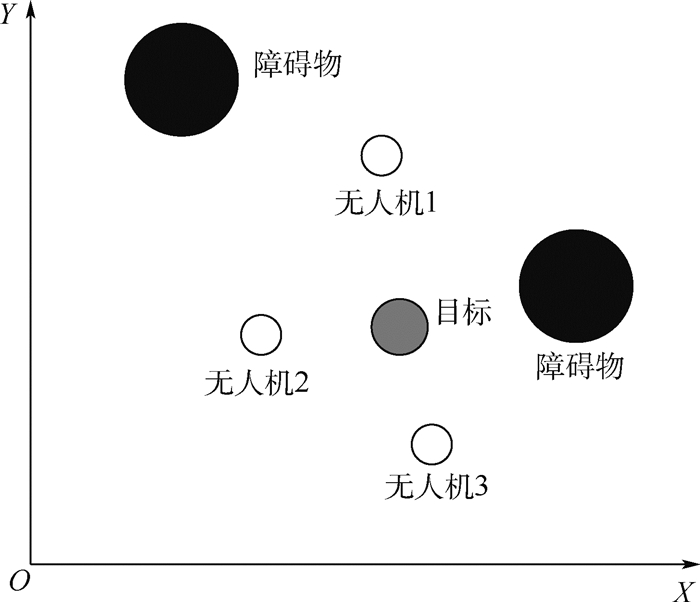
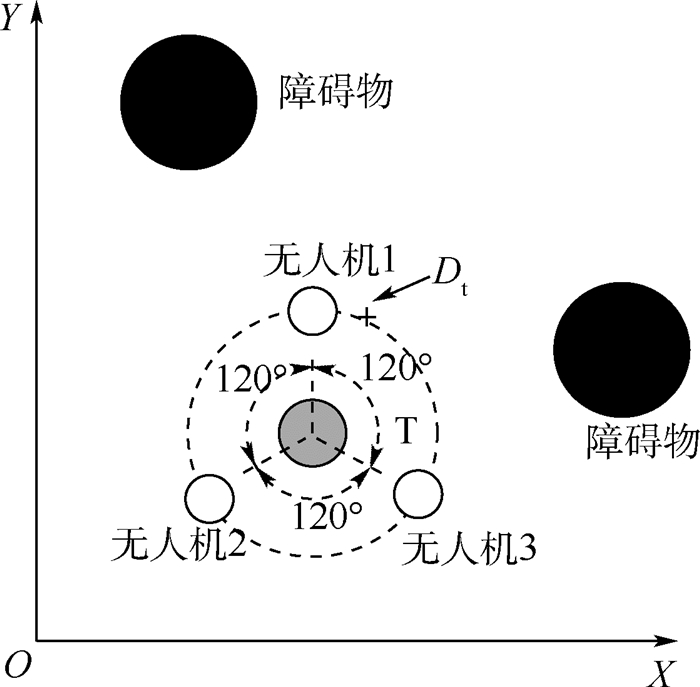
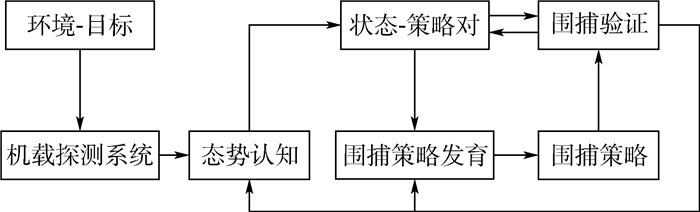
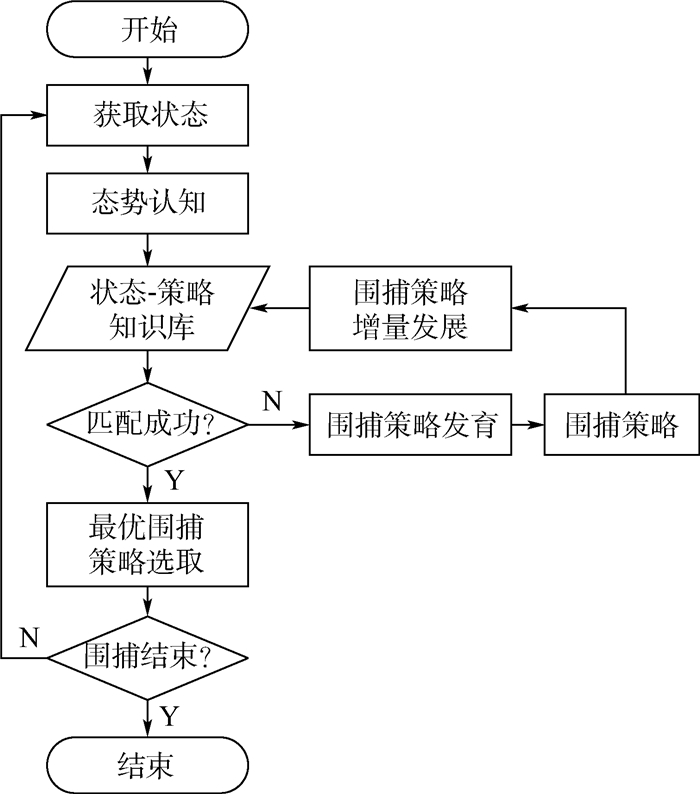
无人机集群围捕是智能无人机“蜂群”作战的一种重要任务方式。现有集群围捕方法大多建立在环境已知的基础上,面对未知的任务环境时围捕策略经常性失效。针对此问题,提出了基于态势认知的发育模型,探索一种对环境适应性较佳的围捕方法。首先,对集群围捕行为分解,将围捕离散化;然后,基于深度Q神经网络(DQN),设计一种围捕策略的生成方法;最后,建立状态-策略知识库,并通过大量有效数据的训练,针对不同环境获得不同的策略,对知识库进行发育。仿真结果表明:提出的基于态势认知的发育模型,能够有效适应不同环境,完成不同环境下的围捕。
-
关键词:
- 无人机 /
- 集群围捕 /
- 态势认知 /
- 深度Q神经网络(DQN) /
- 自主发育
Abstract:UAV swarm rounding up is an important mission mode of intelligent UAV swarm operation. Most of the existing swarm rounding up methods are based on the known environment, and the strategy often fails in the face of unknown mission environment. To solve this problem, a developmental model based on situation cognition is proposed in this paper to explore a better adaptive method of rounding up. First, the swarm rounding up behavior is decomposed and the rounding up is discretized. Then, based on the Deep Q-Network (DQN), a method of generating the rounding up strategy is designed. Finally, the state-strategy knowledge base is established, and through the training of a large amount of effective data, different strategies are obtained according to different environments to develop the knowledge base. The simulation results show that the proposed developmental model based on situation cognition can effectively adapt to different environments and complete the rounding up in different environments.
-
Key words:
- UAV /
- swarm rounding up /
- situation cognition /
- Deep Q-Network (DQN) /
- autonomous development
-
表 1 无人机与目标参数设定
Table 1. Parameter setting of UAV and target
参数 数值 坐标轴范围/m [-25, 25] 围捕者最大速度/(m·s-1) 3 围捕者最大加速度/(m·s-2) 3 围捕者探测距离/m 10 目标最大速度/(m·s-1) 5 目标最大加速度/(m·s-2) 5 目标探测距离/m 5  下载: 导出CSV
下载: 导出CSV
表 2 障碍物生成参数
Table 2. Obstacle generation parameters
参数 数值 数目均值 3 数目变化范围 0~5 位置范围/m [-24, 24] 直径均值/m 4 直径变化范围/m 2~8
下载: 导出CSV
-
[1] 段海滨, 李沛. 基于生物群集行为的无人机集群控制[J]. 科技导报, 2017, 35(7): 17-25. https://www.cnki.com.cn/Article/CJFDTOTAL-KJDB201707010.htmDUAN H B, LI P. Autonomous control for unmanned aerial vehicle swarms based on biological collective behaviors[J]. Science & Technology Review, 2017, 35(7): 17-25(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-KJDB201707010.htm [2] OLFATISABER R. Flocking for multi-agent dynamic systems: Algorithms and theory[J]. IEEE Transactions on Automatic Control, 2006, 51(3): 401-420. doi: 10.1109/TAC.2005.864190 [3] 黄天云, 陈雪波, 徐望宝. 基于松散偏好规则的群体机器人系统自组织协作围捕[J]. 自动化学报, 2013, 39(1): 57-68. https://www.cnki.com.cn/Article/CJFDTOTAL-MOTO201301008.htmHUANG T Y, CHEN X B, XU W B. A self-organizing cooperative hunting by swarm robotic systems based on loose-preference rule[J]. Acta Automatica Sinica, 2013, 39(1): 57-68(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-MOTO201301008.htm [4] 李瑞珍, 杨惠珍, 萧丛杉. 基于动态围捕点的多机器人协同策略[J]. 控制工程, 2019, 26(3): 510-514. https://www.cnki.com.cn/Article/CJFDTOTAL-JZDF201903017.htmLI R Z, YANG H Z, XIAO C S. Cooperative hunting strategy for multi-mobile robot systems based on dynamic hunting points[J]. Control Engineering of China, 2019, 26(3): 510-514(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-JZDF201903017.htm [5] 张子迎, 吕骏, 徐东, 等. 能量均衡的围捕任务分配方法[J]. 国防科技大学学报, 2019, 41(2): 107-114. https://www.cnki.com.cn/Article/CJFDTOTAL-GFKJ201902016.htmZHANG Z Y, LV J, XU D, et al. Method of capturing task allocation based on energy balabce[J]. Journal of National University of Defense Technology, 2019, 41(2): 107-114(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-GFKJ201902016.htm [6] UEHARA S, TAKIMOTO M, KAMBAYASHI Y.Mobile agent based obstacle avoidance in multi-robot hunting[M]//GEN M, GREEN D, KATAI O, et al.Intelligent and evolutionary systems.Berlin: Springer, 2017: 443-452. [7] VLAHOV B, SQUIRES E, STRICKLAND L, et al.On developing a UAV pursuit-evasion policy using reinforcement learning[C]//201817th IEEE International Conference on Machine Learning and Applications (ICMLA).Piscataway: IEEE Press, 2018: 859-864. [8] 谭浪, 巩庆海, 王会霞. 基于深度强化学习的追逃博弈算法[J]. 航天控制, 2018, 36(6): 3-8. https://www.cnki.com.cn/Article/CJFDTOTAL-HTKZ201806001.htmTAN L, GONG Q H, WANG H X. Pursuit-evasion game algorithm based on deep reinforcement learning[J]. Aerospace Control, 2018, 36(6): 3-8(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-HTKZ201806001.htm [9] TENG T H, TAN A H, ZURADA J M. Selforganizing neural networks integrating domain knowledge and reinforcement learning[J]. IEEE Transactions on Neural Networks and Learning Systems, 2014, 26(5): 889-902. http://www.ncbi.nlm.nih.gov/pubmed/25881365 [10] BEVERIDGE A, CAI Y. Pursuit-evasion in a two-dimensional domain[J]. ARS Mathematica Contemporanea, 2017, 13(1): 187-206. doi: 10.26493/1855-3974.1060.031 [11] LIU J, LIU S, WU H, et al.A pursuit-evasion algorithm based on hierarchical reinforcement learning[C]//2009 International Conference on Measuring Technology and Mechatronics Automation.Piscataway: IEEE Press, 2009, 2: 482-486. [12] BILGIN A T, KADIOGLU-URTIS E.An approach to multiagent pursuit evasion games using reinforcement learning[C]//2015 International Conference on Advanced Robotics (ICAR).Piscataway: IEEE Press, 2015: 164-169. [13] AWHEDA M D, SCHWARTZ H M.A fuzzy reinforcement learning algorithm using a predictor for pursuit-evasion games[C]//2016 Annual IEEE Systems Conference(SysCon).Piscataway: IEEE Press, 2016: 1-8. [14] LOWE R, WU Y I, TAMAR A, et al.Multi-agent actor-critic for mixed cooperative-competitive environments[C]//Advances in Neural Information Processing Systems, 2017: 6379-6390. [15] VAN HASSELT H, GUEZ A, SILVER D, et al.Deep reinforcement learning with double Q-learning[C]//National Conference on Artificial Intelligence, 2016: 2094-2100. [16] HAUSKNECHT M, STONE P.Deep recurrent Q-learning for partially observable MDPS[EB/OL].(2015-07-23)[2020-06-01].https://arxiv.org/abs/1507.06527. [17] HESTER T, VECERIK M, PIETQUIN O, et al.Deep Q-learning from demonstrations[C]//National Conference on Artificial Intelligence, 2018: 3223-3230. [18] 魏瑞轩, 张启瑞, 许卓凡. 类脑发育无人机防碰撞控制[J]. 控制理论与应用, 2019, 36(2): 13-20. https://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201902002.htmWEI R X, ZHANG Q R, XU Z F. A brain-like mechanism for developmental UAVs' collision avoidance[J]. Control Theory & Applications, 2019, 36(2): 13-20(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201902002.htm [19] MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518: 529-533. doi: 10.1038/nature14236 [20] MORDATCH I, ABBEEL P.Emergence of grounded compositional language in multi-agent populations[EB/OL].(2017-03-15)[2020-06-01].https://arxiv.org/abs/1703.04908. -

 下载:
下载:
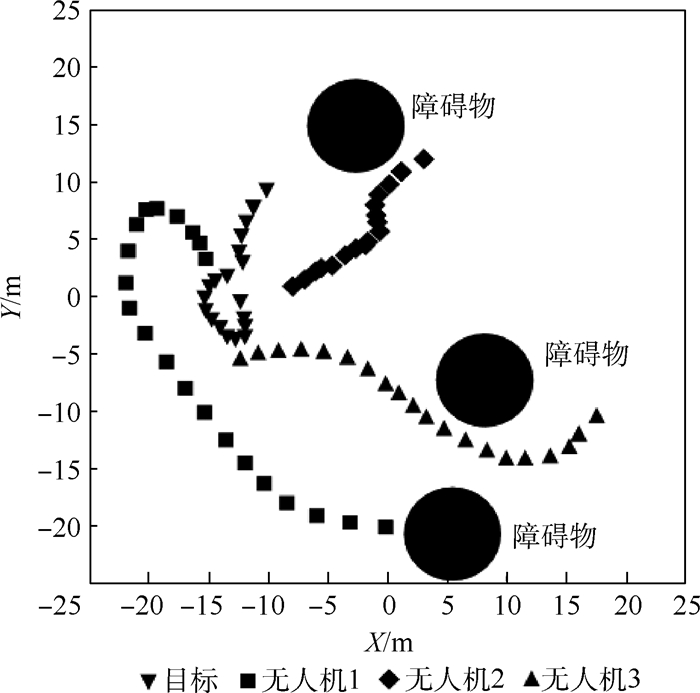
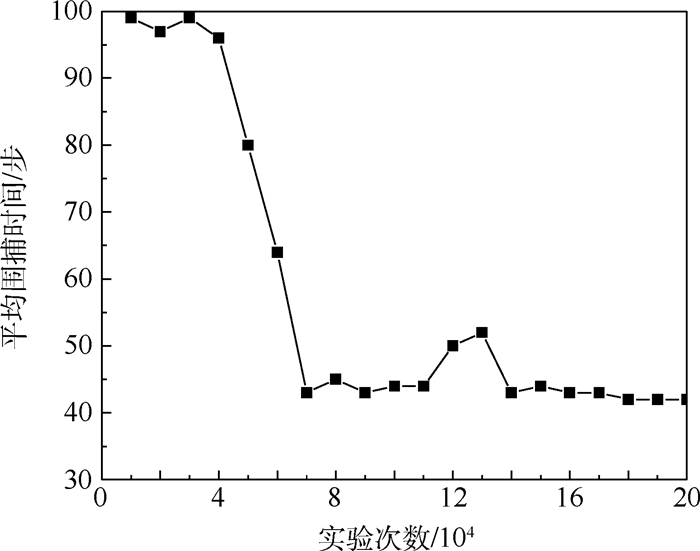
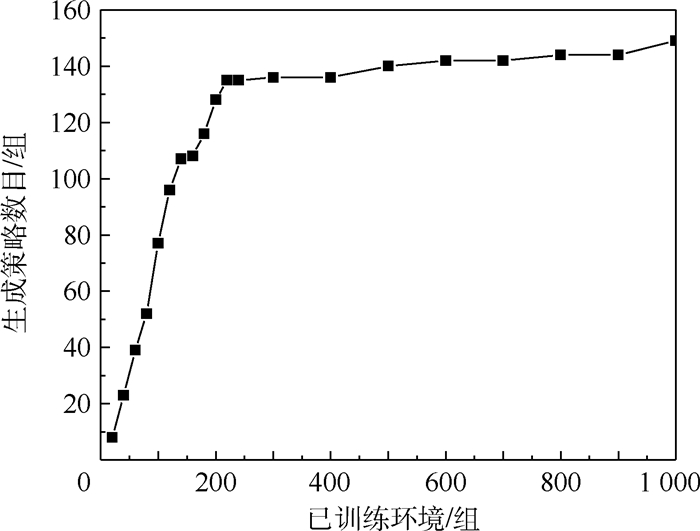
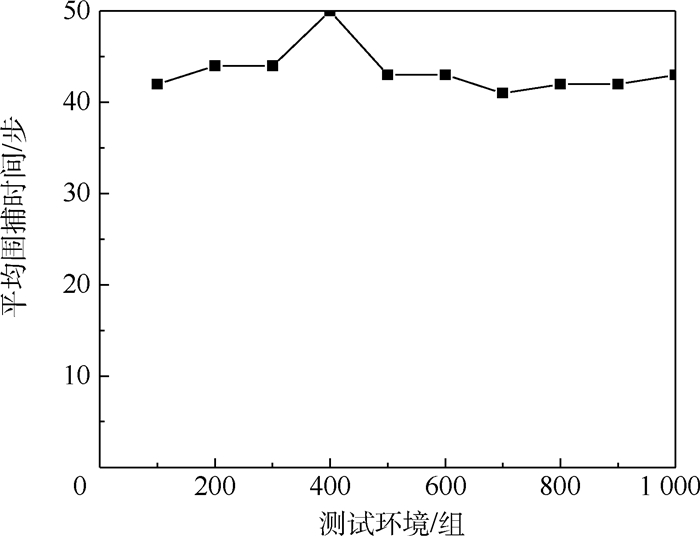

 点击查看大图
点击查看大图

计量
- 文章访问数: 1610
- HTML全文浏览量: 170
- PDF下载量: 249
- 被引次数: 0
