



-
摘要:
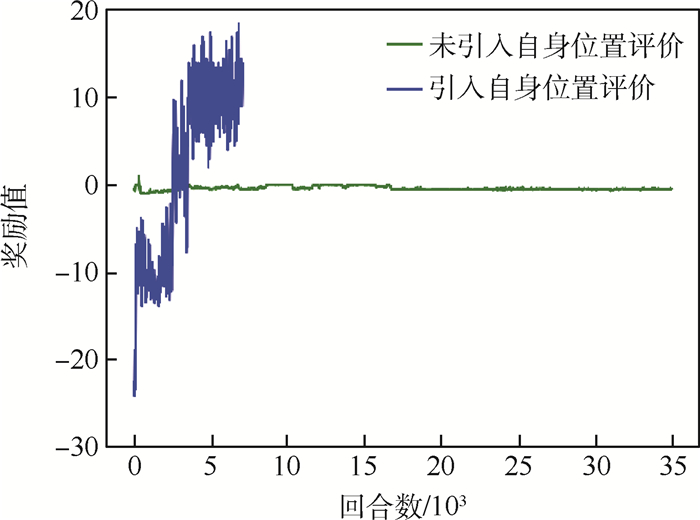
为解决强化学习算法在自主导航任务中动作输出不连续、训练收敛困难等问题, 提出了一种基于近似策略优化(PPO)算法的移动平台自主导航方法。在PPO算法的基础上设计了基于正态分布的动作策略函数, 解决了移动平台整车线速度和横摆角速度的输出动作连续性问题。设计了一种改进的人工势场算法作为自身位置评价, 有效提高强化学习模型在自主导航场景中的收敛速度。针对导航场景设计了模型的网络框架和奖励函数, 并在Gazebo仿真环境中进行模型训练, 结果表明, 引入自身位置评价的模型收敛速度明显提高。将收敛模型移植入真实环境中, 验证了所提方法的有效性。
Abstract:This paper presents an autonomous navigation method based on proximal policy optimization (PPO) algorithm for mobile platform. In this method, GNSS and LADAR are used for sensing environment information. To define the state of reinforcement learning model, an ego position evaluation method is introduced based on improved artificial potential field algorithm. After that, on the basis of PPO algorithm, a kind of action policy function is designed based on Gaussian distribution, which solves the continuity problem of the vehicle linear velocity and yaw velocity. Furthermore, the network framework and reward function of the model are also designed for navigation scenarios. In order to train the navigation model, a virtual environment based on Gazebo is built. The training results show that the ego position evaluation method obviously helps to improve the speed of model convergence. Finally, the navigation model is transplanted to a real environment, which verifies the effectiveness of the proposed method.
-

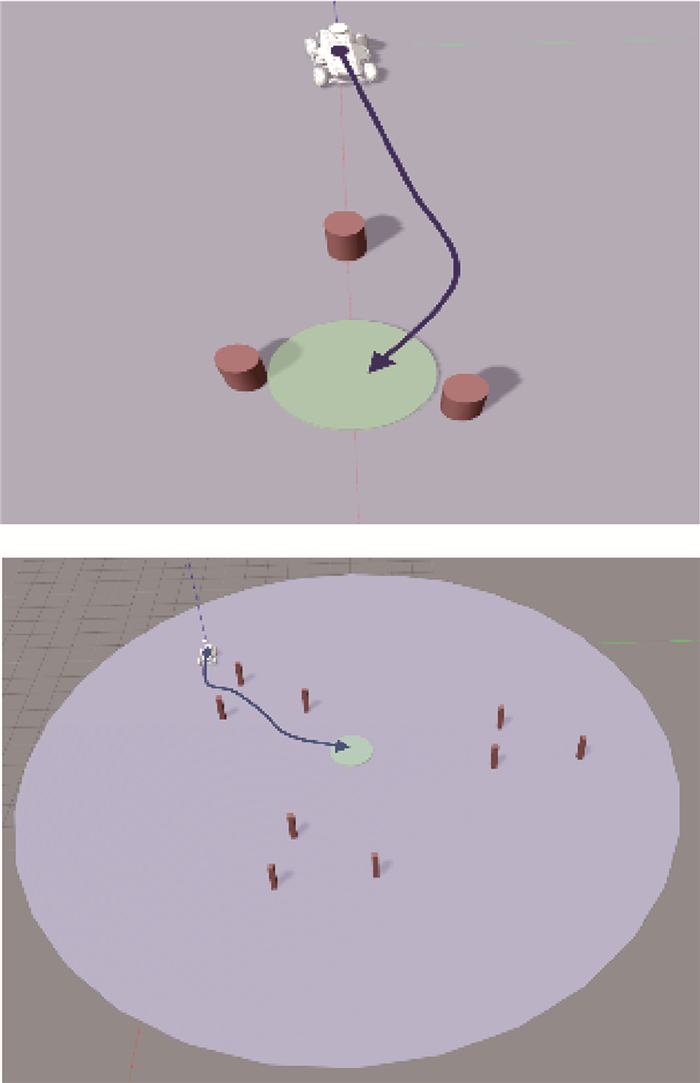
图 6 仿真环境中导航模型所习得路径
Figure 6. Learned path of navigation model in simulation environment
-
[1] 王义林. 地面无人平台自主导航避障系统的研究与实现[D]. 哈尔滨: 哈尔滨工业大学, 2020.WANG Y L. Research and implementation of autonomous navigation and obstacle avoidance system for ground unmanned platform[D]. Harbin: Harbin Institute of Technology, 2020(in Chinese). [2] 秦圣然. 基于激光传感器的移动机器人导航系统研究[D]. 沈阳: 沈阳工业大学, 2020.QIN S R. Research on laser sensor-based navigation system for mobile robots[D]. Shenyang: Shenyang University of Technology, 2020(in Chinese). [3] HART P E, NILSSON N J, RAPHAEL B. A formal basis for the heuristic determination of minimum cost paths in graphs[J]. IEEE Transactions on Systems Science and Cybernetics, 1968, 4(2): 100-107. doi: 10.1109/TSSC.1968.300136 [4] STENT A. Optimal and efficient path planning for partially-known environments[C]//Proceedings of IEEE International Conference on Robotics and Automation. Piscataway: IEEE Press, 1994, 4: 3310-3317. [5] STENT A. The focussed D* algorithm for real-time replanning[C]//Proceedings of the 14th International Joint Conference on Artificial Intelligence. New York: ACM, 1995: 1652-1659. [6] LAVALLE S M, KUFFNER J J. Randomized kinodynamic planning[C]//Proceedings of IEEE International Conference on Robotics and Automation. Piscataway: IEEE Press, 1999, 1: 473-479. [7] 付雪建. 基于强化学习的移动机器人自主导航研究[D]. 重庆: 重庆大学, 2017.FU X J. Research on autonomous navigation of mobile robots based on reinforcement learning[D]. Chongqing: Chongqing University, 2017(in Chinese). [8] 杨宁博. 面向环境探测的全向模式移动机器人自主导航研究[D]. 哈尔滨: 哈尔滨工业大学, 2019.YANG N B. Research on autonomous navigation of omnidirectional mode mobile robots for environmental detection[D]. Harbin: Harbin Institute of Technology, 2019(in Chinese). [9] 陶睿. 基于深度强化学习的移动机器人导航[D]. 济南: 山东大学, 2020.TAO R. Deep reinforcement learning-based navigation for mobile robots[D]. Jinan: Shandong University, 2020(in Chinese). [10] 何聪. 基于深度强化学习的机器人视觉导航算法[D]. 南京: 东南大学, 2021.HE C. Robot visual navigation algorithm based on deep reinforcement learning[D]. Nanjing: Southeast University, 2021(in Chinese). [11] TAI L, PAOLO G, LIU M. Virtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless navigation[C]//IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway: IEEE Press, 2017: 31-36. [12] SCHULMAN J, WOLSKI F, DHARIWAL P, et al. Proximal policy optimization algorithms[EB/OL]. (2017-08-28)[2021-03-01]. https://arxiv.org/abs/1707.06347. [13] 刘志平, 余前勇, 査剑锋. 空间直角坐标至两类常用坐标的快速变换[J]. 测绘科学, 2015, 40(3): 8-11. https://www.cnki.com.cn/Article/CJFDTOTAL-CHKD201503002.htmLIU Z P, YU Q Y, ZHA J F. Fast coordinate transformations for both XYZ-BLH and XYZ-RhA[J]. Science of Surveying and Mapping, 2015, 40(3): 8-11(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-CHKD201503002.htm [14] 刘山洪, 邓彩群. 坐标转换与坐标变换研究[J]. 吉林建筑大学学报, 2016, 33(1): 43-47. https://www.cnki.com.cn/Article/CJFDTOTAL-JLJZ201601011.htmLIU S H, DENG C Q. Transformation of coordinate system[J]. Journal of Jilin Jianzhu University, 2016, 33(1): 43-47(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-JLJZ201601011.htm [15] KHATIB O. Real-time obstacle avoidance system for manipulators and mobile robots[J]. International Journal of Robotics Research, 1986, 5(1): 90-98. doi: 10.1177/027836498600500106 -

 下载:
下载:







 点击查看大图
点击查看大图

计量
- 文章访问数: 343
- HTML全文浏览量: 132
- PDF下载量: 38
- 被引次数: 0
