



-
摘要:
针对强化学习(RL)应用于无人机自主控制中学习效率低的问题,结合示教学习利用专家经验对其进行改进,提出基于示教知识辅助的无人机RL控制算法。通过设立示教目标函数、修正值函数,将专家经验作为监督信号引入到策略更新中,实现专家经验对基于RL的无人机自主控制系统优化过程的引导,同时,设置专家经验样本缓存库,利用经验优先回放机制赋予经验样本不同的利用率,提高数据的使用效率。仿真结果表明:与普通的无人机RL控制器相比,所提算法能够在训练初期快速获得奖励值,整个学习过程中获得的奖励值更高,学习到的控制策略的响应速度更快、准确性更高。示教知识的加入有效引导了算法的学习,提高了无人机自主控制系统的学习效率,同时,能够提高算法的性能,有利于学习到更好的控制策略。此外,示教知识的加入扩大了经验数据的种类,有利于促进算法的稳定性,使无人机自主控制系统对奖励函数的设置具有鲁棒性。
Abstract:The practical application of reinforcement learning (RL) in an unmanned aerial vehicle control is restricted by low learning efficiency. An algorithm integrating RL with imitation learning was proposed to improve the performance of autonomous flight control systems. By establishing new loss and value functions, demonstrations were included as supervisory signals to actor and critic networks updating. Two replay buffers were utilized to store demonstration data and the data generated by interacting with the environment respectively. The prioritized experience replay system enhances the use of high-quality data and may assess the ratio of experience data utilization while learning. Simulation results showed that the RL control algorithm with demonstrations quickly obtained high rewards in the early stage of training and it had higher rewards during the whole training process than the conventional RL algorithm. The control strategy obtained by the proposed algorithm had faster response speed and higher control precision. Demonstrations enhance both the performance of the algorithm and the learning efficiency of the unmanned aerial vehicle autonomous control system, which makes it easier to learn more effective control techniques. The addition of demonstrations expands experience data, and increases the stability of the algorithm, making the unmanned aerial vehicle autonomous control system robust to the setting of the reward function.
-
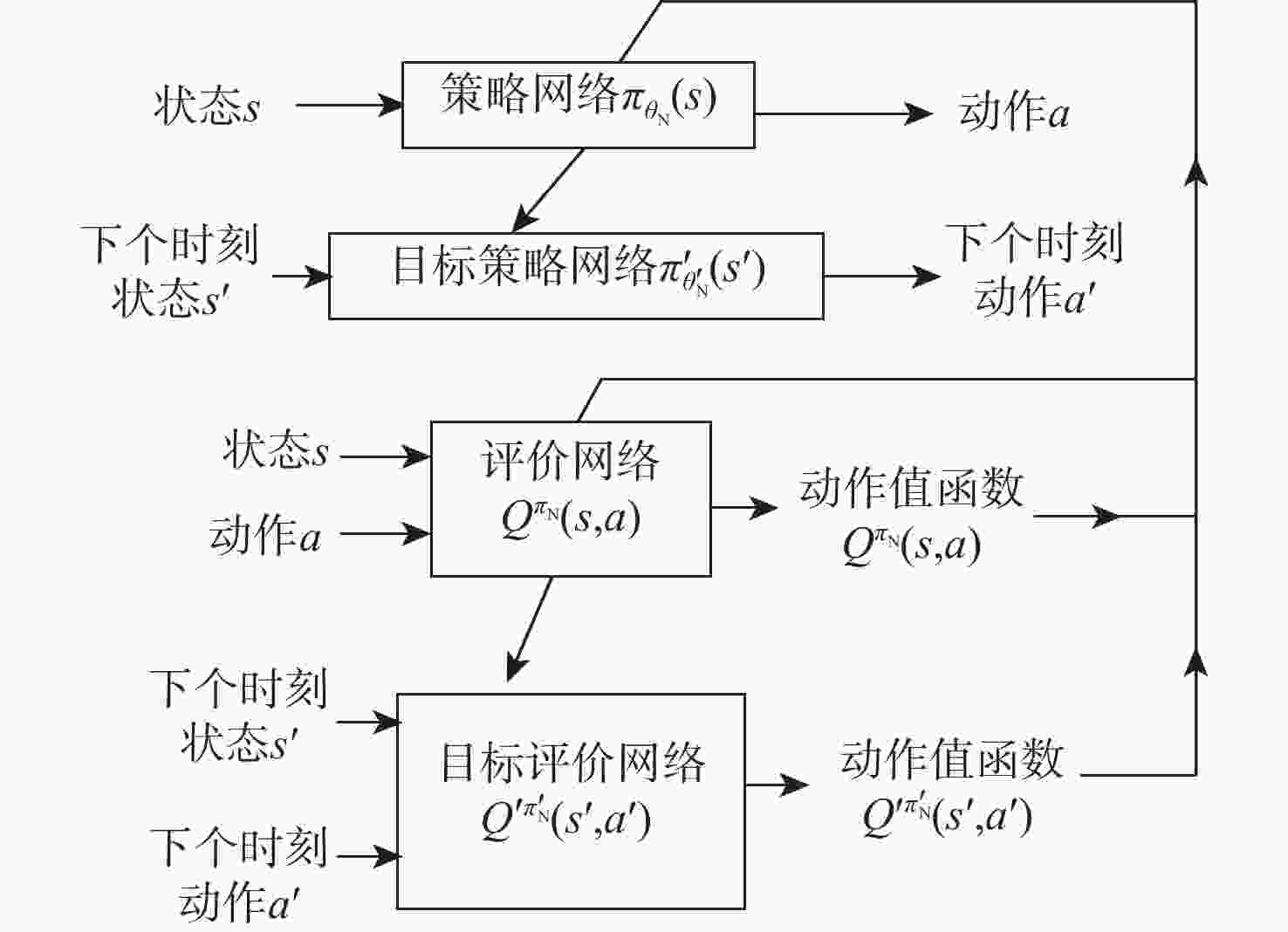
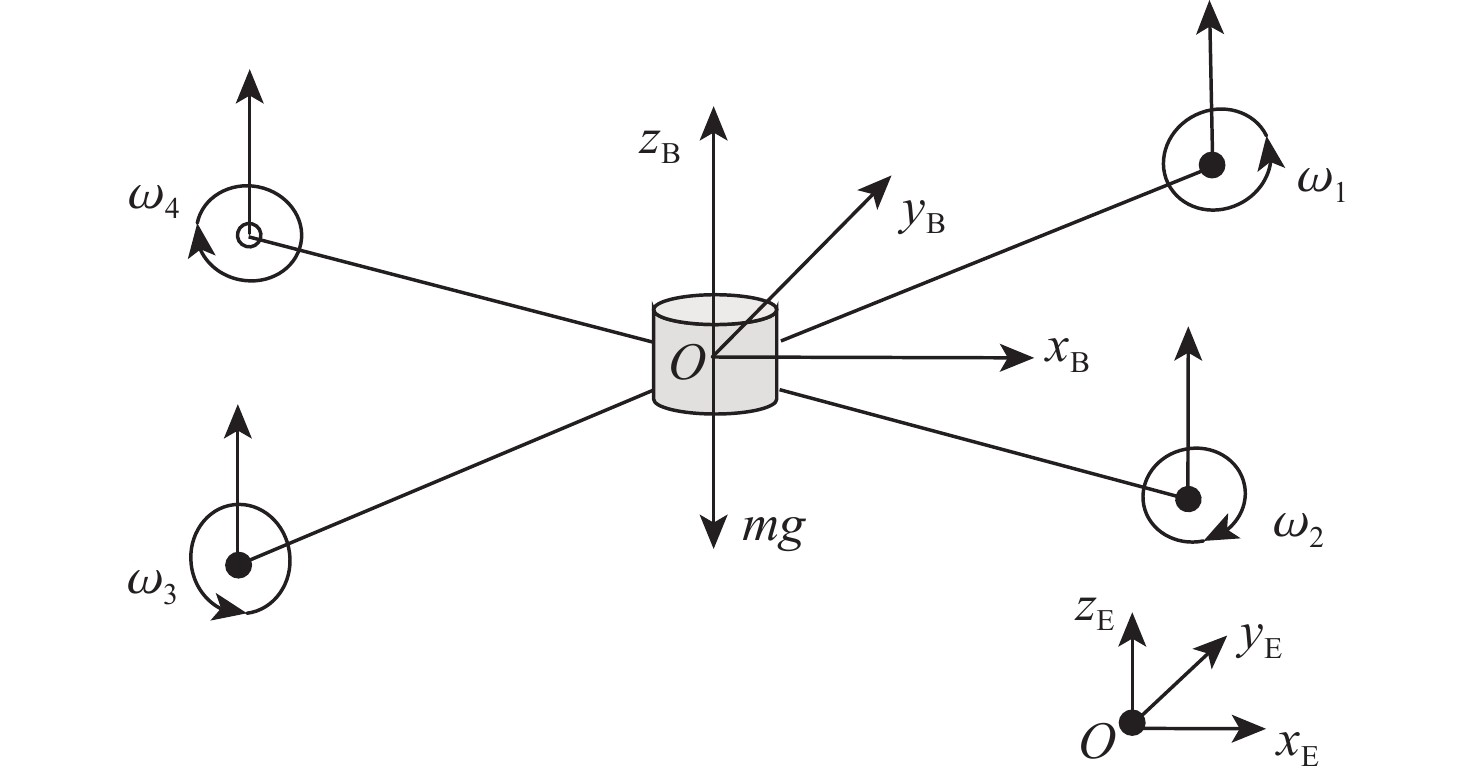
图 1 示教知识辅助的无人机强化学习控制算法结构
Figure 1. Structure of UAV RL control algorithm with demonstrations
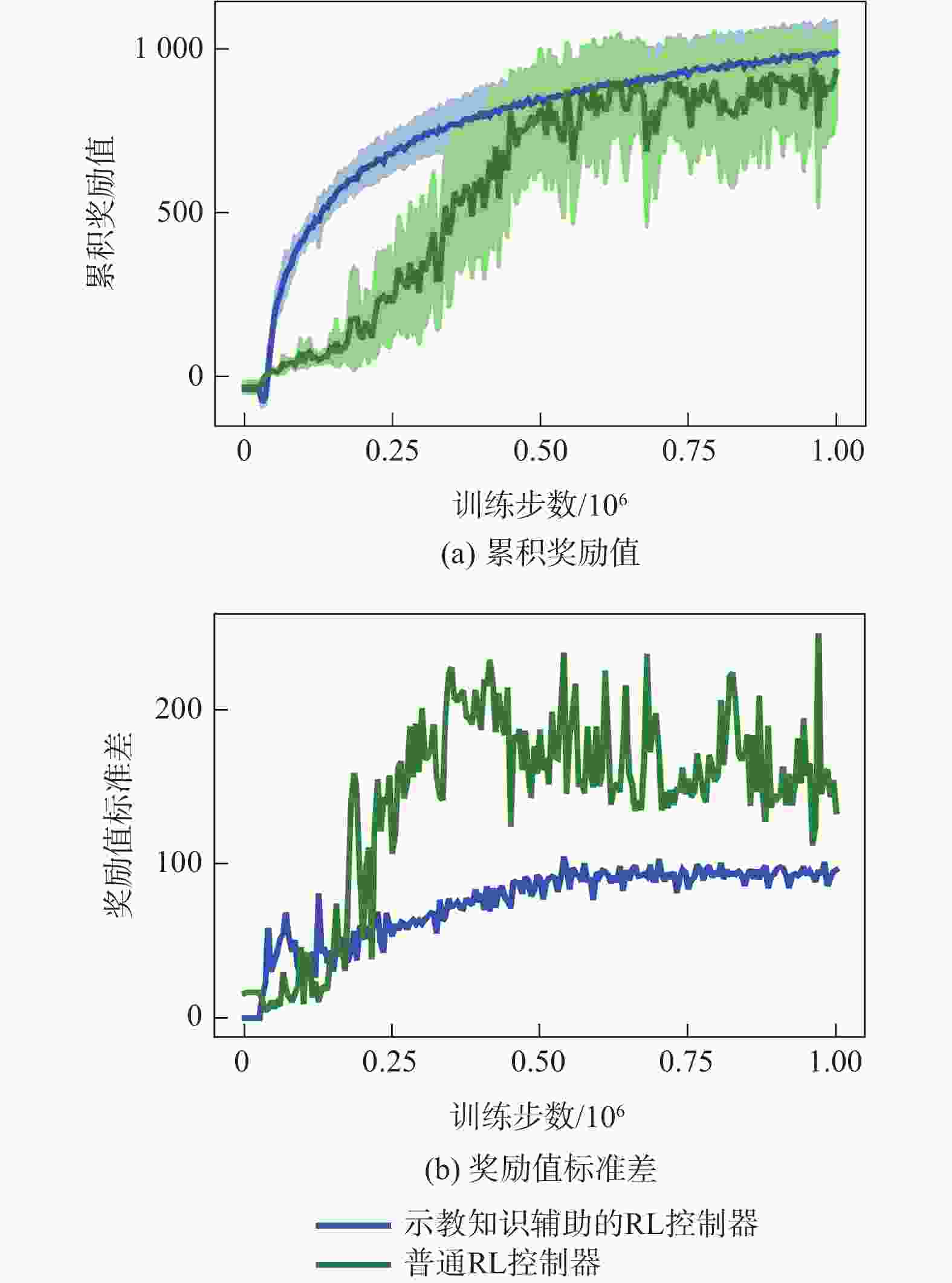
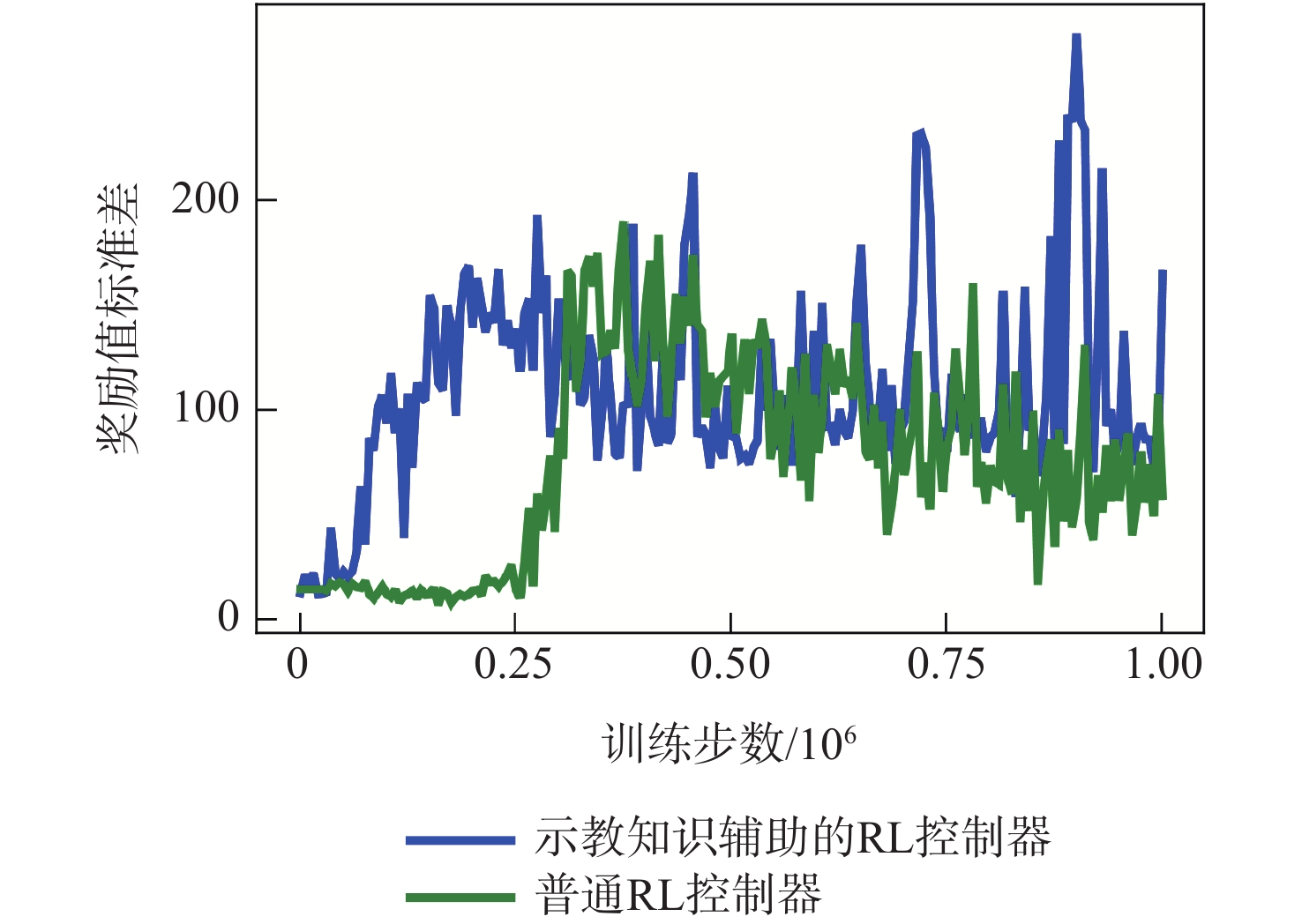
图 3 训练过程中奖励值及其标准差变化
Figure 3. Values and standard deviation of rewards during training
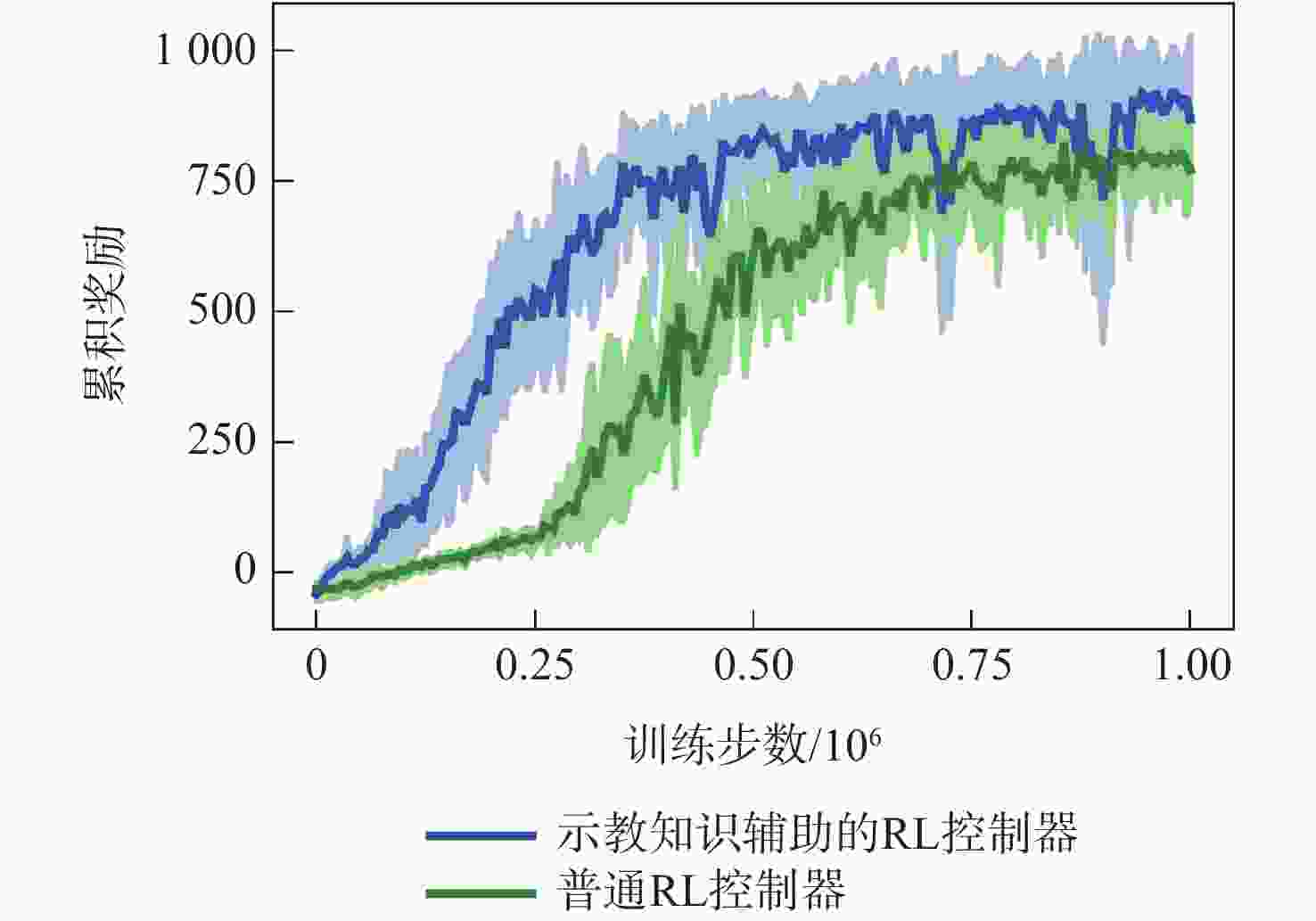
图 7 稀疏奖励下训练过程中累积奖励值的变化
Figure 7. Changes in accumulate rewards during training on thecondition of sparse rewards
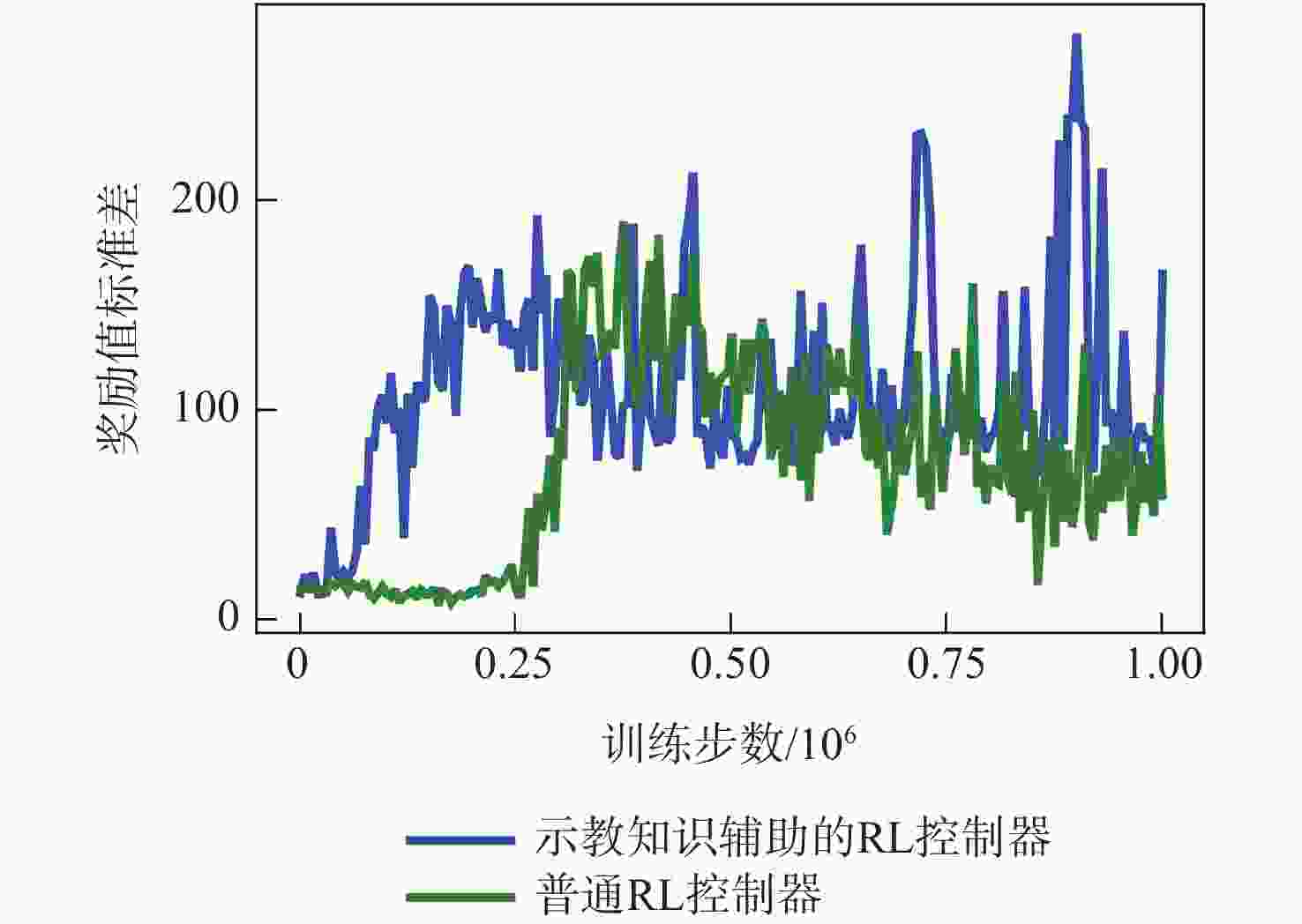
图 8 稀疏奖励下训练过程中奖励值标准差的变化
Figure 8. Sandard deviation of rewards during training on thecondition of sparse rewards
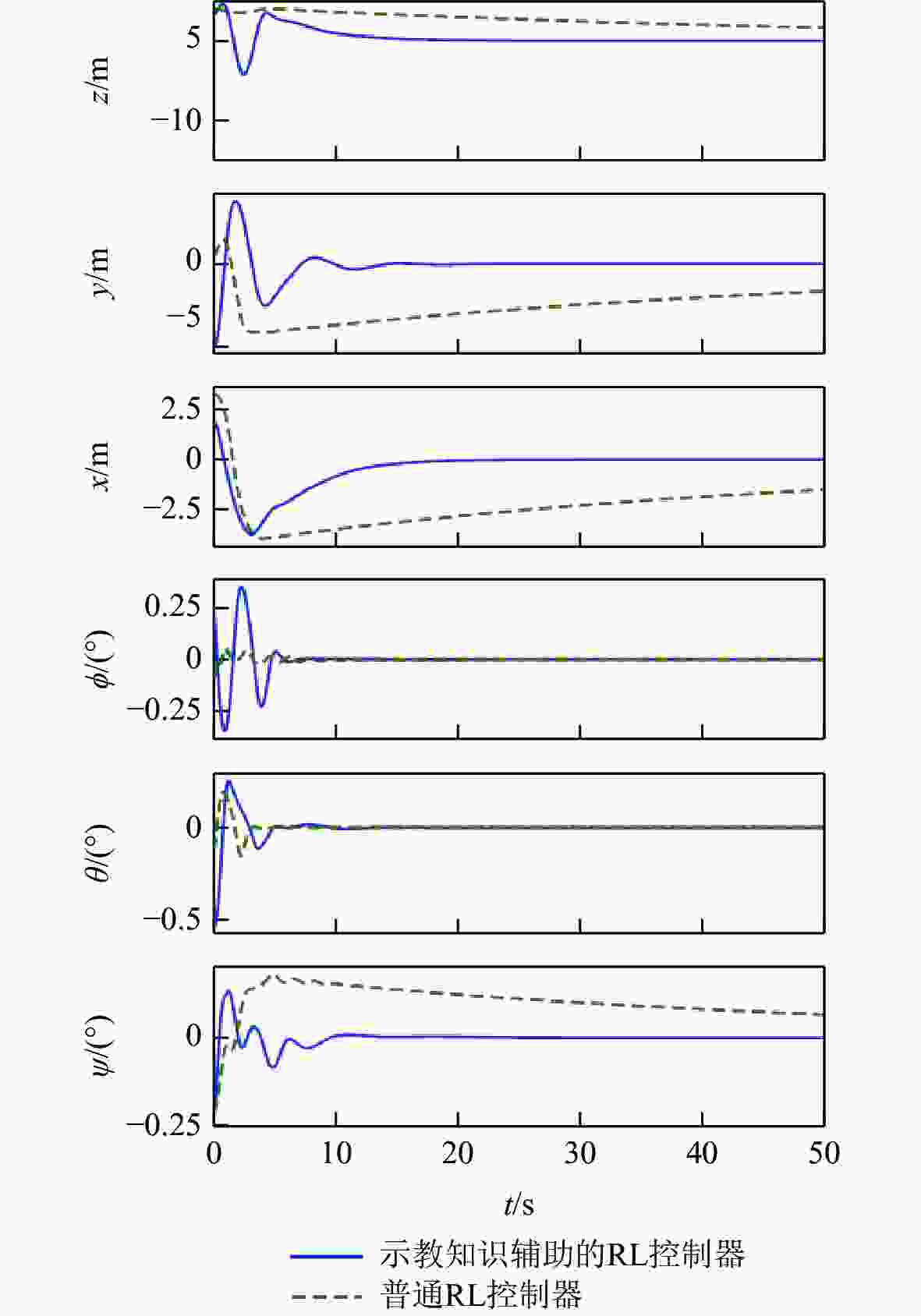
图 9 奖励稀疏情况下RL控制器的控制效果
Figure 9. Control effect of RL controller on the condition of sparse rewards

图 10 奖励稀疏情况下RL控制器的控制信号
Figure 10. Signals of RL controller on condition of sparse rewards
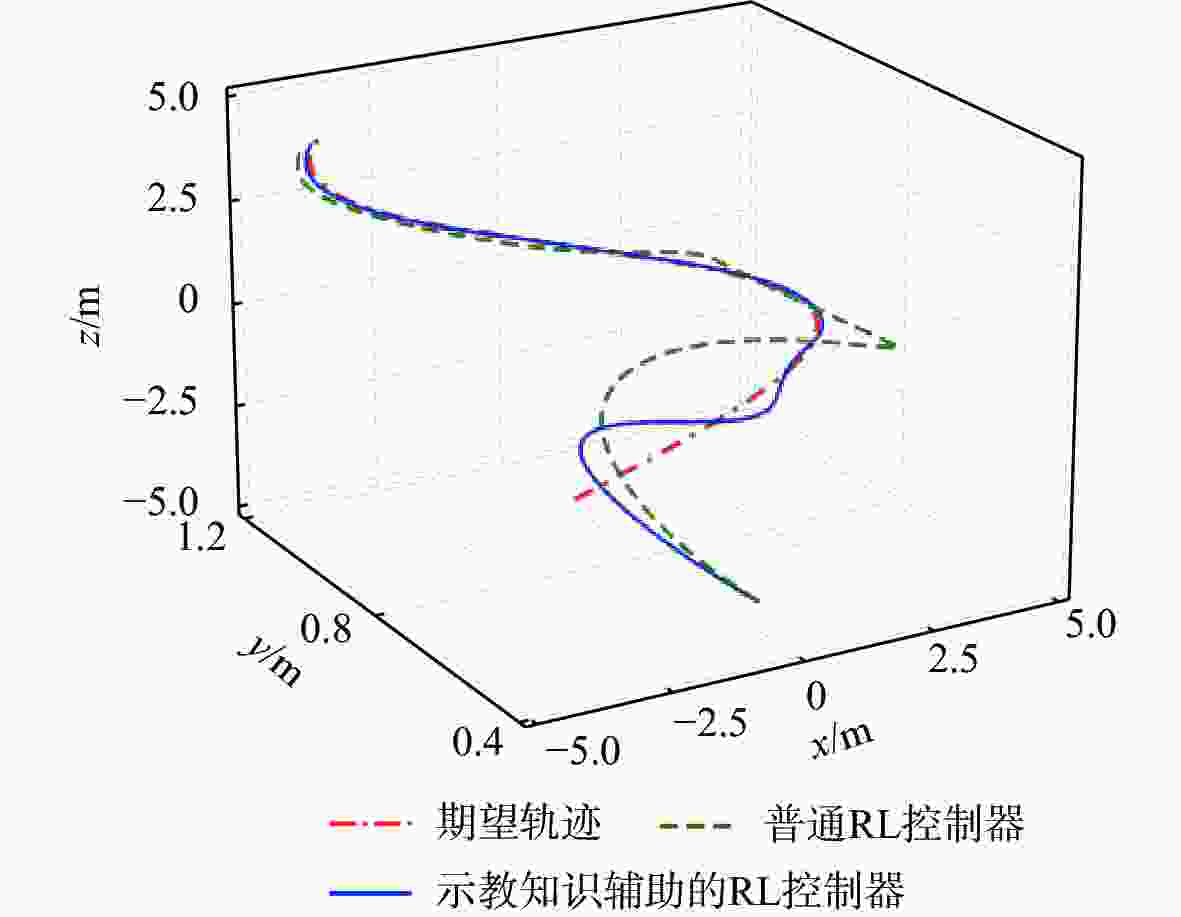
图 11 奖励稀疏情况下无人机轨迹跟踪图
Figure 11. Trajectory tracking map of UAV on the condition of sparse rewards
表 1 四旋翼模拟器模型参数
Table 1. Parameters of quadrotor simulator model
参数 数值 质量 $ m $/kg 1.5 四旋翼半径 $ d $/m 0.225 重力加速度 $ g $/(m·s−2) 9.8 转动惯量 $ {J_x} $/(kg·m2) 0.01745 转动惯量 $ {J_y} $/(kg·m2) 0.01745 转动惯量 $ {J_{\textit{z}}} $/(kg·m2) 0.03175 阻力系数 $ {K_1} $/(Ns·m−1) 0.01 阻力系数 $ {K_2} $/(Ns·m−1) 0.01 阻力系数 $ {K_3} $/(Ns·m−1) 0.01 阻力系数 $ {K_4} $/(Ns·m−1) 0.04 阻力系数 $ {K_5} $/(Ns·m−1) 0.04 阻力系数 $ {K_6} $/(Ns·m−1) 0.04 单桨综合拉力系数 $ {c_{\text{T}}} $/(N·(rad·s)−2) 1.105×10−5 单桨综合力矩系数 $ {c_{\text{M}}} $/(Nm·(rad·s)−2) 1.489×10−7  下载: 导出CSV
下载: 导出CSV
表 2 示教知识辅助的无人机强化学习控制算法训练参数
Table 2. Training parameters of UAV RL control algorithm with demonstrations
参数 数值 交互样本容量 106 专家样本容量 105 单次训练样本数 68 总训练步数 106 每个回合可仿真的步数上限 1 000 动作网络学习速率 0.000 1 价值网络学习速率 0.001 目标网络更新速率 0.001 每步的仿真时间/s 0.1 折扣因子 0.99
下载: 导出CSV
表 3 控制性能指标对比
Table 3. Comparison of control performance indicators
控制器类型 达到控制要
求的比例/%位置稳定调节
时间(均值)/s姿态稳定调节
时间(均值)/s稳定后
波动情况示教知识辅助
的RL控制器95 5 4 无波动 普通RL控制器 91 12 10 无波动
下载: 导出CSV
表 4 奖励稀疏情况下RL控制器控制性能指标对比
Table 4. Comparison of RL controllers control performance indicators on condition of sparse rewards
控制器类型 达到控制要
求的比例/%位置稳定调节
时间(均值)/s姿态稳定调节
时间(均值)/s稳定后
波动情况示教知识辅助
的RL控制器92 15 10 无波动 普通RL控制器 2 40 34 无波动
下载: 导出CSV
-
[1] SANTOSO F, GARRATT M A, ANAVATTI S G. State-of-the-art intelligent flight control systems in unmanned aerial vehicles[J]. IEEE Transactions on Automation Science and Engineering, 2018, 15(2): 613-627. doi: 10.1109/TASE.2017.2651109 [2] FAUST A, PALUNKO I, CRUZ P, et al. Learning swing-free trajectories for UAVs with a suspended load[C]//2013 IEEE International Conference on Robotics and Automation. Piscataway: IEEE Press, 2013: 4902-4909. [3] ZHANG B C, MAO Z L, LIU W Q, et al. Geometric reinforcement learning for path planning of UAVs[J]. Journal of Intelligent & Robotic Systems, 2015, 77(2): 391-409. [4] KOCH W, MANCUSO R, WEST R, et al. Reinforcement learning for UAV attitude control[J]. ACM Transactions on Cyber-Physical Systems, 2019, 3(2): 1-21. [5] HWANGBO J, SA I, SIEGWART R, et al. Control of a quadrotor with reinforcement learning[J]. IEEE Robotics and Automation Letters, 2017, 2(4): 2096-2103. doi: 10.1109/LRA.2017.2720851 [6] PHAM H X, LA H M, FEIL-SEIFER D, et al. Reinforcement learning for autonomous UAV navigation using function approximation[C]//2018 IEEE International Symposium on Safety, Security, and Rescue Robotics. Piscataway: IEEE Press, 2018: 1-6. [7] WANG D W, FAN T X, HAN T, et al. A two-stage reinforcement learning approach for multi-UAV collision avoidance under imperfect sensing[J]. IEEE Robotics and Automation Letters, 2020, 5(2): 3098-3105. doi: 10.1109/LRA.2020.2974648 [8] ZENG Y, XU X L, JIN S, et al. Simultaneous navigation and radio mapping for cellular-connected UAV with deep reinforcement learning[J]. IEEE Transactions on Wireless Communications, 2021, 20(7): 4205-4220. doi: 10.1109/TWC.2021.3056573 [9] EBRAHIMI D, SHARAFEDDINE S, HO P H, et al. Autonomous UAV trajectory for localizing ground objects: A reinforcement learning approach[J]. IEEE Transactions on Mobile Computing, 2021, 20(4): 1312-1324. doi: 10.1109/TMC.2020.2966989 [10] ESCANDELL-MONTERO P, LORENTE D, MARTÍNEZ-MARTÍNEZ J M, et al. Online fitted policy iteration based on extreme learning machines[J]. Knowledge-Based Systems, 2016, 100: 200-211. doi: 10.1016/j.knosys.2016.03.007 [11] SAUNDERS W, SASTRY G, STUHLMÜLLER A, et al. Trial without error: Towards safe reinforcement learning via human intervention[C]//Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems. New York: ACM, 2018: 2067–2069. [12] ABEL D, SALVATIER J, STUHLMÜLLER A, et al. Agent-agnostic human-in-the-loop reinforcement learning[C]//Proceeding of Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2017: 1-13. [13] NACHUM O, GU S, LEE H, et al. Data-efficient hierarchical reinforcement learning[C]//Proceeding of Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2018: 1-17. [14] HORGAN D, QUAN J, BUDDEN D, et al. Distributed prioritized experience replay[C]//Proceeding of International Conference on Learning Representations, 2018: 1-19. [15] BOBTSOV A, GUIRIK A, BUDKO M, et al. Hybrid parallel neuro-controller for multirotor unmanned aerial vehicle[C]//2016 8th International Congress on Ultra Modern Telecommunications and Control Systems and Workshops. Piscataway: IEEE Press, 2016: 1-4. [16] SUTTON R S, BARTO A G. Reinforcement learning: An introduction[M]. Cambridge: MIT press, 2018: 50-55. [17] HOU Y N, LIU L F, WEI Q, et al. A novel DDPG method with prioritized experience replay[C]//2017 IEEE International Conference on Systems, Man, and Cybernetics. Piscataway: IEEE Press, 2017: 316-321. [18] SCHAUL T, QUAN J, ANTONOGLOU I, et al. Prioritized experience replay[C]//Proceeding of International Conference on Learning Representations, 2016: 1-21. [19] LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[C]//Proceeding of International Conference on Learning Representations, 2016: 1-14. [20] PLAPPERT M, HOUTHOOFT R, DHARIWAL P, et al. Parameter space noise for exploration[C]//Proceeding of International Conference on Learning Representations, 2018: 1-18. [21] FERNANDO H C T E, DE SILVA A T A, DE ZOYSA M D C, et al. Modelling, simulation and implementation of a quadrotor UAV[C]//2013 IEEE 8th International Conference on Industrial and Information Systems. Piscataway: IEEE Press, 2014: 207-212. -

 下载:
下载:









 点击查看大图
点击查看大图

计量
- 文章访问数: 286
- HTML全文浏览量: 70
- PDF下载量: 37
- 被引次数: 0
