



-
摘要:
非重叠视域摄像机网络行人目标跨视域跟踪是智能视觉监控的基本问题之一。针对基于外观一致性假设的行人跨视域跟踪方法对光照或衣着变化敏感的问题,提出一种融合基于2D骨架图的步态特征与时空约束的跨视域行人跟踪方法。从单视域局部轨迹提取骨架集合计算步态特征,建立跨视域目标跟踪问题的整数线性规划模型,模型参数由步态特征相似度和时空约束定义,利用对偶分解算法实现问题的分布式求解。通过步态特征与更加精细化的时空约束融合,显著提升了仅基于步态特征的跨视域跟踪算法对于光照和衣着变化的鲁棒性,克服了单独使用步态或时空特征时判别力较弱的问题。在公开数据集上的测试结果表明,所提方法跟踪准确,且对光照和衣着变化具有鲁棒性。
Abstract:Pedestrian tracking across non-overlapping camera views is one of the basic problems of intelligent visual surveillance. A cross-view pedestrian target tracking method based on the gait features of a 2D skeleton diagram and space-time constraints is proposed in order to address the issue that the pedestrian cross-view tracking method based on the assumption of appearance consistency is sensitive to lighting or clothing changes. The skeleton set is extracted from the local trajectory of the single view to calculate the gait features, and the integer programming model of the cross-view target tracking problem is established. The model parameters are defined by the similarity of the gait features and the space-time constraints. The dual decomposition algorithm is used to realize the distributed solution to the above problems. The algorithm’s robustness to changes in lighting and clothing is greatly increased through the combination of gait features and more precise space-time restrictions, and it also solves the issue of weak discriminating when gait or space-time features are employed alone. The test results on the public data sets show that the proposed method is accurate in tracking and robust to lighting and clothing changes.
-
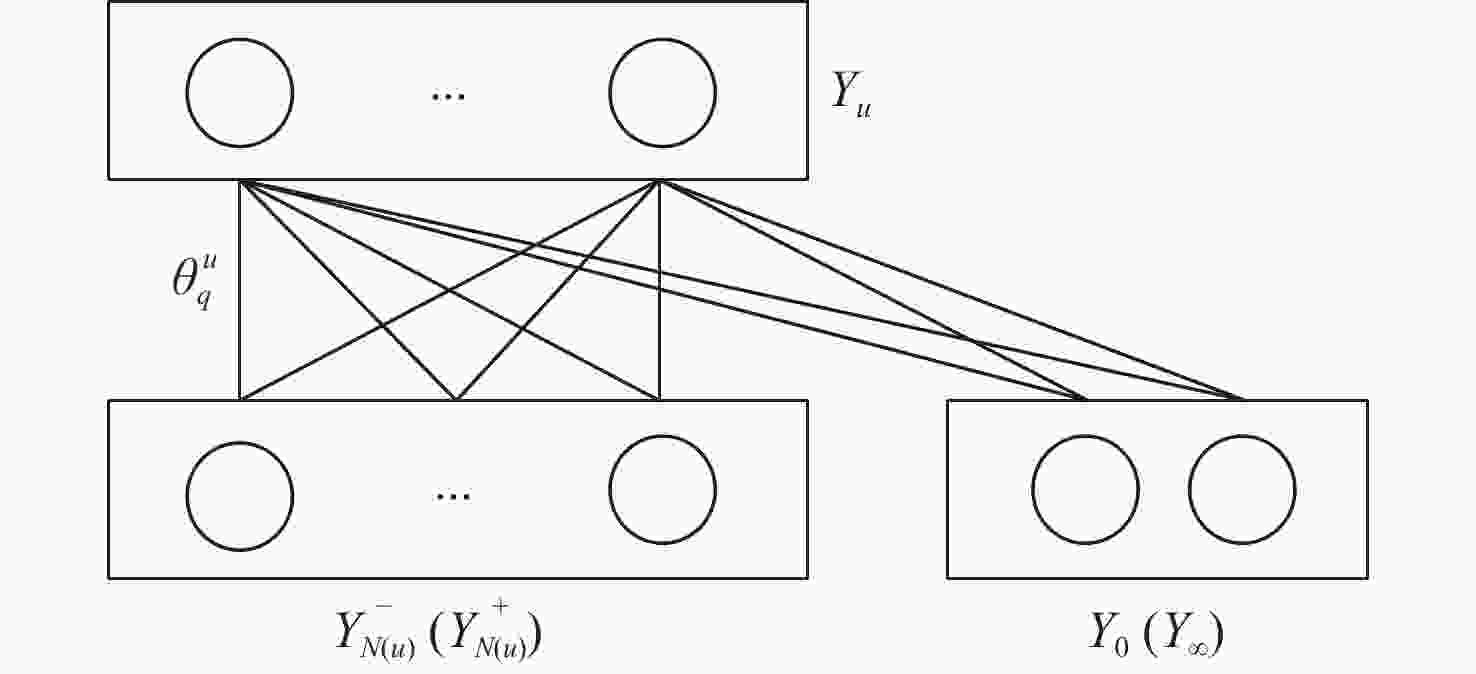
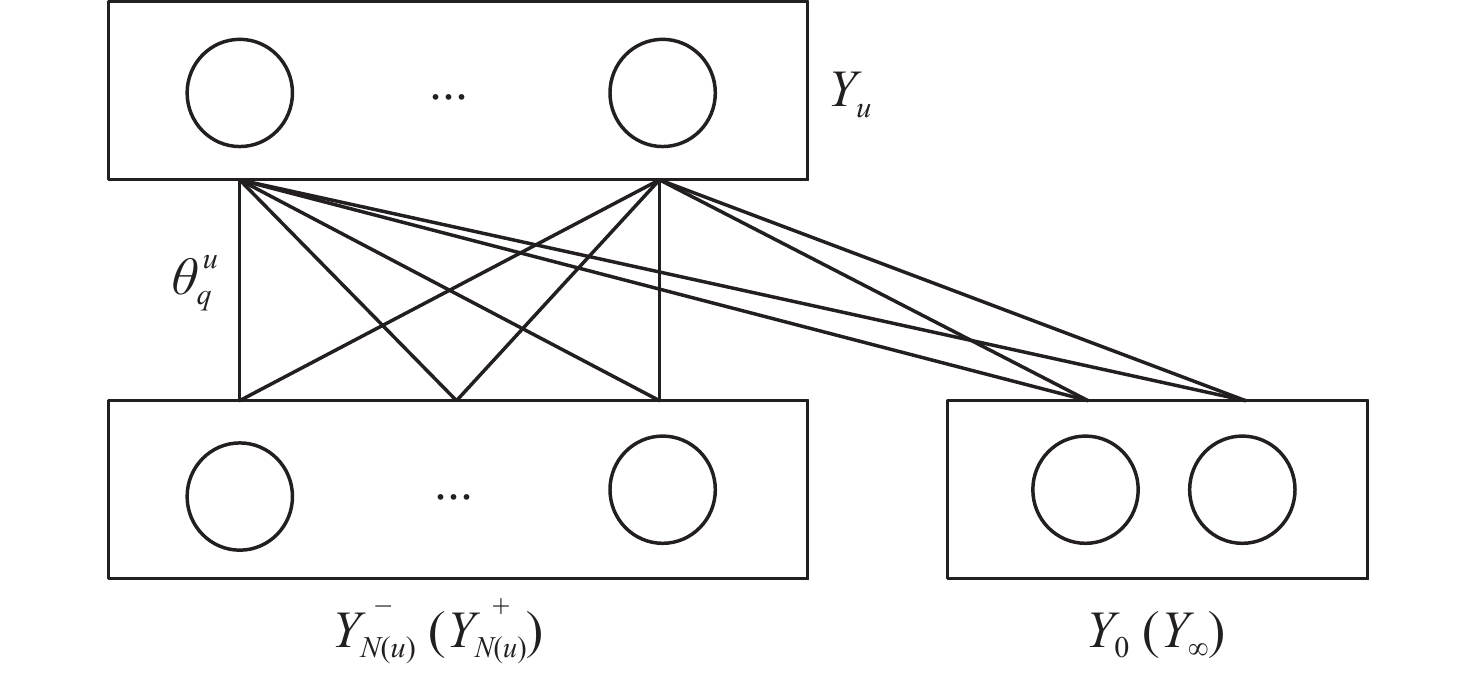
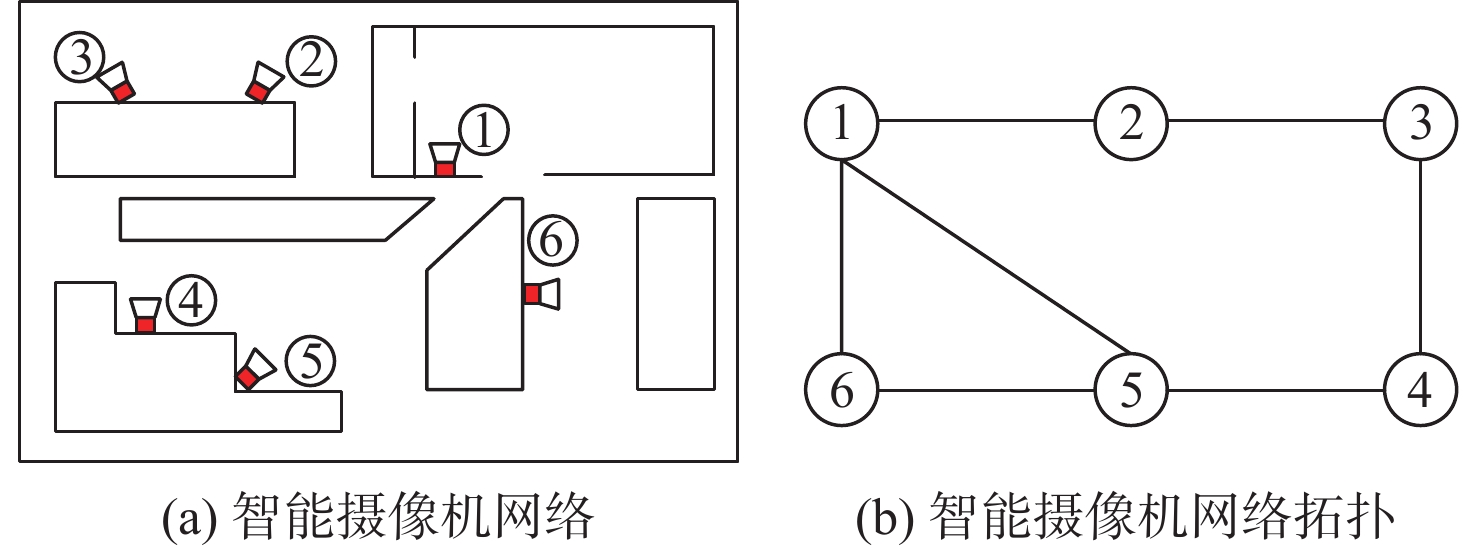
图 7 对偶分解算法中的二分图子问题
Figure 7. Bipartite graph subproblem in dual decomposition algorithm

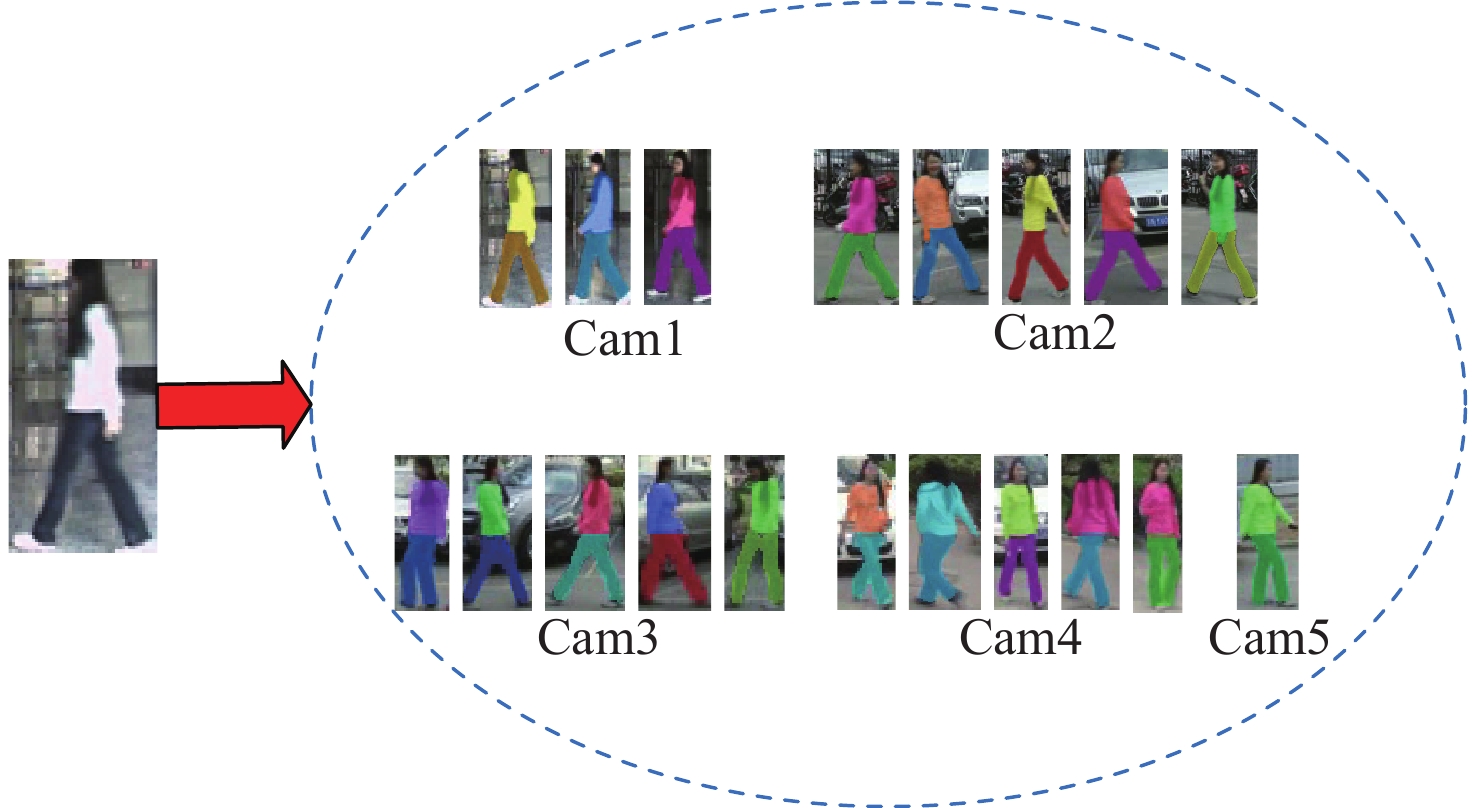
图 13 9个演员Rank-1~Rank-10查询结果的对应观测
Figure 13. Corresponding observations of 9 actors from Rank-1 to Rank-10

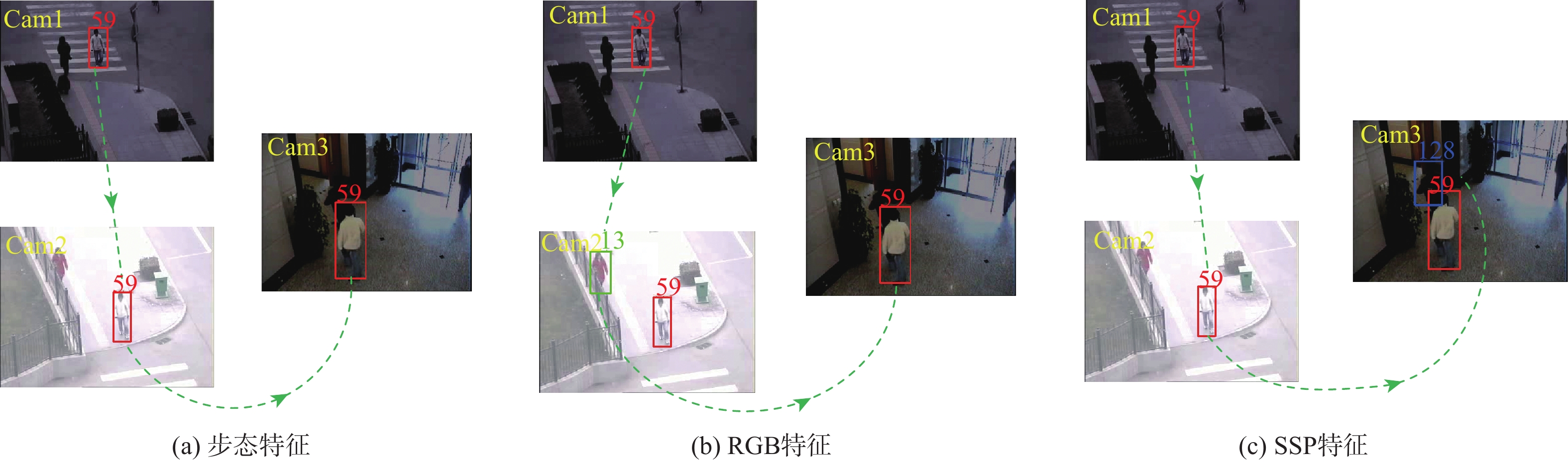
图 14 光照改变下跨视域跟踪示例
Figure 14. Examples of cross-view tracking under lighting variations
表 1 时空观测
Table 1. Space-time observation
时空属性 状态 位置 CamE 进入的时间 09:10:21 a.m. 离开的时间 09:10:27 a.m. 进入的方向 左边界 离开的方向 右边界  下载: 导出CSV
下载: 导出CSV
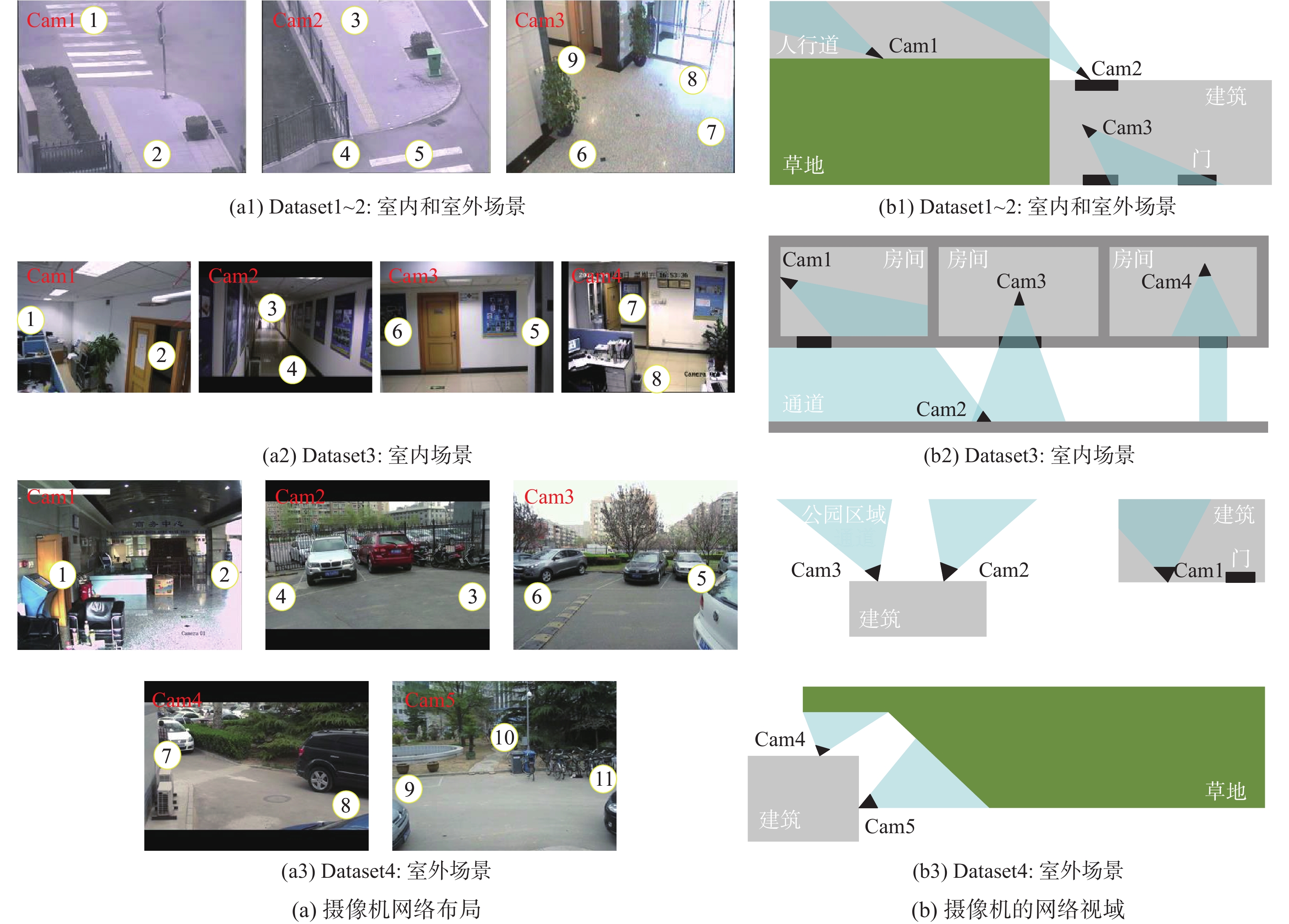
表 2 NLPR_MCT数据集的细节
Table 2. Details of NLPR_MCT dataset
子数据集 相机数 持续时间/min 帧率/(帧·s−1) 目标数 $T{P_s}$ $ T{P_c} $ Dataset1 3 20 20 235 71853 334 Dataset2 3 20 20 255 88419 408 Dataset3 4 3.5 25 14 18187 152 Dataset4 4 24 25 49 42615 256 注:TPs为数据集提供的单视域的轨迹数,TPc为数据集提供的跨视域的轨迹数。
下载: 导出CSV
表 3 MCT及模拟数据集上Rank-n准确度比较
Table 3. Comparison of Rank-n accuracy on MCT and simulated datasets
% 子数据集 Rank-1 Rank-5 原始 光照 换装 原始 光照 换装 RGB SSP 步态 RGB SSP 步态 RGB SSP 步态 RGB SSP 步态 RGB SSP 步态 RGB SSP 步态 Dataset1 6.35 45.5 17.86 2.59 2.6 26.42 0.53 3.2 17.53 15.34 54.5 40.82 4.15 4.2 41.97 7.41 7.9 38.14 Dataset2 8.89 50.4 11.96 0.73 1.1 8.99 0.37 1.1 11.15 16.67 64.1 26.45 2.19 3.0 17.27 2.96 5.2 23.38 Dataset3 19.08 69.1 35.1 16.11 60.5 35.1 9.21 13.8 29.8 53.29 85.5 65.56 47.65 78.3 62.25 35.53 55.3 65.56 Dataset4 21.14 85.5 40.73 14.11 55.0 36.95 5.62 8.4 36.95 41.87 95.6 66.53 37.9 74.3 64.66 24.1 34.9 61.04
下载: 导出CSV
表 4 VBOLO数据集上步态特征Rank-n准确度比较
Table 4. Comparison of Rank-n accuracyof gait feature on VBOLO dataset
% Rank-1 Rank-5 Rank-10 Rank-15 Rank-20 56.57 91.92 97.98 98.99 100
下载: 导出CSV
表 5 跨视域跟踪方法的性能比较
Table 5. Performance comparison of cross-view tracking methods
方法 ${ {{e} } }^{ {\rm{c} } }$ W Dataset1 Dataset2 Dataset3 Dataset4 Dataset1 Dataset2 Dataset3 Dataset4 ICLM[37] 13 30 32 62 0.961 0.927 0.790 0.758 CRF[37] 54 81 51 70 0.838 0.801 0.665 0.727 EGM[29] 55 121 39 157 0.8353 0.7034 0.7417 0.3845 PMCSHR[38] 112 167 44 110 0.662 0.591 0.711 0.633 Hfutdspmct[30] 86 141 40 155 0.7425 0.6544 0.7368 0.3945 AdbTeam[30] 227 267 131 216 0.3204 0.3456 0.1382 0.1563 TRACTA[39] 121 176 126 181 0.6327 0.5448 0.1398 0.2870 本文 24 81 85 95 0.9279 0.8014 0.4370 0.6286
下载: 导出CSV
表 6 光照改变和换装情况下基于步态、RGB和SSP特征的跨视域跟踪方法结果对比
Table 6. Comparison of results of cross-view tracking methods based on gait, RGB and SSP feature under lighting variations and clothes changing
子数据集 $e^{ {\rm{c} } }$ W 原始 光照改变 换装 原始 光照改变 换装 RGB SSP 步态 RGB SSP 步态 RGB SSP 步态 RGB SSP 步态 RGB SSP 步态 RGB SSP 步态 Dataset1 75 18 30 83 43 26 54 59 30 0.775 4 0.945 8 0.908 9 0.751 4 0.870 8 0.921 8 0.838 2 0.823 3 0.909 5 Dataset2 140 39 56 132 0.904 4 57 114 73 62 0.656 8 114 0.860 9 0.674 0 0.818 8 0.859 5 0.720 5 0.719 9 0.847 2 Dataset3 120 36 55 86 65 55 94 95 60 0.210 5 0.699 9 0.517 5 0.358 2 0.488 2 0.533 9 0.381 5 0.374 9 0.508 2 Dataset4 164 36 78 151 81 100 115 114 82 0.359 2 0.859 0 0.695 0 0.403 0 0.678 3 0.601 4 0.550 6 0.554 5 0.675 6
下载: 导出CSV
表 7 有无时空约束的结果比较
Table 7. Comparison of results with and without space-time constraints
有/无时控约束 $e^{ {\rm{c} } }$ W Dataset1 Dataset2 Dataset3 Dataset4 Dataset1 Dataset2 Dataset3 Dataset4 无时空约束 276 342 120 203 0.159 9 0.148 2 0.195 7 0.200 7 有时空约束 30 56 55 78 0.908 9 0.860 9 0.517 5 0.695 0
下载: 导出CSV
表 8 基于剪影和基于骨架的步态特征对比
Table 8. Silhouette vs skeleton based gait feature
输入 $e^{ {\rm{c} } }$ W Dataset1 Dataset2 Dataset3 Dataset4 Dataset1 Dataset2 Dataset3 Dataset4 剪影 37 88 93 110 0.891 5 0.782 4 0.365 7 0.551 2 骨架 30 56 55 78 0.908 9 0.860 9 0.517 5 0.695 0
下载: 导出CSV
-
[1] GRAY D, TAO H. Viewpoint invariant pedestrian recognition with an ensemble of localized features[C]//European Conference on Computer Vision. Berlin: Springer, 2008: 262-275. [2] VARMA M, ZISSERMAN A. A statistical approach to texture classification from single images[J]. International Journal of Computer Vision, 2005, 62(1-2): 61-81. doi: 10.1007/s11263-005-4635-4 [3] AHONEN T, HADID A, PIETIKÄINEN M. Face description with local binary patterns: Application to face recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2006, 28(12): 2037-2041. doi: 10.1109/TPAMI.2006.244 [4] LOWE D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91-110. doi: 10.1023/B:VISI.0000029664.99615.94 [5] BAY H, TUYTELAARS T, VAN GOOL L. SURF: Speeded up robust features[C]//European Conference on Computer Vision. Berlin: Springer, 2006: 404-417. [6] CALONDER M, LEPETIT V, STRECHA C, et al. BRIEF: Binary robust independent elementary features[C]//European Conference on Computer Vision. Berlin: Springer, 2010: 778-792. [7] ABDEL-HAKIM A E, FARAG A A. CSIFT: A SIFT descriptor with color invariant characteristics[C]//2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2006: 1978-1983. [8] BAK S, BRÉMOND F. Re-identification by covariance descriptors[M]. Berlin: Springer, 2014: 71-91. [9] WAN F B, WU Y, QIAN X L, et al. When person re-identification meets changing clothes[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE Press, 2020: 3620-3628. [10] 王科俊, 丁欣楠, 邢向磊, 等. 多视角步态识别综述[J]. 自动化学报, 2019, 45(5): 841-852. doi: 10.16383/j.aas.2018.c170559WANG K J, DING X N, XING X L, et al. A survey of multi-view gait recognition[J]. Acta Automatica Sinica, 2019, 45(5): 841-852(in Chinese). doi: 10.16383/j.aas.2018.c170559 [11] HAN J, BHANU B. Individual recognition using gait energy image[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2006, 28(2): 316-322. doi: 10.1109/TPAMI.2006.38 [12] GIANARIA E, BALOSSINO N, GRANGETTO M, et al. Gait characterization using dynamic skeleton acquisition[C]//2013 IEEE 15th International Workshop on Multimedia Signal Processing. Piscataway: IEEE Press, 2013: 440-445. [13] GÜLER R A, NEVEROVA N, KOKKINOS I. DensePose: Dense human pose estimation in the wild[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 7297-7306. [14] VERLEKAR T. Gait analysis in unconstrained environments[D]. Lisbon: University of Lisbon, 2019. [15] JAN NORDIN M D, SAADOON A. A survey of gait recognition based on skeleton model for human identification[J]. Research Journal of Applied Sciences, Engineering and Technology, 2016, 12(7): 756-763. doi: 10.19026/rjaset.12.2751 [16] ZHANG D, SHAH M. Human pose estimation in videos[C]//2015 IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2016: 2012-2020. [17] LIN B, ZHANG S, BAO F. Gait recognition with multiple-temporal-scale 3D convolutional neural network[C]//Proceedings of the 28th ACM International Conference on Multimedia. New York: ACM, 2020: 3054-3062. [18] LI N, ZHAO X, MA C. JointsGait: A model-based gait recognition method based on gait graph convolutional networks and joints relationship pyramid mapping[EB/L]. (2020-12-09) [2021-10-01]. https://arxiv.org/abs/2005.08625v1. [19] CHAO H B, HE Y W, ZHANG J P, et al. GaitSet: Regarding gait as a set for cross-view gait recognition[J]. Proceedings of the Conference on Artificial Intelligence, 2019, 33(1): 8126-8133. doi: 10.1609/aaai.v33i01.33018126 [20] CHEN W H, CAO L J, CHEN X T, et al. An equalized global graph model-based approach for multicamera object tracking[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2017, 27(11): 2367-2381. doi: 10.1109/TCSVT.2016.2589619 [21] CHEN X J, BHANU B. Integrating social grouping for multitarget tracking across cameras in a CRF model[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2017, 27(11): 2382-2394. doi: 10.1109/TCSVT.2016.2565978 [22] YU S Q, TAN D L, TAN T N. A framework for evaluating the effect of view angle, clothing and carrying condition on gait recognition[C]//18th International Conference on Pattern Recognition. Piscataway: IEEE Press, 2006: 441-444. [23] WANG L, TAN T N, NING H Z, et al. Silhouette analysis-based gait recognition for human identification[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003, 25(12): 1505-1518. doi: 10.1109/TPAMI.2003.1251144 [24] CAO Z, HIDALGO G, SIMON T, et al. OpenPose: Realtime multi-person 2D pose estimation using part affinity fields[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021, 43(1): 172-186. doi: 10.1109/TPAMI.2019.2929257 [25] ZAHEER M, KOTTUR S, RAVANBAKHSH S, et al. Deep sets[EB/OL]. (2018-04-14) [2021-10-01].https://arxiv.org/abs/1703.06114v1, [26] FU Y, WEI Y C, ZHOU Y Q, et al. Horizontal pyramid matching for person re-identification[C]//Proceedings of the AAAI Conference on Artificial Intelligence. Washington, D. C.:AAAI Press, 2019: 8295-8302. [27] GOLDBERG A V. An efficient implementation of a scaling minimum-cost flow algorithm[J]. Journal of Algorithms, 1997, 22(1): 1-29. doi: 10.1006/jagm.1995.0805 [28] KOMODAKIS N, PARAGIOS N. Beyond pairwise energies: Efficient optimization for higher-order MRFs[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2009: 2985-2992. [29] WAN J Q, CHEN X, BU S C, et al. Distributed data association in smart camera network via dual decomposition[J]. Information Fusion, 2018, 39: 120-138. doi: 10.1016/j.inffus.2017.04.007 [30] Multi-camera object tracking (MCT) challenge[DB/OL]. (2017)[2017-10-18]. http://www.mct2014.com. [31] LIANG X D, GONG K, SHEN X H, et al. Look into person: Joint body parsing & pose estimation network and a new benchmark[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(4): 871-885. [32] LI P, BROGAN J, FLYNN P J. Toward facial re-identification: Experiments with data from an operational surveillance camera plant[C]//2016 IEEE 8th International Conference on Biometrics Theory, Applications and Systems. Piscataway: IEEE Press, 2016: 1-8. [33] LI P, PRIETO M L, FLYNN P J, et al. Learning face similarity for re-identification from real surveillance video: A deep metric solution[C]//2017 IEEE International Joint Conference on Biometrics. Piscataway: IEEE Press, 2018: 243-252. [34] ZHENG J K, LIU X C, YAN C G, et al. TraND: Transferable neighborhood discovery for unsupervised cross-domain gait recognition[C]//2021 IEEE International Symposium on Circuits and Systems. Piscataway: IEEE Press, 2021: 1-5. [35] QUISPE R, PEDRINI H. Improved person re-identification based on saliency and semantic parsing with deep neural network models[J]. Image and Vision Computing, 2019, 92: 103809. doi: 10.1016/j.imavis.2019.07.009 [36] LI X, ZHAO L M, WEI L N, et al. DeepSaliency: Multi-task deep neural network model for salient object detection[J]. IEEE Transactions on Image Processing, 2016, 25(8): 3919-3930. doi: 10.1109/TIP.2016.2579306 [37] LEE Y G, TANG Z, HWANG J N. Online-learning-based human tracking across non-overlapping cameras[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2018, 28(10): 2870-2883. doi: 10.1109/TCSVT.2017.2707399 [38] CHEN W H, CAO L J, CHEN X T, et al. A novel solution for multi-camera object tracking[C]//2014 IEEE International Conference on Image Processing. Piscataway: IEEE Press, 2015: 2329-2333. [39] HE Y H, WEI X, HONG X P, et al. Multi-target multi-camera tracking by tracklet-to-target assignment[J]. IEEE Transactions on Image Processing, 2020, 29: 5191-5205. doi: 10.1109/TIP.2020.2980070 [40] TEEPE T, KHAN A, GILG J, et al. GaitGraph: Graph convolutional network for skeleton-based gait recognition[EB/OL]. (2021-06-09) [2021-10-01].https://arxiv.org/abs/2101.11228. [41] BARNICH O, VAN DROOGENBROECK M. ViBe: A universal background subtraction algorithm for video sequences[J]. IEEE Transactions on Image Processing, 2011, 20(6): 1709-1724. doi: 10.1109/TIP.2010.2101613 -

 下载:
下载:









 点击查看大图
点击查看大图
计量
- 文章访问数: 202
- HTML全文浏览量: 58
- PDF下载量: 13
- 被引次数: 0
