



An iterative pedestrian detection method sensitive to historical information features
-
摘要:
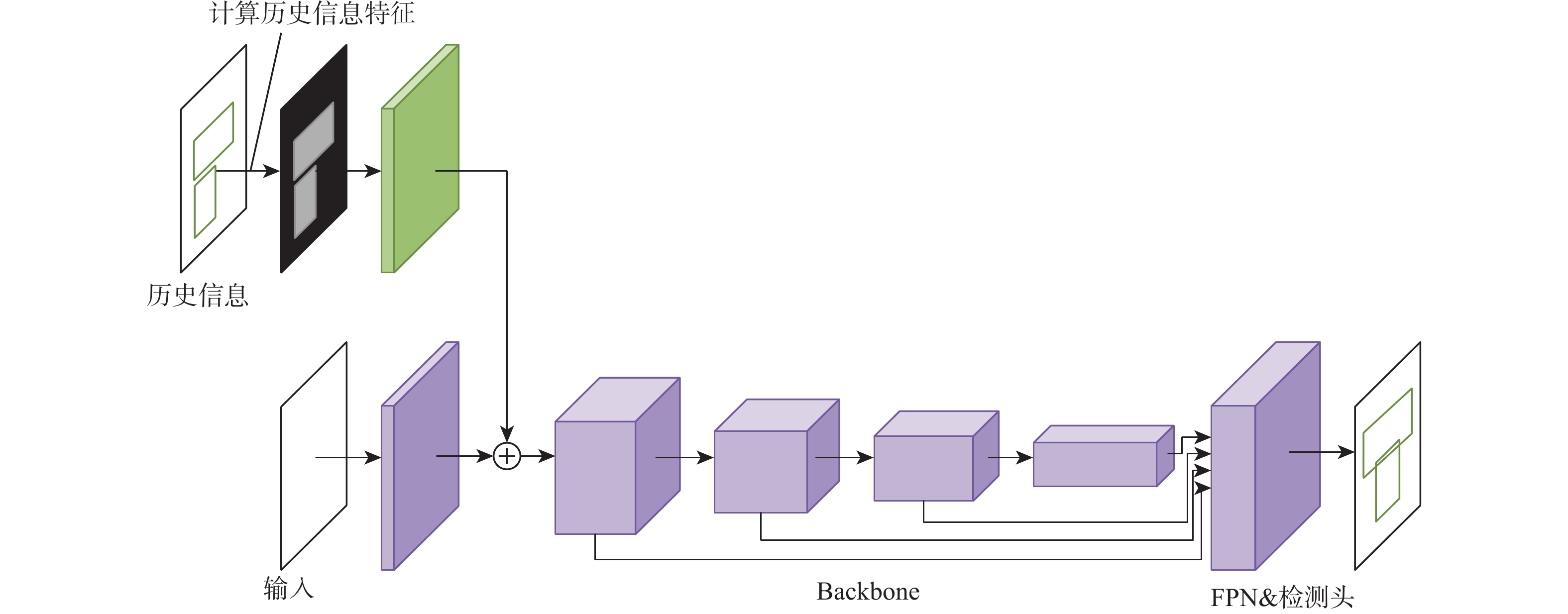
基于深度学习的目标检测算法通常需要使用非极大值抑制等后处理方法对预测框进行筛选,无法在行人拥挤的场景下平衡模型的检测精度和召回率。虽然迭代检测的方法可以解决非极大值抑制等方法带来的问题,但是重复检测同样会限制模型的性能。提出了一种历史信息特征敏感的行人迭代检测方法。引入带权重的历史信息特征(WHIC),提高特征的区分度;利用历史信息特征提取模块(HIFEM)得到不同尺度的历史信息特征,并融合进主网络中进行多尺度检测,增强了模型对历史信息特征的敏感度,有效抑制重复检测框的产生。实验结果表明:所提方法在拥挤场景的行人检测数据集CrowdHuman和WiderPerson上取得了最优的检测精度和召回率。
Abstract:Object detection algorithms based on deep learning usually need to use post-processing methods such as non-maximum suppression to filter the prediction box, and can not balance the detection accuracy and recall rate of the model in the crowded pedestrian scene. Although the iterative detection method can solve the problems caused by non-maximum suppression methods, repeated detection will also limit the performance of the model. In this paper, a pedestrian iterative detection method sensitive to historical information features is proposed. Firstly, the weighted historical information characteristics (WHIC) is introduced to improve the feature discrimination. Second, the historical information feature extraction module (HIFEM) suggested in this paper is utilized to obtain and fuse historical information features of various scales into the main network for multi-scale detection, increasing the sensitivity of the model to the historical information features. This method can effectively suppress the generation of repeated detection frames. Experimental results show that the proposed method achieves the best detection accuracy and recall on CrowdHuman and WiderPerson.
-
Key words:
- machine vision /
- object detection /
- feature fusion /
- convolution neural network /
- deep learning
-
表 1 HIFEM网络参数
Table 1. Parameters of HIFEM
层名称 输出尺寸 层参数 conv1 112×112 7×7, 64, stride 2 conv2_x 56×56 3×3 max pool, stride 2 (3×3,2563×3,256)×2 conv3_x 28×28 (3×3,5123×3,512)×2 conv4_x 14×14 (3×3,10243×3,1024)×2  下载: 导出CSV
下载: 导出CSV
表 2 CrowdHuman数据集上基于RetinaNet+IterDet的权重系数实验结果
Table 2. Experimental results of weight coefficient based on RetinaNet+IterDet on CrowdHuman dataset
轻度遮挡
权重系数中度遮挡
权重系数重度遮挡
权重系数召回率 检测精度 平均重复
检测框个数91.49 84.77 11.89 2 4 6 92.39 85.45 8.87 4 8 12 93.26 85.59 8.56 6 12 18 92.13 85.16 8.59 8 16 24 88.19 85.11 7.18 10 20 30 80.76 81.13 6.12
下载: 导出CSV
表 3 CrowdHuman数据集上基于Faster R-CNN+IterDet的权重系数实验结果
Table 3. Experimental results of weight coefficient based on Faster R-CNN+IterDet on CrowdHuman dataset
轻度遮挡
权重系数中度遮挡
权重系数重度遮挡
权重系数召回率 检测精度 平均重复
检测框个数95.80 88.08 8.45 2 4 6 96.14 89.18 7.34 4 8 12 96.54 89.56 6.12 6 12 18 96.34 88.65 5.06 8 16 24 95.16 85.17 5.12 10 20 30 90.46 83.14 4.06
下载: 导出CSV
表 4 WiderPerson数据集上基于RetinaNet+IterDet的权重系数实验结果
Table 4. Experimental results of weight coefficient based on RetinaNet+IterDet on WiderPerson dataset
轻度遮挡
权重系数中度遮挡
权重系数重度遮挡
权重系数召回率 检测精度 平均重复
检测框个数95.35 90.23 8.66 2 4 6 95.44 91.59 7.15 4 8 12 96.13 92.43 6.21 6 12 18 95.89 91.87 6.34 8 16 24 90.14 88.56 5.22 10 20 30 88.19 85.34 5.12
下载: 导出CSV
表 5 WiderPerson数据集上基于Faster R-CNN+IterDet的权重系数实验结果
Table 5. Experimental results of weight coefficient based on Faster R-CNN+IterDet on WiderPerson dataset
轻度遮挡
权重系数中度遮挡
权重系数重度遮挡
权重系数召回率 检测精度 平均重复
检测框个数97.15 91.95 5.65 2 4 6 97.16 92.59 4.49 4 8 12 97.60 93.14 4.45 6 12 18 94.17 90.15 4.19 8 16 24 90.23 88.71 4.01 10 20 30 88.59 84.88 3.67
下载: 导出CSV
表 6 CrowdHuman数据集上的消融实验结果
Table 6. Ablation experimental results on CrowdHuman dataset
检测器 召回率 检测精度 平均重复检测框个数 IterDet IterDet+HIFEM IterDet IterDet+HIFEM IterDet IterDet+HIFEM RetinaNet 91.49 96.76 84.77 88.98 11.89 3.34 Faster R-CNN 95.80 97.10 88.08 91.10 8.45 2.21
下载: 导出CSV
表 7 WiderPerson数据集上的消融实验结果
Table 7. Ablation experimental results on WiderPerson dataset
检测器 召回率 检测精度 平均重复检测框个数 IterDet IterDet+HIFEM IterDet IterDet+HIFEM IterDet IterDet+HIFEM RetinaNet 95.35 97.60 90.23 94.70 8.66 4.12 Faster R-CNN 97.15 98.23 91.95 95.40 5.65 1.81
下载: 导出CSV
表 8 CrowdHuman数据集对比实验结果
Table 8. Results of comparison experiment on CrowdHuman dataset
检测器 召回率 检测精度 Baseline PS-RCNN IterDet 本文方法 Baseline PS-RCNN IterDet 本文方法 RetinaNet 93.80 91.49 97.40 80.83 84.77 89.73 Faster R-CNN 90.24 93.77 95.80 97.98 84.95 86.05 88.08 91.15
下载: 导出CSV
表 9 WiderPerson数据集对比实验结果
Table 9. Results of comparison experiment on WiderPerson dataset
检测器 召回率 检测精度 Baseline PS-RCNN IterDet 本文方法 Baseline PS-RCNN IterDet 本文方法 RetinaNet 90.20 95.35 98.87 89.12 90.23 95.99 Faster R-CNN 93.60 94.71 97.15 98.67 88.89 89.96 91.95 96.67
下载: 导出CSV
-
[1] 邱博, 刘翔, 石蕴玉, 等. 一种轻量化的多目标实时检测模型[J]. 北京航空航天大学学报, 2020, 46(9): 1778-1785. doi: 10.13700/j.bh.1001-5965.2020.0066QIU B, LIU X, SHI Y Y, et al. A lightweight multi-target real-time detection model[J]. Journal of Beijing University of Aeronautics and Astronautics, 2020, 46(9): 1778-1785(in Chinese). doi: 10.13700/j.bh.1001-5965.2020.0066 [2] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2014: 580-587. [3] HE K M, ZHANG X Y, REN S Q, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916. doi: 10.1109/TPAMI.2015.2389824 [4] GIRSHICK R. Fast R-CNN [C]//IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2016: 1440-1448. [5] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. doi: 10.1109/TPAMI.2016.2577031 [6] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 779-788. [7] REDMON J, FARHADI A. YOLO9000: Better, faster, stronger[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 6517-6525. [8] REDMON J, FARHADI A. YOLOv3: An incremental improvement[EB/OL]. (2018-04-08)[2021-06-06], [9] BOCHKOVSKIY A, WANG C Y, LIAO H. YOLOv4: Optimal speed and accuracy of object detection[EB/OL]. (2020-04-23) [2021-06-06]. [10] LIU W, ANGUELOV D, ERHAN D, et al. SSD: Single shot multibox detector[C]//European Conference on Computer Vision. Berlin: Springer, 2016: 21-37. [11] LAW H, DENG J. CornerNet: Detecting objects as paired keypoints[J]. International Journal of Computer Vision, 2020, 128(3): 642-656. doi: 10.1007/s11263-019-01204-1 [12] ZHOU X Y, ZHUO J C, KRÄHENBÜHL P. Bottom-up object detection by grouping extreme and center points[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 850-859. [13] TIAN Z, SHEN C H, CHEN H, et al. FCOS: Fully convolutional one-stage object detection[C]//IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2020: 9626-9635. [14] ZHANG S F, CHI C, YAO Y Q, et al. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 9756-9765. [15] 罗会兰, 陈鸿坤. 基于深度学习的目标检测研究综述[J]. 电子学报, 2020, 48(6): 1230-1239. doi: 10.3969/j.issn.0372-2112.2020.06.026LUO H L, CHEN H K. Survey of object detection based on deep learning[J]. Acta Electronica Sinica, 2020, 48(6): 1230-1239(in Chinese). doi: 10.3969/j.issn.0372-2112.2020.06.026 [16] GE Z, JIE Z, HUANG X, et al. PS-RCNN: Detecting secondary human instances in a crowd via primary object suppression [EB/OL]. (2020-03-16) [2021-06-06]. [17] RUKHOVICH D, SOFIIUK K, GALEEV D, et al. IterDet: Iterative scheme for object detection in crowded environments[C]//Structural, Syntactic, and Statistical Pattern Recognition. Beilin: Springer, 2021: 344-354. [18] 王海, 王宽, 蔡英凤, 等. 基于改进级联卷积神经网络的交通标志识别[J]. 汽车工程, 2020, 42(9): 1256-1262. doi: 10.19562/j.chinasae.qcgc.2020.09.016WANG H, WANG K, CAI Y F, et al. Traffic sign recognition based on improved cascade convolution neural network[J]. Automotive Engineering, 2020, 42(9): 1256-1262(in Chinese). doi: 10.19562/j.chinasae.qcgc.2020.09.016 [19] 郑浦, 白宏阳, 李伟, 等. 复杂背景下的小目标检测算法[J]. 浙江大学学报(工学版), 2020, 54(9): 1777-1784. doi: 10.3785/j.issn.1008-973X.2020.09.014ZHENG P, BAI H Y, LI W, et al. Small target detection algorithm in complex background[J]. Journal of Zhejiang University (Engineering Science), 2020, 54(9): 1777-1784(in Chinese). doi: 10.3785/j.issn.1008-973X.2020.09.014 [20] 马立, 巩笑天, 欧阳航空. Tiny YOLOV3目标检测改进[J]. 光学精密工程, 2020, 28(4): 988-995.MA L, GONG X T, OUYANG H K. Improvement of Tiny YOLOV3 target detection[J]. Optics and Precision Engineering, 2020, 28(4): 988-995(in Chinese). [21] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 936-944. [22] LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 8759-8768. [23] PANG J M, CHEN K, SHI J P, et al. Libra R-CNN: Towards balanced learning for object detection[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 821-830. [24] SHAO S, ZHAO Z J, LI B X, et al. CrowdHuman: A benchmark for detecting human in a crowd[EB/OL]. (2018-04-30)[2021-06-06]. [25] ZHANG S F, XIE Y L, WAN J, et al. WiderPerson: A diverse dataset for dense pedestrian detection in the wild[J]. IEEE Transactions on Multimedia, 2020, 22(2): 380-393. doi: 10.1109/TMM.2019.2929005 -

 下载:
下载:




 点击查看大图
点击查看大图
计量
- 文章访问数: 1900
- HTML全文浏览量: 46
- PDF下载量: 10
- 被引次数: 0
