



-
摘要:
在室外监控视频的场景下,由于场景的复杂性及目标的多样性,监控视频中的目标存在难以检测的情况,如目标被遮挡、目标尺寸变化等,目标检测任务仍然存在挑战。基于此,提出了一种利用运动信息引导基于卷积神经网络的目标检测算法来提高目标检测的准确率。对运动目标检测算法进行一定的改进,使得到的运动前景图中能够保持静止目标前景的存在;利用运动前景图中的前景可以指示目标空间位置的特点,在特征层面将网络提取的特征图与获取的以运动前景图为主的运动信息相融合,提高特征图可能存在目标区域的响应值;在目标检测算法的检测器中,引入一个定位分支,利用视频帧的运动前景图,学习候选目标的定位置信度,并与目标的分类置信度加权求和,作为目标最终的置信度,再通过非极大值抑制方法得到检测结果。实验证明,在固定摄像机下采集的数据集中,所提算法能够提升目标检测的准确率。
Abstract:Due to the complexity of the scene and the diversity of objects, the objects in the scene of outdoor surveillance video are difficult to detect, which involves such problems like the object is blocked, or the size of object changes. Therefore, the object detection task is still challenging. To improve the accuracy of the object detection algorithm, this paper proposed a method of using motion information to guide the object detection algorithm based on convolutional neural network. Firstly, the motion object detection algorithm is improved to keep the foreground of stationary target in the motion foreground map; secondly, using the feature that the foreground in the motion foreground map can indicate the spatial position of the object, the feature map extracted by the network is fused with the motion information to improve the response value of the possible object area in the feature map; finally, in the detector of the object detection algorithm, a localization branch is introduced. Using the motion foreground map of the video frame, the location reliability of the candidate object is learned, and weighted sum with the classification confidence of the object is used as the final confidence of the object. The detection result is obtained through the non maximum suppression method. Experiments show that the proposed method can improve the accuracy of object detection in the data set collected under the fixed camera.
-
Key words:
- motion information /
- foreground area /
- feature fusion /
- localization branch /
- object detection
-

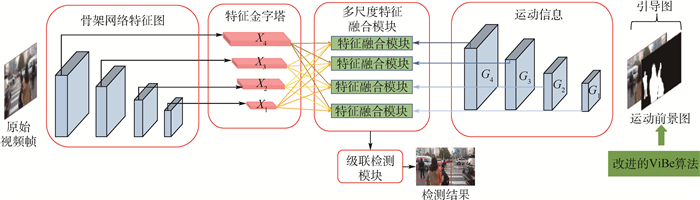
图 3 基于运动信息的多尺度特征融合模块网络结构
Figure 3. Network structure of multi-scale feature fusion module based on motion information

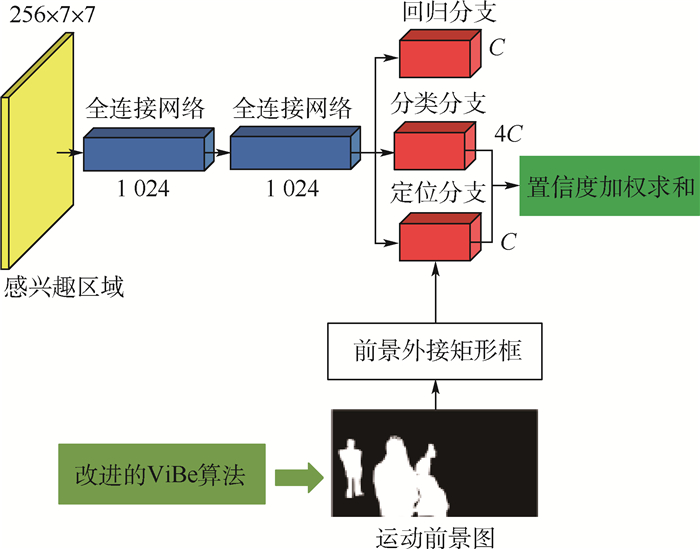
图 5 引入定位分支后的检测器结构
Figure 5. Detection head structure after introducing localization branch
表 1 DML_det数据集上本文算法与其他目标检测算法对比
Table 1. Comparison of the proposed algorithm with other object detection algorithms on DML_det dataset
%  下载: 导出CSV
下载: 导出CSV
表 2 DukeMTMC数据集上本文算法与其他目标检测算法对比
Table 2. Comparison of the proposed algorithm with other object detection algorithms on DukeMTMC dataset
%
下载: 导出CSV
表 3 PETS09数据集上本文算法与其他目标检测算法对比
Table 3. Comparison of the proposed algorithm with other object detection algorithms on PETS09 dataset
%
下载: 导出CSV
表 4 DML_det数据集性能评价指标
Table 4. Performance evaluation indexes of DML_det dataset
方法 评价指标/% Cascade R-CNN 改进ViBe算法 多尺度特征融合 定位分支 AP@[0.5:0.95] Recall@[0.5:0.95] √ 35.5 52.5 √ √ √ 40.1 56.4 √ √ √ 40.7 57.8 √ √ √ 41.9 58.5 √ √ √ √ 43.6 57.7
下载: 导出CSV
表 5 DukeMTMC数据集性能评价指标
Table 5. Performance evaluation indexes of DukeMTMC dataset
方法 评价指标/% Cascade R-CNN 改进ViBe算法 多尺度特征融合 定位分支 AP@[0.5:0.95] Recall@[0.5:0.95] √ 58.1 68.2 √ √ √ 60.4 69.3 √ √ √ 60.2 70.3 √ √ √ 61.2 70.7 √ √ √ √ 62.0 71.0
下载: 导出CSV
表 6 PETS09数据集性能评价指标
Table 6. Performance evaluation indexes of PETS09 dataset
方法 评价指标/% Cascade R-CNN 改进ViBe算法 多尺度特征融合 定位分支 AP@[0.5:0.95] Recall@[0.5:0.95] √ 38.2 54.8 √ √ √ 40.0 57.2 √ √ √ 39.9 57.3 √ √ √ 41.2 56.7 √ √ √ √ 42.3 57.9
下载: 导出CSV
-
[1] DOLLAR P, WOJEK C, SCHIELE B, et al. Pedestrian detection: An evaluation of the state of the art[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 34(4): 743-761. [2] DALAL N, TRIGGS B. Histograms of oriented gradients for human detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2005, 1: 886-893. [3] AHONEN T, HADID A, PIETIKÄINEN M. Face recognition with local binary patterns[C]//European Conference on Computer Vision. Berlin: Springer, 2004: 469-481. [4] LOWE D G. Distinctive image features from scale-invariant keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91-110. doi: 10.1023/B:VISI.0000029664.99615.94 [5] SINGLA N. Motion detection based on frame difference method[J]. International Journal of Information & Computation Technology, 2014, 4(15): 1559-1565. [6] ZIVKOVIC Z. Improved adaptive Gaussian mixture model for background subtraction[C]//Proceedings of the 17th International Conference on Pattern Recognition. Piscataway: IEEE Press, 2004, 2: 28-31. [7] BARNICH O, VAN DROOGENBROECK M. ViBe: A universal background subtraction algorithm for video sequences[J]. IEEE Transactions on Image Processing, 2010, 20(6): 1709-1724. [8] PICCARDI M. Background subtraction techniques: A review[C]//2004 IEEE International Conference on Systems, Man and Cybernetics. Piscataway: IEEE Press, 2004, 4: 3099-3104. [9] LIU W, ANGUELOV D, ERHAN D, et al. SSD: Single shot multibox detector[C]//European Conference on Computer Vision. Berlin: Springer, 2016: 21-37. [10] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 779-788. [11] REDMON J, FARHADI A. YOLO9000: Better, faster, stronger[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 7263-7271. [12] REDMON J, FARHADI A. YOLOv3: An incremental improvement[EB/OL]. (2018-04-08)[2022-04-08]. https://arxiv.org/abs/1804.02767v1. [13] BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: Optimal speed and accuracy of object detection[J]. Artificial Intelligence, 2020, 4: 1-17. [14] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 2980-2988. [15] GIRSHICK R, DONAHUE J, DARRELL T, et al. Region-based convolutional networks for accurate object detection and segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 38(1): 142-158. [16] GIRSHICK R. Fast R-CNN[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2015: 1440-1448. [17] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. Advances in Neural Information Processing Systems, 2017, 39(6): 1137-1149. [18] CAI Z, VASCONCELOS N. Cascade R-CNN: Delving into high quality object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 6154-6162. [19] ZHU X, XIONG Y, DAI J, et al. Deep feature flow for video recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 2349-2358. [20] ZHU X, WANG Y, DAI J, et al. Flow-guided feature aggregation for video object detection[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 408-417. [21] REZATOFIGHI H, TSOI N, GWAK J Y, et al. Generalized intersection over union: A metric and a loss for bounding box regression[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 658-666. [22] JIANG B, LUO R, MAO J, et al. Acquisition of localization confidence for accurate object detection[C]//European Conference on Computer Vision. Berlin: Springer, 2018: 784-799. [23] WU S, LI X, WANG X. IoU-aware single-stage object detector for accurate localization[J]. Image and Vision Computing, 2020, 97: 103911. [24] NEUBECK A, VAN GOOL L. Efficient non-maximum suppression[C]//Proceedings of the 18th International Conference on Pattern Recognition. Piscataway: IEEE Press, 2006, 3: 850-855. [25] WANG X, HU H M, ZHANG Y. Pedestrian detection based on spatial attention module for outdoor video surveillance[C]//2019 IEEE 15th International Conference on Multimedia Big Data (BigMM). Piscataway: IEEE Press, 2019: 247-251. [26] ZHANG Z, WU J, ZHANG X, et al. Multi-target, multi-camera tracking by hierarchical clustering: Recent progress on dukemtmc project[EB/OL]. (2017-11-27)[2022-04-08]. https://arxiv.org/abs/1712.09531. [27] FERRYMAN J, SHAHROKNI A. PETS2009: Dataset and challenge[C]//2009 12th IEEE International Workshop on Performance Evaluation of Tracking and Surveillance. Piscataway: IEEE Press, 2009: 1-6. [28] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in context[C]//European Conference on Computer Vision. Berlin: Springer, 2014: 740-755. [29] FENG C, ZHONG Y, GAO Y, et al. TOOD: Task-aligned one-stage object detection[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2021: 3490-3499. [30] ZHANG H, CHANG H, MA B, et al. Dynamic R-CNN: Towards high quality object detection via dynamic training[C]//European Conference on Computer Vision. Berlin: Springer, 2020: 260-275. [31] ZHANG S, CHI C, YAO Y, et al. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 9759-9768. [32] ZHANG H, WANG Y, DAYOUB F, et al. VarifocalNet: An iou-aware dense object detector[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 8514-8523. [33] CHEN Q, WANG Y, YANG T, et al. You only look one-level feature[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 13039-13048. [34] SUN P, ZHANG R, JIANG Y, et al. Sparse R-CNN: End-to-end object detection with learnable proposals[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 14454-14463. [35] GE Z, LIU S, WANG F, et al. YOLOX: Exceeding YOLO series in 2021[EB/OL]. (2021-08-06)[2022-04-08]. https://arxiv.org/abs/2107.08430. [36] KONG T, SUN F, LIU H, et al. FoveaBox: Beyound anchor-based object detection[J]. IEEE Transactions on Image Processing, 2020, 29: 7389-7398. [37] WU Y, CHEN Y, YUAN L, et al. Rethinking classification and localization for object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 10186-10195. [38] WANG N, GAO Y, CHEN H, et al. NAS-FCOS: Fast neural architecture search for object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 11943-11951. [39] ZHU X, SU W, LU L, et al. Deformable DETR: Deformable transformers for end-to-end object detection[EB/OL]. (2021-03-18)[2022-04-08]. https://arxiv.org/abs/2010.04159v1. -

 下载:
下载:









 点击查看大图
点击查看大图

计量
- 文章访问数: 312
- HTML全文浏览量: 150
- PDF下载量: 52
- 被引次数: 0
