



-
摘要:
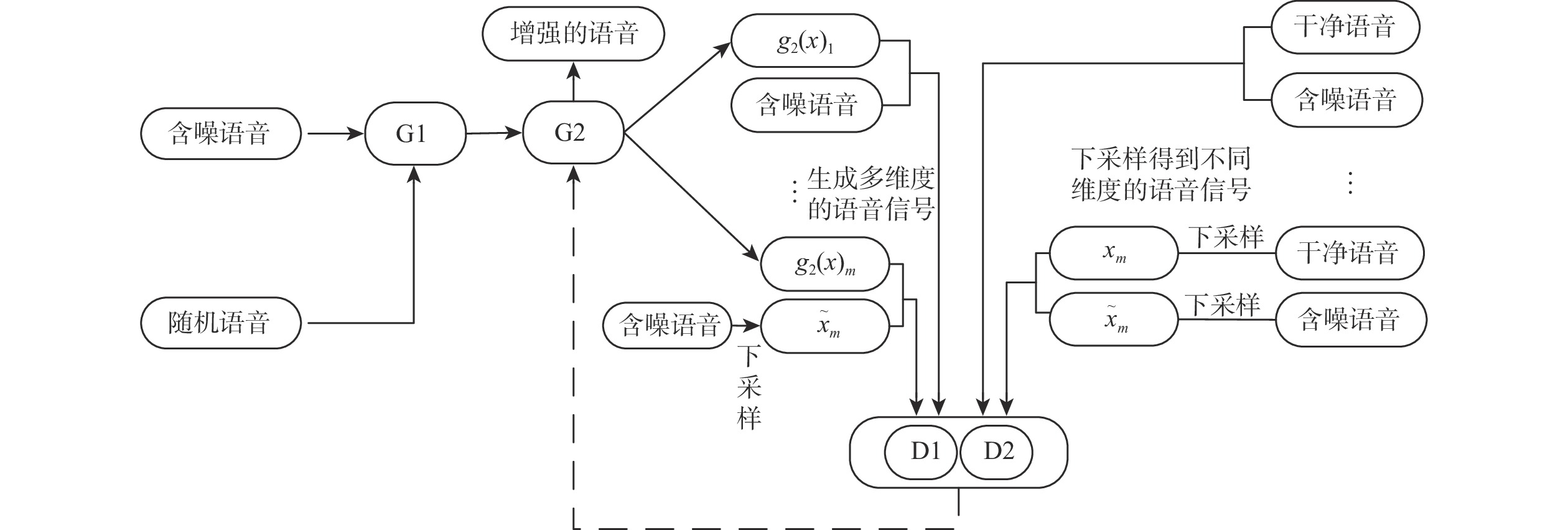
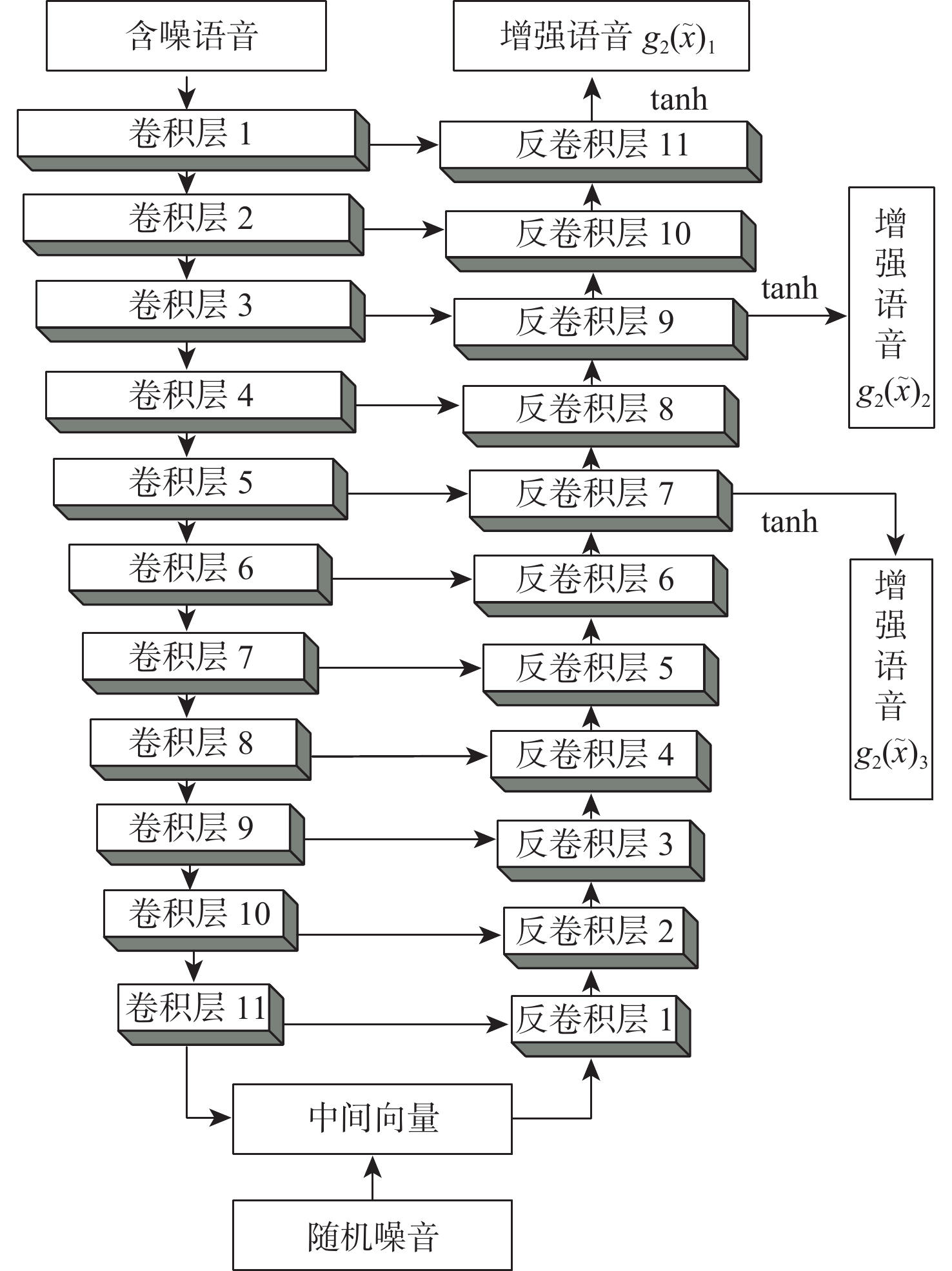
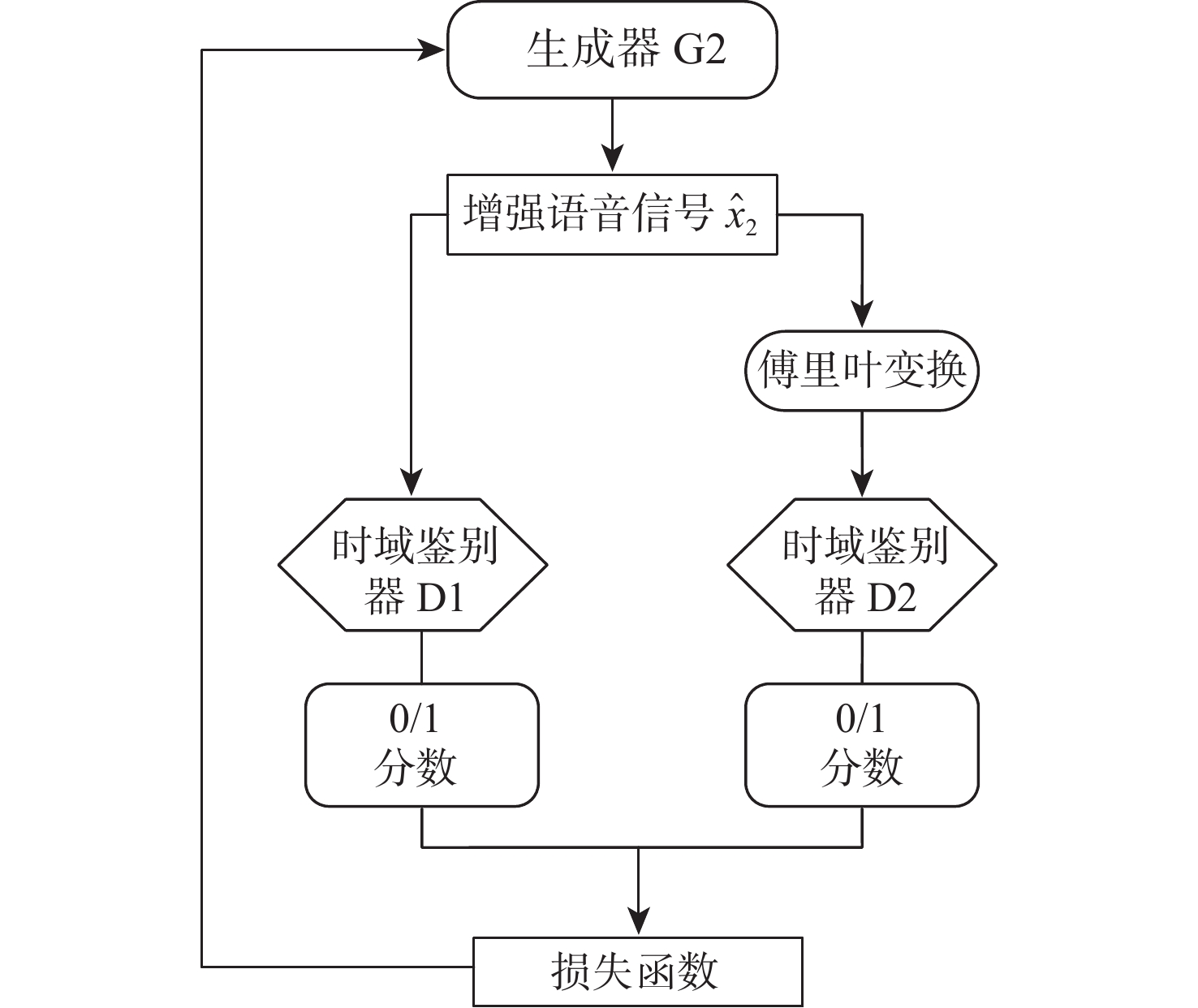
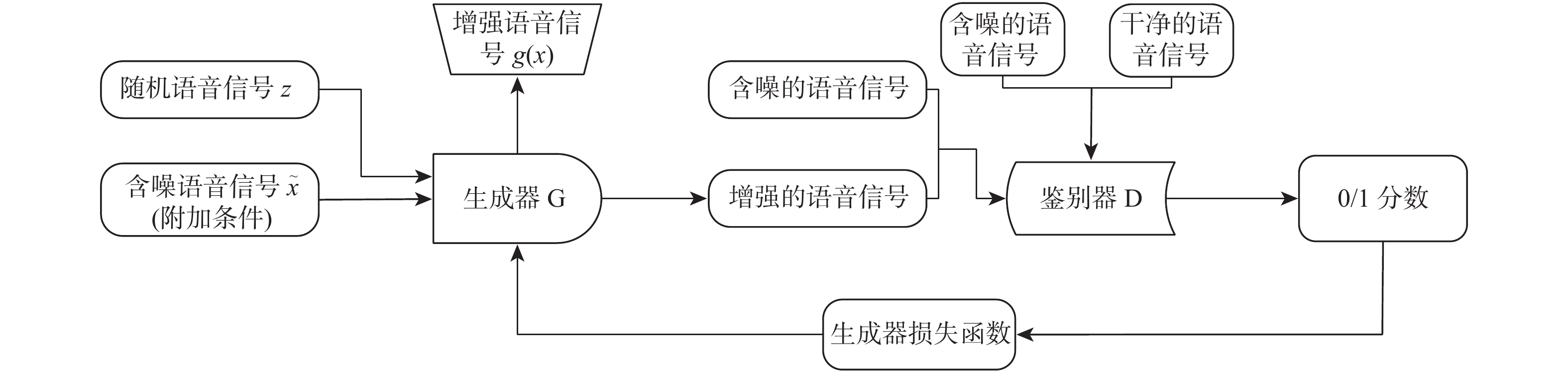
为提高空中交通管制过程中语音通话质量,提出了一种改进生成对抗网络的空管语音增强算法(SEGAN)。针对传统的SEGAN在低信噪比条件下,语音信号被淹没的问题,在SEGAN网络模型的基础上提出了多阶段、多映射、多维度输出的生成器和多尺度、多个鉴别器的网络模型。基于深层神经网络结构提取语音语义特征,完成空管语音语义分段;设置多个生成器,对语音信号做进一步优化处理;在卷积层中添加下采样模块,以提高模型对语音信息的利用率,减少语音信息的流失;采用多尺度、多个鉴别器、多方位学习语音样本的分布规律和信息。结果表明,在低信噪比条件下,改进SEGAN模型在短时客观可懂度(STOI)和语音质量感知评估(PESQ) 2个指标上分别提高23.28%和20.11%,能够快速有效的进行空管语音增强,为后续空管语音识别提供准备工作。
Abstract:An enhanced version of the Speech Enhancement Generative Adversarial Network (SEGAN) algorithm used in air traffic control (ATC) is suggested in an effort to raise the standard of radiotelephony communication. Aiming at the problem that the traditional SEGAN is submerged under the condition of low signal-to-noise ratio, a multi-stage, multi-mapping, multi-dimensional output generation and multi-scale, multi-discriminator network models are proposed. First, the deep neural network structure is used to extract the speech semantic features, and the ATC speech semantic segmentation is finished. Secondly, set up multiple generators to further optimize the speech signal. Then, a down sampling module is added to the convolutional layer to improve the utilization of speech information by the model and reduce the loss of speech information. Finally, multi-scale, multiple discriminators are used to learn the distribution law and information of speech samples in multiple directions. According to the results, the improved SEGAN model's Short-Time Objective Intelligibility (STOI) and Perceptual Evaluation of Speech Quality (PESQ) are improved by 23.28% and 20.11%, respectively, under low signal-to-noise ratio conditions. This can effectively and swiftly improve ATC speech, making it a good option for follow-up. Provide preparatory work for subsequent Automatic Speech Recognition of ATC.
-

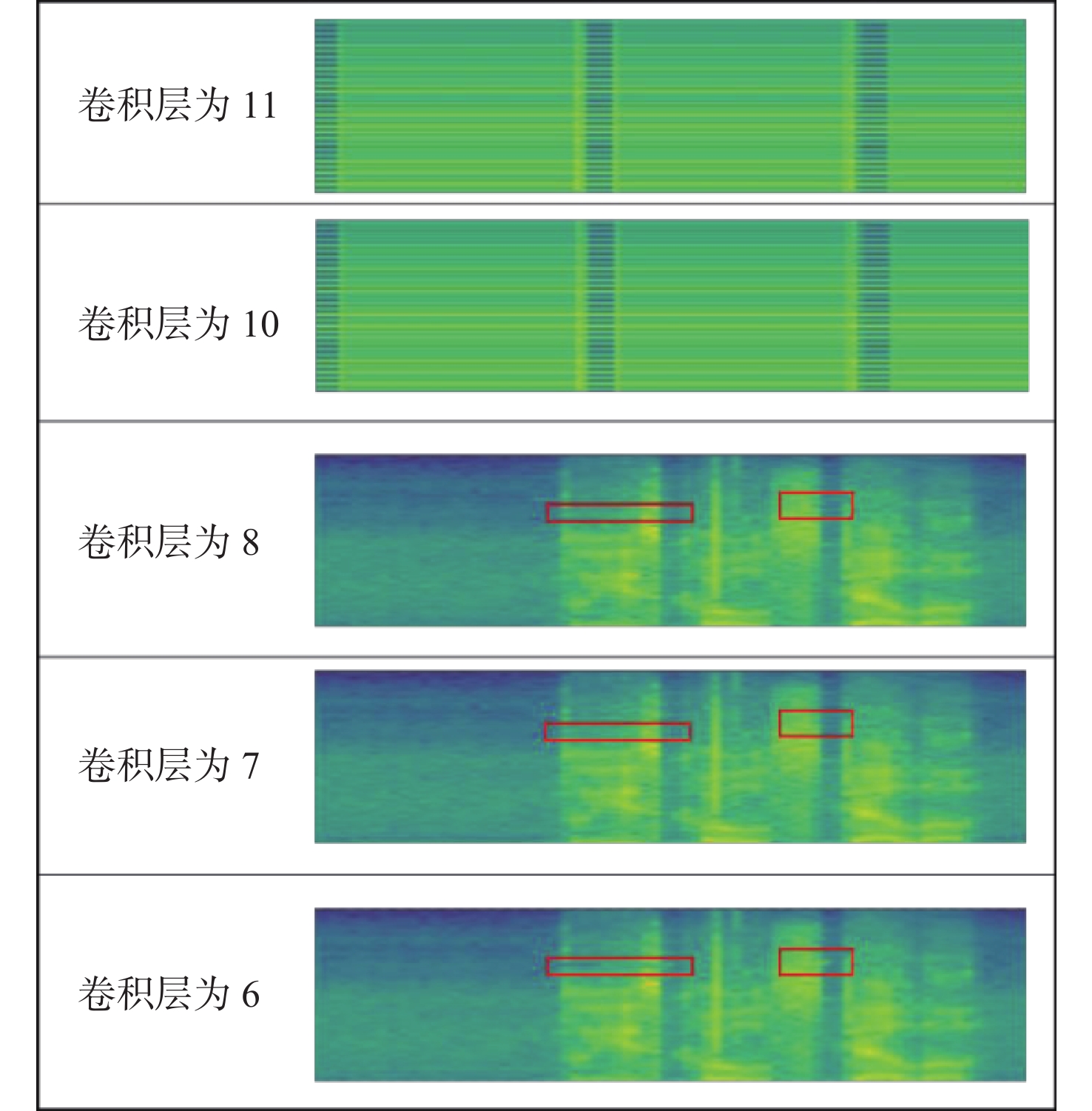
图 8 不同卷积层的声谱图性能对比
Figure 8. Comparison of acoustic spectrogram performance of different convolution layers
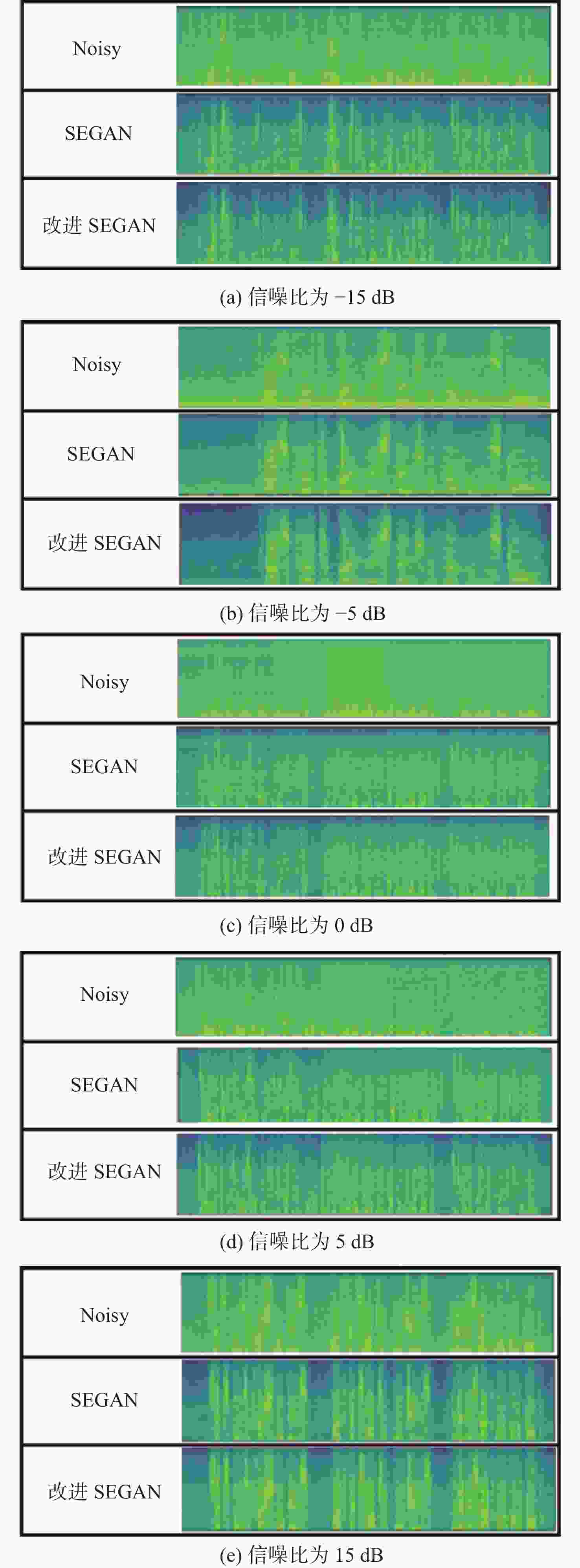
图 9 不同信噪比条件下语音频谱对比图
Figure 9. Contrast chart of speech spectrum under different signal-to-noise ratio conditions
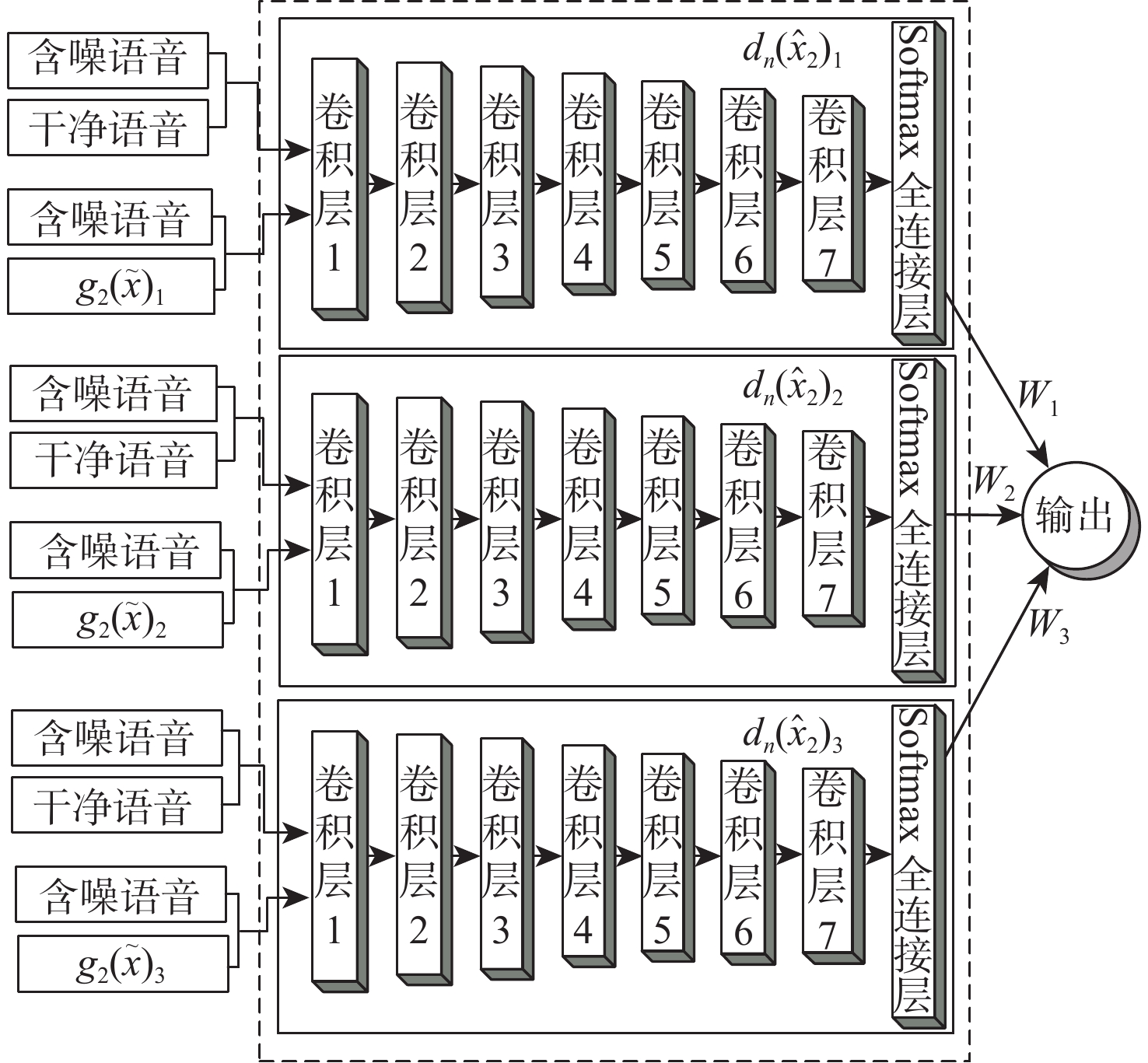
表 1 子鉴别器1
Table 1. Sub-discriminator 1
网络层 卷积核大小 步长 输入大小 输出大小 激活函数 卷积层1 31 4 16 384×1 4 096×16 LeakyReLU 卷积层2 31 4 4 096×16 1 024×32 LeakyReLU 卷积层3 31 4 1 024×32 256×64 LeakyReLU 卷积层4 31 4 256×64 64×128 LeakyReLU 卷积层5 31 4 64×128 16×256 LeakyReLU 卷积层6 31 4 16×256 4×512 LeakyReLU 卷积层7 1 4 4×512 4×1 LeakyReLU 全连接层 无 无 4×1 1 Softmax  下载: 导出CSV
下载: 导出CSV
表 2 子鉴别器2
Table 2. Sub-discriminator 2
网络层 卷积核大小 步长 输入大小 输出大小 激活函数 卷积层1 31 4 4 096×16 1 024×32 LeakyReLU 卷积层2 31 4 1 024×32 256×64 LeakyReLU 卷积层3 31 4 256×64 64×128 LeakyReLU 卷积层4 31 4 64×128 16×256 LeakyReLU 卷积层5 31 4 16×256 4×512 LeakyReLU 卷积层6 1 4 4×512 4×1 LeakyReLU 全连接层 无 无 4×1 1 Softmax
下载: 导出CSV
表 3 子鉴别器3
Table 3. Sub-discriminator 3
网络层 卷积核大小 步长 输入大小 输出大小 激活函数 卷积层1 31 4 1 024×32 256×64 LeakyReLU 卷积层2 31 4 256×64 64×128 LeakyReLU 卷积层3 31 4 64×128 16×256 LeakyReLU 卷积层4 31 4 16×256 4×512 LeakyReLU 卷积层5 1 4 4×512 4×1 LeakyReLU 全连接层 无 无 4×1 1 Softmax
下载: 导出CSV
表 4 不同信噪比下STOI的评价结果
Table 4. Evaluation results of STOI under different signal-to-noise ratios
模型 评价结果 −15 dB −5 dB 0 dB 5 dB 15 dB Noisy 0.640 4 0.798 2 0.872 1 0.934 2 0.954 1 SEGAN 0.621 2 0.803 1 0.898 4 0.924 6 0.951 7 TFSEGAN 0.651 7 0.820 4 0.900 2 0.940 8 0.954 4 改进SEGAN 0.765 8 0.891 2 0.922 3 0.946 5 0.969 3
下载: 导出CSV
表 5 不同信噪比下PESQ的评价结果
Table 5. Evaluation results of PESQ under different signal-to-noise ratios
模型 评价结果 −15 dB −5 dB 0 dB 5 dB 15 dB Noisy 1.097 8 1.297 3 1.613 0 1.823 4 2.230 4 SEGAN 1.028 9 1.328 6 1.723 8 2.046 3 2.395 6 TFSEGAN 1.151 9 1.435 9 1.760 3 2.095 7 2.417 2 改进SEGAN 1.235 8 1.482 8 1.848 9 2.151 8 2.580 3
下载: 导出CSV
表 6 MOS评分标准
Table 6. MOS scoring criteria
MOS得分 语音质量等级 参与者感受 1 劣 不能忍受 2 差 厌烦但能忍受 3 中 听到噪声,可接受 4 良 刚能听到噪声 5 优 几乎听不出噪声
下载: 导出CSV
表 7 测评结果
Table 7. Evaluation results
模型 测评结果 总计 MOS 1 2 3 4 5 Noisy 3 8 89 0 0 100 2.86 SEGAN 0 0 72 28 0 100 3.28 DSEGAN 0 0 58 41 1 100 3.43 改进SEGAN 0 0 13 83 4 100 3.91
下载: 导出CSV
表 8 不同区管不同信噪比下STOI的评价结果
Table 8. Evaluation results of STOI with different signal-to-noise ratios for different zone tubes
模型 评价结果 −15 dB −5 dB 0 dB 5 dB 15 dB Noisy 0.640 4 0.798 2 0.872 1 0.934 2 0.954 1 中国XX空管中心 0.765 8 0.891 2 0.922 3 0.946 5 0.969 3 区管1 0.765 2 0.890 9 0.921 7 0.946 0 0.968 9 区管2 0.764 5 0.889 6 0.920 1 0.945 8 0.968 6 区管3 0.764 0 0.889 3 0.910 5 0.945 9 0.969 0
下载: 导出CSV
表 9 不同区管不同信噪比下PESQ的评价结果
Table 9. Evaluation results of PESQ with different signal-to-noise ratios for different zone pipes
模型 评价结果 −15 dB −5 dB 0 dB 5 dB 15 dB Noisy 1.097 8 1.297 3 1.613 0 1.823 4 2.230 4 中国XX空管中心 1.235 8 1.482 8 1.848 9 2.151 8 2.580 3 区管1 1.234 6 1.482 2 1.848 6 2.151 1 2.580 0 区管2 1.235 9 1.482 4 1.848 2 2.150 9 2.580 6 区管3 1.234 0 1.481 7 1.847 9 2.151 3 2.579 9
下载: 导出CSV
-
[1] 张军峰, 游录宝, 周铭, 等. 基于点融合系统的多目标进场排序与调度[J]. 北京航空航天大学学报, 2023, 49(1): 66-73.ZHANG J F, YOU L B, ZHOU M, et al. Multi-objective arrival sequencing and scheduling based on point merge system[J]. Journal of Beijing University of Aeronautics and Astronautics, 2023, 49(1): 66-73 (in Chinese). [2] 王钇翔. 面向民航空中管制语音指令的语音增强算法系统研究与应用[D]. 成都: 电子科技大学, 2022: 46-60.WANG Y X. Research and application of voice enhancement algorithm system for civil aviation air traffic control voice command[D]. Chengdu: University of Electronic Science and Technology of China, 2022: 46-60(in Chinese). [3] 中国民航局. 2018年中国航空安全年度报告 [R]. 北京: 中国民航局, 2019.Civil Aviation Administration of China. Annual report on aviation safety in China, 2018 [R]. Beijing: Civil Aviation Administration of China, 2019(in Chinese). [4] 周坤, 陈文杰, 陈伟海, 等. 基于三次样条插值的扩展谱减语音增强算法[J]. 北京航空航天大学学报, 2023, 49(10): 2826-2834.ZHOU K, CHEN W J, CHEN W H, et al. Spline subtraction speech enhancement based on cubic spline interpolation[J]. Journal of Beijing University of Aeronautics and Astronautics, 2023, 49(10): 2826-2834(in Chinese). [5] KARAM M, KHAZAAL H F, AGLAN H, et al. Noise removal in speech processing using spectral subtraction[J]. Journal of Signal and Information Processing, 2014, 5(2): 32-41. doi: 10.4236/jsip.2014.52006 [6] CHEN J D, BENESTY J, HUANG Y T, et al. New insights into the noise reduction Wiener filter[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2006, 14(4): 1218-1234. doi: 10.1109/TSA.2005.860851 [7] LIM J S, OPPENHEIM A V. Enhancement and bandwidth compression of noisy speech[J]. Proceedings of the IEEE, 1979, 67(12): 1586-1604. doi: 10.1109/PROC.1979.11540 [8] 孙琦. 基于子空间的低计算复杂度语音增强算法研究[D]. 长春: 吉林大学, 2017: 18-23.SUN Q. Research on speech enhancement algorithm with low computational complexity based on subspace[D]. Changchun: Jilin University, 2017: 18-23 (in Chinese). [9] DENDRINOS M, BAKAMIDIS S, CARAYANNIS G. Speech enhancement from noise: A regenerative approach[J]. Speech Communication, 1991, 10(1): 45-57. doi: 10.1016/0167-6393(91)90027-Q [10] TUFTS D W, KUMARESAN R, KIRSTEINS I. Data adaptive signal estimation by singular value decomposition of a data matrix[J]. Proceedings of the IEEE, 1982, 70(6): 684-685. doi: 10.1109/PROC.1982.12367 [11] LEE D D, SEUNG H S. Learning the parts of objects by non-negative matrix factorization[J]. Nature, 1999, 401: 788-791. doi: 10.1038/44565 [12] 娄迎曦, 袁文浩, 时云龙, 等. 融合注意力机制的QRNN语音增强方法[J]. 山东理工大学学报(自然科学版), 2022, 36(3): 7-12.LOU Y X, YUAN W H, SHI Y L, et al. A speech enhancement method based on QRNN incorporating attention mechanism[J]. Journal of Shandong University of Technology (Natural Science Edition), 2022, 36(3): 7-12 (in Chinese). [13] SCHMIDHUBER J. Deep learning in neural networks: An overview[J]. Neural Networks, 2015, 61: 85-117. doi: 10.1016/j.neunet.2014.09.003 [14] SCALART P, FILHO J V. Speech enhancement based on a priori signal to noise estimation[C]// 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing Conference Proceedings. Piscataway: IEEE Press, 1996: 629-632. [15] XU Y, DU J, DAI L R, et al. An experimental study on speech enhancement based on deep neural networks[J]. IEEE Signal Processing Letters, 2014, 21(1): 65-68. doi: 10.1109/LSP.2013.2291240 [16] KANG T G, KWON K, SHIN J W, et al. NMF-based speech enhancement incorporating deep neural network[C]//Interspeech 2014. Singapore: ISCA, 2014. [17] GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial networks[J]. Communications of the ACM, 2020, 63(11): 139-144. doi: 10.1145/3422622 [18] PASCUAL S, BONAFONTE A, SERRÀ J. SEGAN: Speech enhancement generative adversarial network[EB/OL]. (2017-06-09)[2022-10-30]. http://arxiv.org/abs/1703.09452. [19] 尹文兵, 高戈, 曾邦, 等. 基于时频域生成对抗网络的语音增强算法[J]. 计算机科学, 2022, 49(6): 187-192. doi: 10.11896/jsjkx.210500114YIN W B, GAO G, ZENG B, et al. Speech enhancement based on time-frequency domain GAN[J]. Computer Science, 2022, 49(6): 187-192 (in Chinese). doi: 10.11896/jsjkx.210500114 [20] 李晓理, 张博, 王康, 等. 人工智能的发展及应用[J]. 北京工业大学学报, 2020, 46(6): 583-590.LI X L, ZHANG B, WANG K, et al. Development and application of artificial intelligence[J]. Journal of Beijing University of Technology, 2020, 46(6): 583-590 (in Chinese). [21] QUAN T M, NGUYEN-DUC T, JEONG W K. Compressed sensing MRI reconstruction using a generative adversarial network with a cyclic loss[J]. IEEE Transactions on Medical Imaging, 2018, 37(6): 1488-1497. doi: 10.1109/TMI.2018.2820120 [22] PHAN H, MCLOUGHLIN I V, PHAM L, et al. Improving GANs for speech enhancement[J]. IEEE Signal Processing Letters, 2020, 27: 1700-1704. doi: 10.1109/LSP.2020.3025020 [23] PANDEY A, WANG D L. On adversarial training and loss functions for speech enhancement[C]// 2018 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE Press, 2018: 5414-5418. -

 下载:
下载:



 点击查看大图
点击查看大图
计量
- 文章访问数: 191
- HTML全文浏览量: 45
- PDF下载量: 0
- 被引次数: 0
