



Object detection algorithm based on DSGIoU loss and dual branch coordinate attention
-
摘要:
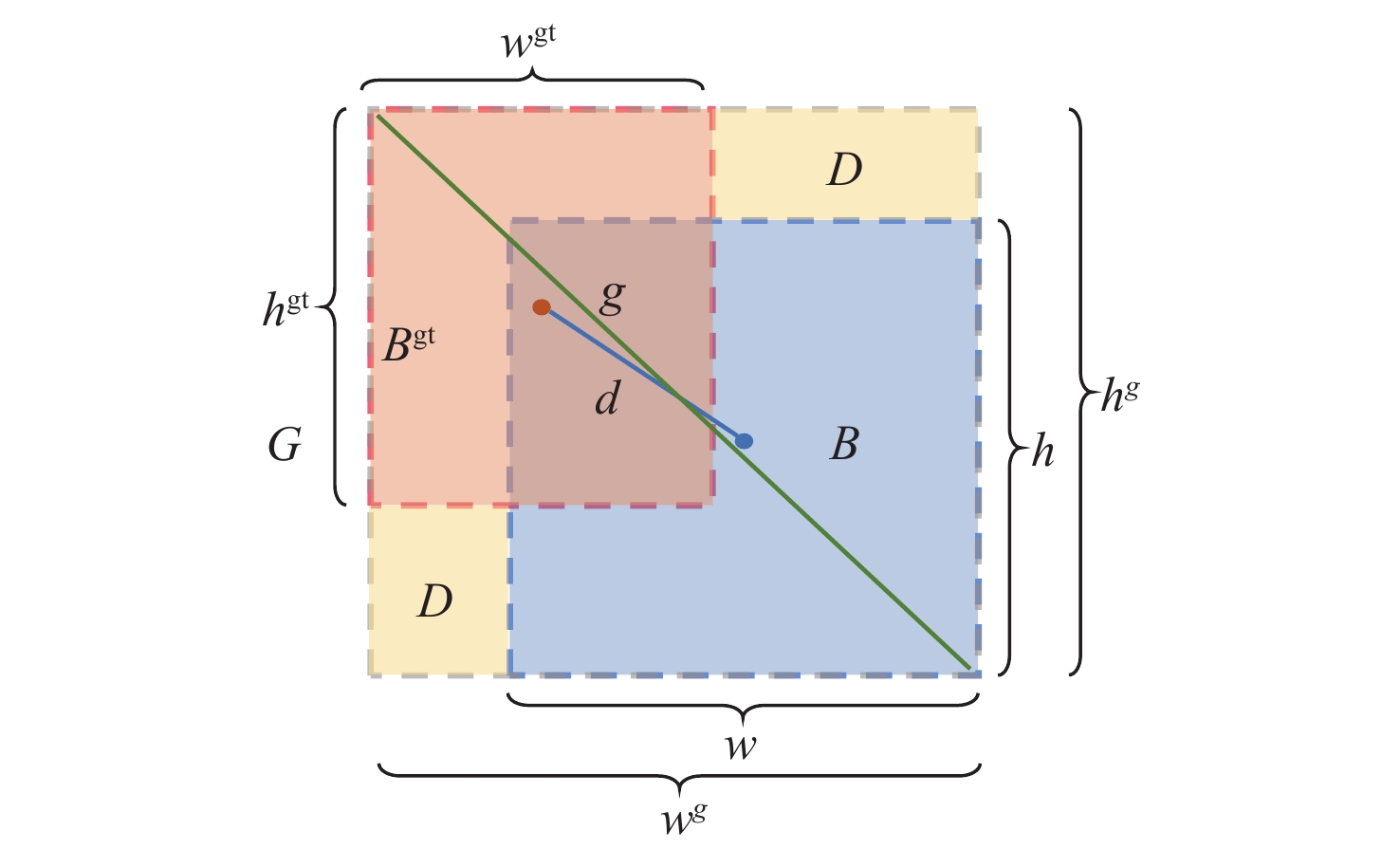
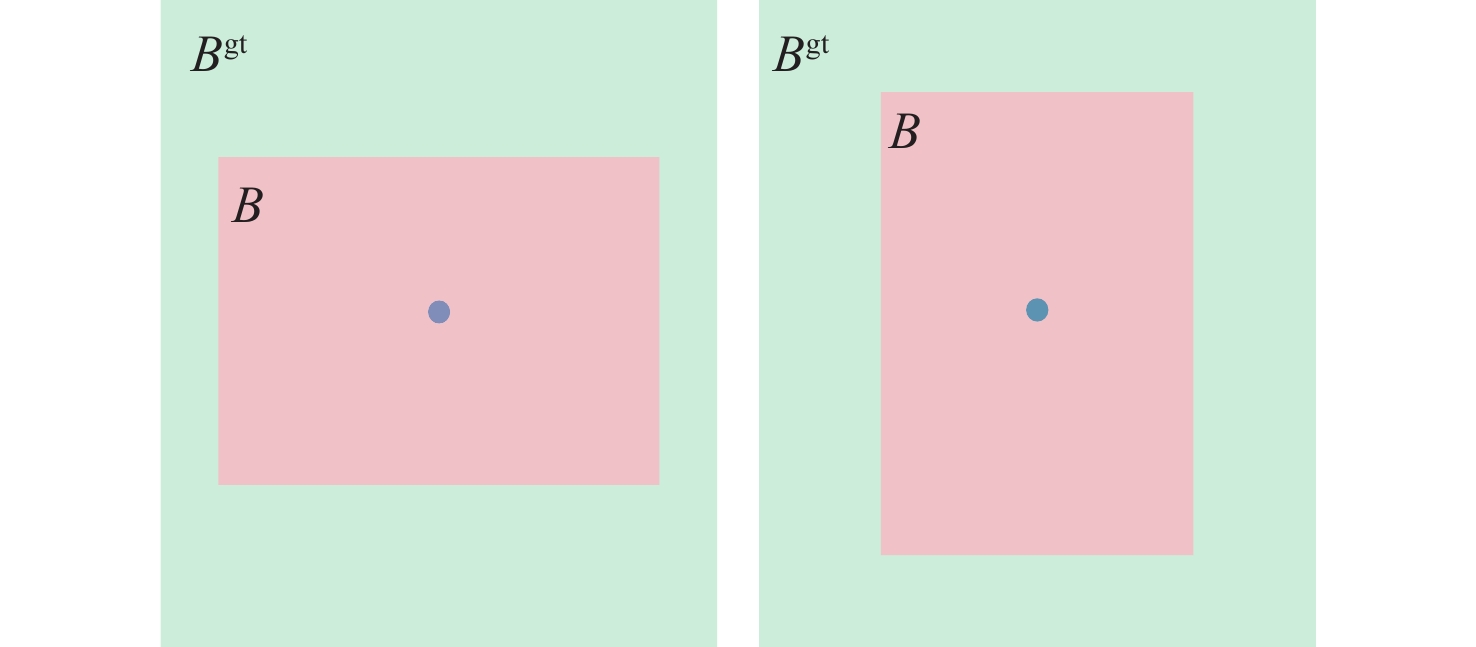
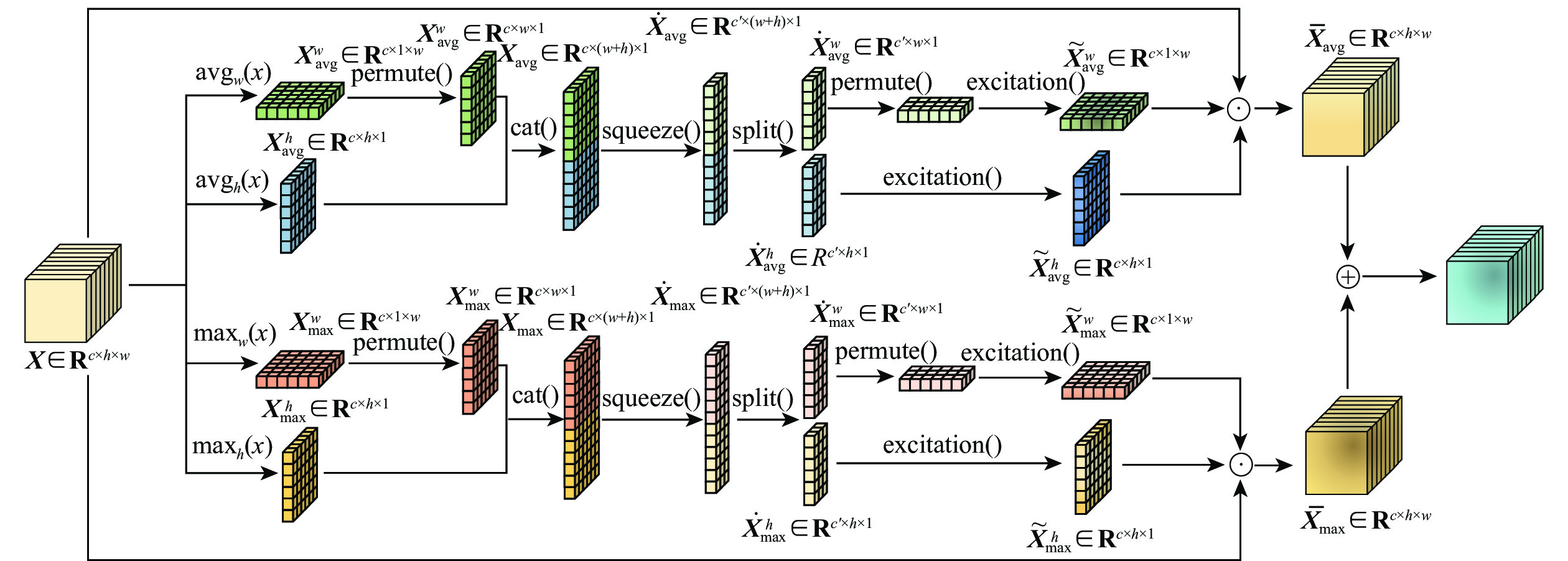
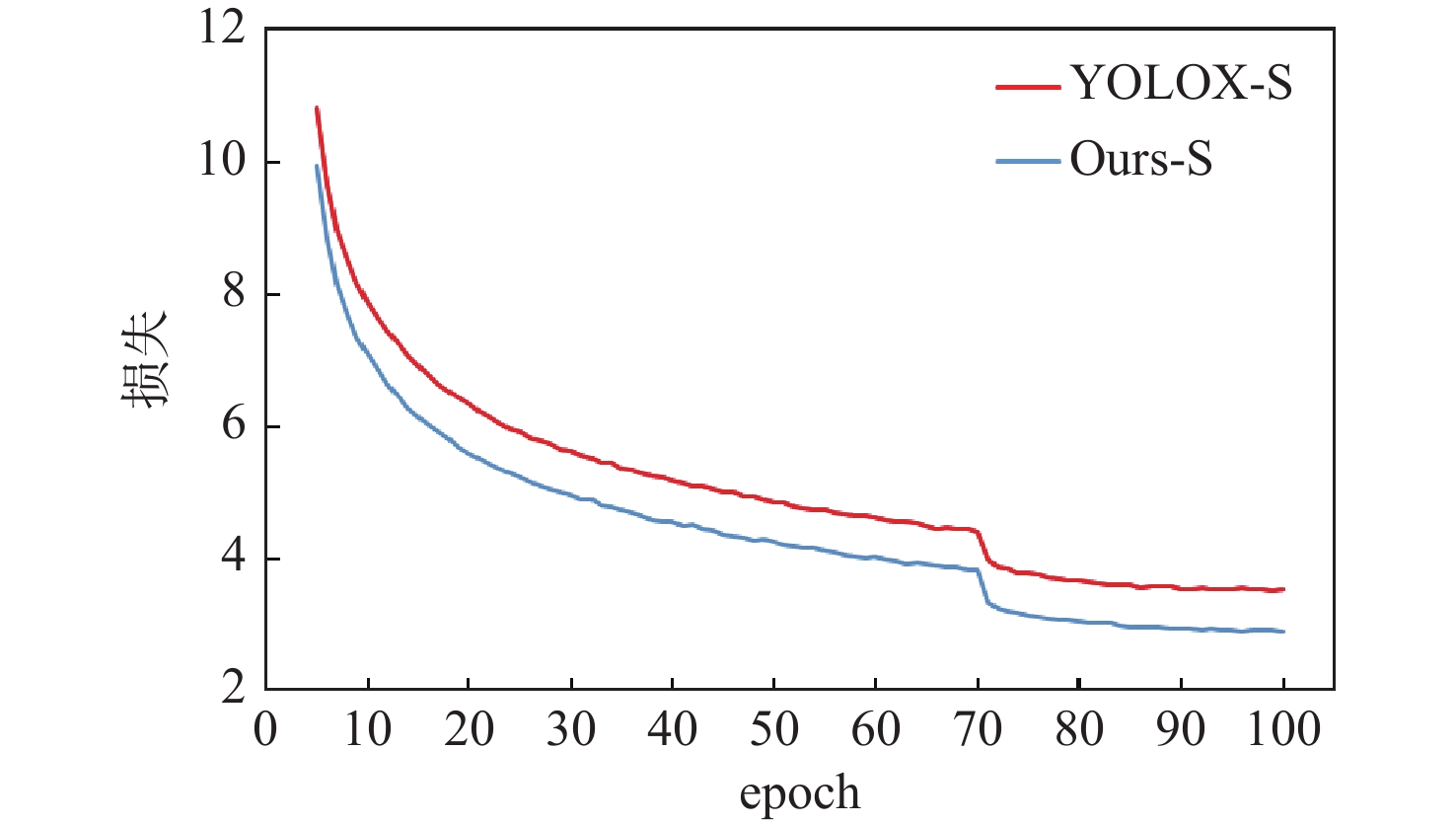
针对YOLOX算法中边界框回归损失效果有限和多尺度特征表示能力不足,导致检测结果不准确的问题,提出一种基于距离形状广义交并比(DSGIoU)损失与双分支坐标注意力的目标检测算法。在交并比(IoU)损失项的基础上,通过添加真实框与预测框之间的非重叠面积、中心点距离及宽高比3个惩罚项,优化边界框的回归收敛效果;通过平均池化和最大池化沿着2个方向对特征进行编码,获取方向感知信息和位置信息,从而对特征进行增强。为验证所提算法的检测性能,分别以网络大小为Tiny、S、M的YOLOX为基准,在PASCAL VOC和KITTI数据集上进行测试。实验结果表明:所提算法在PASCAL VOC数据集上的检测精度分别达到80.0%、82.6%、85.8%,相比基准算法YOLOX提升了1.5%、1.6%、2.0%;在KITTI数据集上的检测精度分别达到87.7%、89.7%、90.7%,相比基准算法YOLOX提升了1.7%、2.9%、1.3%。所提算法能够优化网络收敛性,提高多尺度特征的表示能力,有效提高检测精度。
Abstract:The bounding box regression loss effect is limited, and the multi-scale feature representation ability is insufficient in the YOLOX algorithm, which leads to inaccurate detection results. To address this issue, an object detection algorithm based on distance shape of generalized intersection over union (DSGIoU) loss and dual branch coordinate attention was proposed. Based on the intersection over union (IoU) loss term, the regression convergence effect of the bounding box was optimized by adding three penalty terms: non-overlapping area, distance from the center, and aspect ratio between the true box and the predicted box. Meanwhile, the feature was encoded in two directions by using average pooling and max pooling to obtain directional perception information and position information, so as to enhance the feature. To demonstrate the detection performance of the proposed algorithm, YOLOX with network sizes of Tiny, S, and M was used as the benchmark to carry out tests on PASCAL VOC and KITTI datasets. The experimental results show that the detection accuracy of the proposed algorithm on the PASCAL VOC dataset reaches 80.0%, 82.6%, and 85.8%, respectively, which is 1.5%, 1.6%, and 2.0% higher than the YOLOX as the benchmark. On the KITTI dataset, the detection accuracy reaches 87.7%, 89.7%, and 90.7%, which is increased by 1.7%, 2.9%, and 1.3%, respectively. The proposed algorithm can optimize the network convergence, improve the representation ability of multi-scale features, and significantly boost the detection accuracy.
-
Key words:
- object detection /
- loss function /
- bounding box regression /
- coordinate attention /
- YOLOX
-
表 1 PASCAL VOC数据集测试结果
Table 1. Test results on PASCAL VOC dataset
算法 模型大小/Mbit mAP/% 检测速度/(帧·s−1) YOLOX-Tiny 5.04 78.5 64.1 Ours-Tiny 5.09 80.0 35.6 YOLOX-S 8.95 81.0 60.5 Ours-S 9.02 82.6 31.5 YOLOX-M 25.3 83.8 45.8 Ours-M 25.6 85.8 19.2  下载: 导出CSV
下载: 导出CSV
表 2 各类算法在PASCAL VOC数据集上的测试结果
Table 2. Test results of various algorithms on PASCAL VOC dataset
算法 主干网络 图像分辨率 mAP/% 检测速度/
(帧·s−1)YOLOv3[7] DarkNet-53 544×544 79.3 26.0 YOLOv4[8] CSPDarkNet-53 448×448 82.0 43.0 SSD[9] VGG-16 512×512 76.8 19.0 DSSD[10] ResNet-101 513×513 81.5 5.5 Faster R-CNN[13] ResNet-101 1000 ×60076.4 2.4 YOLOX-S[26] Modified CSPv5 640×640 81.0 60.5 R-FCN[29] ResNet-101 1000 ×60079.5 5.8 FCOS[30] ResNet-50 800×800 80.2 16.0 CenterNet[31] ResNet-101 512×512 78.7 30.0 CenterNet-DHRNet[32] DHRNet 512×512 81.9 18.0 CenterNet-Res101-
FcaNet[33]Res101-FcaNet 512×512 82.3 27.6 YOLOv7[34] 640×640 82.3 45.0 Ours-S Modified CSPv5 640×640 82.6 31.5
下载: 导出CSV
表 3 各类算法在PASCAL VOC数据集上每个类别的平均精度比较
Table 3. AP comparison of various algorithms for each category on PASCAL VOC dataset
% 类别 Ours-S YOLOX-S[26] Faster R-CNN[13] R-FCN[29] SSD[9] RetinaNet[35] CenterNet-DHRNet[32] aero 89.5 86.5 79.8 82.5 82.4 89.4 86.2 bike 90.4 89.5 80.7 83.7 84.7 86.6 88.6 bird 79.2 77.3 76.2 80.3 78.4 79.8 82.4 boat 74.6 73.9 68.3 69.0 73.8 67.8 72.8 bottle 73.5 71.6 55.9 69.2 53.2 70.8 73.4 bus 88.7 88.2 85.1 87.5 86.2 85.4 86.6 car 93.1 91.9 85.3 88.4 87.5 90.5 88.8 cat 87.5 87.4 89.8 88.4 86.0 88.8 87.3 chair 69.0 66.7 56.7 65.4 57.8 61.0 68.1 cow 83.4 82.0 87.8 87.3 83.1 75.6 86.9 table 80.9 79.6 69.4 72.1 70.2 65.8 78.4 dog 84.6 82.9 88.3 87.9 84.9 84.1 84.6 horse 89.3 89.1 88.9 88.3 85.2 84.4 88.5 mbike 87.6 86.7 80.9 81.3 83.9 84.9 86.5 person 89.1 88.7 78.4 79.8 79.7 85.7 86.0 plant 57.7 53.9 41.7 54.1 50.3 52.1 59.0 sheep 79.1 78.3 78.6 79.6 77.9 77.7 85.3 sofa 82.8 79.8 79.8 78.8 73.9 74.2 81.5 train 88.5 86.3 85.3 87.1 82.5 85.8 87.5 tv 83.1 79.0 72 79.5 75.3 79.6 80.2
下载: 导出CSV
表 4 KITTI数据集测试结果
Table 4. Test results on KITTI dataset
算法 模型大小/Mbit mAP/% 检测速度/(帧·s−1) YOLOX-Tiny 5.04 86.0 64.1 Ours-Tiny 5.09 87.7 35.6 YOLOX-S 8.95 86.8 60.5 Ours-S 9.02 89.7 31.5 YOLOX-M 25.3 89.4 45.8 Ours-M 25.6 90.7 19.2
下载: 导出CSV
表 5 各类算法在KITTI数据集上的测试结果
Table 5. Test results of various algorithms on KITTI dataset
算法 主干网络 图像分辨率 mAP/% 检测速度/
(帧·s−1)YOLOv3[7] DarkNet-53 544×544 84.9 29.0 SSD[9] VGG-16 512×512 61.2 28.9 YOLOX-S[26] Modified CSPv5 640×640 86.8 60.5 CenterNet[31] 512×512 86.1 30.0 CenterNet-DHRNet[32] DHRNet 512×512 87.1 18.0 AM-YOLOv3[36] DarkNet-53 544×544 86.0 26.0 Ours-S Modified CSPv5 640×640 89.7 31.5
下载: 导出CSV
表 6 各类算法在KITTI数据集上每个类别的平均精度比较
Table 6. AP comparison of various algorithms for each category on KITTI dataset
%
下载: 导出CSV
表 7 在PASCAL VOC数据集上的消融实验
Table 7. Ablation experiment on PASCAL VOC dataset
YOLOX-S DSGIoU 损失 DBCA mAP/% √ 81.0 √ √ 82.0 √ √ 82.0 √ √ √ 82.6
下载: 导出CSV
表 8 不同边界框回归损失的测试结果
Table 8. Test results of different bounding box regression losses
方法 mAP/% 检测速度/(帧·s−1) IoU损失 81.0 60.5 GIoU损失 81.4 63.0 DIoU损失 81.3 63.4 CIoU损失 81.4 64.5 DSGIoU损失 82.0 63.5
下载: 导出CSV
-
[1] LIU L, OUYANG W L, WANG X G, et al. Deep learning for generic object detection: A survey[J]. International Journal of Computer Vision, 2020, 128(2): 261-318. doi: 10.1007/s11263-019-01247-4 [2] DENG L J, GONG Y X, LIN Y, et al. Detecting multi-oriented text with corner-based region proposals[J]. Neurocomputing, 2019, 334: 134-142. doi: 10.1016/j.neucom.2019.01.013 [3] ZABLOCKI É, BEN-YOUNES H, PÉREZ P, et al. Explainability of deep vision-based autonomous driving systems: review and challenges[J]. International Journal of Computer Vision, 2022, 130(10): 2425-2452. doi: 10.1007/s11263-022-01657-x [4] LIU Y H, ZHANG F D, ZHANG Q Y, et al. Cross-view correspondence reasoning based on bipartite graph convolutional network for mammogram mass detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 3811-3821. [5] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 779-788. [6] REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 6517-6525. [7] REDMON J, FARHADI A. YOLOv3: an incremental improvement[EB/OL]. (2018-04-08)[2023-04-17]. https://arxiv.org/abs/1804.02767. [8] BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. (2020-04-23)[2023-04-17]. https://arxiv.org/abs/2004.10934. [9] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]//Proceedings of the 14th European Conference on Computer Vision. Berlin: Springer, 2016: 21-37. [10] FU C Y, LIU W, RANGA A, et al. DSSD: deconvolutional single shot detector[EB/OL]. (2017-01-23)[2023-04-17]. https://arxiv.org/abs/1701.06659. [11] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2014: 580-587. [12] GIRSHICK R. Fast R-CNN[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2015: 1440-1448. [13] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149. doi: 10.1109/TPAMI.2016.2577031 [14] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: ACM, 2017: 6000-6010. [15] CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers[C]//Proceedings of the 16th European Conference on Computer Vision. Berlin: Springer, 2020: 213-229. [16] DAI Z G, CAI B L, LIN Y G, et al. UP-DETR: unsupervised pre-training for object detection with Transformers[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 1601-1610. [17] YU J H, JIANG Y N, WANG Z Y, et al. UnitBox: an advanced object detection network[C]//Proceedings of the 24th ACM International Conference on Multimedia. New York: ACM, 2016: 516-520. [18] REZATOFIGHI H, TSOI N, GWAK J, et al. Generalized intersection over union: a metric and a loss for bounding box regression[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 658-666. [19] ZHENG Z H, WANG P, LIU W, et al. Distance-IoU loss: faster and better learning for bounding box regression[C]//Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2020: 12993-13000. [20] GUO M H, XU T X, LIU J J, et al. Attention mechanisms in computer vision: a survey[J]. Computational Visual Media, 2022, 8(3): 331-368. doi: 10.1007/s41095-022-0271-y [21] 康涛, 段蓉凯, 杨磊, 等. 融合多注意力机制的卷积神经网络轴承故障诊断方法[J]. 西安交通大学学报, 2022, 56(12): 68-77.KANG T, DUAN R K, YANG L, et al. Bearing fault diagnosis using convolutional neural network based on a multi-attention mechanism[J]. Journal of Xi’an Jiaotong University, 2022, 56(12): 68-77(in Chinese). [22] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 7132-7141. [23] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]//Proceedings of the 15th European Conference on Computer Vision. Berlin: Springer, 2018: 3-19. [24] RUAN D S, WANG D Y, ZHENG Y, et al. Gaussian context Transformer[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 15124-15133. [25] HOU Q B, ZHOU D Q, FENG J S. Coordinate attention for efficient mobile network design[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 13708-13717. [26] GE Z, LIU S T, WANG F, et al. YOLOX: exceeding YOLO series in 2021[EB/OL]. (2021-08-06)[2023-04-17]. https://arxiv.org/abs/2107.08430. [27] BOUREAU Y L, PONCE J, LECUN Y. A theoretical analysis of feature pooling in visual recognition[C]//Proceedings of the 27th International Conference on Machine Learning. New York: ACM, 2010: 111-118. [28] BOUREAU Y L, BACH F, LECUN Y, et al. Learning mid-level features for recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2010: 2559-2566. [29] DAI J F, LI Y, HE K M, et al. R-FCN: object detection via region-based fully convolutional networks[C]//Proceedings of the 30th International Conference on Neural Information Processing Systems. New York: ACM, 2016: 379-387. [30] TIAN Z, SHEN C H, CHEN H, et al. FCOS: fully convolutional one-stage object detection[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2019: 9626-9635. [31] ZHOU X Y, WANG D Q, KRÄHENBÜHL P. Objects as points[EB/OL]. (2019-04-25)[2023-04-17]. https://arxiv.org/abs/1904.07850. [32] 王新, 李喆, 张宏立. 一种迭代聚合的高分辨率网络Anchor-free目标检测方法[J]. 北京航空航天大学学报, 2021, 47(12): 2533-2541.WANG X, LI Z, ZHANG H L. High-resolution network Anchor-free object detection method based on iterative aggregation[J]. Journal of Beijing University of Aeronautics and Astronautics, 2021, 47(12): 2533-2541(in Chinese). [33] 侯志强, 郭浩, 马素刚, 等. 基于双分支特征融合的无锚框目标检测算法[J]. 电子与信息学报, 2022, 44(6): 2175-2183.HOU Z Q, GUO H, MA S G, et al. Anchor-free object detection algorithm based on double branch feature fusion[J]. Journal of Electronics & Information Technology, 2022, 44(6): 2175-2183(in Chinese). [34] WANG C Y, BOCHKOVSKIY A, LIAO H Y M. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[EB/OL]. (2022-07-06)[2023-04-17]. https://arxiv.org/abs/2207.02696. [35] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 42(2): 318-327. [36] 鞠默然, 罗江宁, 王仲博, 等. 融合注意力机制的多尺度目标检测算法[J]. 光学学报, 2020, 40(13): 132-140.JU M R, LUO J N, WANG Z B, et al. Multi-scale target detection algorithm based on attention mechanism[J]. Acta Optica Sinica, 2020, 40(13): 132-140(in Chinese). -

 下载:
下载:




 点击查看大图
点击查看大图
计量
- 文章访问数: 179
- HTML全文浏览量: 59
- PDF下载量: 3
- 被引次数: 0
