



-
摘要:
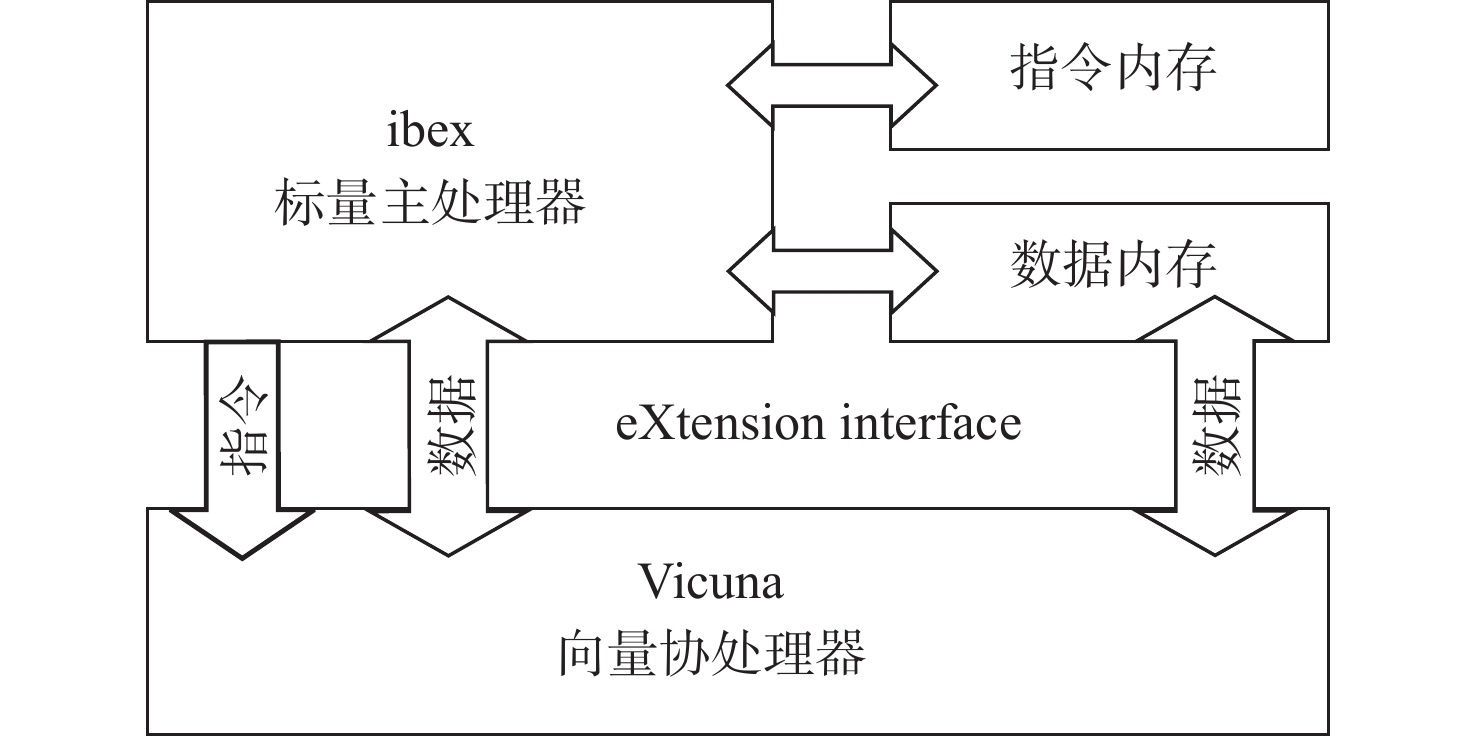
作为卷积神经网络(CNN)计算的前序步骤,图像预处理不可或缺又非常耗时。为加速图像预处理,提出一种基于RISC-V向量扩展的加速方法,对灰度化、标准化、高斯滤波等11种图像预处理算法进行加速。从计算模式上将11种图像预处理算法归为4类,并基于RISC-V向量扩展对各类图像预处理算法设计了加速方案;为进一步提高性能,新增6条自定义的向量指令,并通过修改编译器和设计硬件模块实现了6条自定义向量指令;使用现场可编程门阵列(FPGA)进行测试,并分析了向量处理器配置对性能和资源消耗的影响。结果显示:所提方法相比标量处理器实现了3.13~9.97倍的加速效果,可有效解决图像预处理在深度学习过程中的性能瓶颈问题。
Abstract:As the pre-order step of convolutional neural network (CNN) computing, image preprocessing is indispensable but time-consuming. To accelerate image preprocessing, a method based on RISC-V vector extension was proposed to accelerate eleven image preprocessing algorithms such as gray scale processing, standardization, and Gaussian filtering. Firstly, eleven image preprocessing algorithms were classified into four categories according to the computing mode, and acceleration schemes for the preprocessing algorithms were designed based on RISC-V vector extension. In order to further improve the performance, six customized vector instructions were added. The customized instructions were implemented by modifying the compiler and designing the hardware module. Finally, a field programmable gate array (FPGA) was used for testing, and the impact of vector processor configuration on performance and resource consumption was analyzed. The results showed that the proposed method achieves 3.13–9.97 times speedup compared with scalar processors, which effectively solves the performance bottleneck problem of image preprocessing in deep learning.
-
Key words:
- convolutional neural network /
- preprocessing /
- RISC-V /
- vector extension /
- algorithm acceleration
-

图 8 不同向量寄存器长度配置下的灰度化周期数
Figure 8. Cycles of grayscale processing under different vector register length configurations

图 9 不同向量处理单元位宽配置下的灰度化周期数
Figure 9. Cycles of grayscale processing under different vector processing pipe width configurations
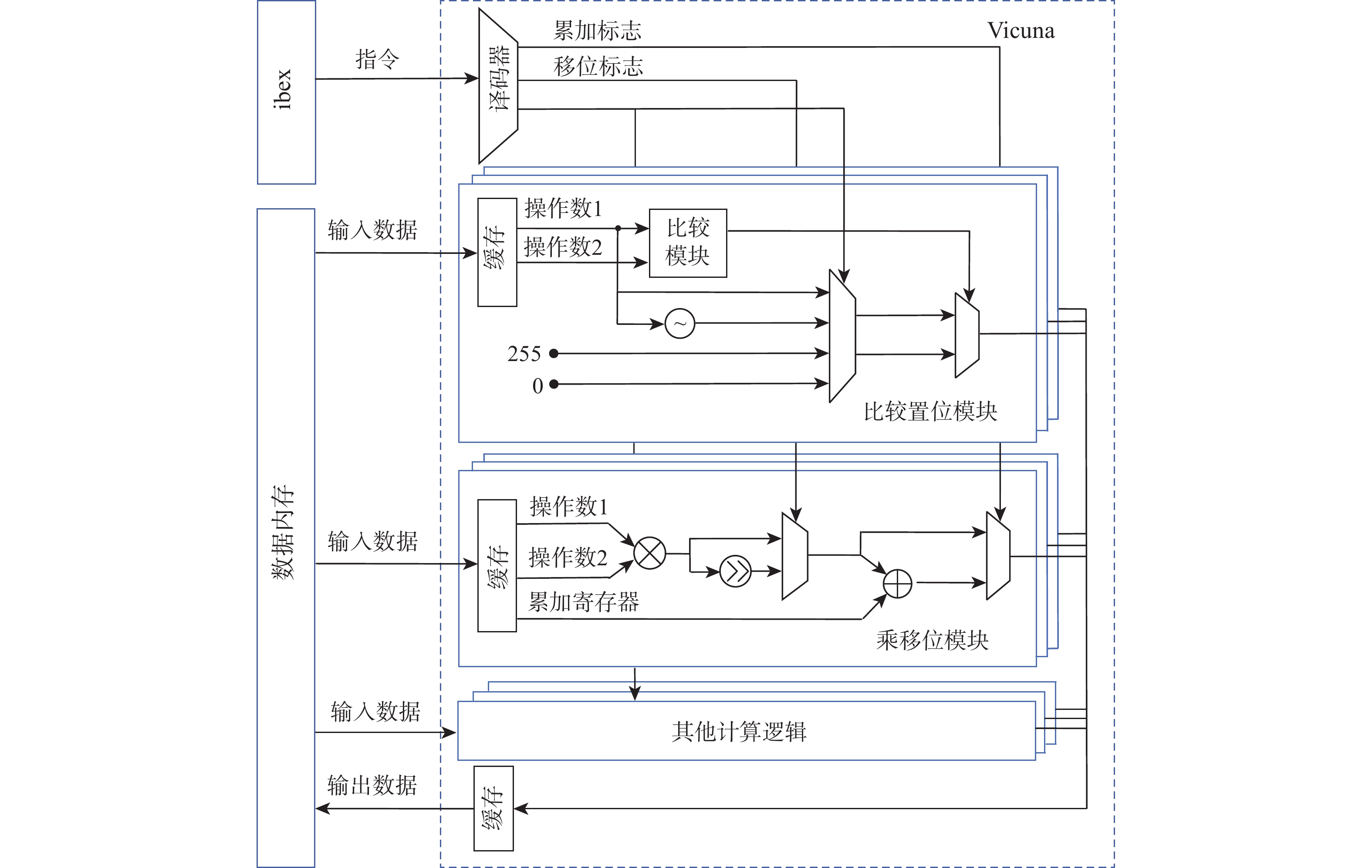
表 1 自定义向量指令功能
Table 1. Function of customized vector instructions
指令 功能 vset255 vd = vs1 >rs2 ? 255: vs1 vset0 vd = vs1 >rs2 ?vs1:0 vabs vd = vs1 > rs2 ? vs1: −vs1 vcmpset vd = vs1 > rs2 ?255: 0 vwmsau vd = vd + (vs1·rs2 >> 8) vmuls vd = vs1·rs2 >>8  下载: 导出CSV
下载: 导出CSV
表 2 不同向量寄存器长度配置下资源消耗及功耗
Table 2. Resource and power consumption under different vector register length configurations
向量寄存器长度/bit LUT FF BRAM DSP 功耗/W 64 9880 5976 64 7 0.336 128 10373 6964 64 7 0.346 256 11312 8716 64 7 0.353 512 13262 12168 64 7 0.373 1024 17374 19079 64 7 0.424 2048 41836 33068 64 7 0.533
下载: 导出CSV
表 3 不同向量处理单元位宽配置下资源消耗及功耗
Table 3. Resource and power consumption under different vector processing pipe width configurations
向量处理单元位宽/bit LUT FF BRAM DSP 功耗/W 32 41386 33068 64 7 0.533 64 42693 33642 64 11 0.539 128 44133 34772 64 19 0.545 256 47470 37058 64 35 0.577 512 52061 41584 64 67 0.607 1024 81279 48705 64 131 0.738
下载: 导出CSV
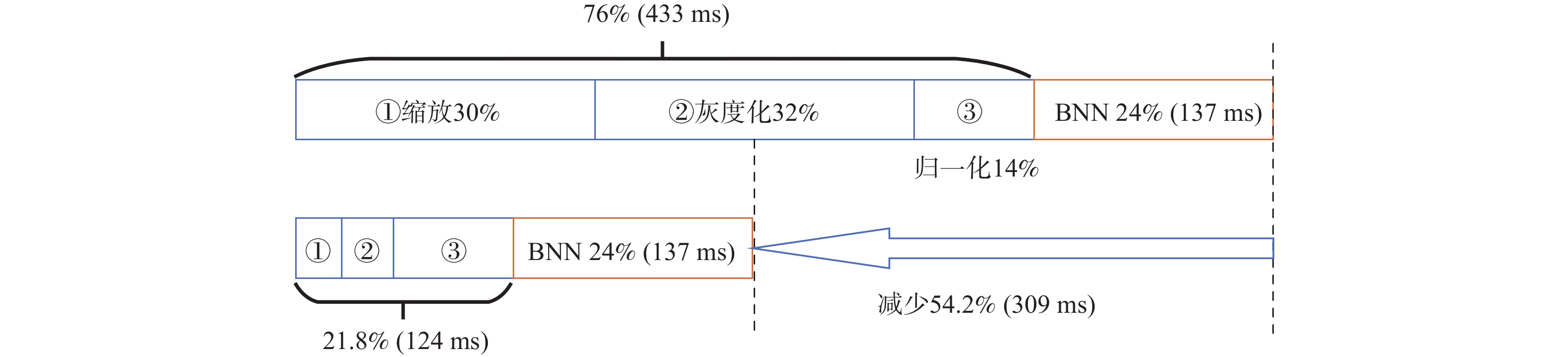
表 4 像素位置变化类算法加速效果
Table 4. Acceleration results of pixel location change algorithms
算法 标量基准周期数 RVV周期数 加速倍数 旋转/镜像 46728 4791 9.75 平移 47439 5679 8.35 缩放 40681 5868 6.93
下载: 导出CSV
表 5 像素数值变化类算法加速效果
Table 5. Acceleration results of pixel value change algorithms
算法 标量基准
周期数标准RVV
周期数标准RVV
加速倍数自定义RVV
周期数自定义RVV
加速倍数灰度化 60488 10786 5.61 8651 6.99 二值化 42576 42576 1.00 4272 9.97 亮度调整 116627 80730 1.44 17422 6.69
下载: 导出CSV
表 6 求全局平均值类算法加速效果
Table 6. Acceleration results of global average computation algorithms
算法 标量基准周期数 RVV周期数 加速倍数 标准化 65620 8724 7.52
下载: 导出CSV
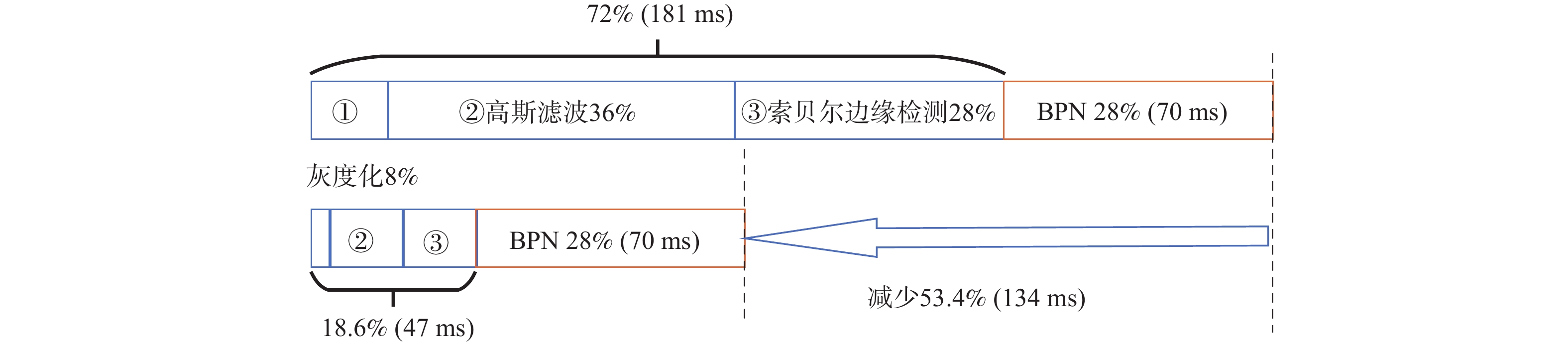
表 7 卷积类算法加速效果
Table 7. Acceleration results of convolution algorithms
算法 标量基准
周期数标准RVV
周期数标准RVV
加速倍数自定义RVV
周期数自定义RVV
加速倍数高斯滤波 268604 66178 4.06 63037 4.26 拉普拉斯滤波 214456 105235 2.04 57650 3.72 索贝尔边缘检测 214783 197202 1.09 68542 3.13
下载: 导出CSV
表 8 资源消耗及功耗
Table 8. Resource and power consumption
硬件架构 LUT FF BRAM DSP 功耗/W ibex+CNN 310840 279836 957 2161 11.65 ibex+Vicuna+CNN 349618 311699 1005 2168 11.88 ibex+自定义Vicuna+CNN 349835 311964 1005 2168 11.88
下载: 导出CSV
-
[1] PAL K K, SUDEEP K S. Preprocessing for image classification by convolutional neural networks[C]//Proceedings of the IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology. Piscataway: IEEE Press, 2016: 1778-1781. [2] ŞABAN Ö, AKDEMIR B. Effects of histopathological image pre-processing on convolutional neural networks[J]. Procedia Computer Science, 2018, 132: 396-403. doi: 10.1016/j.procs.2018.05.166 [3] PITALOKA D A, WULANDARI A, BASARUDDIN T, et al. Enhancing CNN with preprocessing stage in automatic emotion recognition[J]. Procedia Computer Science, 2017, 116: 523-529. doi: 10.1016/j.procs.2017.10.038 [4] TABIK S, PERALTA D, HERRERA-POYATOS A, et al. A snapshot of image pre-processing for convolutional neural networks: case study of MNIST[J]. International Journal of Computational Intelligence Systems, 2017, 10(1): 555-568. doi: 10.2991/ijcis.2017.10.1.38 [5] DU C Y, TSAI C F, CHEN W C, et al. A 28 nm 11.2 TOPS/W hardware-utilization-aware neural-network accelerator with dynamic dataflow[C]//Proceedings of the IEEE International Solid-State Circuits Conference. Piscataway: IEEE Press, 2023: 1-3. [6] KELLER B, VENKATESAN R, DAI S, et al. A 95.6-TOPS/W deep learning inference accelerator with per-vector scaled 4-bit quantization in 5 nm[J]. IEEE Journal of Solid-State Circuits, 2023, 58(4): 1129-1141. doi: 10.1109/JSSC.2023.3234893 [7] KARNIK T, KURIAN D, ASERON P, et al. A cm-scale self-powered intelligent and secure IoT edge mote featuring an ultra-low-power SoC in 14 nm tri-gate CMOS[C]//Proceedings of the IEEE International Solid-State Circuits Conference. Piscataway: IEEE Press, 2018: 46-48. [8] NARAYANAN D, SANTHANAM K, PHANISHAYEE A, et al. Accelerating deep learning workloads through efficient multi-model execution[C]//Proceedings of the NeurIPS Workshop on Systems for Machine Learning. [S. l. ]: NeurIPS, 2018: 20-27. [9] JIA T Y, JU Y H, JOSEPH R, et al. NCPU: an embedded neural CPU architecture on resource-constrained low power devices for real-time end-to-end performance[C]//Proceedings of the 53rd Annual IEEE/ACM International Symposium on Microarchitecture. Piscataway: IEEE Press, 2020: 1097-1109. [10] NVIDIA. NVIDIA data loading library (DALI) [EB/OL]. [2023-04-01]. https://github.com/NVIDIA/DALI. [11] MA N. A SoC-based acceleration method for UAV runway detection image pre-processing algorithm[C]//Proceedings of the 25th International Conference on Automation and Computing. Piscataway: IEEE Press, 2019: 1-6. [12] KUO Y M, GARCÍA-HERRERO F, RUANO O, et al. RISC-V Galois field ISA extension for non-binary error-correction codes and classical and post-quantum cryptography[J]. IEEE Transactions on Computers, 2023, 72(3): 682-692. [13] RAZILOV V, MATÚŠ E, FETTWEIS G. Communications signal processing using RISC-V vector extension[C]//Proceedings of the International Wireless Communications and Mobile Computing. Piscataway: IEEE Press, 2022: 690-695. [14] CAVALCANTE M, SCHUIKI F, ZARUBA F, et al. Ara: a 1-GHz scalable and energy-efficient RISC-V vector processor with multiprecision floating-point support in 22-nm FD-SOI[J]. IEEE Transactions on Very Large Scale Integration Systems, 2020, 28(2): 530-543. doi: 10.1109/TVLSI.2019.2950087 [15] 刘强, 李一可. 基于指令扩展的RISC-V可配置故障注入检测方法[J/OL]. 北京航空航天大学学报, 2023(2023-03-10)[2023-04-01]. https://bhxb.buaa.edu.cn/bhzk/cn/article/doi/10.13700/j.bh.1001-5965.2022.0995.LIU Q, LI Y K. Configurable fault detection method for RISC-V processors based on instruction extension[J/OL]. Journal of Beijing University of Aeronautics and Astronautics, 2023(2023-03-10)[2023-04-01]. https://bhxb.buaa.edu.cn/bhzk/cn/article/doi/10.13700/j.bh.1001-5965.2022.0995(in Chinese). [16] ASANOVIC K. Vector extension 1.0[EB/OL]. (2021-09-20)[2023-04-01]. https://github.com/riscv/riscv-v-spec/releases/tag/v1.0. [17] PLATZER M, PUSCHNER P. Vicuna: a timing-predictable RISC-V vector coprocessor for scalable parallel computation[C]//Proceedings of the 33rd Euromicro Conference on Real-Time Systems. Porto: [s. n. ], 2021: 1-18. [18] SCHIAVONE P D, CONTI F, ROSSI D, et al. Slow and steady wins the race? A comparison of ultra-low-power RISC-V cores for Internet-of-things applications[C]//Proceedings of the 27th International Symposium on Power and Timing Modeling, Optimization and Simulation. Piscataway: IEEE Press, 2017: 1-8. [19] OpenHW Group. OpenHW group eXtension interface[EB/OL]. [2023-04-01]. https://docs.openhwgroup.org/projects/openhw-group-core-v-xif/en/latest/index.html. [20] ALEX K, VINOD N. The CIFAR-10 dataset[EB/OL]. [2023-04-01]. http://www.cs.toronto.edu/~kriz/cifar.html. [21] YAN S, LIU Z Y, WANG Y, et al. An FPGA-based MobileNet accelerator considering network structure characteristics[C]//Proceedings of the 31st International Conference on Field-Programmable Logic and Applications. Piscataway: IEEE Press, 2021: 17-23. -

 下载:
下载:


 点击查看大图
点击查看大图
计量
- 文章访问数: 273
- HTML全文浏览量: 72
- PDF下载量: 6
- 被引次数: 0
