



-
摘要:
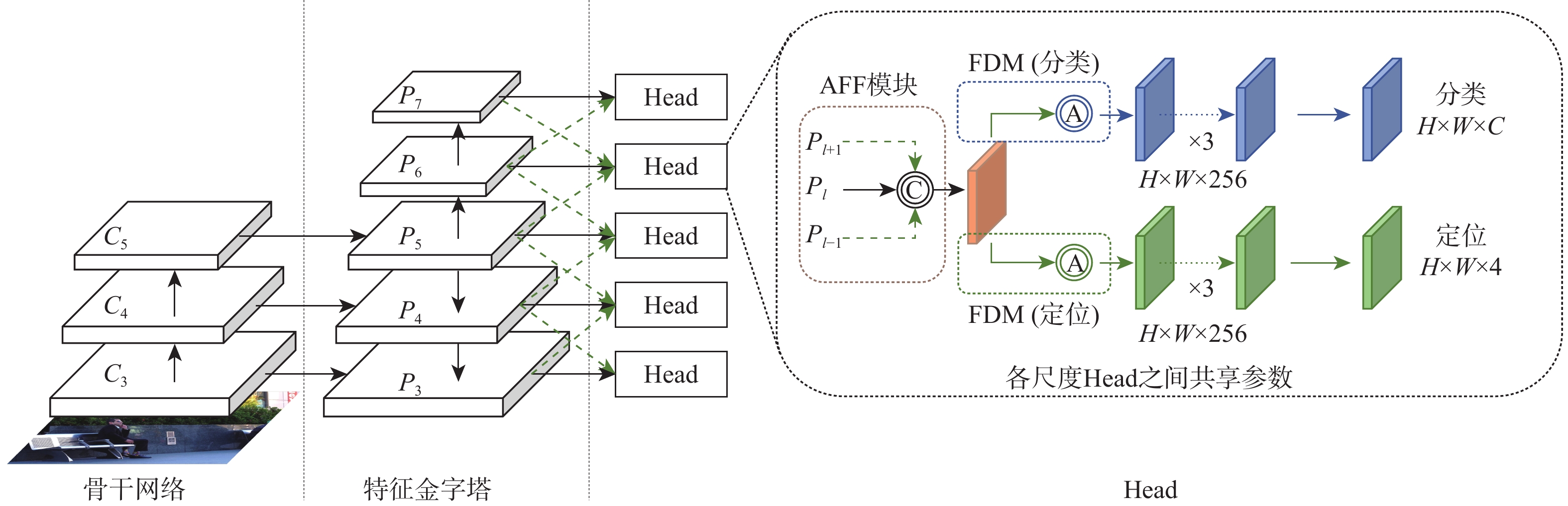
针对目标检测中特征金字塔网络(FPN)造成的大尺度目标检测精度下降及目标检测2个子任务所需语义特征不一致问题,提出一种基于相邻特征融合(AFF)与特征解耦的网络(AFFDN)模型。该模型中的AFF模块通过多对一连接引入更短的梯度回传路径,缓解了大尺度目标梯度消失的问题;AFF模块通过共享参数和偏移量,有效减小了模型参数量,并增强了多尺度特征语义一致性;相比于基于神经架构搜索的FPN(NAS-FPN),AFF参数量更小、性能增益更显著。AFFDN模型中的特征解耦模块(FDM)通过动态感受野和全局注意力,在感受野-通道-空间3个维度上进行细粒度特征解耦,为不同分支生成特有的任务相关特征,进而提高目标检测精度。将AFFDN模型应用到不同的一阶段目标检测模型时,在PASCAL VOC和MS COCO2017数据集上与基线模型相比,检测精度分别提升了至少0.9%和2.3%。
Abstract:In view of reduced large-scale object detection accuracy caused by the feature pyramid network (FPN) in object detection and the inconsistency of the semantic characteristics of the two sub-tasks of object detection, a new model based on adjacent feature fusion (AFF) and feature decoupling network (AFFDN) model was proposed. Firstly, the AFF module in the model introduced a shorter gradient return path by using the many-to-one connection, thereby alleviating the problem of large-scale object gradient disappearance. At the same time, AFF effectively reduced the amount of model parameters and enhanced the semantic consistency of multi-scale features by sharing parameters and offsets. In addition, compared with neural architecture search FPN (NAS-FPN), the parameters of AFF were smaller, and the performance gain was more significant. Secondly, the feature decoupling module (FDM) in the AFFDN used the dynamic receptive field and global attention to decouple fine-grained features in the three dimensions of receptive field, channel, and space, generating unique task-related features for different task branches and thereby improving the accuracy of object detection. Finally, when AFFDN was applied to different one-stage object detection models, the detection accuracy of the baseline model was improved by at least 0.9% and 2.3% on the PASCAL VOC dataset and MS COCO2017 dataset, respectively.
-
Key words:
- object detection /
- multi-scale feature fusion /
- feature decoupling /
- attention /
- deformable convolution
-

图 2 添加FPN后Faster R-CNN的性能变化
Figure 2. Performance change of Faster R-CNN after adding FPN
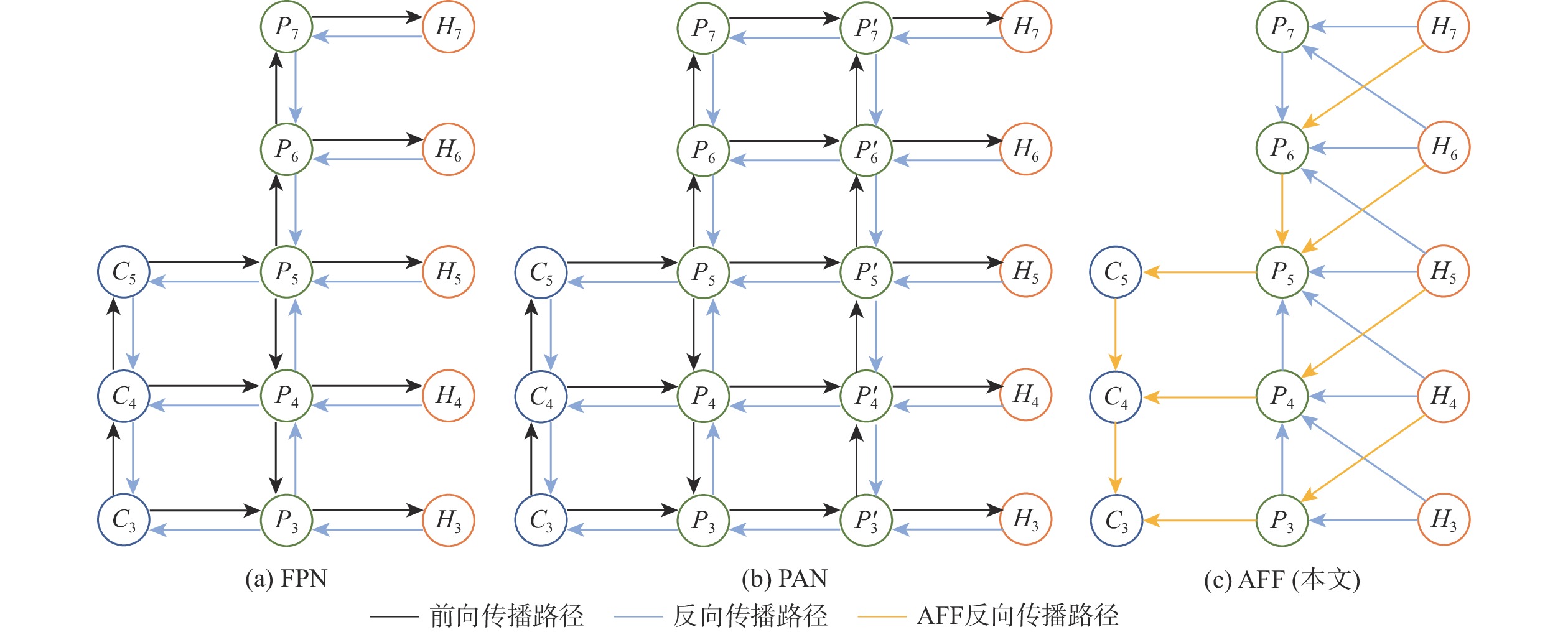
图 3 不同多尺度特征融合方法下梯度信号的传播路径
Figure 3. Propagation paths of gradient signals under different multi-scale feature fusion methods
表 1 不同模型在MS COCO2017 minival数据集上的实验结果对比
Table 1. Comparison of experimental results of different models on MS COCO2017 minival dataset
模型 骨干网络 轮次 mAP/% mAP50/% mAP75/% mAPS/% mAPM/% mAPL/% 参数量/MB 运算量 RetinaNet[4] ResNet-50 12 36.5 55.4 39.1 20.4 40.3 48.1 37.74 239.32×109 RetinaNet[4]/CE-FPN[14] ResNet-50 12 38.0 57.3 40.5 21.2 41.0 47.4 65.02 260.27×109 RetinaNet[4]/DRFPN[19] ResNet-50 12 38.4 58.7 41.6 23.5 42.1 46.7 44.64 410.92×109 Double Head[20] ResNet-50 12 40.1 59.4 43.5 22.9 43.6 52.9 47.12 481.26×109 FCOS[5] ResNet-50 12 38.7 57.4 41.8 22.9 42.5 50.1 32.02 200.50×109 ATSS[26] ResNet-50 12 39.4 57.6 42.8 23.6 42.9 50.3 32.07 205.21×109 ATSS[26]/NAS-FPN[28] ResNet-50 12 40.9 59.2 44.3 24.9 44.3 52.4 38.89 200.54×109 ATSS[26]/AF-Head[29] ResNet-50 12 41.1 59.2 44.5 23.6 44.5 53.7 34.69 210.79×109 ATSS[26]/Dy-Head[24] ResNet-50 12 42.5 60.2 46.2 26.3 46.6 55.3 38.85 112.69×109 PAA[30] ResNet-50 12 40.4 58.4 43.9 22.9 44.3 54.0 32.07 205.30×109 GFL[27] ResNet-50 12 40.2 58.4 43.3 23.3 44.0 52.2 32.22 208.39×109 VarifocalNet[31] ResNet-50 12 41.6 59.5 45.0 24.4 45.1 54.2 32.67 192.86×109 DW [32] ResNet-50 12 42.1 59.9 45.1 24.2 45.3 55.9 32.09 205.73×109 TOOD[22] ResNet-50 12 42.4 59.5 46.1 25.1 45.5 55.5 31.98 184.4×109 ATSS(本文) ResNet-50 12 42.0 60.0 45.7 24.9 45.8 54.5 32.49 186.39×109 GFL(本文) ResNet-50 12 42.5 60.4 46.2 24.6 46.3 55.8 32.64 189.49×109 TOOD(本文) ResNet-50 12 44.7 61.9 48.6 25.6 47.8 58.6 32.40 165.50×109  下载: 导出CSV
下载: 导出CSV
表 2 在PASCAL VOC 2007和PASCAL VOC 2012 数据集上的实验结果
Table 2. Experiment results on PASCAL VOC 2007 and PASCAL VOC 2012 datasets
% 模型 mAP 平均mAP 飞机 自行车 鸟 船 瓶子 公交车 汽车 猫 椅子 牛 桌子 狗 马 摩托车 人 盆栽 羊 沙发 火车 电视 FCOS[5] 79.3 82.1 72.8 62.5 58.0 78.1 83.3 82.7 56.5 71.1 64.0 78.6 78.6 80.1 79.0 43.1 71.4 69.5 77.3 67.7 71.8 ATSS[26] 85.6 82.3 82.4 73.2 70.5 84.5 87.9 88.2 64.9 83.0 70.7 86.7 85.4 83.1 85.1 52.7 81.8 73.6 80.6 79.4 79.1 GFL[27] 84.3 82.7 80.3 69.6 70.6 83.0 87.6 87.5 63.5 85.0 68.9 85.5 84.0 81.9 84.4 52.8 83.4 72.2 84.6 78.0 78.5 TOOD[22] 85.5 84.6 82.7 72.4 71.9 84.7 88.3 88.1 64.4 84.7 71.9 86.6 86.1 84.0 84.9 55.3 81.9 74.5 83.8 80.6 79.8 VarifocalNet[31] 86.2 84.7 82.6 70.6 69.9 86.0 87.6 88.3 63.1 84.3 68.5 85.4 86.7 83.7 84.3 53.8 82.4 71.4 84.7 78.2 79.1 ATSS (本文) 86.6 85.4 82.2 74.8 71.9 87.3 88.1 88.8 65.4 84.9 72.8 86.7 85.6 83.8 85.5 56.3 81.0 72.5 85.2 81.6 80.3 GFL (本文) 87.0 84.1 81.7 74.0 71.3 85.1 87.6 88.6 64.2 85.2 71.2 86.1 85.1 83.5 84.8 54.8 81.4 73.2 85.9 80.8 79.8 TOOD (本文) 87.4 84.1 83.4 73.0 70.6 87.0 88.4 88.3 65.4 88.5 74.5 86.9 87.7 84.2 84.9 55.2 82.8 77.5 86.4 81.0 80.7
下载: 导出CSV
表 4 FDM消融实验结果
Table 4. Ablation experiment results of FDM
通道-空间 感受野 mAP/% mAP50/% mAP75/% × √ 39.4 57.6 42.8 √ × 39.6 57.7 43.0 × √ 40.1 58.5 43.6 √ √ 40.8 58.9 44.5
下载: 导出CSV
表 5 AFF与NAS-FPN的实验结果对比
Table 5. Comparison of experimental results between AFF and NAS-FPN
下载: 导出CSV
表 7 X-Ray目标检测数据集上的消融实验结果
Table 7. Ablation experiment results on X-ray object detection dataset
GFL[27] SwinL 12 epochs Mixup, Flip and SoftNMS AFF(本文) FDM(本文) mAP50/% 参数量/MB 运算量 √ 68.83 32.22 208.39×109 √ √ 83.43 203.6 872.59×109 √ √ √ 87.94 203.6 872.59×109 √ √ √ √ 89.01 203.6 872.59×109 √ √ √ √ √ 89.81 203.9 876.14×109 √ √ √ √ √ √ 90.01 204.0 857.32×109
下载: 导出CSV
-
[1] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems. Piscataway: IEEE Press, 2015: 91-99. [2] LU X, LI B Y, YUE Y X, et al. Grid R-CNN[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 7355-7364. [3] CAI Z W, VASCONCELOS N. Cascade R-CNN: delving into high quality object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 6154-6162. [4] LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 2999-3007. [5] TIAN Z, SHEN C H, CHEN H, et al. FCOS: fully convolutional one-stage object detection[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2019: 9626-9635. [6] GE Z, LIU S T, WANG F, et al. YOLOX: exceeding YOLO series in 2021[EB/OL]. (2021-08-06)[2023-04-01]. https://arxiv.org/abs/2107.08430v2. [7] 李晨瑄, 顾佼佼, 王磊, 等. 多尺度特征融合的Anchor-Free轻量化舰船要害部位检测算法[J]. 北京航空航天大学学报, 2022, 48(10): 2006-2019.LI C X, GU J J, WANG L, et al. Warship’s vital parts detection algorithm based on lightweight Anchor-Free network with multi-scale feature fusion[J]. Journal of Beijing University of Aeronautics and Astronautics, 2022, 48(10): 2006-2019(in Chinese). [8] 王榆锋, 李大海. 改进YOLO框架的血细胞检测算法[J]. 计算机工程与应用, 2022, 58(12): 191-198. doi: 10.3778/j.issn.1002-8331.2110-0224WANG Y F, LI D H. Improved YOLO framework blood cell detection algorithm[J]. Computer Engineering and Applications, 2022, 58(12): 191-198(in Chinese). doi: 10.3778/j.issn.1002-8331.2110-0224 [9] 刘树东, 刘业辉, 孙叶美, 等. 基于倒置残差注意力的无人机航拍图像小目标检测[J]. 北京航空航天大学学报, 2023, 49(3): 514-524.LIU S D, LIU Y H, SUN Y M, et al. Small object detection in UAV aerial images based on inverted residual attention[J]. Journal of Beijing University of Aeronautics and Astronautics, 2023, 49(3): 514-524(in Chinese). [10] LIN T Y, DOLLÁR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 936-944. [11] LIU S, QI L, QIN H F, et al. Path aggregation network for instance segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2018: 8759-8768. [12] TAN M X, PANG R M, LE Q V. EfficientDet: scalable and efficient object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 10778-10787. [13] JIANG Y Q, TAN Z Y, WANG J Y, et al. GiraffeDet: a heavy-neck paradigm for object detection[C]//International Conference on Learning Representations. Washington, D. C. : ICLR, 2022: 1-17. [14] LUO Y H, CAO X, ZHANG J T, et al. CE-FPN: enhancing channel information for object detection[J]. Multimedia Tools and Applications, 2022, 81(21): 30685-30704. doi: 10.1007/s11042-022-11940-1 [15] JIN Z C, YU D D, SONG L C, et al. You should look at all objects[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2022: 332-349. [16] LI R, WANG L B, ZHANG C, et al. A2-FPN for semantic segmentation of fine-resolution remotely sensed images[J]. International Journal of Remote Sensing, 2022, 43(3): 1131-1155. doi: 10.1080/01431161.2022.2030071 [17] LIU S T, HUANG D, WANG Y H. Learning spatial fusion for single-shot object detection[EB/OL]. (2019-11-25)[2023-04-01]. https://arxiv.org/abs/1911.09516v2. [18] LIU Y, HAN J G, ZHANG Q, et al. Deep salient object detection with contextual information guidance[J]. IEEE Transactions on Image Processing, 2019, 29: 360-374. [19] MA J L, CHEN B. Dual refinement feature pyramid networks for object detection[EB/OL]. (2020-12-04)[2023-04-01]. https://arxiv.org/abs/2012.01733v2. [20] WU Y, CHEN Y P, YUAN L, et al. Rethinking classification and localization for object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 10183-10192. [21] SONG G L, LIU Y, WANG X G. Revisiting the sibling head in object detector[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 11560-11569. [22] FENG C J, ZHONG Y J, GAO Y, et al. TOOD: task-aligned one-stage object detection[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE Press, 2021: 3490-3499. [23] CHEN Z H, YANG C, LI Q F, et al. Disentangle your dense object detector[C]//Proceedings of the 29th ACM International Conference on Multimedia. New York: ACM, 2021: 4939-4948. [24] DAI X Y, CHEN Y P, XIAO B, et al. Dynamic head: unifying object detection heads with attentions[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 7369-7378. [25] LIU Y, ZHANG D W, LIU N, et al. Disentangled capsule routing for fast part-object relational saliency[J]. IEEE Transactions on Image Processing, 2022, 31: 6719-6732. [26] ZHANG S F, CHI C, YAO Y Q, et al. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 9756-9765. [27] LI X, WANG W H, WU L J, et al. Generalized focal loss: learning qualified and distributed bounding boxes for dense object detection[J]. Advances in Neural Information Processing Systems, 2020, 33: 21002-21012. [28] GHIASI G, LIN T Y, LE Q V. NAS-FPN: learning scalable feature pyramid architecture for object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 7029-7038. [29] LIU Z T, SHAO M W, SUN Y T, et al. Multi-task feature-aligned head in one-stage object detection[J]. Signal, Image and Video Processing, 2023, 17(4): 1345-1353. doi: 10.1007/s11760-022-02342-9 [30] KIM K, LEE H S. Probabilistic anchor assignment with IoU prediction for object detection[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2020: 355-371. [31] ZHANG H Y, WANG Y, DAYOUB F, et al. VarifocalNet: an IoU-aware dense object detector[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2021: 8510-8519. [32] LI S, HE C H, LI R H, et al. A dual weighting label assignment scheme for object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2022: 9377-9386. [33] BOLYA D, FOLEY S, HAYS J, et al. TIDE: a general toolbox for identifying object detection errors[C]//Proceedings of the European Conference on Computer Vision. Berlin: Springer, 2020: 558-573. -

 下载:
下载:






 点击查看大图
点击查看大图
计量
- 文章访问数: 186
- HTML全文浏览量: 46
- PDF下载量: 4
- 被引次数: 0
