



Enhancing performance through static computing partitioning approach in processing-in-memory systems
-
摘要:
存算一体化(PIM)系统通过引入存内计算单元改变冯·诺依曼结构“存算分离”模式,可有效缓解存储墙问题,但PIM系统与现有软件体系不匹配,性能和能效受程序的计算划分限制,甚至可能出现负优化。针对该问题,提出一种PIM系统中的静态计算划分方法。该方法将PIM系统中程序的执行过程抽象为基于注释调用图(ACG)的表征模型,从而将计算划分问题转化为ACG的最小割问题,并提出一种基于模拟退火的启发式计算划分求解算法。实验结果表明:相较于传统方法,所提方法的计算划分结果可平均提升39%系统性能,降低32%系统能耗。
Abstract:Processing-in-memory (PIM) systems mitigate the von Neumann “memory-wall” bottleneck by integrating in-memory computing units to break the conventional memory-computation separation paradigm. However, PIM architectures are incompatible with mainstream software stacks, their performance and energy efficiency are highly constrained by the computational partitioning of programs, and may even suffer from performance degradation or negative optimization. In this paper, we propose a static computing partitioning approach that deals with this challenge. The key insight of our work is to reframe the computing partitioning as an annotated call graph (ACG) partitioning problem and propose a simulated annealing-based algorithm to find the optimal computing partitions. In comparison to traditional methods, our trials show that our methodology can improve performance by 39% and cut energy use by an average of 32%.
-
Key words:
- processing-in-memory /
- computing partitioning /
- min-cut /
- simulated annealing /
- heterogeneous system
-
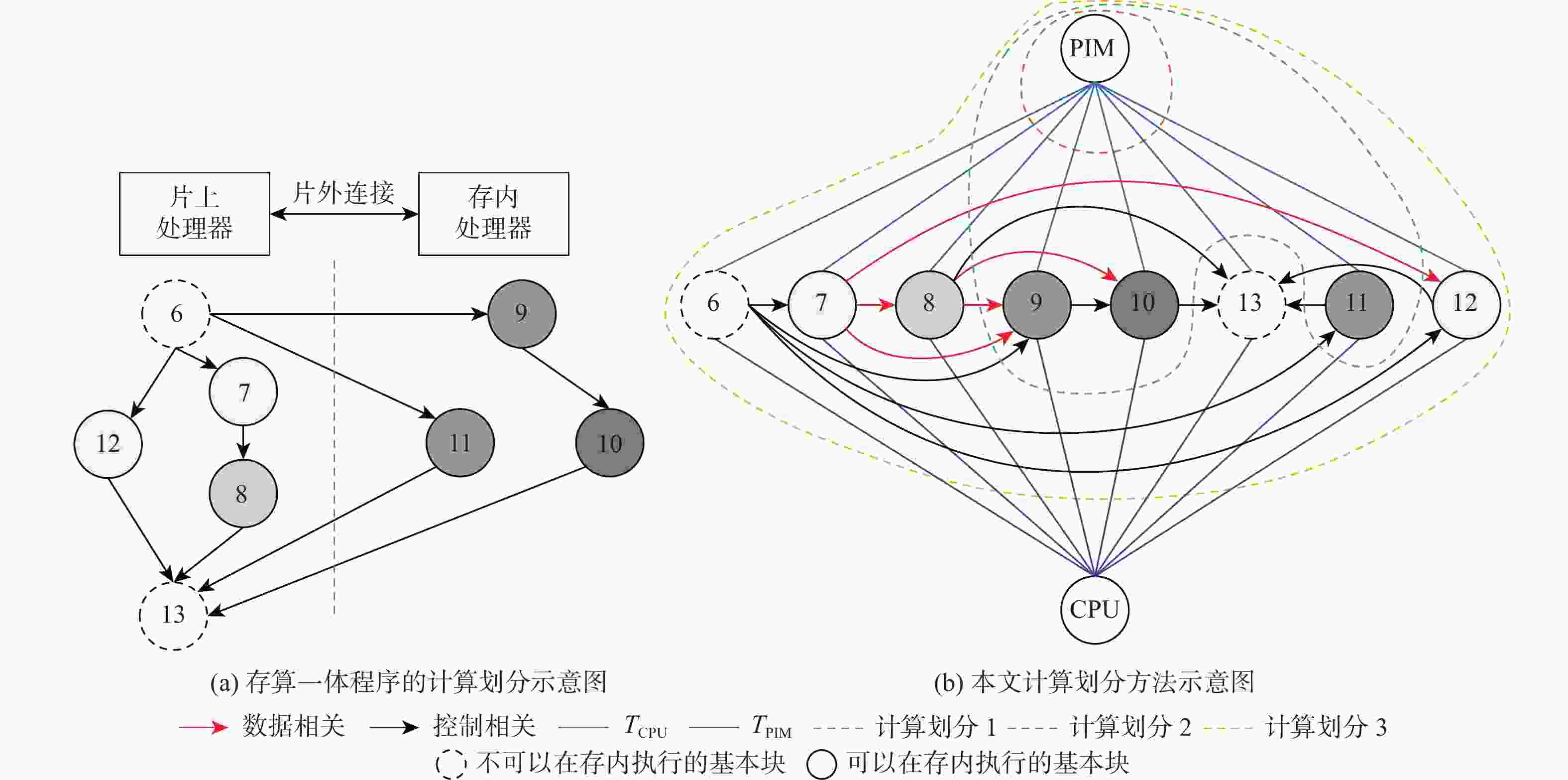
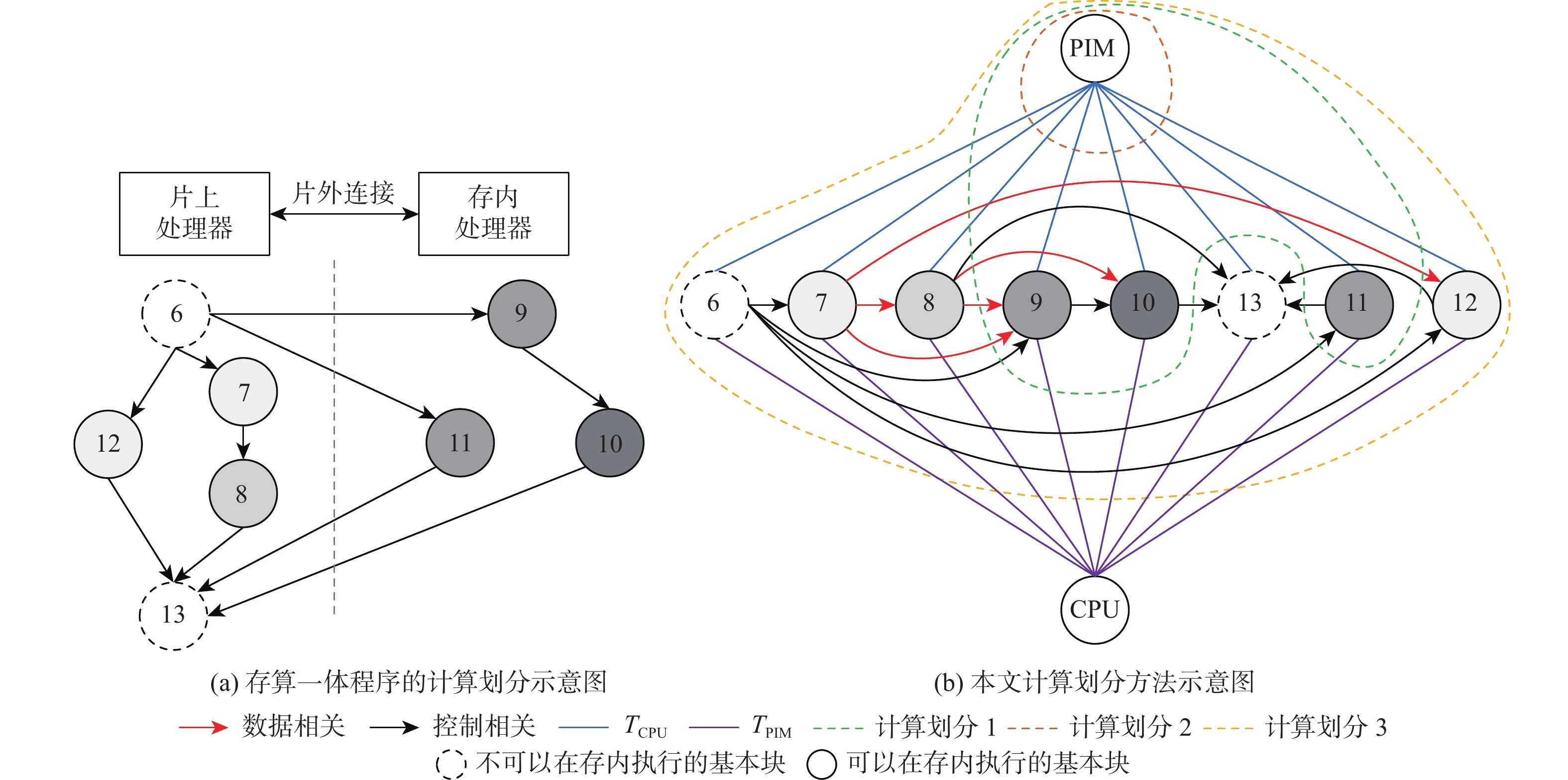
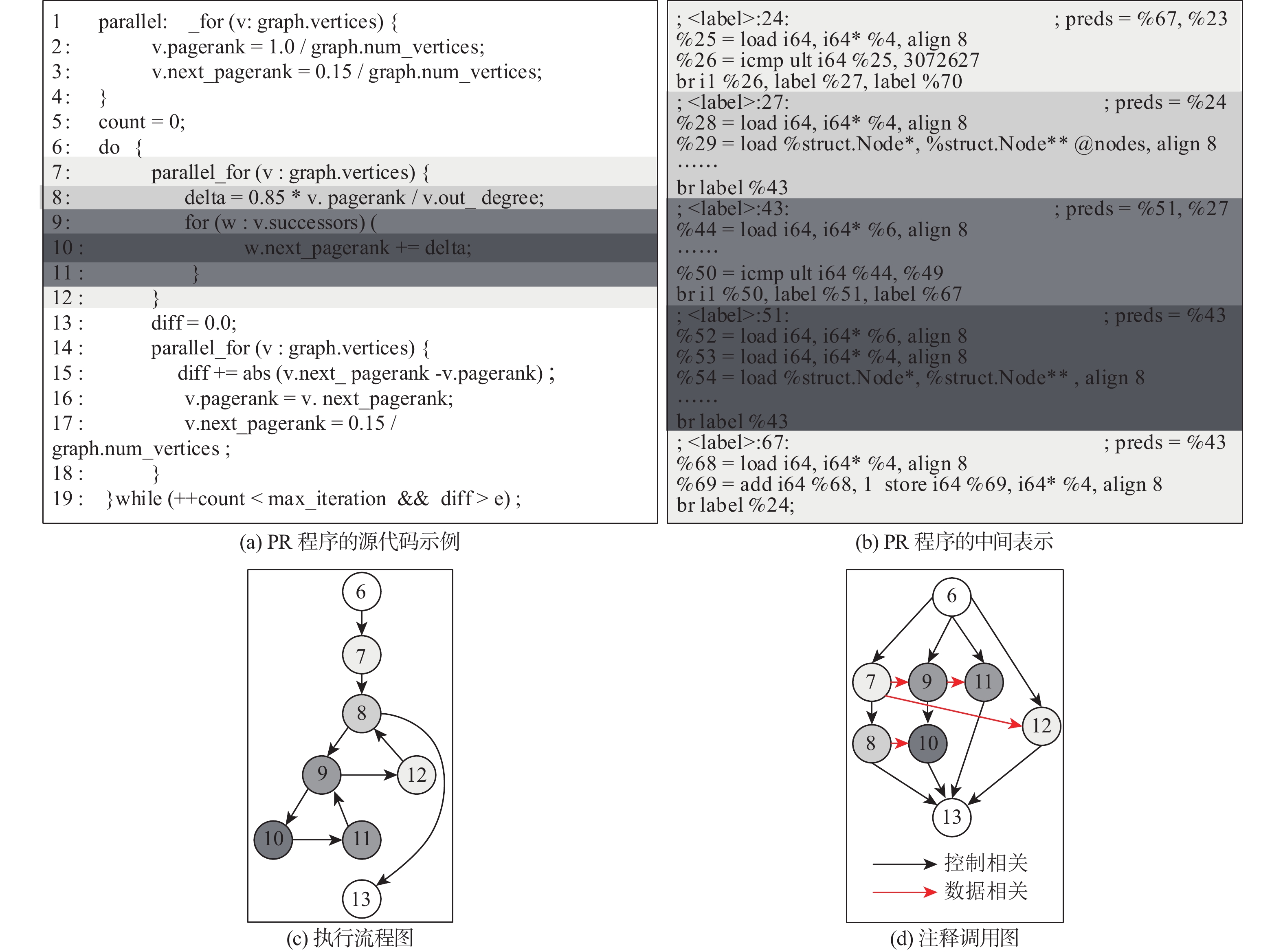
图 2 基于注释调用图的计算划分方法和对应的存算一体程序计算划分示意图
Figure 2. ACG-based computing partitioning approach and corresponding compute-in-memory program computing partitioning diagram
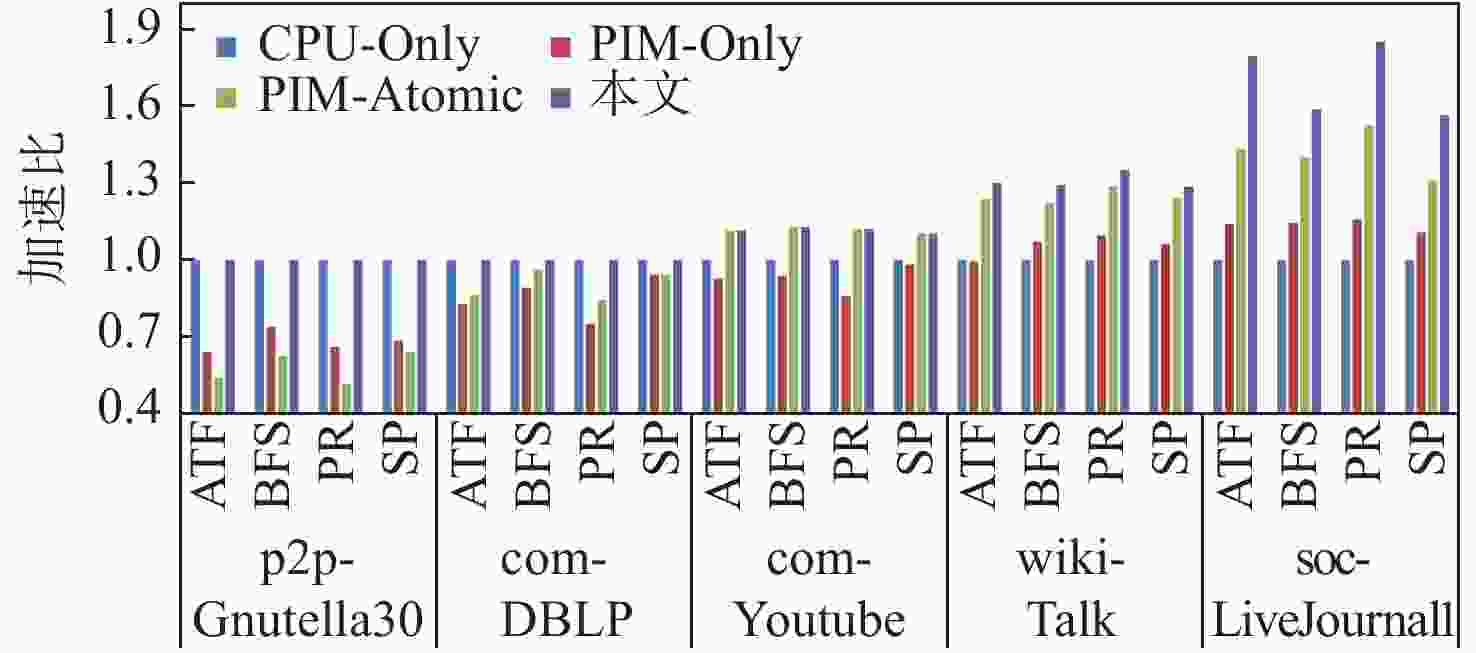
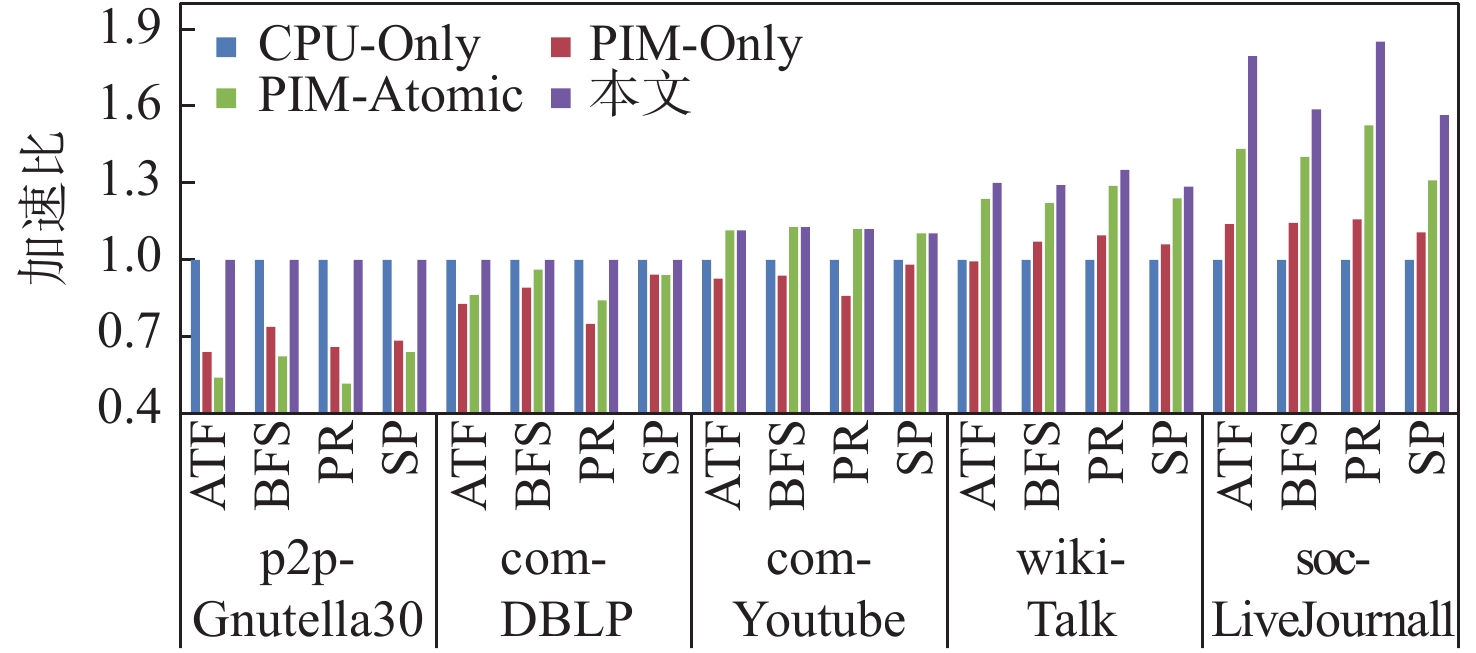
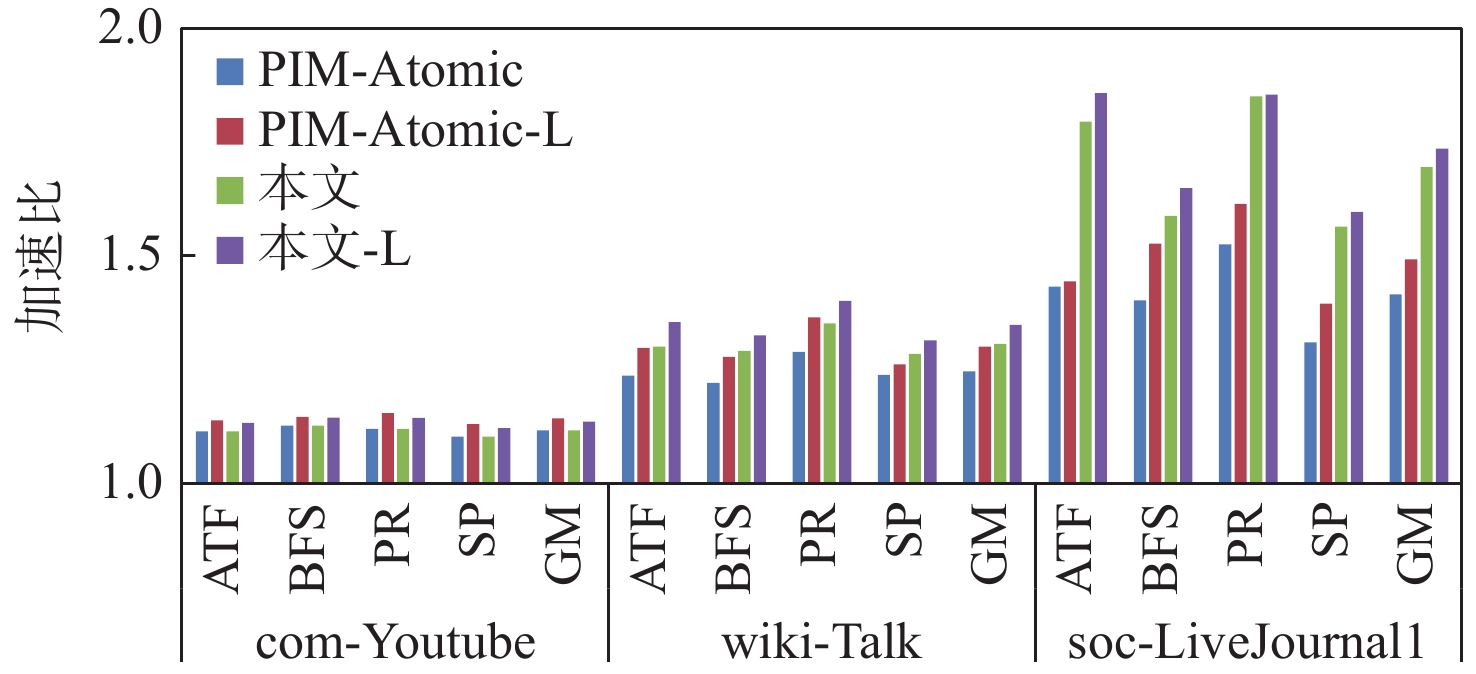
图 3 不同大小数据集和不同计算划分下的性能加速比
Figure 3. Performance acceleration ratio under different dataset sizes and computational partitions
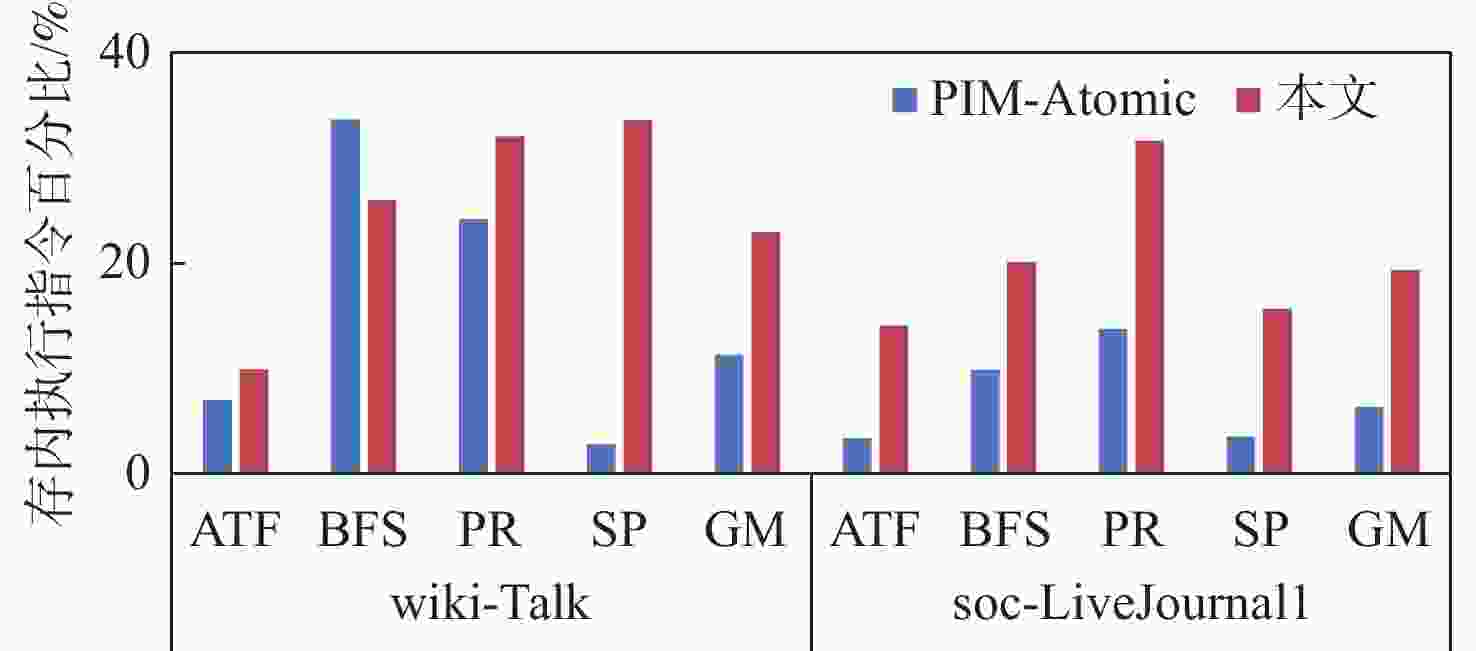
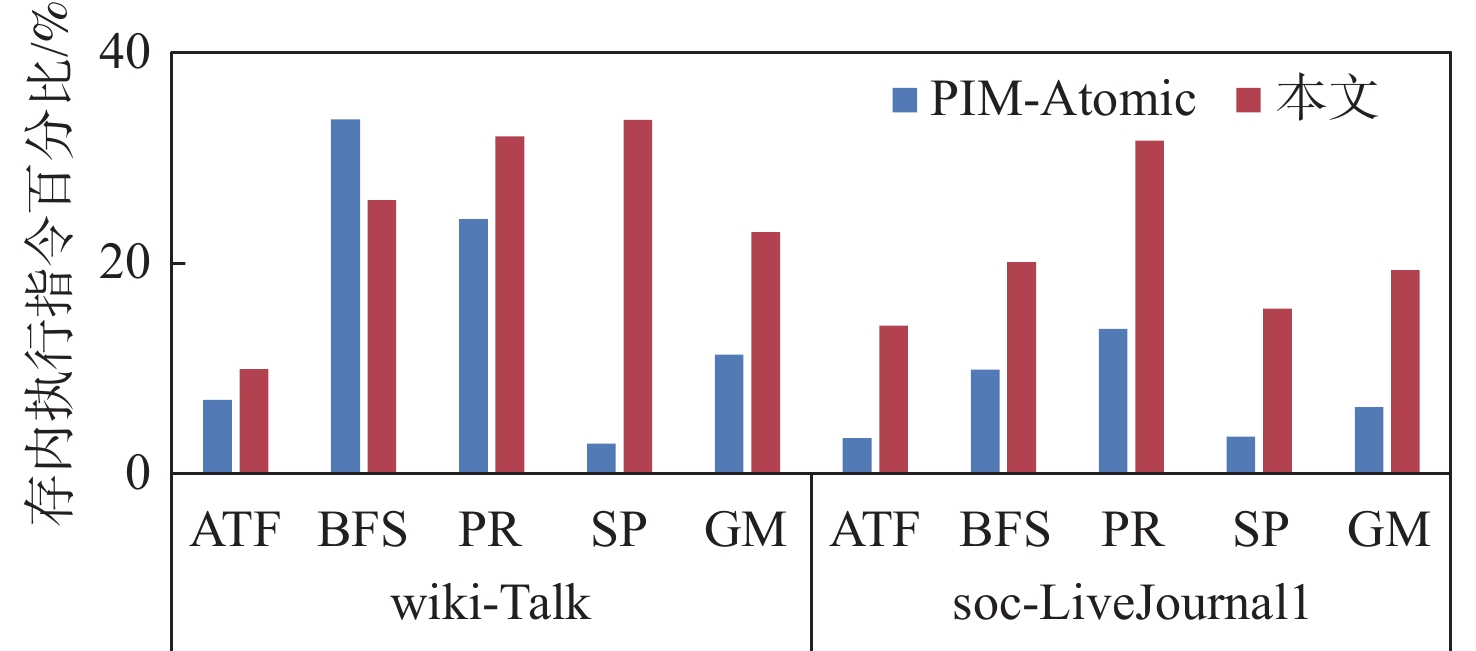
图 4 基准程序在存内执行指令百分比
Figure 4. Percentage of instructions executed in-memory by benchmark programmes
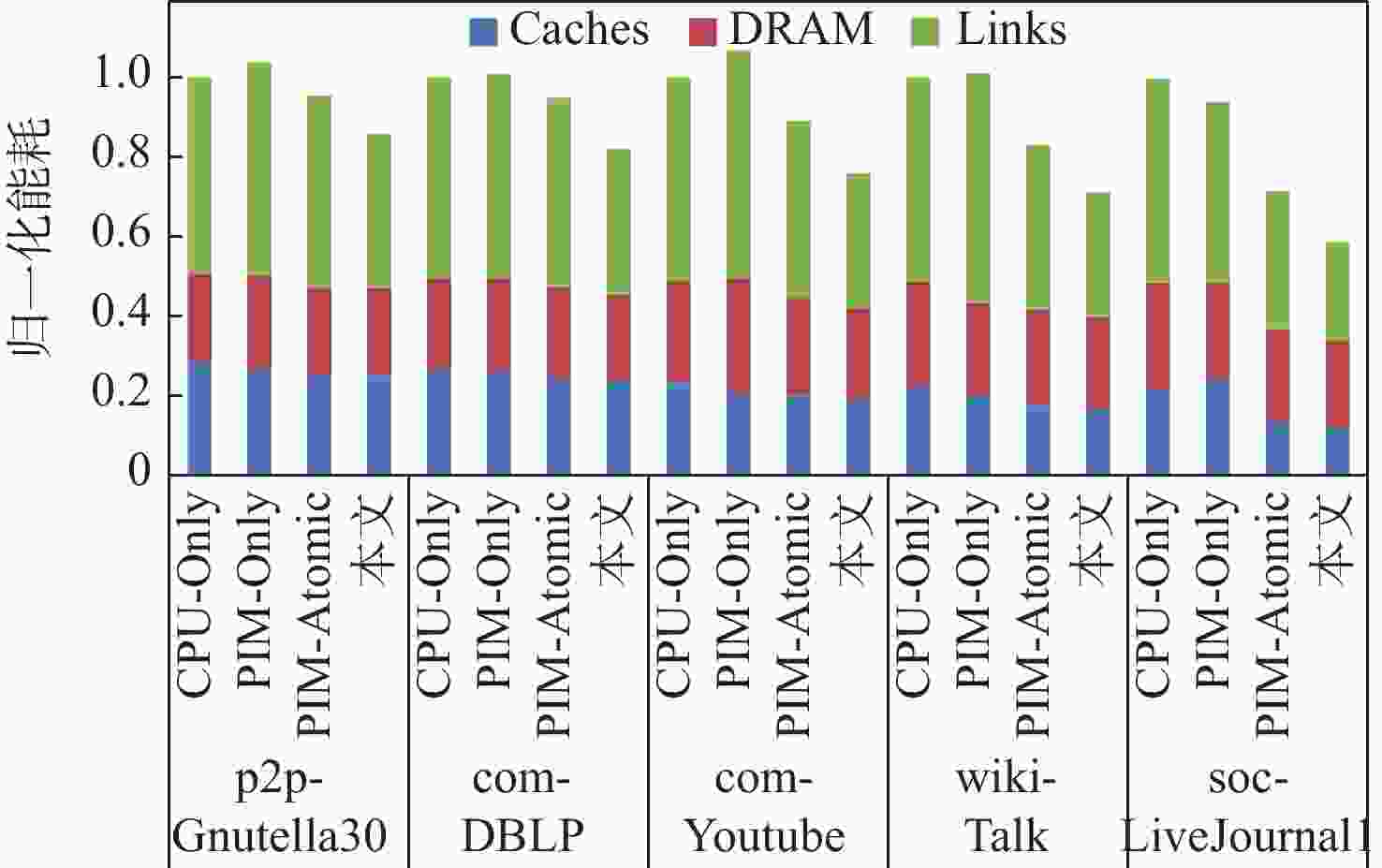
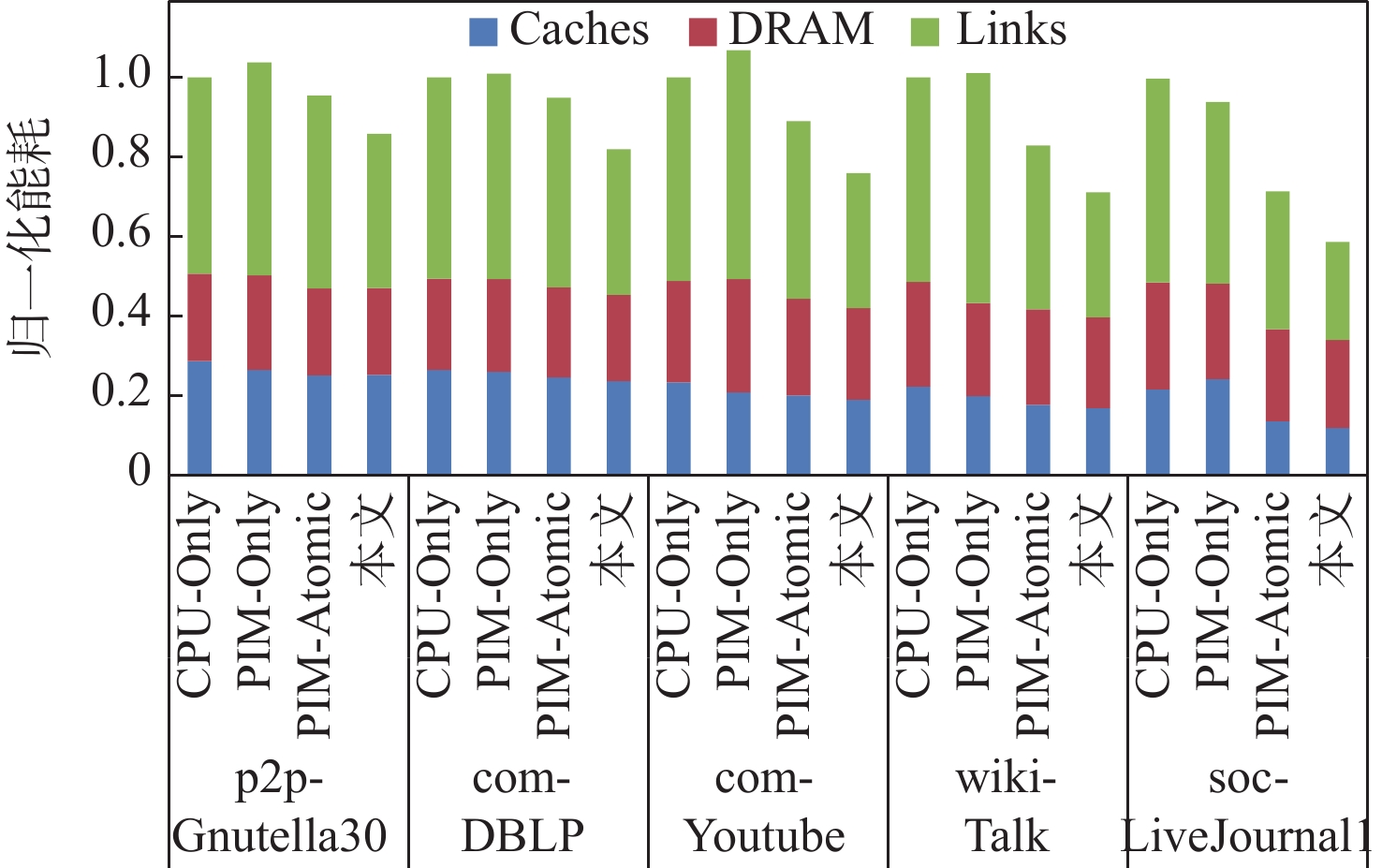
图 5 不同基准设计的能耗分解图
Figure 5. Energy consumption breakdown for different benchmark schemes
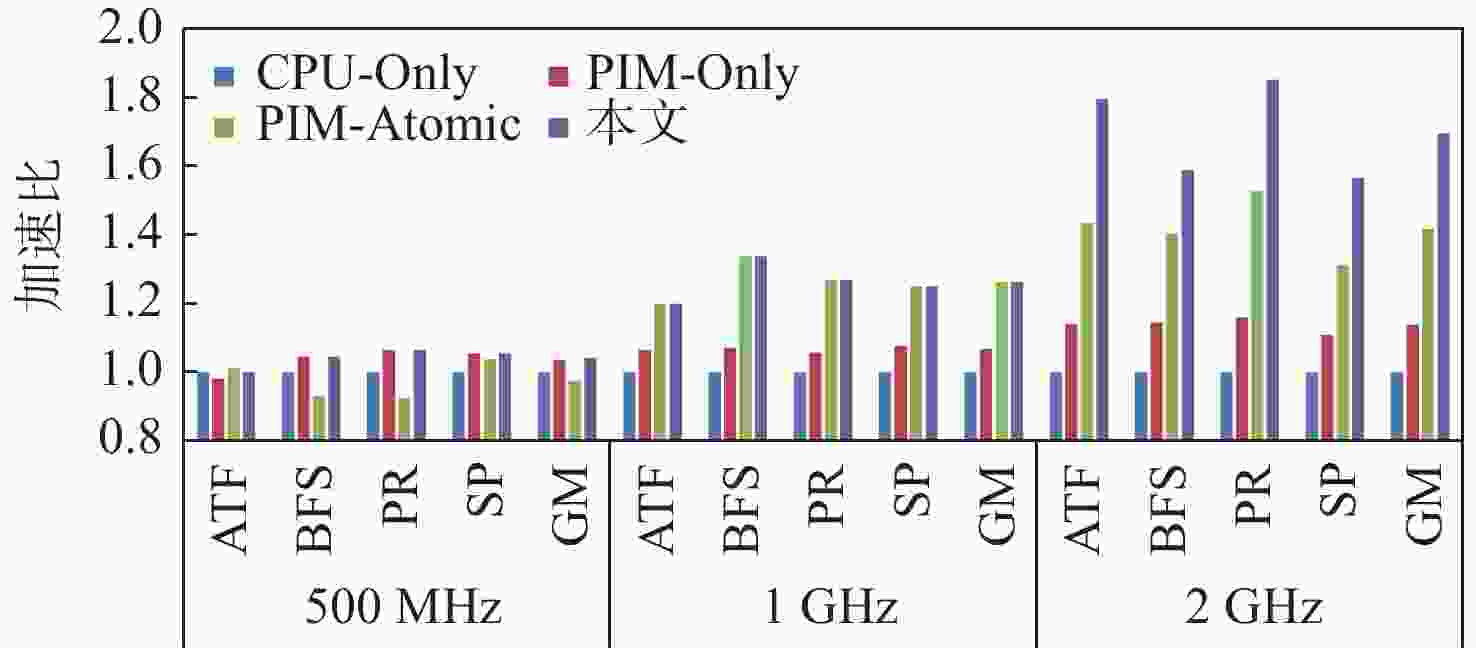
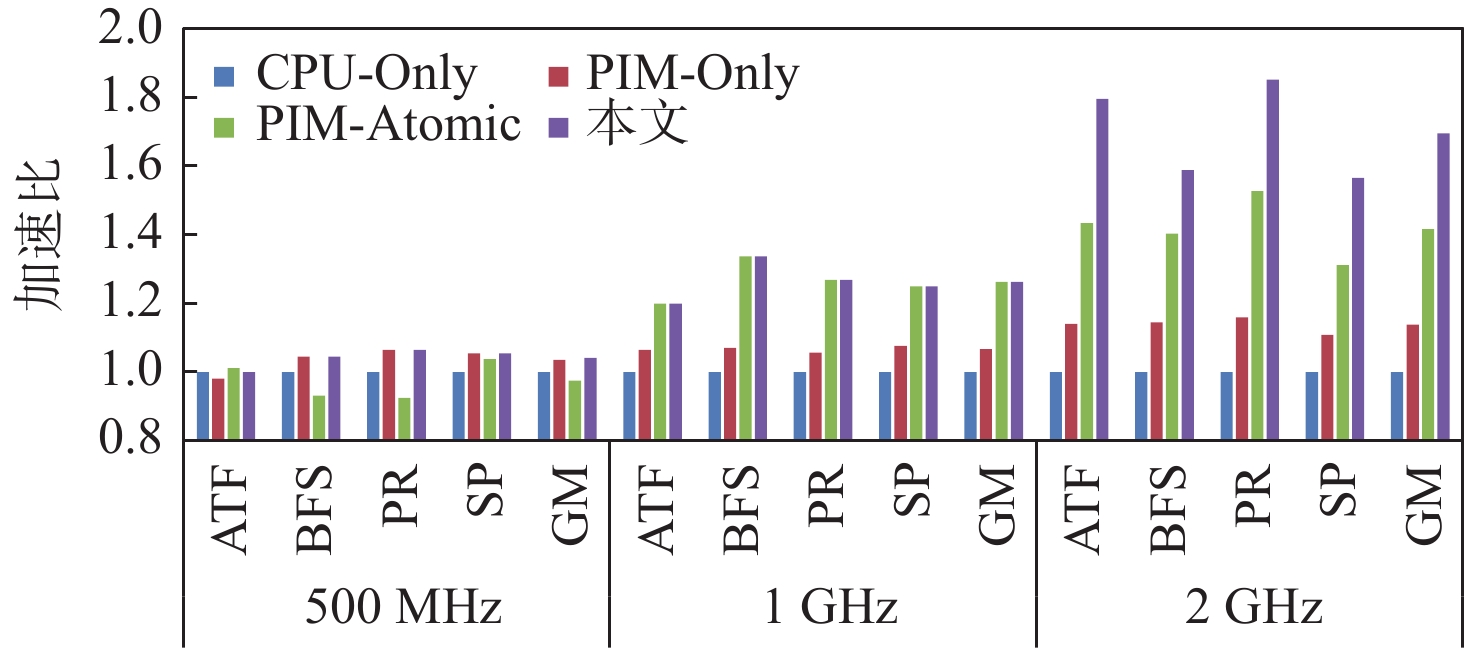
图 6 不同存内处理器核频率对系统性能的影响
Figure 6. Impact of different in-memory processor core frequencies on system performance
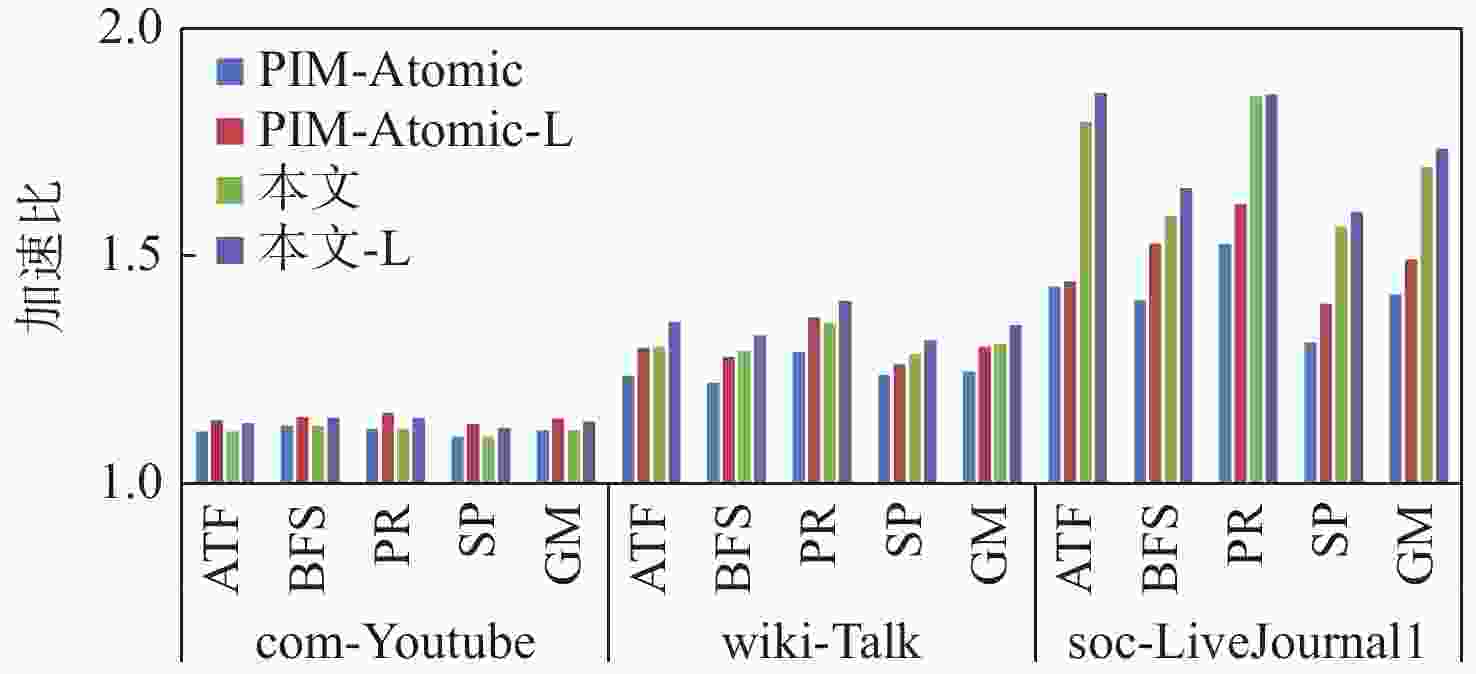
图 7 局部性感知对划分结果的影响示意图
Figure 7. Schematic diagram of the impact of locality awareness on partitioning results
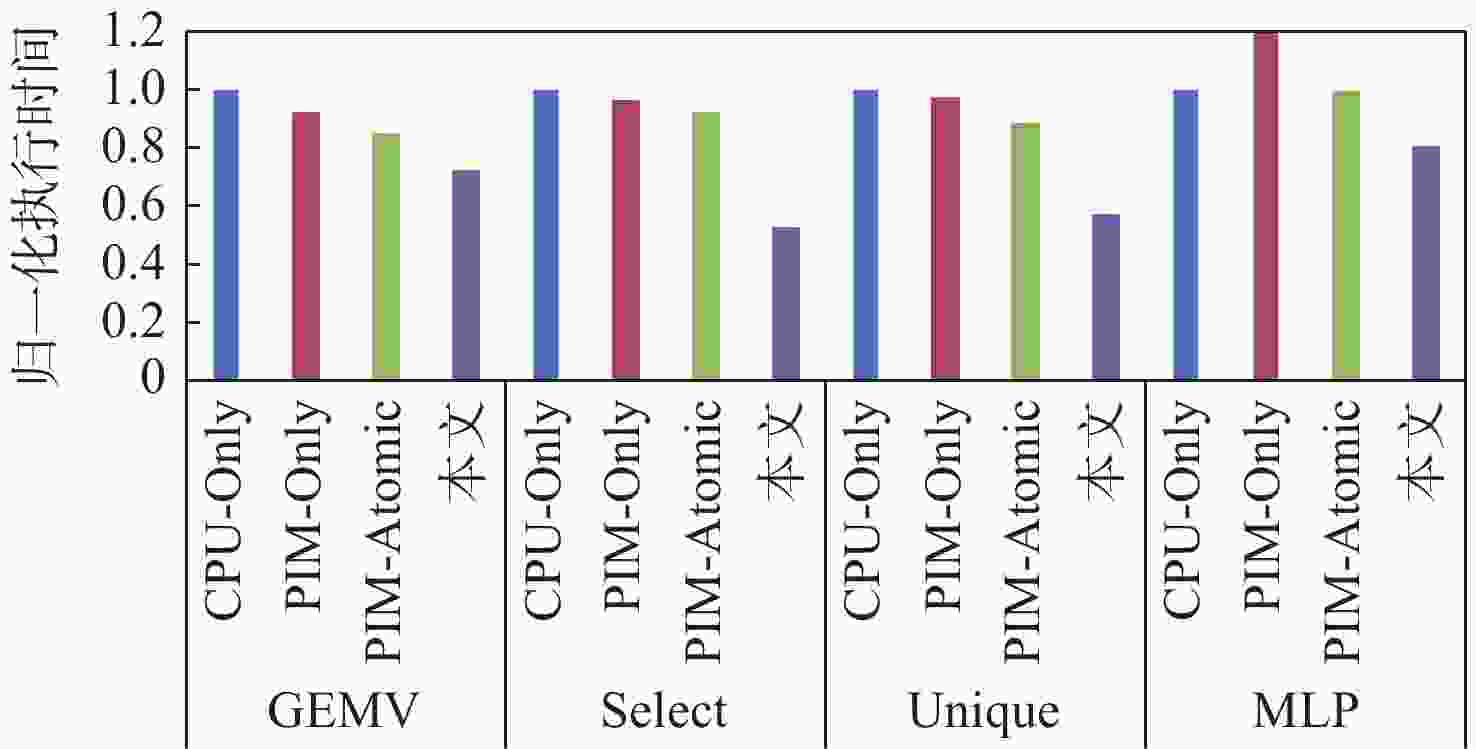
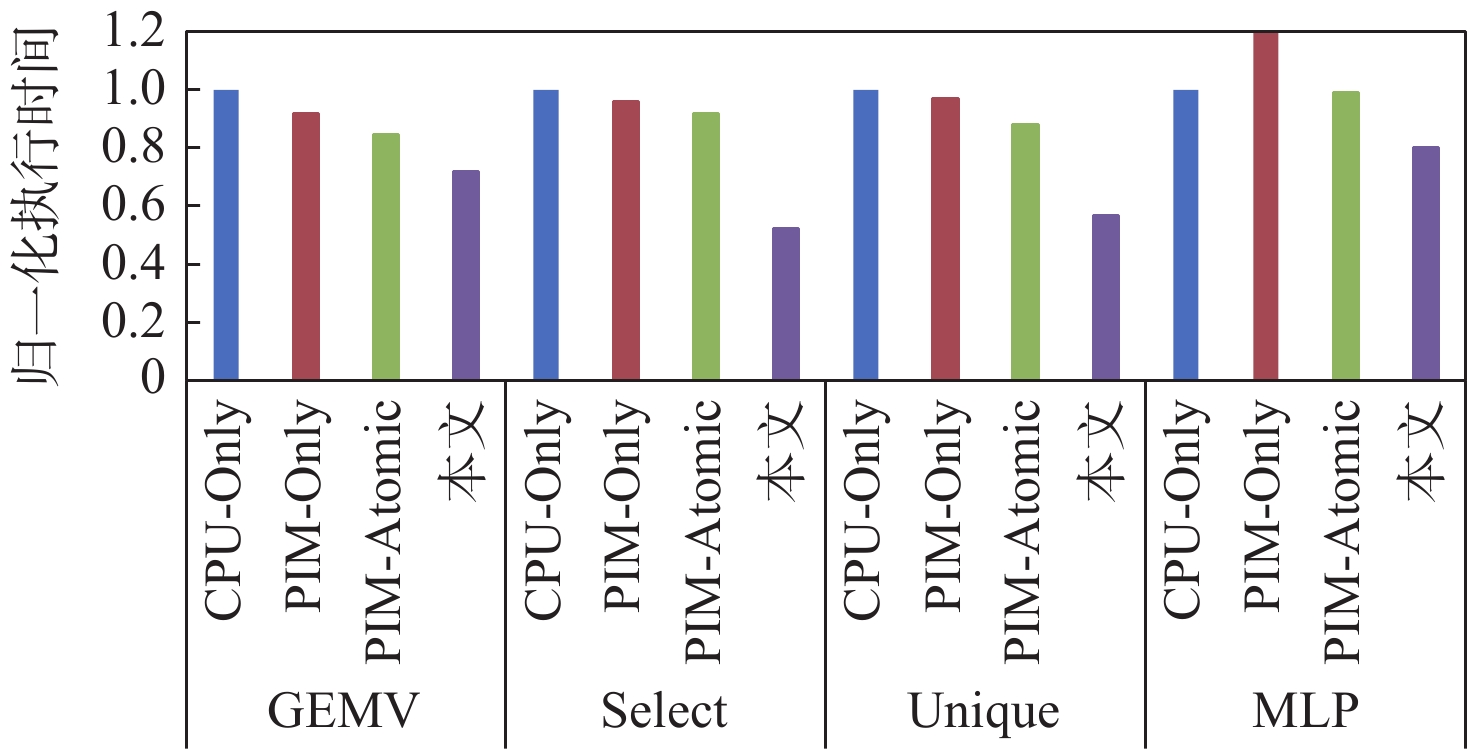
图 8 使用非图处理程序的性能加速比
Figure 8. Performance acceleration ratio when using non-graph processing programmes
表 1 注释调用图中边的属性说明
Table 1. Description of the edge properties in the ACG
ACG中
边的类型对应属性 说明 数据相关边
e = (u, v)$ \dfrac{{S}_{u,v}}{B_{\text{W}}^{}} $ 基本块u向基本块v传输
数据的时间控制相关边 控制相关决定了基本块间
的先行后续关系从PIM伪节点出发的边
e = ($ {v}_{\text{PIM}} $, v)$ T_{v}^{\text{PIM}} $ 基本块v在存内计算单元
中的执行时间,无法在存
内执行的基本块值为+∞从CPU伪节点出发的边
e = ($ {v}_{\text{CPU}} $, v)$ T_{v}^{\text{CPU}} $ 基本块v在CPU上的执行
时间 下载: 导出CSV
下载: 导出CSV
表 3 本文使用的基准程序和数据集
Table 3. Benchmarks and datasets used in this paper
基准程序 数据集 Average Teenage Follower (ATF)、
Breadth-First Search (BFS)、
Bellman Ford Shortest Path (SP)、
PageRank (PR)p2p-Gnutella30 (36 K点, 88 K边)、
com-DBLP (317 K点, 1 M边)、
com-Youtube (1.1 M点, 2.9 M边)、
wiki-Talk (2.3 M点, 5 M边)、
soc-LiveJournal1 (4.8 M点, 6.9 M边)
下载: 导出CSV
表 4 非图处理应用存内加载比例
Table 4. In-memory loading ratio for non-graph processing applications
基准程序 存内加载比例/% PIM-Only PIM-Atomic 本文方法 GEMV 100 15.44 13.75 Select 100 31.45 36.48 Unique 100 40.60 46.17 MLP 100 5.35 9.64
下载: 导出CSV
-
[1] HUANG X H, LIU C S, JIANG Y G, et al. In-memory computing to break the memory wall[J]. Chinese Physics B, 2020, 29(7): 078504. [2] LEE C, SHIN W, KIM D J, et al. NVDIMM-C: a byte-addressable non-volatile memory module for compatibility with standard DDR memory interfaces[C]//Proceedings of the 2020 IEEE International Symposium on High Performance Computer Architecture. Piscataway: IEEE Press, 2020: 502-514. [3] PATTNAIK A P. Be aware of data movement: optimizing throughput processors for efficient computations[D]. State College: The Pennsylvania State University, 2019: 10-12. [4] Advanced Micro Devices, Inc. AMD EPYC™ 9684X server processors[EB/OL]. (2023-01-16)[2024-03-12]. https://www.amd.com/zh-cn/products/processors/server/epyc/4th-generation-9004-and-8004-series/amd-epyc-9684x.html. [5] AHN J, YOO S, MUTLU O, et al. PIM-enabled instructions: a low-overhead, locality-aware processing-in-memory architecture[C]//Proceedings of the 2015 ACM/IEEE 42nd Annual International Symposium on Computer Architecture. Piscataway: IEEE Press, 2015: 336-348. [6] KAUTZ W H. Cellular logic-in-memory arrays[J]. IEEE Transactions on Computers, 1969, C-18(8): 719-727. [7] JEDDELOH J, KEETH B. Hybrid memory cube new DRAM architecture increases density and performance[C]///Proceedings of the 2012 Symposium on VLSI Technology. Piscataway: IEEE Press, 2012: 87-88. [8] VAHIDPOUR M, O’BRIEN W, WHYLAND J T, et al. Superconducting through-silicon vias for quantum integrated circuits[EB/OL]. (2017-08-07)[2024-03-12]. https://arxiv.org/abs/1708.02226. [9] LI T, HOU J, YAN J L, et al. Chiplet heterogeneous integration technology—status and challenges[J]. Electronics, 2020, 9(4): 670. [10] AHN J, HONG S, YOO S, et al. A scalable processing-in-memory accelerator for parallel graph processing[C]//Proceedings of the 2015 ACM/IEEE 42nd Annual International Symposium on Computer Architecture. Piscataway: IEEE Press, 2015: 105-117. [11] IMANI M, KIM Y, ROSING T. MPIM: multi-purpose in-memory processing using configurable resistive memory[C]//Proceedings of the 2017 22nd Asia and South Pacific Design Automation Conference. Piscataway: IEEE Press, 2017: 757-763. [12] STRUKOV D B, SNIDER G S, STEWART D R, et al. The missing memristor found[J]. Nature, 2008, 453(7191): 80-83. [13] KHAN K, PASRICHA S, KIM R G. A survey of resource management for processing-in-memory and near-memory processing architectures[J]. Journal of Low Power Electronics and Applications, 2020, 10(4): 30. [14] HSIEH K, EBRAHIM E, KIM G, et al. Transparent offloading and mapping (TOM): enabling programmer-transparent near-data processing in GPU systems[C]//Proceedings of the 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture. Piscataway: IEEE Press, 2016: 204-216. [15] TSAI P A, CHEN C P, SANCHEZ D. Adaptive scheduling for systems with asymmetric memory hierarchies[C]//Proceedings of the 2018 51st Annual IEEE/ACM International Symposium on Microarchitecture. Piscataway: IEEE Press, 2018: 641-654. [16] XIAO Y, NAZARIAN S, BOGDAN P. Prometheus: processing-in-memory heterogeneous architecture design from a multi-layer network theoretic strategy[C]//Proceedings of the 2018 Design, Automation & Test in Europe Conference & Exhibition. Piscataway: IEEE Press, 2018: 1387-1392. [17] LI Z R, CHEN X M, HAN Y H. Optimal data allocation for graph processing in processing-in-memory systems[C]//Proceedings of the 2022 27th Asia and South Pacific Design Automation Conference. Piscataway: IEEE Press, 2022: 238-243. [18] RYDER B G. Constructing the call graph of a program[J]. IEEE Transactions on Software Engineering, 1979, SE-5(3): 216-226. [19] NAI L F, HADIDI R, SIM J, et al. GraphPIM: enabling instruction-level PIM offloading in graph computing frameworks[C]//Proceedings of the 2017 IEEE International Symposium on High Performance Computer Architecture. Piscataway: IEEE Press, 2017: 457-468. [20] YAN L, ZHANG M Z, WANG R J, et al. CoPIM: a concurrency-aware PIM workload offloading architecture for graph applications[C]//Proceedings of the 2021 IEEE/ACM International Symposium on Low Power Electronics and Design. Piscataway: IEEE Press, 2021: 1-6. [21] BOROUMAND A, GHOSE S, PATEL M, et al. CoNDA: efficient cache coherence support for near-data accelerators[C]//Proceedings of the 2019 ACM/IEEE 46th Annual International Symposium on Computer Architecture. Piscataway: IEEE Press, 2020: 629-642. [22] XU S, CHEN X M, WANG Y, et al. CuckooPIM: an efficient and less-blocking coherence mechanism for processing-in-memory systems[C]//Proceedings of the 2019 24th Asia and South Pacific Design Automation Conference. Piscataway: IEEE Press, 2024: 1-6. [23] SONG L H, QIAN X H, LI H, et al. PipeLayer: a pipelined ReRAM-based accelerator for deep learning[C]//Proceedings of the 2017 IEEE International Symposium on High Performance Computer Architecture. Piscataway: IEEE Press, 2017: 541-552. [24] ZOU K W, WANG Y, LI H W, et al. XORiM: a case of in-memory bit-comparator implementation and its performance implications[C]//Proceedings of the 2018 23rd Asia and South Pacific Design Automation Conference. Piscataway: IEEE Press, 2018: 349-354. [25] NAI L F, HADIDI R, XIAO H, et al. Thermal-aware processing-in-memory instruction offloading[J]. Journal of Parallel and Distributed Computing, 2019, 130: 193-207. [26] LI S C, XU C, ZOU Q S, et al. Pinatubo: a processing-in-memory architecture for bulk bitwise operations in emerging non-volatile memories[C]//Proceedings of the 2016 53nd ACM/EDAC/IEEE Design Automation Conference. Piscataway: IEEE Press, 2016: 1-6. [27] HADIDI R, NAI L F, KIM H, et al. CAIRO: a compiler-assisted technique for enabling instruction-level offloading of processing-in-memory[J]. ACM Transactions on Architecture and Code Optimization, 2017, 14(4): 1-25. [28] AHMED H, SANTOS P C, LIMA J P C, et al. A compiler for automatic selection of suitable processing-in-memory instructions[C]//Proceedings of the 2019 Design, Automation & Test in Europe Conference & Exhibition. Piscataway: IEEE Press, 2019: 564-569. [29] JIN H, CHEN D, ZHENG L, et al. Accelerating graph convolutional networks through a PIM-accelerated approach[J]. IEEE Transactions on Computers, 2023, 72(9): 2628-2640. [30] NAI L F, HADIDI R, XIAO H, et al. CoolPIM: thermal-aware source throttling for efficient PIM instruction offloading[C]//Proceedings of the 2018 IEEE International Parallel and Distributed Processing Symposium. Piscataway: IEEE Press, 2018: 680-689. [31] PATTNAIK A, TANG X L, JOG A, et al. Scheduling techniques for GPU architectures with processing-in-memory capabilities[C]//Proceedings of the 2016 International Conference on Parallel Architectures and Compilation. New York: ACM, 2016: 31-44. [32] HSIEH K, KHAN S, VIJAYKUMAR N, et al. Accelerating pointer chasing in 3D-stacked memory: challenges, mechanisms, evaluation[C]//Proceedings of the 2016 IEEE 34th International Conference on Computer Design. Piscataway: IEEE Press, 2016: 25-32. [33] LI J, WANG X, TUMEO A, et al. PIMS: a lightweight processing-in-memory accelerator for stencil computations[C]//Proceedings of the International Symposium on Memory Systems. New York: ACM, 2019: 41-52. [34] FERRANTE J, OTTENSTEIN K J, WARREN J D. The program dependence graph and its use in optimization[C]//Proceedings of the International Symposium on Programming. Berlin: Springer, 1984: 125-132. [35] RAILING B P, HEIN E R, CONTE T M. Contech: efficiently generating dynamic task graphs for arbitrary parallel programs[J]. ACM Transactions on Architecture and Code Optimization, 2015, 12(2): 1-24. [36] GIBBONS P B, MUCHNICK S S. Efficient instruction scheduling for a pipelined architecture[C]//Proceedings of the 1986 SIGPLAN Symposium on Compiler Construction. New York: ACM, 1986: 11-16. [37] BUCHSBAUM A L, KAPLAN H, ROGERS A, et al. Linear-time pointer-machine algorithms for least common ancestors, MST verification, and dominators[C]//Proceedings of the Thirtieth Annual ACM Symposium on Theory of Computing. New York: ACM, 1998: 279-288. [38] LUK C K, COHN R, MUTH R, et al. Pin: building customized program analysis tools with dynamic instrumentation[J]. ACM SIGPLAN Notices: A Monthly Publication of the Special Interest Group on Programming Languages, 2005, 40(6): 190-200. [39] BARBERA M V, KOSTA S, MEI A, et al. To offload or not to offload the bandwidth and energy costs of mobile cloud computing[C]//Proceedings of the 2013 Proceedings IEEE INFOCOM. Piscataway: IEEE Press, 2013: 1285-1293. [40] DELAHAYE D, CHAIMATANAN S, MONGEAU M. Simulated annealing: from basics to applications[M]//GENDREAU M, POTVIN J Y. Handbook of metaheuristics. Berlin: Springer, 2019: 1-35. [41] XU S, CHEN X M, WANG Y, et al. PIMSim: a flexible and detailed processing-in-memory simulator[J]. IEEE Computer Architecture Letters, 2019, 18(1): 6-9. [42] BEAMER S, ASANOVIĆ K, PATTERSON D. The GAP benchmark suite[EB/OL]. (2017-05-16)[2024-03-12]. https://doi.org/10.48550/arXiv.1508.03619. [43] LESKOVEC J, SOSIČ R. SNAP: a general-purpose network analysis and graph-mining library[J]. ACM Transactions on Intelligent Systems, 2016, 8(1): 1-20. [44] MURALIMANOHAR N, BALASUBRAMONIAN R, JOUPPI N P. CACTI 6.0: a tool to model large caches: HPL-2009-85[R]. Palo Alto: HP Laboratories, 2009. [45] GÓMEZ-LUNA J, EL HAJJ I, FERNANDEZ I, et al. Benchmarking a new paradigm: experimental analysis and characterization of a real processing-in-memory system[J]. IEEE Access, 2022, 10: 52565-52608. -

 下载:
下载:

 点击查看大图
点击查看大图
计量
- 文章访问数: 10
- HTML全文浏览量: 2
- PDF下载量: 2
- 被引次数: 0
