



Superblock nesting based on performance optimization for dynamic binary translation
-
摘要:
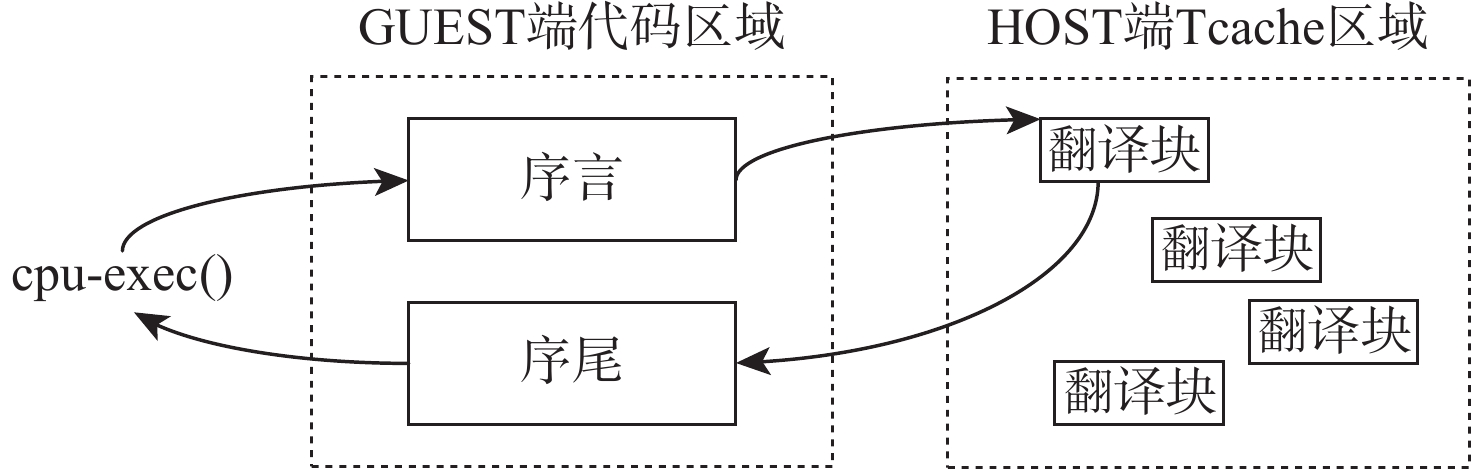
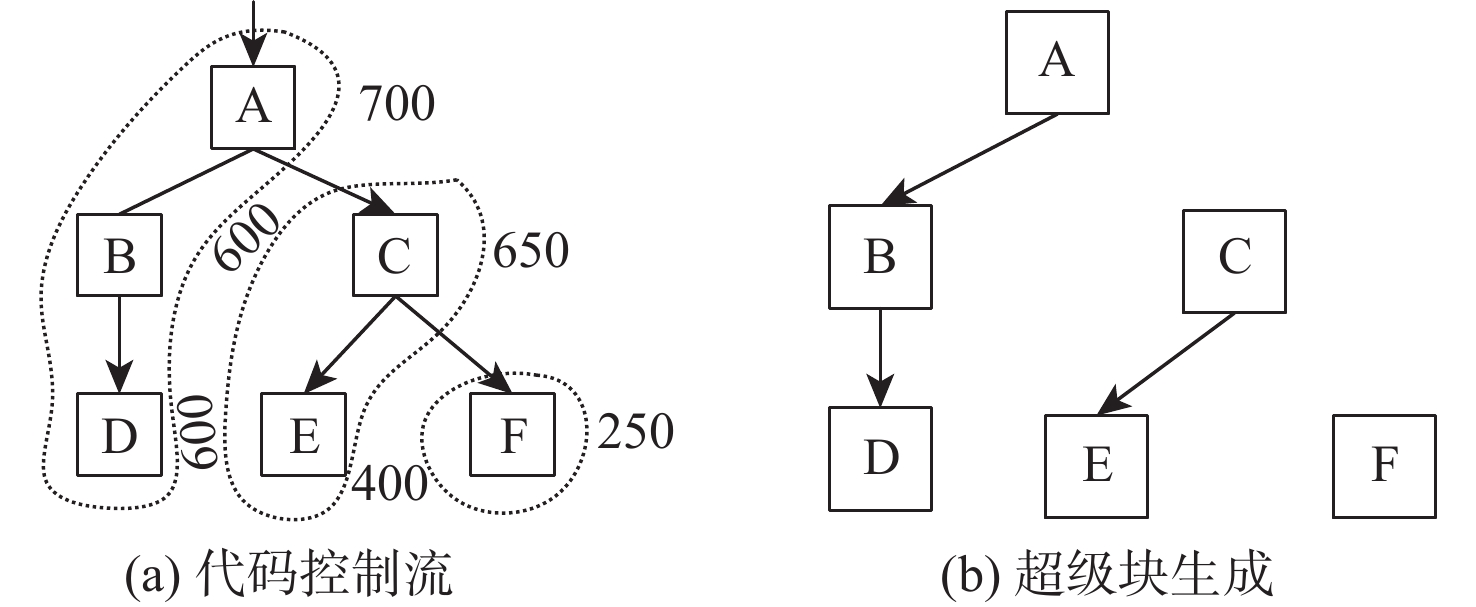
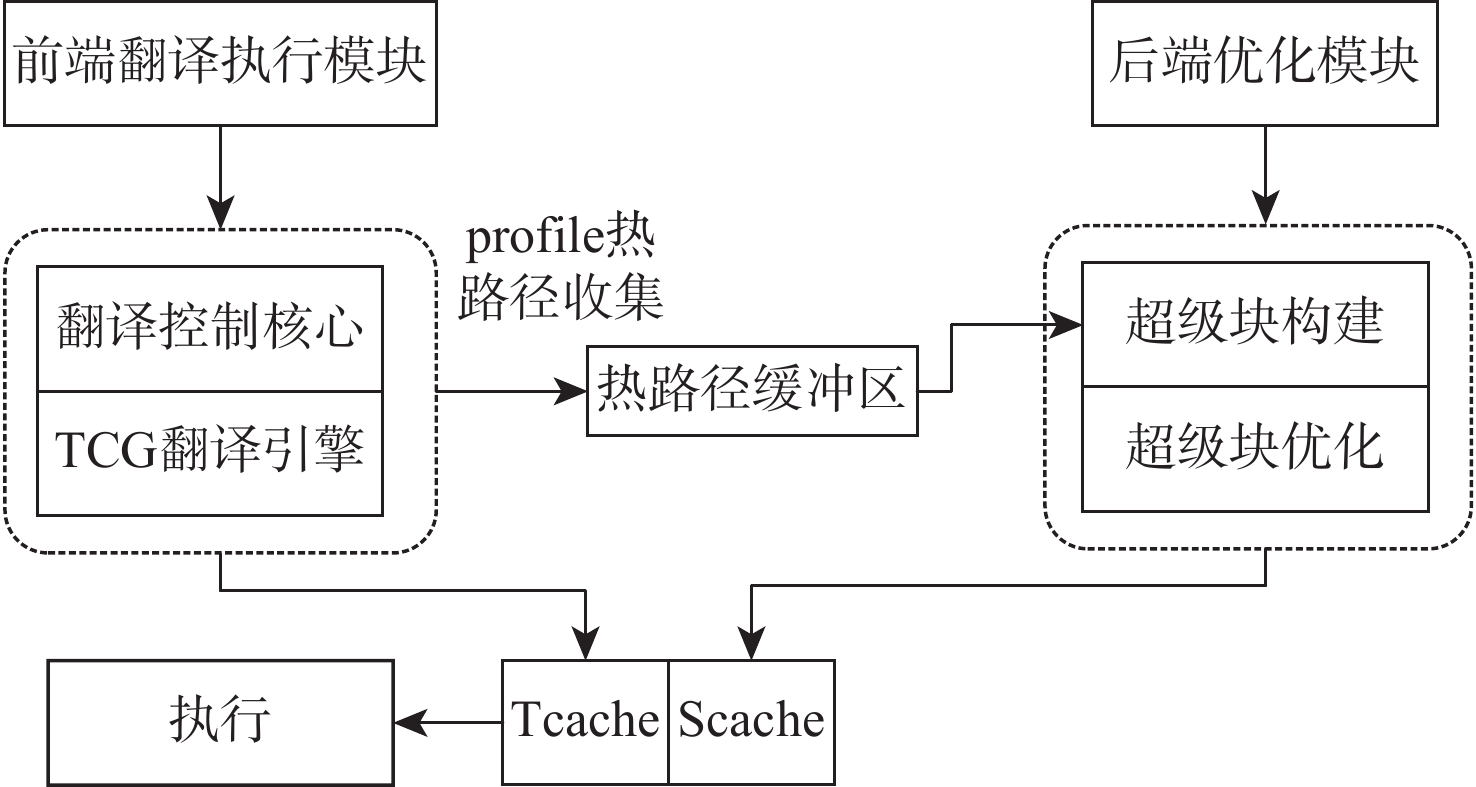
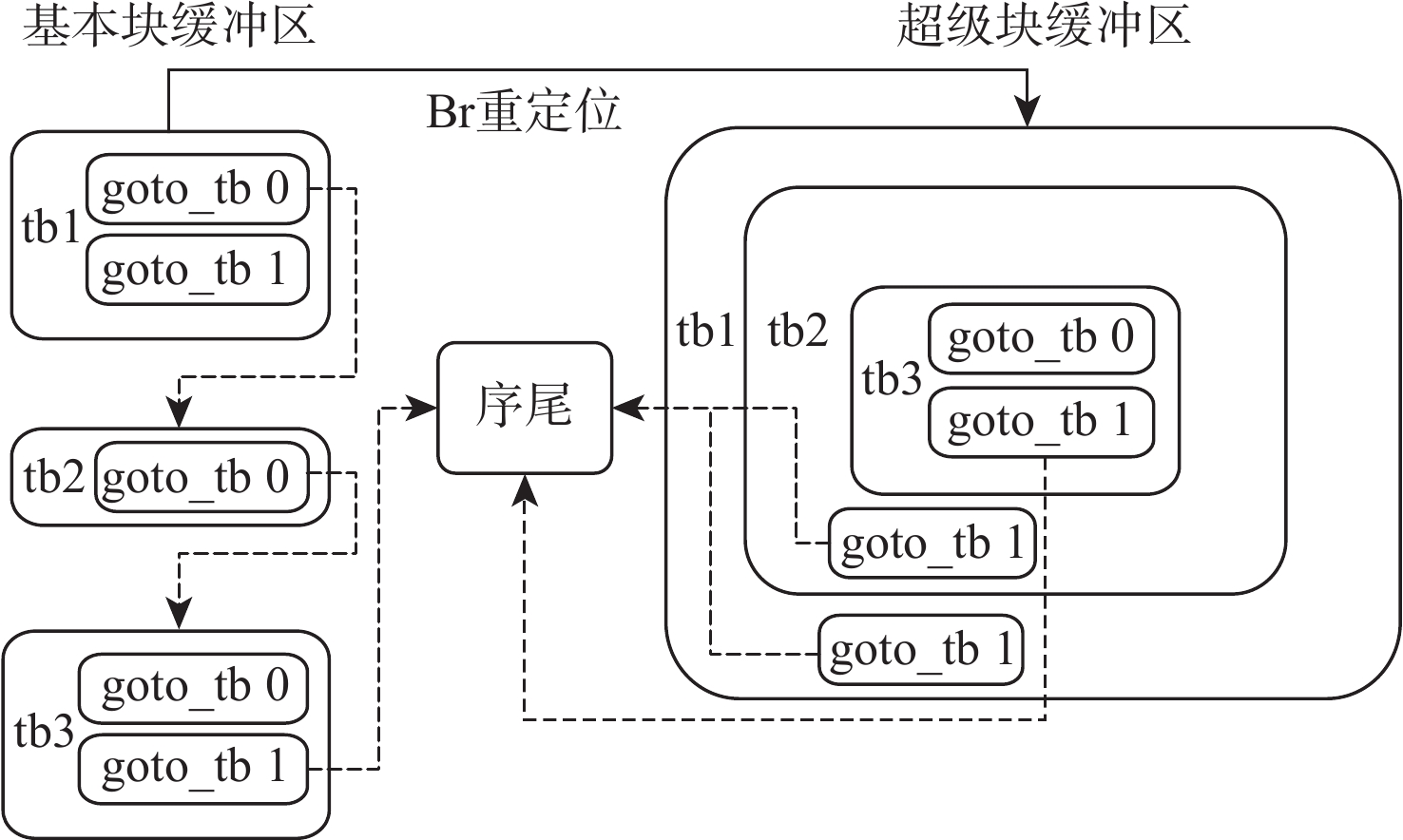
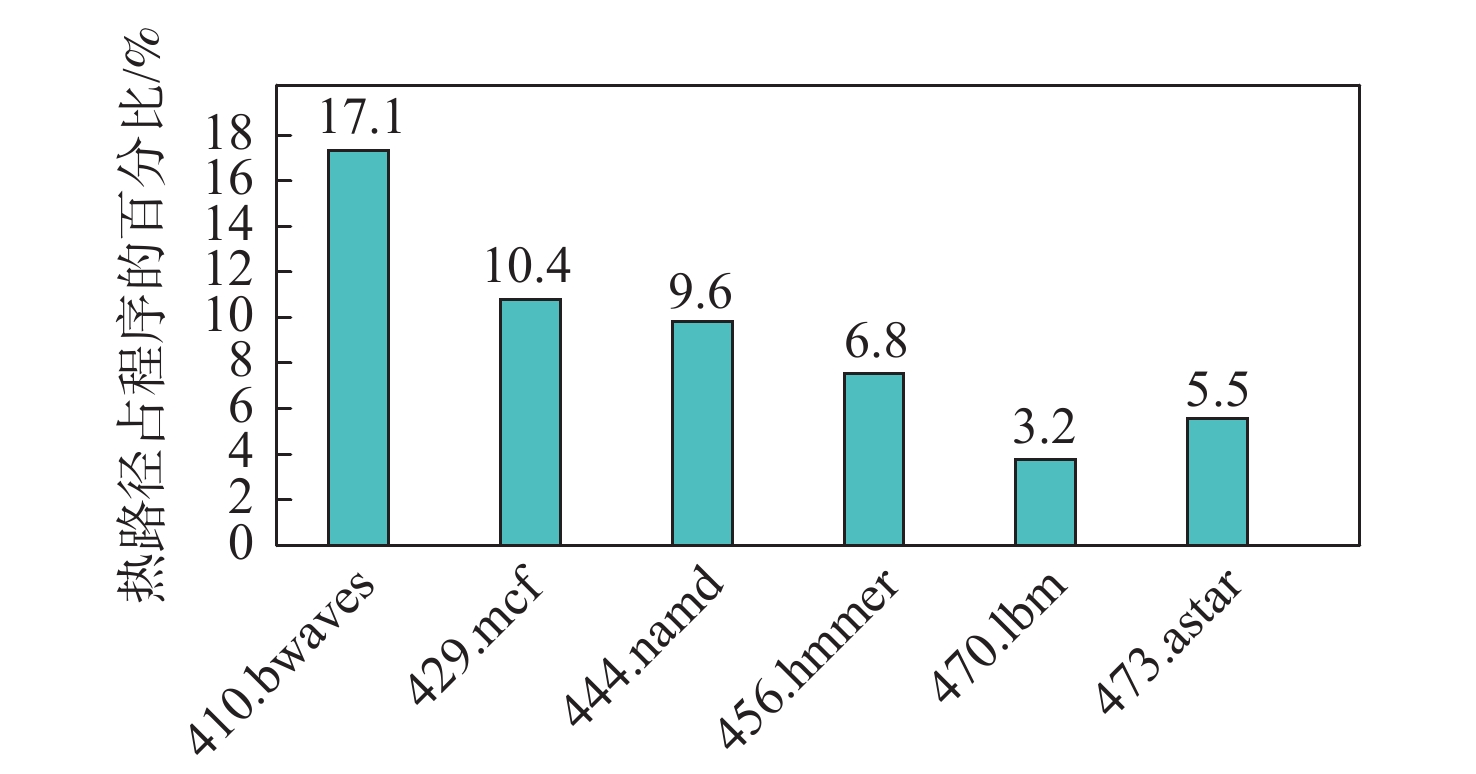
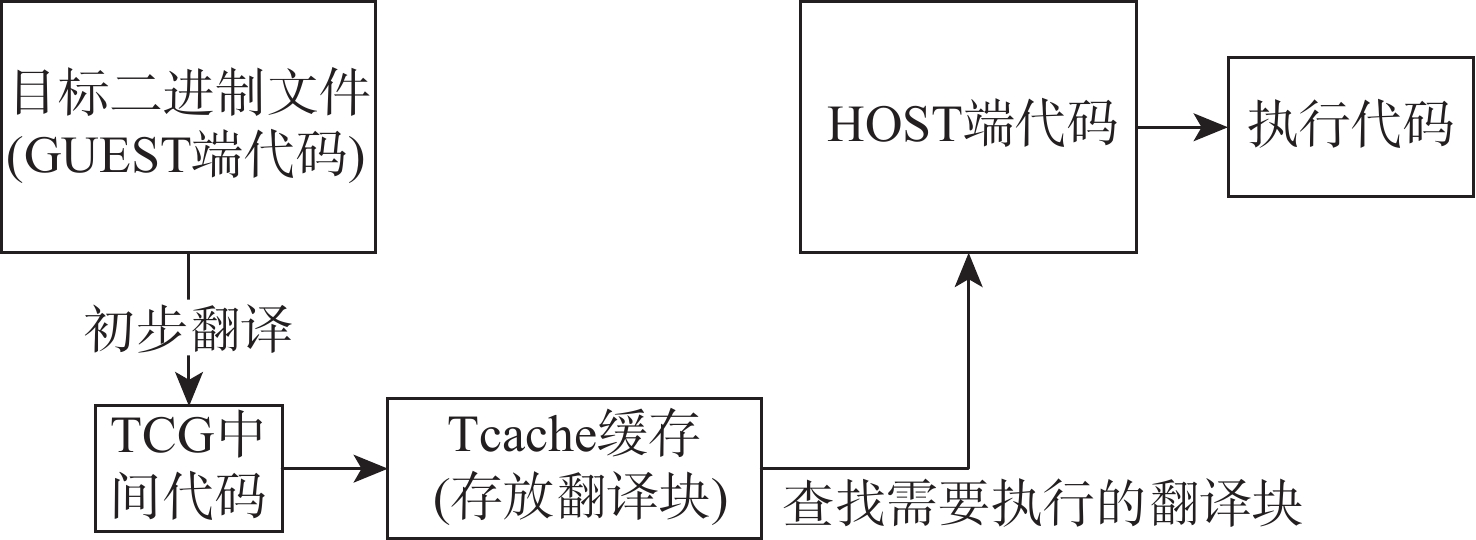
直接块链接方法可以在动态二进制翻译过程中降低翻译器介入频率、提升目标程序运行性能,单纯的直接块链接只关注逻辑层面的连接,并未关注物理存储位置的连续。针对该问题,提出了一种基于超级块嵌套的动态二进制翻译性能优化方法。基于二进制翻译器预翻译目标代码生成的中间表示(IR)指令,通过构建嵌套结构的超级块使代码实现物理存储位置的连续,从而增加指令cache命中率。实验结果表明:以动态二进制翻译领域最经典的且最常用的SPEC2006作为测试基准,以主流的开源二进制翻译器QEMU6.0为实验框架时,相比未采用超级块嵌套的版本,所提方法可将cache命中率平均提升53.28%,最大可提升90%。目标程序运行性能平均提升3.07%,最高可提升4.58%。
Abstract:Simple direct block linking only considers the connection at the logical level and ignores the continuity of the physical storage location, despite the fact that the "direct block linking" method can decrease the frequency of translator intervention and enhance the target program's performance during the dynamic binary translation process. Aiming at this problem, a dynamic binary translation performance optimization method based on superblock nesting is proposed, which is based on the IR instructions generated by the binary translator pre-translating the target code, and increases the instruction cache hit rate by constructing superblocks with a nested structure so that the code achieves the continuity of physical storage locations. The experimental results show that: SPEC2006, the most classic and commonly used in the field of dynamic binary translation, is used as the test benchmark, and QEMU6.0, a mainstream open-source binary translator, is used as the experimental framework. Compared with the version without superblock nesting, the proposed method can improve the cache hit rate by 53.28% on average, and the maximum increase can be 90%. The running performance of the target program can be improved by 3.07% on average and 4.58% at maximum.
-
Key words:
- dynamic binary translation /
- superblock /
- intermediate code nesting /
- QEMU /
- cache
-
表 1 SPEC2006超级块构造相关统计数据
Table 1. SPEC2006 Superblock construction related statistics
测试程序 基本块
数量/个超级块
数量/个基本块
大小/KB超级块
大小/KB410.bwaves 1 899 633 383 345 429.mcf 3 024 1 008 478 442 444.namd 10 962 3 654 5 043 4 640 456.hmmer 16 092 5 343 8 754 8 090 470.lbm 600 151 401 370 473.astar 1 400 423 656 604  下载: 导出CSV
下载: 导出CSV
表 2 410.bwaves课题相关统计数据
Table 2. 410.bwaves subject-related statistics
调用函数名称 调用次数/次 运行时间/s 函数单次循环次数/次 mat_times_vec_ 604 21.62 3 380 000 bi_cgstab_block_ 20 3.88 0 shell_ 1 2.8 0 jacobian_ 60 0.77 0 flux 20 0.34 0 MAIN_ 1 0.01 0 main 1 0.01 2 041 520 000
下载: 导出CSV
表 3 470.lbm课题相关统计数据
Table 3. 470.lbm subject-related statistics
调用函数名称 调用
次数/次运行
时间/s函数单次循环
次数/次LBM_performStreamCollide 300 11.70 0 LBM_initializeGrid 2 1.70 0 LBM_handleInOutFlow_ 300 0.23 0 LBM_showGridStatistics_ 6 0.10 0 LBM_initializeSpecialCellsForChannel 2 0.01 1 300 000 LBM_swapGrids 300 0.01 0 LBM_allocateGrid 2 0.01 0 LBM_freeGrid 2 0.01 0 LBM_loadObstacleFile 2 0.01 1 300 000 MAIN_finalize 1 0.01 0 MAIN_initialize 1 0.01 0 MAIN_parseCommandLine 1 0.01 0 MAIN_printInfo 1 0.01 0 main 1 0.01 5 200 000
下载: 导出CSV
-
[1] BELLARD F. QEMU, a fast and portable dynamic translator[C]//Proceedings of the 2005 USENIX Annual Technical Conference. Anaheim: USENIX, 2005: 41-46. [2] 胡伟武, 汪文祥, 吴瑞阳, 等. 龙芯指令系统架构技术[J]. 计算机研究与发展, 2023, 60(1): 2-16.HU W W, WANG W X, WU R Y, et al. Loongson instruction set architecture technology[J]. Journal of Computer Research and Development, 2023, 60(1): 2-16(in Chinese). [3] SHEN B Y, YOU J Y, YANG W, et al. An LLVM-based hybrid binary translation system[C]//Proceedings of the 7th IEEE International Symposium on Industrial Embedded Systems. Piscataway: IEEE Press, 2012: 229-236. [4] EBCIOGLU K, ALTMAN E, GSCHWIND M, et al. Dynamic binary translation and optimization[J]. IEEE Transactions on Computers, 2001, 50(6): 529-548. [5] HWU W M W, MAHLKE S A, CHEN W Y, et al. The superblock: an effective technique for VLIW and superscalar compilation[C]//Proceedings of the Instruction-level Parallelism. Boston: Springer, 2011: 229-248. [6] SCOTT K, KUMAR N, CHILDERS B R, et al. Overhead reduction techniques for software dynamic translation[C]//Proceedings of the 18th International Parallel and Distributed Processing Symposium. Piscataway: IEEE Press, 2004: 200-207. [7] 石强. 面向国产处理器的二进制翻译关键优化技术研究[D]. 郑州: 解放军信息工程大学, 2017: 19-34.SHI Q. Research on key optimization techniques of binary translation for domestic processors[D]. Zhengzhou: PLA Information Engineering University, 2017: 19-34(in Chinese). [8] 李男, 庞建民. 基于中间表示规则替换的二进制翻译中间代码优化方法[J]. 国防科技大学学报, 2021, 43(4): 156-162.LI N, PANG J M. Intermediate code optimization method for binary translation based on intermediate representation rule replacement[J]. Journal of National University of Defense Technology, 2021, 43(4): 156-162(in Chinese). [9] HONG D Y, HSU C C, YEW P C, et al. HQEMU: a multi-threaded and retargetable dynamic binary translator on multicores[C]//Proceedings of the Tenth International Symposium on Code Generation and Optimization. New York: ACM, 2012: 104-113. [10] POEPLAU S, FRANCILLON A. SymQEMU: compilation-based symbolic execution for binaries[C]//Proceedings of the 2021 Network and Distributed System Security Symposium. Internet Society. San Diego: DNSS, 2021: 1-13. [11] DING J H, CHANG P C, HSU W C, et al. PQEMU: a parallel system emulator based on QEMU[C]//Proceedings of the 2011 IEEE 17th International Conference on Parallel and Distributed Systems. Piscataway: IEEE Press, 2012: 276-283. [12] WANG Z G, LIU R, CHEN Y F, et al. COREMU: a scalable and portable parallel full-system emulator[C]//Proceedings of the 16th ACM Symposium on Principles and Practice of Parallel Programming. New York: ACM, 2011: 213-222. [13] ZHAO Z Y, ZHANG J, LIU X M, et al. DQEMU: a scalable emulator with retargetable DBT on distributed platforms[C]// Proceedings of the 49th International Conference on Parallel Processing, Edmonton. New York: ACM, 2020: 1-11. [14] ZENG J Y, FU Y C, LIN Z Q. PEMU: a pin highly compatible out-of-VM dynamic binary instrumentation framework[C]//Proceedings of the 11th ACM SIGPLAN/SIGOPS International Conference on Virtual Execution Environments. New York: ACM, 2015: 147-160. [15] LI M L, PANG J M, YUE F, et al. Enhancing dynamic binary translation in mobile computing by leveraging polyhedral optimization[J]. Wireless Communications and Mobile Computing, 2021, 2021(1): 6611867. [16] DOLAN-GAVITT B, HODOSH J, HULIN P, et al. Repeatable reverse engineering with PANDA[C]//Proceedings of the 5th Program Protection and Reverse Engineering Workshop. New York: ACM, 2015: 1-11. [17] HWU W W, MAHLKE S A, CHEN W Y, et al. The superblock: an effective technique for VLIW and superscalar compilation[J]. Journal of Supercomputing, 1993, 7(1-2): 229-248. [18] CHILIMBI T M, DAVIDSON B, LARUS J R. Cache-conscious structure definition[C]//Proceedings of the ACM SIGPLAN 1999 Conference on Programming Language Design and Implementation. New York: ACM, 1999: 13-24. [19] CALDER B, KRINTZ C, JOHN S, et al. Cache-conscious data placement[C]//Proceedings of the Eighth International Conference on Architectural Support for Programming Languages and Operating Systems. New York: ACM, 1998: 139-149. [20] BAER J L, WANG W H. On the inclusion properties for multi-level cache hierarchies[C]//Proceedings of the The 15th Annual International Symposium on Computer Architecture . Conference Proceedings. Piscataway: IEEE Press, 2002: 73-80. [21] SHI H H, WANG Y, GUAN H B, et al. An intermediate language level optimization framework for dynamic binary translation[J]. ACM SIGPLAN Notices: A Monthly Publication of the Special Interest Group on Programming Languages, 2007, 42(5): 3-9. [22] BALL T, MATAGA P, SAGIV M. Edge profiling versus path profiling: The showdown[C]//Proceedings of the 25th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages - POPL '98. New York: ACM, 1998: 134-148. [23] BALA V, DUESTERWALD E, BANERJIA S. Transparent dynamic optimization: the design and implementation of Dynamo[R]. Hewlett-Packard Labs, 1999: HPL-1999-78. [24] DUESTERWALD E, BALA V. Software profiling for hot path prediction: Less is more[J]. ACM SIGARCH Computer Architecture News, 2000, 35(11): 202-211. [25] CIFUENTES C, LEWIS B, UNG D. Walkabout: a retargetable dynamic binary translation framework[J]. ACM SIGPLAN Notices, 2002, 37(7): 4-21. [26] BRUENING D, DUESTERWALD E, AMARASINGHE S. Design and implementation of a dynamic optimization framework for Windows[C]//Proceedings of the 4th ACM Workshop on Feedback-directed and Dynamic Optimization. New York: ACM Press, 2001: 20. [27] CHEN W K, LERNER S, CHAIKEN R, et al. Mojo: a dynamic optimization system[C]//Proceedings of the 3rd ACM Workshop on Feedback-Directed and Dynamic Optimization. New York: ACM Press, 2000: 81-90. [28] 张世宜. 基于QEMU的热点代码探测与动态优化模型的研究与实现[D]. 成都: 电子科技大学, 2013: 37-39.ZHANG S Y. University of electronic sci ence and technology of China[D]. Chengdu: University of Electronic Science and Technology of China, 2013: 37-39(in Chinese). [29] 白童心. 动态二进制翻译与动态优化相关问题研究[D]. 北京: 中国科学院研究生院(计算技术研究所), 2004: 33-34.BAI T X. Two topics on dynamic binary translation and optimization[D]. Beijing: Institute of Computing Technology, Chinese Academy of Sciences, 2004: 33-34(in Chinese). -

 下载:
下载:
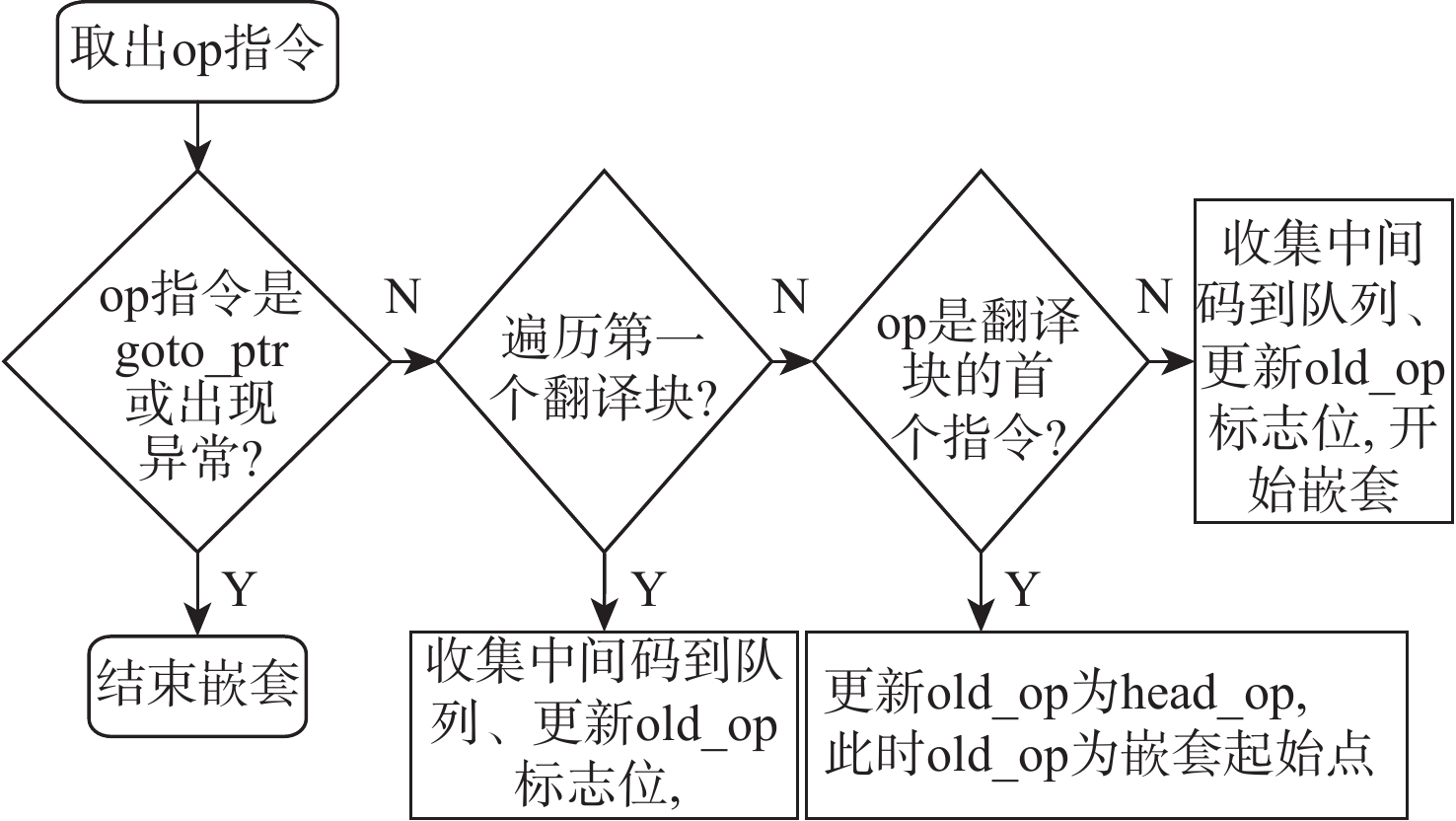
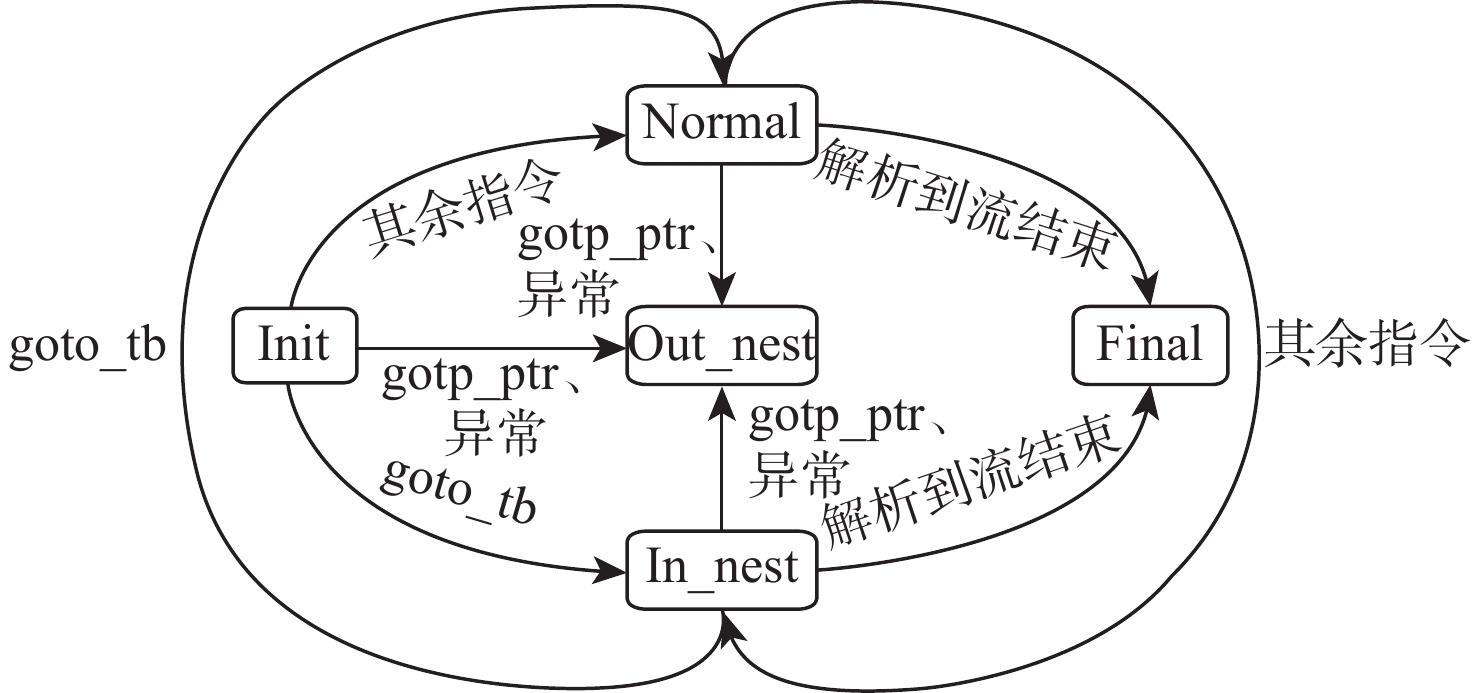
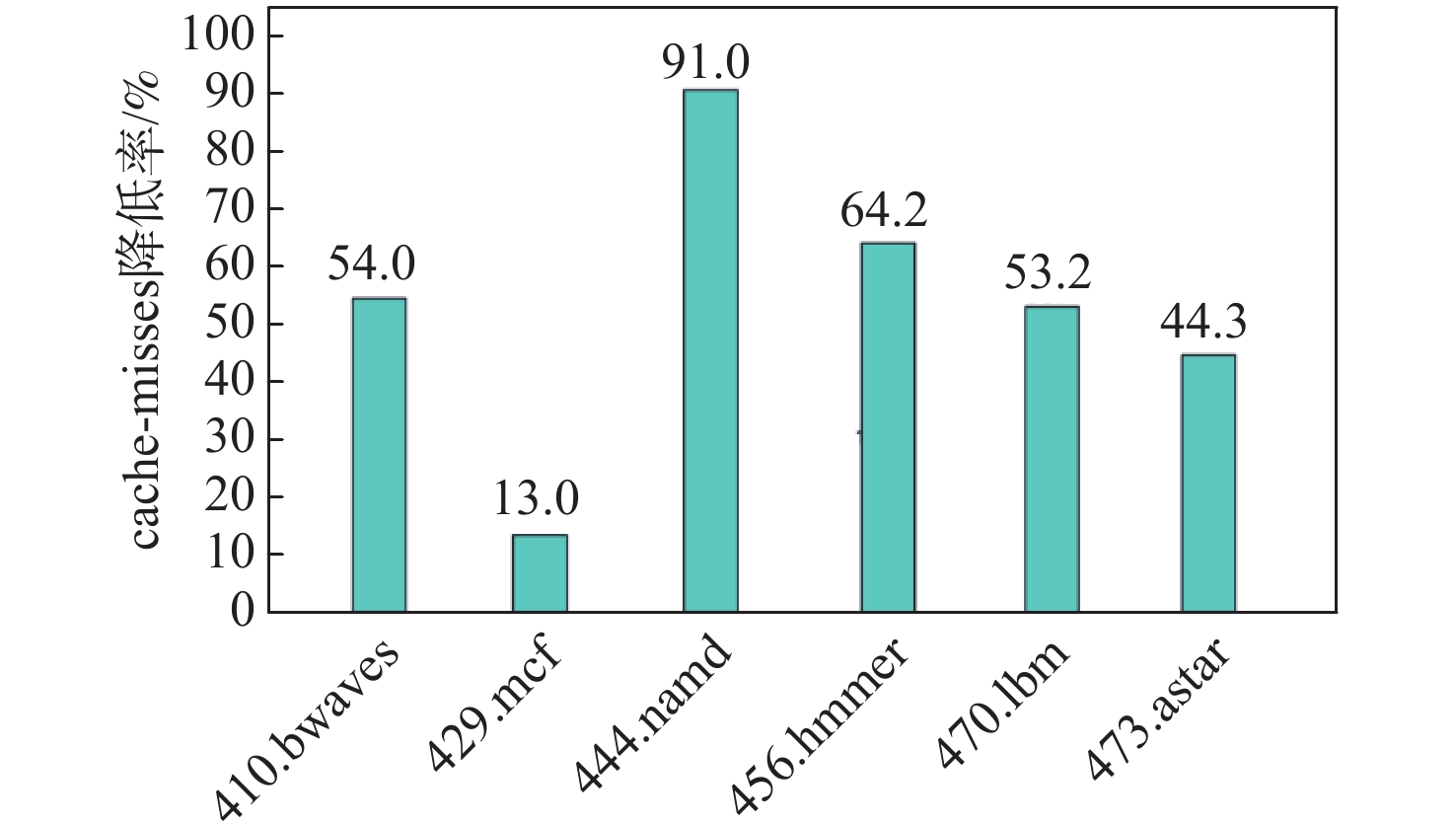
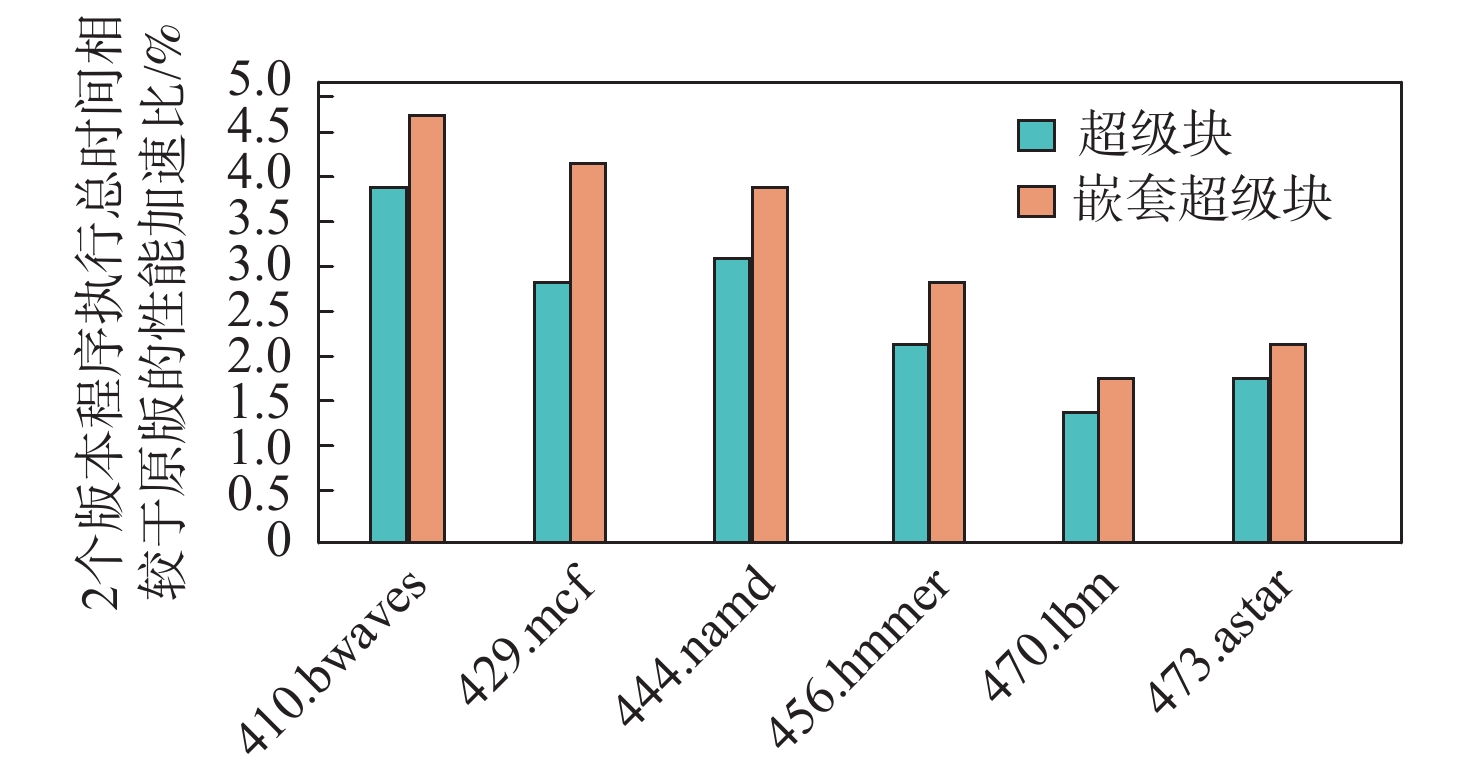

 点击查看大图
点击查看大图
计量
- 文章访问数: 261
- HTML全文浏览量: 99
- PDF下载量: 9
- 被引次数: 0
