



-
摘要:
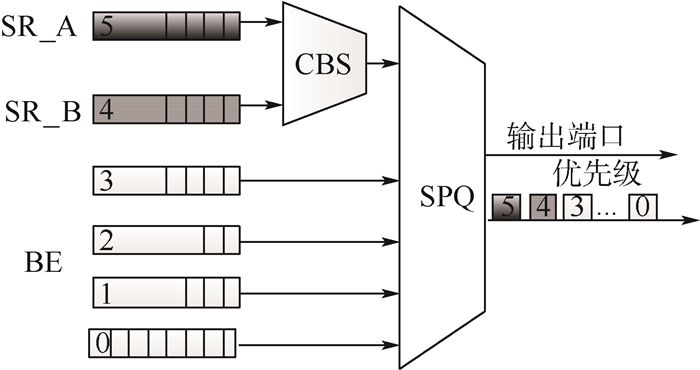
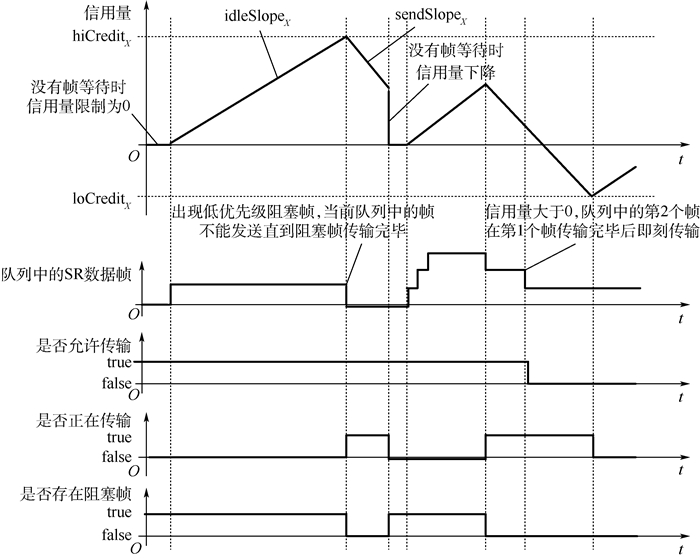
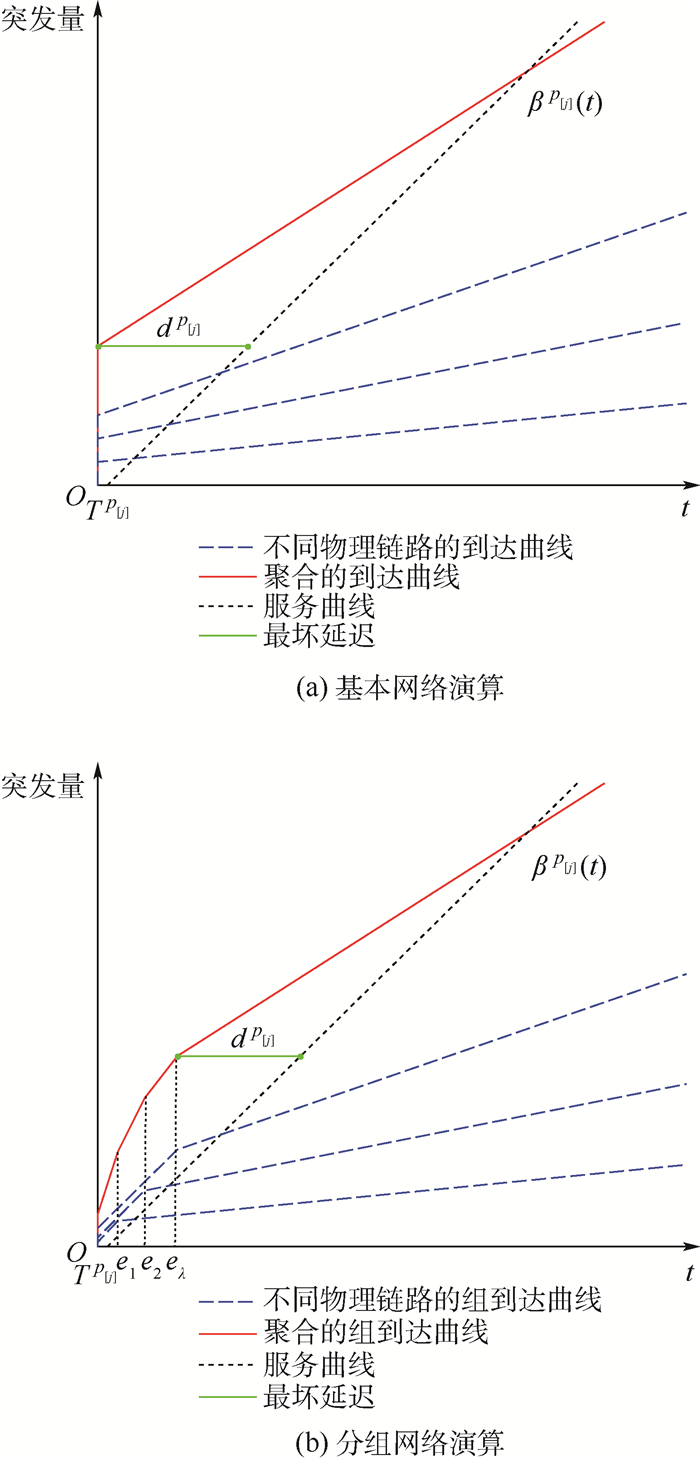
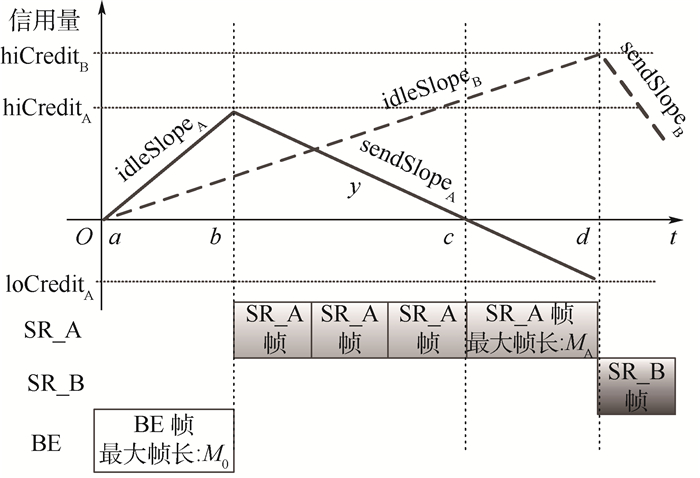
为满足未来航电系统音视频信息传输的需求,考虑车载嵌入式系统的候选实时多媒体网络AVB在航电环境中的应用,并对AVB与AFDX的传输进行了对比研究。首先构建AVB与AFDX标准对比;其次提出基于网络演算的AVB和AFDX端到端延迟计算方法;然后通过定义不同的消息传输场景,采用理论方法分析消息传输实时性的干扰要素;最后利用仿真方法予以验证。在典型1 000条虚拟链路的组网规模下,结果显示:AFDX高优先级流量的端到端延迟优于AVB,对于低优先级流量端到端延迟,则AVB和AFDX各有优劣;但受突发的流量影响,在增加50条各0.22 Mbit/s带宽的低优先级流量干扰情况下,高优先级流量平均端到端延迟的变化率在AVB中为0.25%,在AFDX中为0.38%;在增加50条各0.22 Mbit/s带宽的高优先级流量干扰情况下,低优先级流量平均端到端延迟的变化率在AVB中为5.17%,在AFDX中为10.25%。结果表明:时间敏感消息在AVB网络中传输实时性的抗干扰能力优于AFDX。
-
关键词:
- 航空电子网络 /
- 音视频桥接(AVB)网络 /
- 航空电子全双工交换以太网(AFDX) /
- 实时性 /
- 抗干扰
Abstract:AVB is considered to meet the demands of audio video transmission in future avionics system, which is a real-time multimedia network and has become a candidate for in-vehicle embedded systems. Comparative study on AFDX and AVB is implemented. First, standards of AVB and AFDX are compared. Second, the method for end-to-end delay in AVB and AFDX is discussed by network calculus. Then the elements interfering real-time transmission are analyzed depending on different transmission scenarios. Conclusions are verified by simulation. In typical networking with 1 000 virtual links, the results show that the end-to-end delay of high priority traffic in AFDX is smaller than that in AVB; the advantage and disadvantage of end-to-end delay for low priority traffic exist in both AVB and AFDX. But influenced by the burst 50 low priority streams (each with 0.22 Mbit/s bandwidth), the variation rate of average end-to-end delay for high priority traffic is 0.25% in AVB and 0.38% in AFDX; influenced by the burst 50 high priority streams (each with 0.22 Mbit/s bandwidth), the variation rate of low priority traffic is 5.17% in AVB and 10.25% in AFDX. Real-time anti-jamming transmission of time-sensitive information in AVB is superior to AFDX.
-
表 1 SR_A类和SR_B类参数
Table 1. Parameters of SR_A and SR_B
类型 优先级 最大帧长/Byte 发送频率/μs 7跳最大延迟/ms 最大抖动/μs SR_A 高 1 171 125 2 125 SR_B 低 1 500 250 50 1 000  下载: 导出CSV
下载: 导出CSV
表 3 配置信息
Table 3. Configuration information
VLi 源节点 目的节点 帧长/Byte AFDX AVB BAG/ms 流量类型 ServiceRate/ms MIF 流量类型 1~50 ① ② 72 2 低优先级 40 20 SR_B 51~150 ① ④ 172 16 高优先级 160 10 SR_A 151~350 ② ⑥ 800 128 低优先级 1 280 10 SR_B 351~450 ③ ⑦ 100 8 高优先级 40 5 SR_A 451~650 ④ ⑧ 200 32 高优先级 320 10 SR_A 651~850 ⑤ ⑦ 372 64 低优先级 320 5 SR_B 851~950 ⑧ ⑥ 72 4 高优先级 40 10 SR_A 951~1 000 ⑨ ⑥ 872 32 高优先级 160 5 SR_A 951~1 000 ⑨ ⑥ 872 32 低优先级 160 5 SR_B
下载: 导出CSV
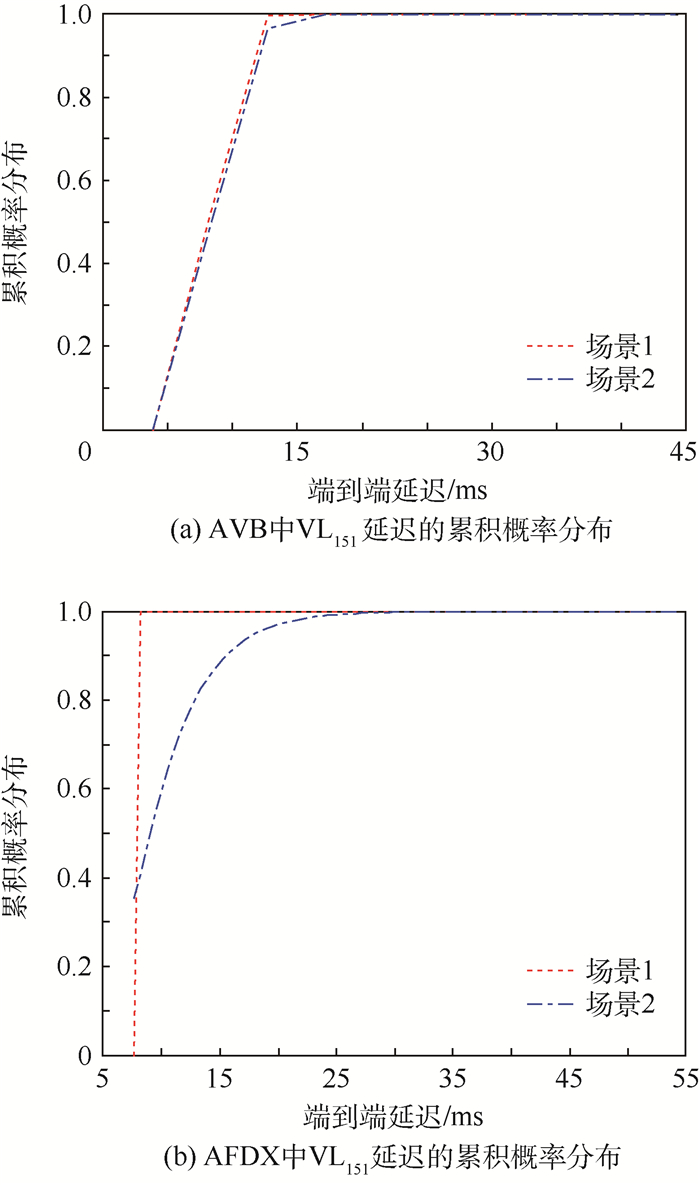
表 4 VL151~350平均端到端延迟对比
Table 4. Comparison of average end-to-end delay for VL151~350
场景 平均端到端延迟/ms AFDX AVB 场景1 19.292 15.053 场景2 21.270 15.831
下载: 导出CSV
表 5 VL851~950平均端到端延迟对比
Table 5. Comparison of average end-to-enddelay for VL851~950
场景 平均端到端延迟/ms AFDX AVB 场景1 2.901 3.561 场景2 2.912 3.570
下载: 导出CSV
-
[1] ARINC 664.Aircraft data network, Part 7:Avionics full duplex switched Ethernet(AFDX)network[S].Annapolis:Aeronautical Radio, 2005:9-18. [2] 蒲小勃.现代航空电子系统与综合[M].北京:航空工业出版社, 2013:55-89.PU X B.Modern avionics system and integration[M].Beijing:Aviation Industry Press, 2013:55-89(in Chinese). [3] IEEE 802.1 AVB Task Group.IEEE 802.1 audio/video bridging (AVB)[EB/OL].(2013-03-20)[2016-04-10]. [4] STEINBACH T, LIM H T, KORF F, et al.Tomorrow's in-car interconnect A competitive evaluation of IEEE 802.1 AVB and time-triggered ethernet(AS6802)[C]//2012 IEEE Vehicular Technology Conference.Piscataway, NJ:IEEE Press, 2012:1-5. [5] ALDERISI G, IANNIZZOTTO G, BELLO L L.Towards 802.1 Ethernet AVB for advanced driver assistance systems:A preliminary assessment[C]//2012 IEEE 17th International Conference on Emerging Technologies and Factory Automation. Piscataway, NJ:IEEE Press, 2012:1-4. [6] ZINNER H, NOEBAUER J, SEITZ J, et al.A comparison of time synchronization in AVB and FlexRay in-vehicle networks[C]//2011 Proceedings of the 9th Workshop on Intelligent Solutions in Embedded Systems. Piscataway, NJ:IEEE Press, 2011:67-72. [7] 熊华钢, 王中华.先进航空电子综合技术[M].北京:国防工业出版社, 2009:85-90.XIONG H G, WANG Z H.Advanced avionics integration techniques[M].Beijing:National Defense Industry Press, 2009:85-90(in Chinese). [8] GEYER F, HEIDINGER E, SCHNEELE S, et al.Evaluation of audio/video bridging forwarding method in avionics switched Ethernet context[C]//2013 IEEE Symposium on Computers and Communications.Piscataway, NJ:IEEE Press, 2013:000711-000716. [9] HEIDINGER E, GEYER F, SCHNEELE S, et al.A performance study of audio video bridging in aeronautic Ethernet networks[C]//7th IEEE International Symposium on Industrial Embedded Systems.Piscataway, NJ:IEEE Press, 2012:67-75. [10] JEON S, LEE J, PARK S.Dual-path method for enhancing the performance of IEEE 802.1 AVB with time-triggered scheme[C]//201521st Asia-Pacific Conference on Communications.Piscataway, NJ:IEEE Press, 2015:519-523. [11] MEYER P, STEINBACH T, KORF F, et al.Extending IEEE 802.1 AVB with time-triggered scheduling:A simulation study of the coexistence of synchronous and asynchronous traffic[C]//IEEE Vehicular Networking Conference.Piscataway, NJ:IEEE Press, 2011:47-54. [12] ALDERISI G, IANNIZZOTTO G, BELLO L L.Simulative assessments of IEEE 802.1 Ethernet AVB and time-triggered Ethernet for advanced driver assistance systems and in-car infotainment[C]//2012 IEEE Vehicular Networking Conference.Piscataway, NJ:IEEE Press, 2012:187-194. [13] 王彤, 赵琳, 何锋.航空电子音视频传输AVB以太网络[J].电光与控制, 2016, 23(1):1-6.WANG T, ZHAO L, HE F.Research on audio video bridging(AVB) for avionics network[J].Electronics Optics & Control, 2016, 23(1):1-6(in Chinese). [14] IEEE.IEEE standard for local and metropolitan area networks, virtual bridged local area networks, Amendment 14:Stream reservation protocol (SRP)[S].New York:IEEE, 2010:1-5. [15] IEEE.IEEE standard for local and metropolitan area networks, virtual bridged local area networks, Amendment 12:Forwarding and queuing enhancements for time-sensitive streams[S].New York:IEEE, 2009:1-17. [16] BOUDEC J Y L.Network calculus:A theory of deterministic queuing systems for the Internet[M].Berlin:Springer, 2001:7-24. [17] CRUZ R L.A calculus for network delay.Part Ⅰ. Network elements in isolation[J].IEEE Transaction on Information Theory, 1991, 37(1):114-131. [18] CRUZ R L. A calculus for network delay. Part Ⅱ. Network analysis[J].IEEE Transaction on Information Theory, 1991, 37(1):132-141. [19] CHANG C S.Performance guarantees in communication networks[M].London:Springer, 2000:4-22. [20] SCHARBARG J L, RIDOUARD F, FRABOUL C.A probabilistic analysis of end-to-end delays on an AFDX avionic network[J]. IEEE Transaction on Industrial Informatics, 2009, 5(1):28-41. [21] BAUER H, SCHARBARG J L, FRABOUL C.Improving the worst-case delay analysis of an AFDX network using an optimized trajectory approach[J].IEEE Transaction on Industrial Information, 2010, 6(4):521-533. [22] MANDERSCHEID M, LANGER F.Network calculus for the validation of automotive Ethernet in-vehicle network configuration[C]//2011 International Conference on Cyber-Enable Distributed Computing and Knowledge Discovery.Piscataway, NJ:IEEE Press, 2011:206-211. [23] BAUER H, SCHARBARG J L, FRABOUL C. Applying trajectory approach to AFDX avionics network[C]//14th Emerging Technologies & Factory Automation.Piscataway, NJ:IEEE Press, 2009:1-8. [24] 代真, 何锋, 张宇静, 等.AFDX虚拟链路路径实时寻优算法[J].航空学报, 2015, 36(6):1924-1932.DAI Z, HE F, ZHANG Y J, et al.Real-time path optimization algorithm of AFDX virtual link[J].Acta Aeronautica et Astronautica Sinica, 2015, 36(6):1924-1932(in Chinese). -

 下载:
下载:





 点击查看大图
点击查看大图

计量
- 文章访问数: 1866
- HTML全文浏览量: 292
- PDF下载量: 676
- 被引次数: 0
