



-
摘要:
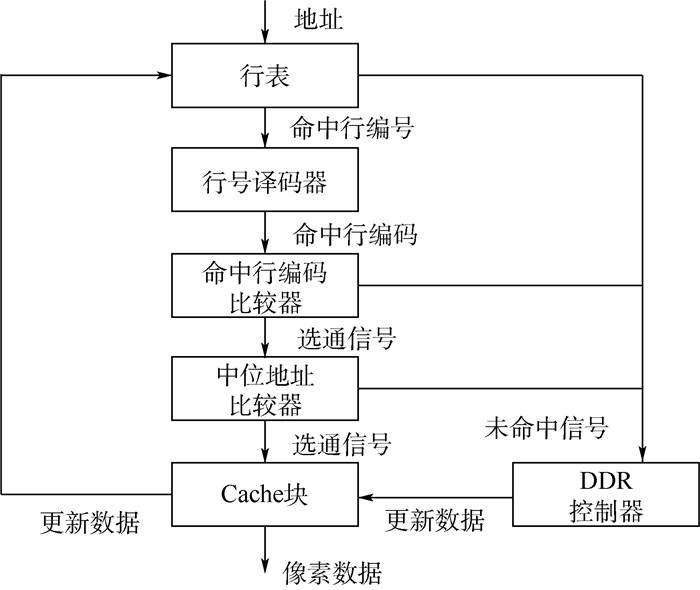
车载平视显示(HUD)系统通过图像翘曲变换将原始平面图像信息显示在挡风玻璃曲面上,原始图像数据的非线性访问会造成存储器访问效率下降。为此,设计了一种高速缓冲存储器(Cache),以最大程度保证像素数据访问的连续性,减少存储器访问次数并提高带宽资源利用率。为优化Cache性能,提出存储空间分离管理技术和地址分级比较技术,提高图像像素在Cache中的存储密度,并节省逻辑资源。此外,提出一种Cache容量动态调整的方法,在保证命中率前提下减少Cache存储资源的使用、降低功耗。实验结果显示,存储空间分离管理技术使存储资源节省25%,地址分级比较技术使逻辑资源节省近10%,Cache容量可以减少75%,且动态功耗减少67.578%,静态功耗减少14.060%。
Abstract:The vehicle head-up display (HUD) system displays the source image plane on the windshield surface by image warping. Non-linear access to source image pixels degrades memory access efficiency. To solve this problem, a Cache is designed to ensure pixel access continuity, reduce memory access numbers and improve bandwidth resource utilization. To optimize the performance of Cache, a storage separation management technology and an address multi-level comparison technology are proposed to improve the storage density of image pixels and save logical resources. In addition, a method for dynamically adjusting the Cache capacity is proposed to reduce storage resource usage and power consumption while ensuring the hit rate. The experimental results show that the storage separation management technology saves storage resources by 25%. The address multi-level comparison technology saves logical resources by nearly 10%. The Cache capacity can be reduced by the dynamic adjusting method by 75%, dynamic power consumption is reduced by 67.578%, and static power consumption is reduced by 14.060%.
-

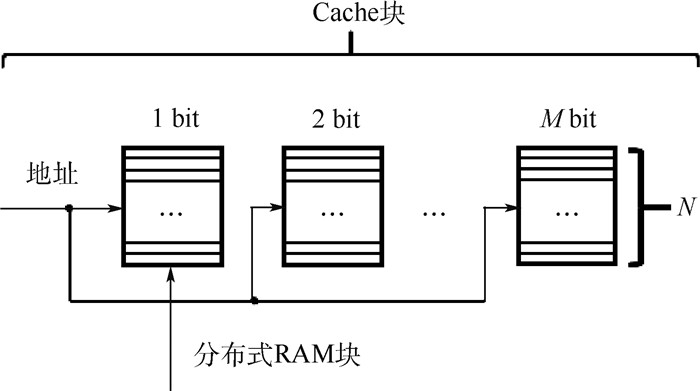
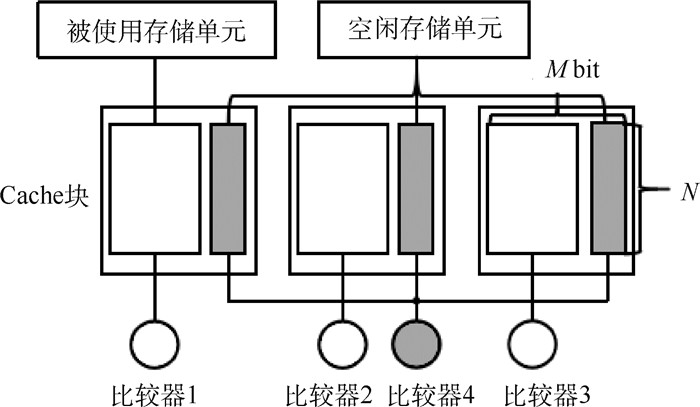
图 3 存储空间分离管理技术示意图
Figure 3. Schematic diagram of storage separation management technology
表 1 Cache容量动态调整技术对实验结果的影响
Table 1. Effect of Cache capacity dynamic adjustment technology on experimental results
Cache块数 命中率/% 动态功耗/W 静态功耗/W 64 98.786 20.076 3.293 32 98.736 11.610 2.988 16 98.716 6.509 2.830 变化量/% -0.071 -67.578 -14.060  下载: 导出CSV
下载: 导出CSV
表 2 存储空间分离管理技术对资源使用情况的影响
Table 2. Effect of storage separation management technology on resource usage
资源 Cache块数 改进前 改进后 变化量/% CLB LUTs 64 5182 6594 27.248 32 2628 2951 12.291 16 1209 1387 14.723 LUTRAM 64 2048 1536 -25.000 32 1024 768 -25.000 16 512 384 -25.000 CLB Registers 64 3743 3242 -13.385 32 1855 1604 -13.531 16 927 807 -12.945
下载: 导出CSV
表 3 地址分级比较技术对资源使用情况的影响
Table 3. Effect of address multi-level comparison technology on resource usage
资源 Cache块数 改进前 改进后 变化量/% CLB LUTs 64 5182 5252 1.351 32 2628 2559 -2.626 16 1209 1217 0.662 CLB Registers 64 3743 3374 -9.858 32 1855 1710 -7.817 16 927 842 -9.169
下载: 导出CSV
-
[1] LEE M, KIM H, PAIK J.Correction of barrel distortion in fisheye lens images using image-based estimation of distortion parameters[J].IEEE Access, 2019, 7:45723-45733. [2] YUAN X, HU C, CHEN J, et al.Correction of capsule endoscope image distortion based on two-dimensional look-up table[C]//Proceeding of the 11th World Congress on Intelligent Control and Automation.Piscataway, NJ: IEEE Press, 2014: 553-557. [3] SHETE P P, MADHUKAR S D, BOSE S K.A real-time stereo rectification of high definition image stream using GPU[C]//2014 International Conference on Advances in Computing, Communications and Informatics (ICACCI).Piscataway, NJ: IEEE Press, 2014: 158-162. [4] MENG G, XIANG S, PAN C, et al.Active rectification of curved document images using structured beams[J].International Journal of Computer Vision, 2017, 122(1):34-60. [5] TAN Z, ZHANG S, WANG R.Stable stitching method for stereoscopic panoramic video[J].CAAI Transactions on Intelligence Technology, 2018, 3(1):1-7. [6] LIN C, TSAI Y M, WANG W, et al.GPU-accelerated high-resolution image stitching with better initial guess[C]//2018 IEEE International Conference on Consumer Electronics(ICCE).Piscataway, NJ: IEEE Press, 2018: 1-3. [7] MELO R, FALCAO G, BARRETO J P.Real-time HD image distortion correction in heterogeneous parallel computing systems using efficient memory access patterns[J].Journal of Real-Time Image Processing, 2016, 11(1):83-91. [8] RYOO J R, LEE E S, PARK H K.Real-time implementation of an LUT-based image warping system[C]//IEEE Intelligence and Safty for Robotics 2013.Piscataway, NJ: IEEE Press, 2013: 1-4. [9] RYOO J R, LEE E S, DOH T Y.An implementation of real-time image warping using FPGA[J].Journal of Embedded Systems & Applications, 2014, 9(6):335-344. [10] LU Y, LUO X, WANG Y, et al.Line buffer reduction for LUT-based real-time image inverse warping[C]//2016 14th IEEE International New Circuits and Systems Conference(NEWCAS).Piscataway, NJ: IEEE Press, 2016: 1-4. [11] GREISEN P, HEINZLE S, GROSS M, et al.An FPGA-based processing pipeline for high-definition stereo video[J].EURASIP Journal on Image & Video Processing, 2011, 2011:18. [12] JOON C Y, RAE R J.Image Cache for FPGA-based real-time image warping[J].Journal of the Institute of Electronics and Information Engineers, 2016, 53(6):91-100. [13] HAN X, CHEN S L, WU L, et al.Design and verification of distributed RAM using look-up tables in an SOI-based FPGA[C]//2010 10th IEEE International Conference on Solid-State and Integrated Circuit Technology.Piscataway, NJ: IEEE Press, 2010: 306-308. [14] PENG M, LIU X.Adaptive rapid reconfigurable algorithm for low power Cache[C]//International Conference on Computational & Information Sciences.Piscataway, NJ: IEEE Press, 2013: 203-206. [15] UPADHYAY B R, SUDARSHAN T S B.Low power predictive placement Cache scheme for embedded system[C]//2014 International Conference on Embedded Systems(ICES).Piscataway, NJ: IEEE Press, 2014: 250-254. [16] KUMAR S, SINGH P K.An overview of modern Cache memory and performance analysis of replacement policies[C]//2016 IEEE International Conference on Engineering and Technology(ICETECH).Piscataway, NJ: IEEE Press, 2016: 210-214. [17] 杜建海, 吕江花, 高世伟, 等.面向航天器综合测试系统的Web缓存替换策略[J].北京航空航天大学学报, 2018, 44(8):1609-1619.DU J H, LYU J H, GAO S W, et al.A Web Cache replacement strategy for spacecraft comprehensive testing system[J].Journal of Beijing University of Aeronautics and Astronautics, 2018, 44(8):1609-1619(in Chinese). -

 下载:
下载:

 点击查看大图
点击查看大图

计量
- 文章访问数: 1046
- HTML全文浏览量: 210
- PDF下载量: 152
- 被引次数: 0
