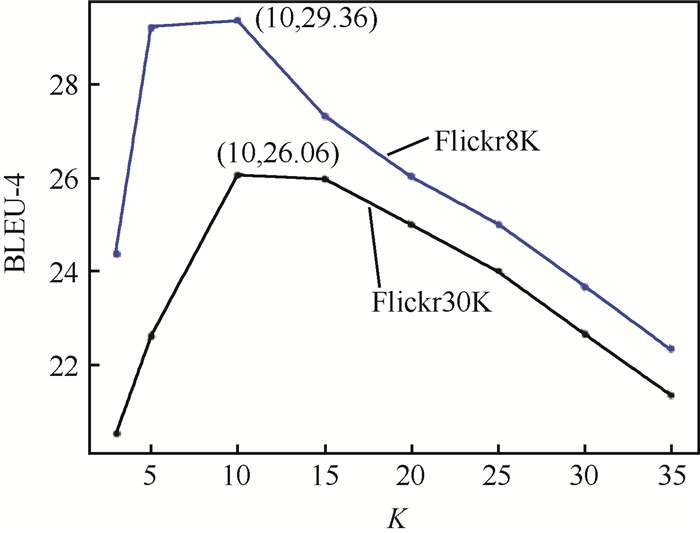
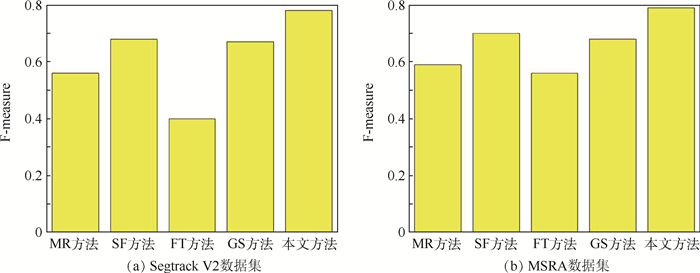
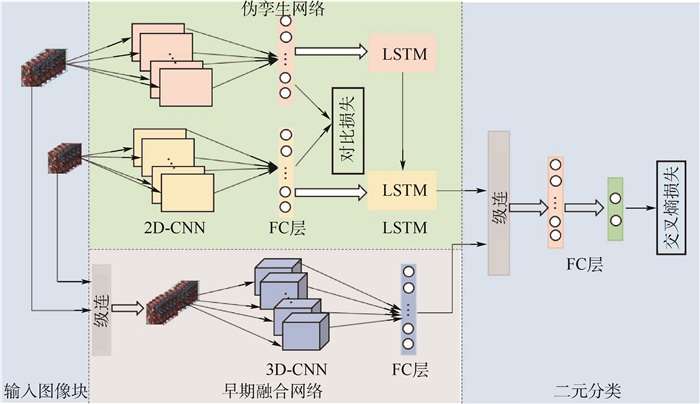
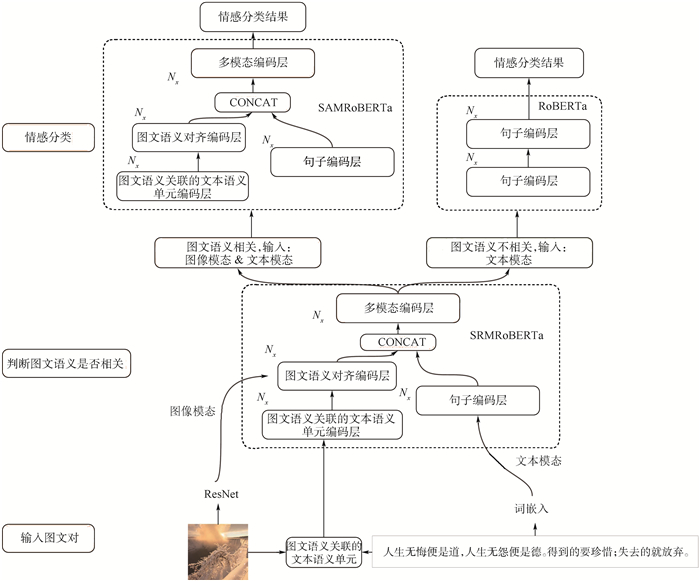
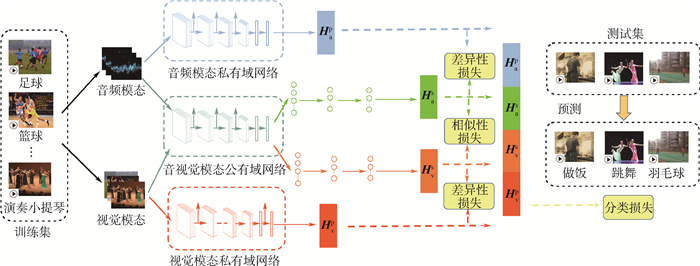
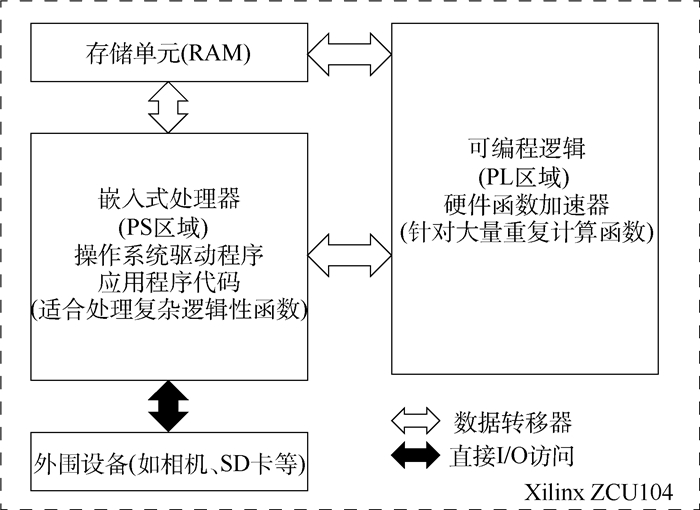
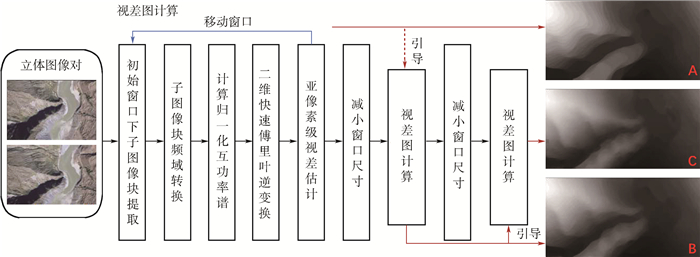
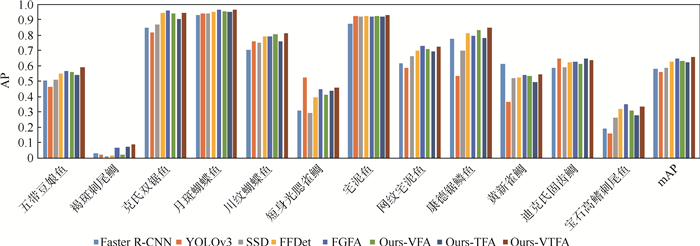
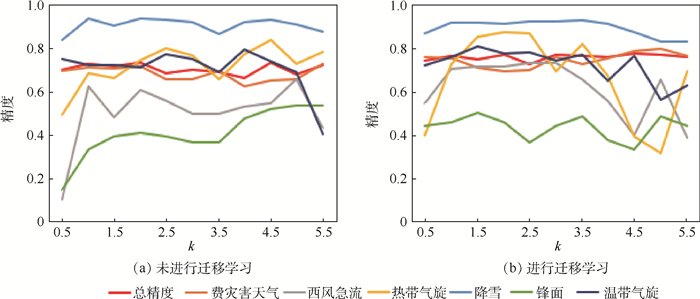
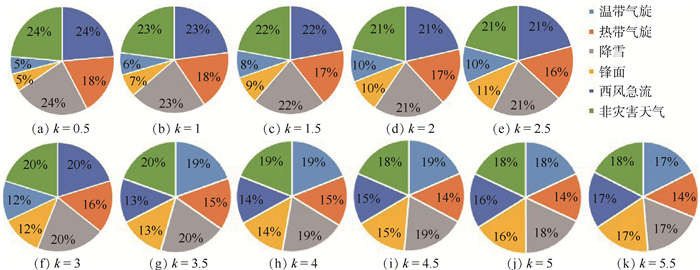
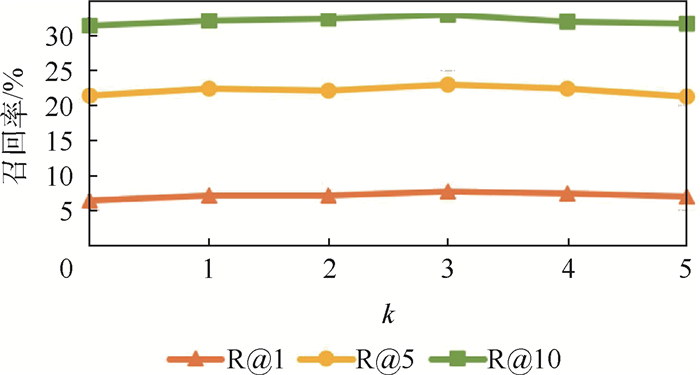
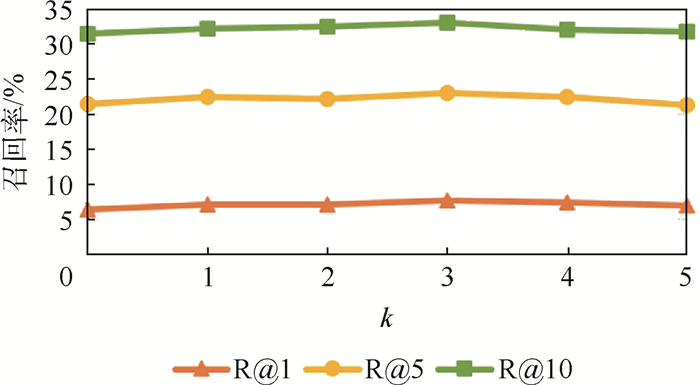
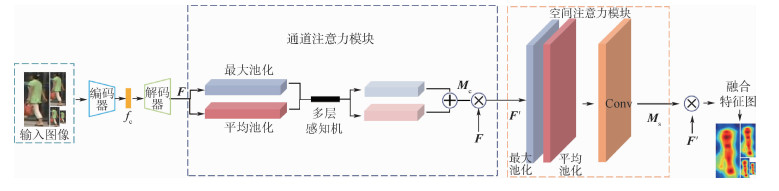
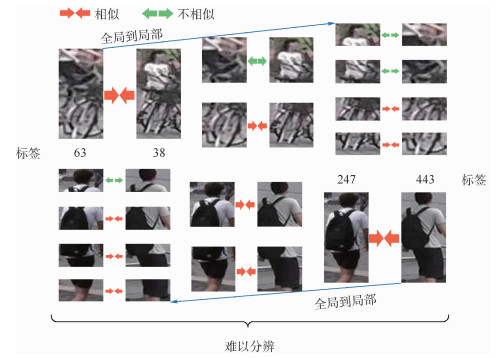
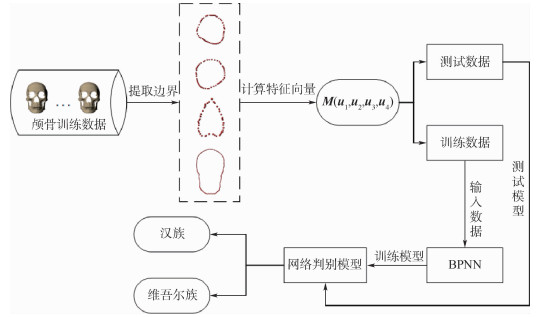
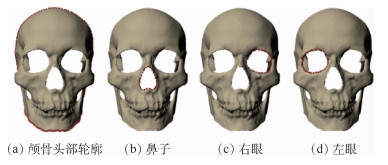
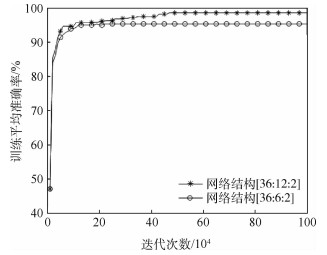
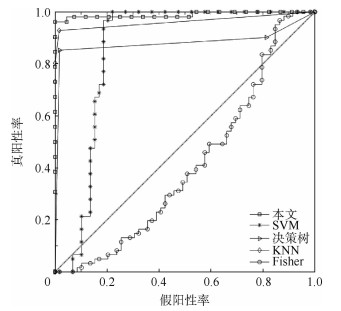
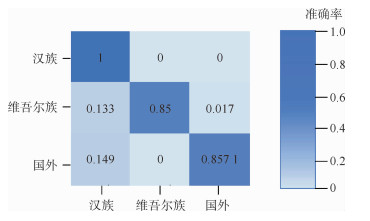
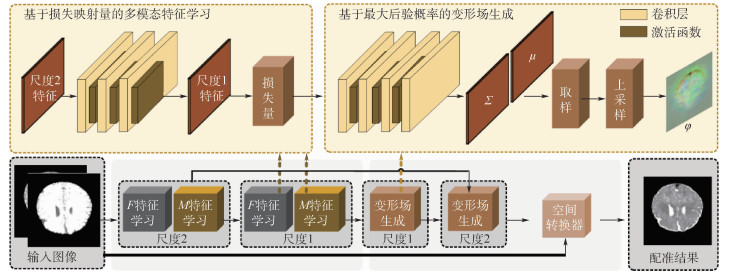
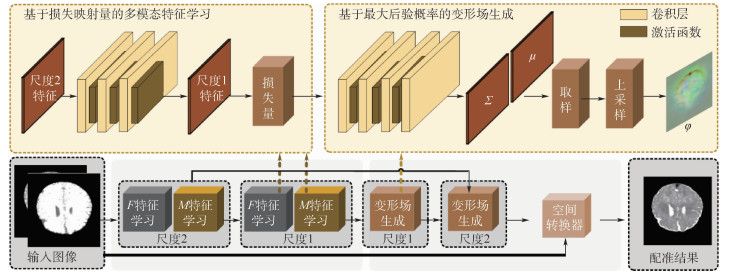
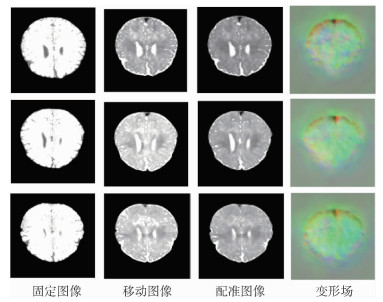
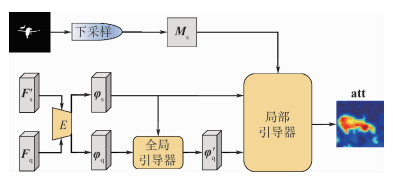
China is a multi-ethnic country. It is of great significance for the skull identification to realize the skull ethnic identification through computers, which can promote the development of forensic anthropology and exploration of national development. Firstly, according to the skull morphology studies, 36 Uighur and Han geometric features of the skull data are extracted, and the Back-Propagation Neural Network (BPNN) of feature vectors is used for ethnic identification. In order to optimize the network, Adam algorithm is adopted to avoid falling into local minimum, and to ensure the stability of the algorithm with regularization terms. Two network structures are used for comparative experiments. The number of neurons in the input layer, hidden layer and output layer are 36, 6, 2 and 36, 12, 2, respectively, and different initial learning rates are set for comparative experiments. The results show that, when the number of hidden-layer neurons is 12 and the learning rate is 0.000 1, the classification accuracy is the highest and the highest accuracy rate in the test stage is 97.5%. In order to verify the universality of the method in this paper, 116 foreign skull data are generated for experiments, and the accuracy rate of the test stage is 90.96%. Compared with machine learning methods such as Support Vector Machine (SVM), decision-making tree, KNN, and Fisher, the proposed method has stronger learning ability and significantly improved classification accuracy.


 Download (80967)
Download (80967) 
 Views
Views  Cited by
Cited by 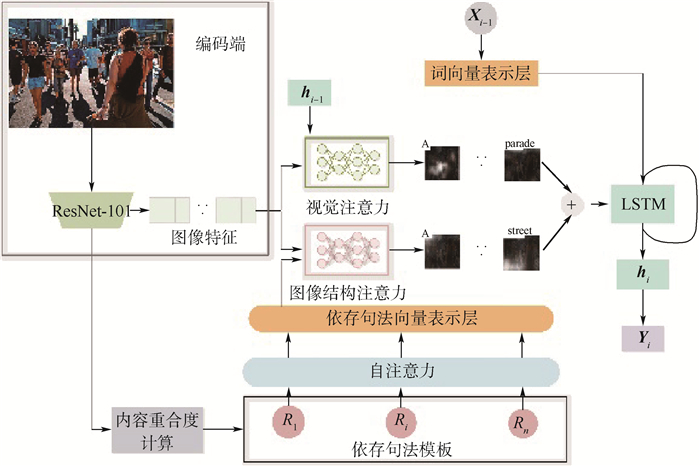





































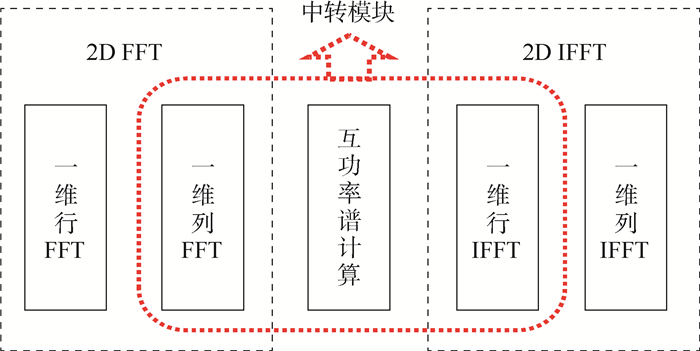


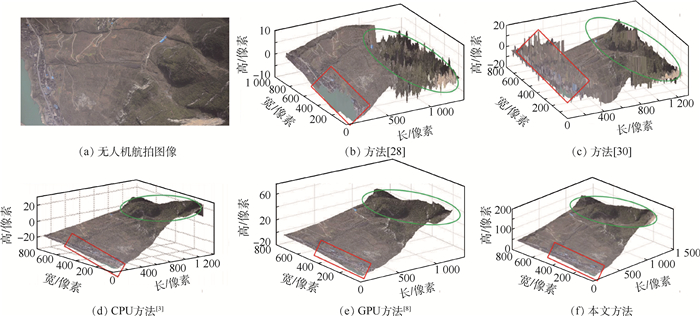


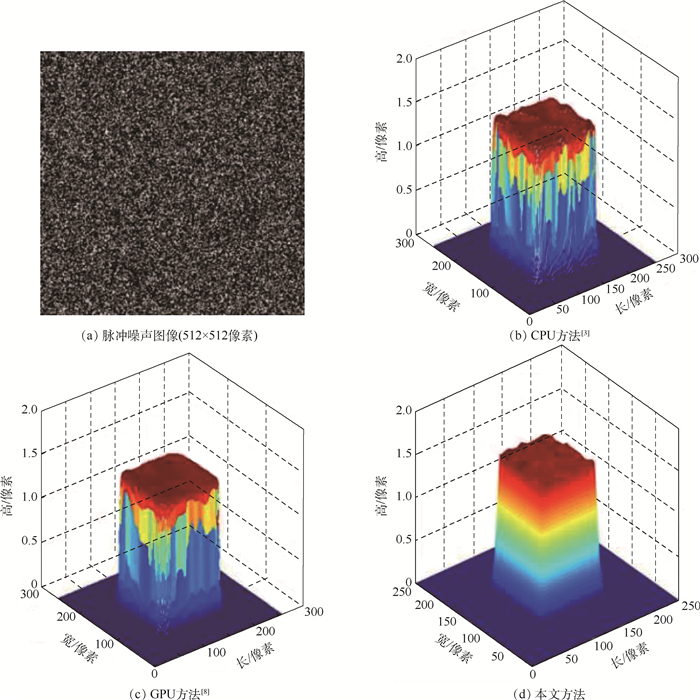
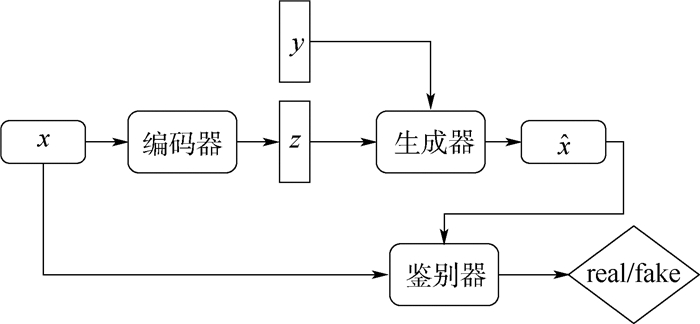









































































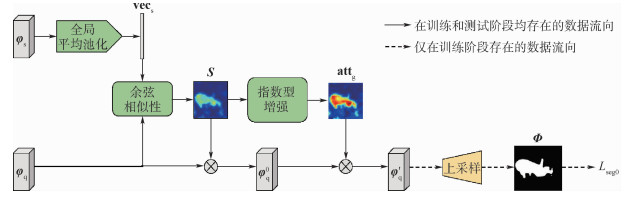
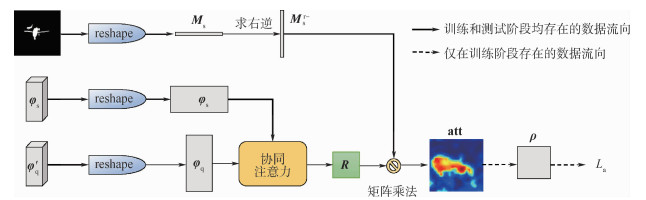
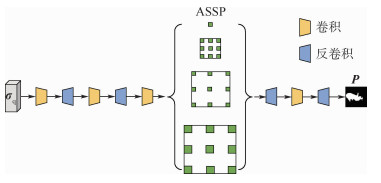






 XML Online Production Platform
XML Online Production Platform
