



Maneuvering decision in air combat based on multi-objective optimization and reinforcement learning
-
摘要:
为了解决无人机自主空战中的机动决策问题,提出了一种将优化思想与机器学习相结合的机动决策模型。采用多目标优化方法作为决策模型核心,既解决了传统优化方法需要为多个优化目标设置权重的困难,又提高了决策模型的可拓展性;同时在多目标优化的基础上通过强化学习方法训练评价网络进行辅助决策,解决了决策模型在对抗时博弈性不足的缺点。为了测试决策模型的性能,以近距空战为背景,设计了3组仿真实验分别验证多目标优化方法的可行性、辅助决策网络的有效性以及决策模型的总体性能,仿真结果表明,决策模型可以对有机动的敌机进行有效的实时机动对抗。
Abstract:To solve the problem of maneuvering decision in the autonomous air combat of unmanned combat aerial vehicle, the existing research achievements are analyzed and a maneuvering decision model that combines optimization idea with machine learning is proposed. The multi-objective optimization method is used as the core of decision model, which solves the problem of setting weight for multiple optimization targets and improves the extensibility of decision model. On the basis of multi-objective optimization, an evaluation network is trained by reinforcement learning and used for auxiliary decision-making to enhance the antagonism of decision model. In order to test the performance of decision model, with the background of short-range air combat, three simulation experiments are designed to test the feasibility of multi-objective optimization method, the effectiveness of auxiliary decision network and the overall performance of decision model. The simulation results show that the maneuvering decision model can be used in real-time confrontation with the maneuvering enemy aircraft.
-

图 3 多目标优化机动决策模型结构
Figure 3. Structure of multi-objective optimization modelfor maneuver decision

图 10 态势关系与控制量(初始有利)
Figure 10. Situation relationship and control quantity (favorable initial conditions)

图 12 态势关系与控制量(初始不利)
Figure 12. Situation relationship and control quantity (adverse initial conditions)
表 1 对抗仿真结果(使用辅助网络一方)
Table 1. Confrontation simulation results (the side with auxiliary network)
初始条件 获胜 平局 失败 初始有利 59 41 0 初始均势 32 51 17 初始不利 11 39 50  下载: 导出CSV
下载: 导出CSV
-
[1] 黄长强, 唐上钦.从"阿法狗"到"阿法鹰"——论无人作战飞机智能自主空战技术[J].指挥与控制学报, 2016, 2(3):261-264. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=zhykzxb201603015HUANG C Q, TANG S Q.From Alphago to Alphaeagle:On the intelligent autonomous air combat technology for UCAV[J].Journal of Command and Control, 2016, 2(3):261-264(in Chinese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=zhykzxb201603015 [2] 朱可钦, 董彦非.空战机动动作库设计方式研究[J].航空计算技术, 2001, 31(4):50-52. doi: 10.3969/j.issn.1671-654X.2001.04.015ZHU K Q, DONG Y F.Study on the design of air combat maneuver library[J].Aeronautical Computer Technique, 2001, 31(4):50-52(in Chinese). doi: 10.3969/j.issn.1671-654X.2001.04.015 [3] 钟友武, 柳嘉润, 杨凌宇, 等.自主近距空战中机动动作库及其综合控制系统[J].航空学报, 2008, 29(s1):114-121. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=QK200802359566ZHONG Y W, LIU J R, YANG L Y, et al.Maneuver library and integrated control system for autonomous close-in air combat[J].Acta Aeronautica et Astronautica Sinica, 2008, 29(s1):114-121(in Chinese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=QK200802359566 [4] 钟友武, 柳嘉润, 申功璋.自主近距空战中敌机的战术动作识别方法[J].北京航空航天大学学报, 2007, 33(9):1056-1059. doi: 10.3969/j.issn.1001-5965.2007.09.013ZHONG Y W, LIU J R, SHEN G Z.Recognition method for tactical maneuver of target in autonomous close-in air combat[J].Journal of Beijing University of Aeronautics and Astronautics, 2007, 33(9):1056-1059(in Chinese). doi: 10.3969/j.issn.1001-5965.2007.09.013 [5] 张涛, 于雷, 周中良, 等.基于混合算法的空战机动决策[J].系统工程与电子技术, 2013, 35(7):1445-1450. http://d.old.wanfangdata.com.cn/Periodical/xtgcydzjs201307015ZHANG T, YU L, ZHOU Z L, et al.Decision-making for air combat maneuvering based on hybrid algorithm[J].Systems Engineering and Electronics, 2013, 35(7):1445-1450(in Chinese). http://d.old.wanfangdata.com.cn/Periodical/xtgcydzjs201307015 [6] SU M C, LAI S C, LIN S C, et al.A new approach to multi-aircraft air combat assignments[J].Swarm & Evolutionary Computation, 2012, 6:39-46. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=69c344d70fce5fdafa94cb4667a76be1 [7] 冯超, 景小宁, 李秋妮, 等.基于隐马尔可夫模型的空战决策点理论研究[J].北京航空航天大学学报, 2017, 43(3):615-626. http://bhxb.buaa.edu.cn/CN/abstract/abstract14135.shtmlFENG C, JING X N, LI Q N, et al.Theoretical research of decision-making point in air combat based on hidden Markov model[J].Journal of Beijing University of Aeronautics and Astronautics, 2017, 43(3):615-626(in Chinese). http://bhxb.buaa.edu.cn/CN/abstract/abstract14135.shtml [8] 张彬超, 寇雅楠, 邬蒙, 等.基于深度置信网络的近距空战态势评估[J].北京航空航天大学学报, 2017, 43(7):1450-1459. http://bhxb.buaa.edu.cn/CN/abstract/abstract14334.shtmlZHANG B C, KOU Y N, WU M, et al.Close-range air combat situation assessment using deep belief network[J].Journal of Beijing University of Aeronautics and Astronautics, 2017, 43(7):1450-1459(in Chinese). http://bhxb.buaa.edu.cn/CN/abstract/abstract14334.shtml [9] 左家亮, 杨任农, 张滢, 等.基于启发式强化学习的空战机动智能决策[J].航空学报, 2017, 38(10):321168. http://d.old.wanfangdata.com.cn/Periodical/hkxb201710021ZUO J L, YANG R N, ZHANG Y, et al.Intelligent decision-making in air combat maneuvering based on heuristic reinforcement learning[J].Acta Aeronautica et Astronautica Sinica, 2017, 38(10):321168(in Chinese). http://d.old.wanfangdata.com.cn/Periodical/hkxb201710021 [10] PARETO V.Cours d'economie politique[M].Lausanne, Paris:F.Rouge, 1896. [11] 国海峰, 侯满义, 张庆杰, 等.基于统计学原理的无人作战飞机鲁棒机动决策[J].兵工学报, 2017, 38(1):160-167. doi: 10.3969/j.issn.1000-1093.2017.01.021GUO H F, HOU M Y, ZHANG Q J, et al.UCAV robust maneuver decision based on statistics principle[J].Acta Armamentarii, 2017, 38(1):160-167(in Chinese). doi: 10.3969/j.issn.1000-1093.2017.01.021 [12] HUANG C, DONG K, HUANG H, et al.Autonomous air combat maneuver decision using Bayesian inference and moving horizon optimization[J].Journal of Systems Engineering and Electro-nics, 2018, 29(1):86-97. http://d.old.wanfangdata.com.cn/Periodical/xtgcydzjs-e201801009 [13] VEERASAMY N.A high-level mapping of cyberterrorism to the OODA loop[C]//Proceedings of 5th European Conference on Information Management and Evaluation.Red Hook, NY: Cu-rren Associates Inc., 2011: 352-360. [14] MIRJALILI S, SAREMI S, MIRJALILI S M, et al.Multi-objective grey wolf optimizer:A novel algorithm for multi-criterion optimization[J].Expert Systems with Applications, 2016, 47:106-119. doi: 10.1016/j.eswa.2015.10.039 [15] 崔明朗, 杜海文, 魏政磊, 等.多目标灰狼优化算法的改进策略研究[J].计算机工程与应用, 2018, 54(5):156-164. http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jsjgcyyy201805025CUI M L, DU H W, WEI Z L, et al.Research on improved stra-tegy for multi-objective grey wolf optimizer[J].Computer Engineering and Applications, 2018, 54(5):156-164(in Chinese). http://www.wanfangdata.com.cn/details/detail.do?_type=perio&id=jsjgcyyy201805025 [16] 马耀飞, 龚光红, 彭晓源.基于强化学习的航空兵认知行为模型[J].北京航空航天大学学报, 2010, 36(4):379-383. http://bhxb.buaa.edu.cn/CN/abstract/abstract8461.shtmlMA Y F, GONG G H, PENG X Y.Cognition behavior model for air combat based on reinforcement learning[J].Journal of Beijing University of Aeronautics and Astronautics, 2010, 36(4):379-383(in Chinese). http://bhxb.buaa.edu.cn/CN/abstract/abstract8461.shtml [17] BOUZY B, CHASLOT G.Monte-Carlo go reinforcement learning experiments[C]//2006 IEEE Symposium on Computational Intelligence and Games.Piscataway, NJ: IEEE Press, 2007: 187-194. [18] 左磊.基于值函数逼近与状态空间分解的增强学习方法研究[D].长沙: 国防科学技术大学, 2011. http://cdmd.cnki.com.cn/Article/CDMD-90002-1012020425.htmZUO L.Research on reinforcement learning based on value function approximation and state space decomposition[D].Changsha: National University of Defense Technology, 2011(in Chinese). http://cdmd.cnki.com.cn/Article/CDMD-90002-1012020425.htm [19] HORNIK K, STINCHCOMBE M, WHITE H.Multilayer feedforward networks are universal approximators[J].Neural Networks, 1989, 2(5):359-366. doi: 10.1016/0893-6080(89)90020-8 [20] SUTTON R S.Learning to predict by the method of temporal differences[J].Machine Learning, 1988, 3(1):9-44. http://d.old.wanfangdata.com.cn/OAPaper/oai_arXiv.org_1110.2416 [21] WILLIAMS P.Three-dimensional aircraft terrain-following via real-time optimal control[J].Journal of Guidance, Control and Dynamics, 2007, 30(4):1201-1206. doi: 10.2514/1.29145 [22] WILLIAMS P.Aircraft trajectory planning for terrain following incorporating actuator constraints[J].Journal of Aircraft, 2005, 42(5):1358-1361. doi: 10.2514/1.17811 -

 下载:
下载:



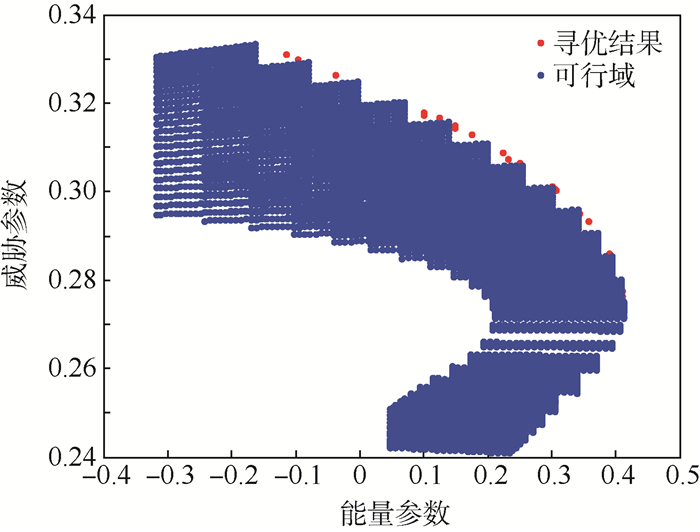
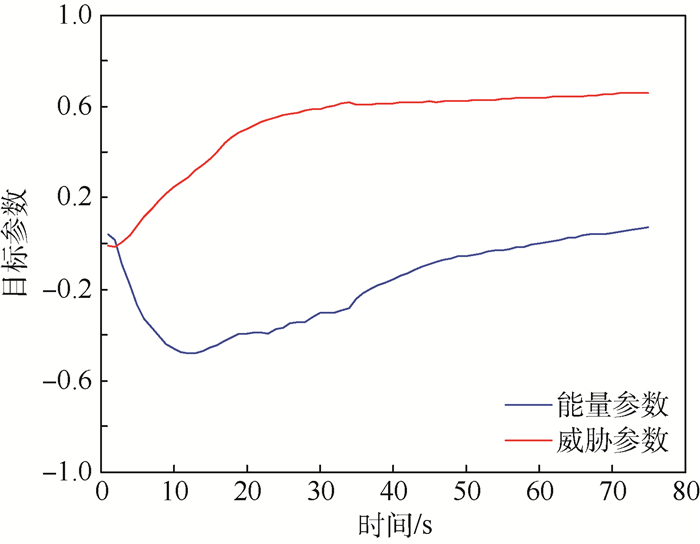
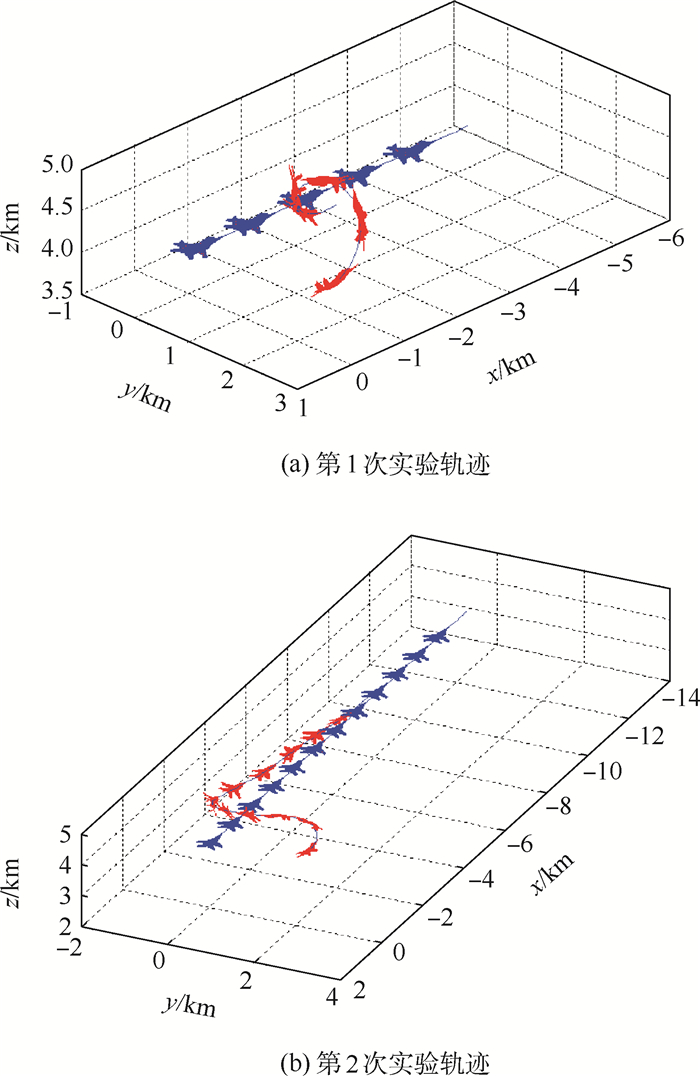






 点击查看大图
点击查看大图
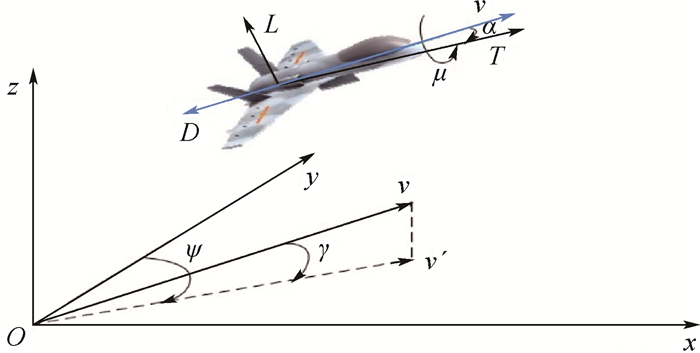
计量
- 文章访问数: 1313
- HTML全文浏览量: 127
- PDF下载量: 1471
- 被引次数: 0
