



-
摘要:
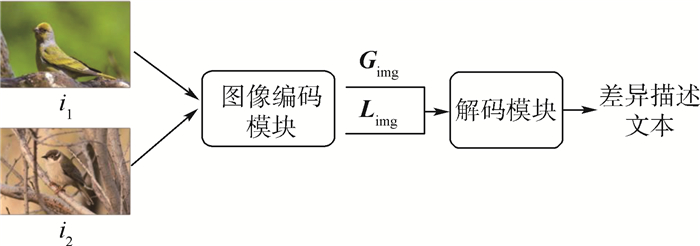
图像描述生成任务要求机器自动生成自然语言文本来描述图像所呈现的语义内容,从而将视觉信息转化为文本描述,便于对图像进行管理、检索、分类等工作。图像差异描述生成是图像描述生成任务的延伸,其难点在于如何确定2张图像之间的视觉语义差别,并将视觉差异信息转换成对应的文本描述。基于此,提出了一种引入文本信息辅助训练的模型框架TA-IDC。采取多任务学习的方法,在传统的编码器-解码器结构上增加文本编码器,在训练阶段通过文本辅助解码和混合解码2种方法引入文本信息,建模视觉和文本2个模态间的语义关联,以获得高质量的图像差别描述。实验证明,TA-IDC模型在3个图像差异描述数据集上的主要指标分别超越已有模型最佳结果12%、2%和3%。
Abstract:The image captioning task requires the machine to automatically generate natural language text to describe the semantic content of the image, thus transforming visual information into textual descriptions that facilitate image management, retrieval, classification, and other tasks. Image difference captioning is an extension of the image captioning task, which requires generating natural language sentences to describe the differences between two similar images. The difficulty of this task is how to determine the visual semantic difference between two images and convert the visual difference information into the corresponding textual descriptions. Previous studies do not make full use of textual information in the training stage to model cross-modal semantic associations between visual difference information and text. In this regard, the proposed framework named TA-IDC uses textual information to assist training. It adopts a multi-task learning method, adding a text encoder to the encoder-decoder structure and introducing textual information by text-assisted decoding and mixed decoding during the training stage. This aids in the modeling of semantic relationships between visual and text modalities, resulting in more accurate picture difference captions. Experimentally, TA-IDC outperforms the best results of existing models on main metricsby 12%, 2%, and 3% on three image difference caption datasets, respectively.
-
表 1 图像差异描述相关工作
Table 1. Related work of image difference captioning
模型 数据集 模型介绍 [1] Spot-the-diff 提出一个基于预先提取的物体级别差异特征的模型,其对复杂变化、细微变化和多处变化的描述效果欠佳 [2] Spot-the-diff、Image Editing Request 提出一个基于动态相关注意力机制的模型,其对复杂变化描述效果欠佳,且存在描述语句不流畅的问题 [3] Birds-to-Words 提出基于Transformer结构的差异描述模型,其存在描述不存在的差异、描述差异错误的问题 [13] Birds-to-Words 结合使用语义分割模型和图卷积神经网络描述图像差异,并引入额外的单图描述数据进行增强,整体模型结构复杂,参数量大训练时间长,且只在一个图像差异数据集上进行了实验  下载: 导出CSV
下载: 导出CSV
表 2 数据集统计信息
Table 2. The statistics of datasets
数据集参数 Spot-the-diff Image EditingRequest Birds-to-Words 训练集大小 17 676 3 053 12 805 验证集大小 3 310 381 1 556 测试集大小 1 270 493 337 图片数量 39 232 11 121 3 520 词汇量 2 060 2 460 2 634 词语/句子 10.96 7.50 32.10 句子/标注 2.60 图像差异类型 局部 全局、局部 局部、细粒度
下载: 导出CSV
表 3 图像特征交互方式实验结果
Table 3. Experimental results of image feature interaction
数据集 特征交互方式 BLEU-4 METEOR ROUGE-L CIDEr 相连 0.092 0.129 0.319 0.383 Spot-the-diff 相减 0.070 0.117 0.278 0.271 混合 0.090 0.130 0.327 0.366 相连 0.042 0.129 0.355 0.181 Image Editing Request 相减 0.060 0.128 0.355 0.234 混合 0.056 0.142 0.401 0.222 相连 0.242 0.228 0.468 0.133 Birds-to-Words 相减 0.279 0.216 0.467 0.102 混合 0.230 0.229 0.468 0.156
下载: 导出CSV
表 4 与SOTA对比实验结果
Table 4. Experimental results of comparison with SOTA
数据集 模型 BLEU-4 METEOR ROUGE-L CIDEr Spot-the-diff DDLA-single 0.085 0.120 0.286 0.328 DDLA-multi 0.062 0.108 0.260 0.297 Relational Speaker 0.081 0.122 0.314 0.353 TA-IDC 0.106 0.129 0.339 0.475 数据集 模型 BLEU-4 METEOR ROUGE-L CIDEr Image Editing Request Relational Speaker 0.067 0.128 0.373 0.264 TA-IDC 0.035 0.150 0.426 0.216 数据集 模型 BLEU-4 METEOR ROUGE-L CIDEr Birds-to-Words Neural Naturalist 0.220 0.430 0.250 L2C 0.318 0.456 0.163 TA-IDC 0.278 0.231 0.481 0.223
下载: 导出CSV
表 5 消融实验结果
Table 5. Experimental results of Ablation study
模型 Spot-the-diff Image Editing Request Birds-to-Words BLEU-4 METEOR ROUGE-L CIDEr BLEU-4 METEOR ROUGE-L CIDEr BLEU-4 METEOR ROUGE-L CIDEr 基线 0.092 0.129 0.319 0.383 0.056 0.142 0.401 0.222 0.230 0.229 0.468 0.156 TA-IDC (T/T) 0.105 0.131 0.327 0.416 0.047 0.147 0.418 0.221 0.245 0.224 0.472 0.112 TA-IDC (I/T) 0.110 0.133 0.335 0.425 0.035 0.150 0.426 0.216 0.260 0.228 0.477 0.172 TA-IDC (T/I) 0.106 0.129 0.339 0.475 0.070 0.145 0.376 0.216 0.278 0.231 0.481 0.223 TA-IDC (I/T+T/I) 0.102 0.123 0.326 0.430 0.042 0.149 0.413 0.208 0.253 0.219 0.470 0.147
下载: 导出CSV
-
[1] JHAMTANI H, BERG-KIRKPATRICK T. Learning to describe differences between pairs of similar images[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018: 4024-4034. [2] TAN H, DERNONCOURT F, LIN Z. Expressing visual relationships via language[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019: 1873-1883. [3] FORBES M, KAESER-CHEN C, SHARMA P, et al. Neural naturalist: Generating fine-grained image comparisons[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, 2019: 708-717. [4] 苗益, 赵增顺, 杨雨露, 等. 图像描述技术综述[J]. 计算机科学, 2020, 47(12): 149-160. https://www.cnki.com.cn/Article/CJFDTOTAL-JSJA202012022.htmMIAO Y, ZHAO Z S, YANG Y L, et al. Survey of image captioning methods[J]. Computer Science, 2020, 47(12): 149-160(in Chinese). https://www.cnki.com.cn/Article/CJFDTOTAL-JSJA202012022.htm [5] HOSSAIN M Z, SOHEL F, SHIRATUDDIN M F, et al. A comprehensive survey of deep learning for image captioning[J]. ACM Computing Surveys, 2019, 51(6): 1-36. [6] VINYALS O, TOSHEV A, BENGIO S, et al. Show and tell: A neural image caption generator[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2015: 3156-3164. [7] JIA X, GAVVES E, FERNANDO B, et al. Guiding the long-short term memory model for image caption generation[C]//Proceedings of 2016 IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2016: 2407-2415. [8] WU J, CHEN T, WU H, et al. Fine-grained image captioning with global-local discriminative objective[J]. IEEE Transactions on Multimedia, 2020, 23: 2413-2427. [9] XU K, BA J, KIROS R, et al. Show, attend and tell: Neural image caption generation with visual attention[C]//Proceedings of the 32nd International Conference on Machine Learning. New York: ACM, 2015: 2048-2057. [10] LU J, XIONG C, PARIKH D, et al. Knowing when to look: Adaptive attention via a visual sentinel for image captioning[C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 3242-3250. [11] MING J, HUANG S, DUAN J, et al. SALICON: Saliency in context[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2015: 1072-1080. [12] PEDERSOLI M, LUCAS T, SCHMID C, et al. Areas of attention for image captioning[C]//Proceedings of 2017 IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2017: 1251-1259. [13] YAN A, WANG X, FU T, et al. L2C: Describing visual differences needs semantic understanding of individuals[C]//Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics, 2021: 2315-2320. [14] CHO K, MERRIËNBOER B, GULCEHRE C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, 2014: 1724-1734. [15] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 770-778. [16] MA S, SUN X, LIN J, et al. Autoencoder as assistant supervisor: Improving text representation for Chinese social media text summarization[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, 2018: 725-731. [17] PAPINENI K, ROUKOS S, WARD T, et al. BLEU: A method for automatic evaluation of machine translation[C]//Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, 2002: 311-318. [18] LIN C Y. ROUGE: A package for automatic evaluation of summaries[C]//Proceedings of the Workshop on Text Summarization Branches Out, 2004: 74-81. [19] BANERJEE S, LAVIE A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments[C]//Proceedings of the ACL workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, 2005: 65-72. [20] VEDANTAM R, ZITNICK C L, PARIKH D. CIDEr: Consensus-based image description evaluation[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2015: 4566-4575. [21] DENG J, DONG W, SOCHER R, et al. ImageNet: A large-scale hierarchical image database//Proceedings of 2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2009: 248-255. -

 下载:
下载:





 点击查看大图
点击查看大图

计量
- 文章访问数: 317
- HTML全文浏览量: 87
- PDF下载量: 25
- 被引次数: 0
