


2022年 第48卷 第8期

 下载 (90388)
下载 (90388) 
 浏览量
浏览量
 施引文献
施引文献 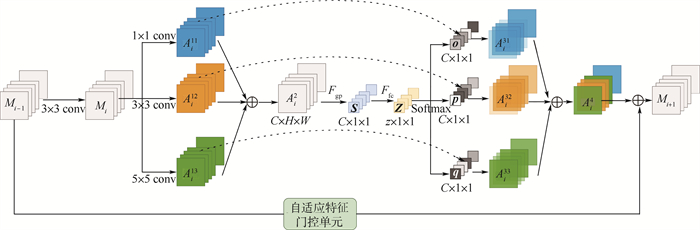



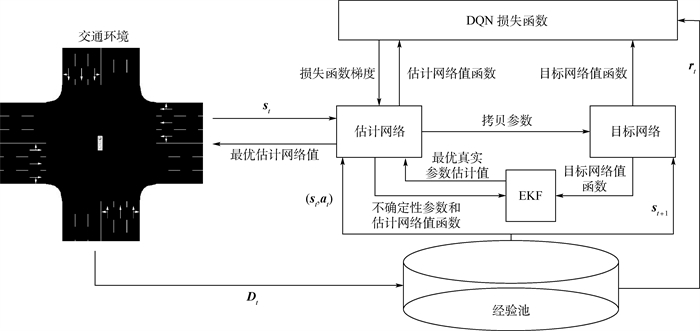
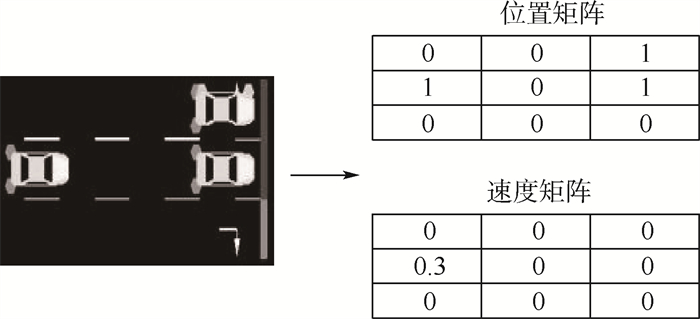
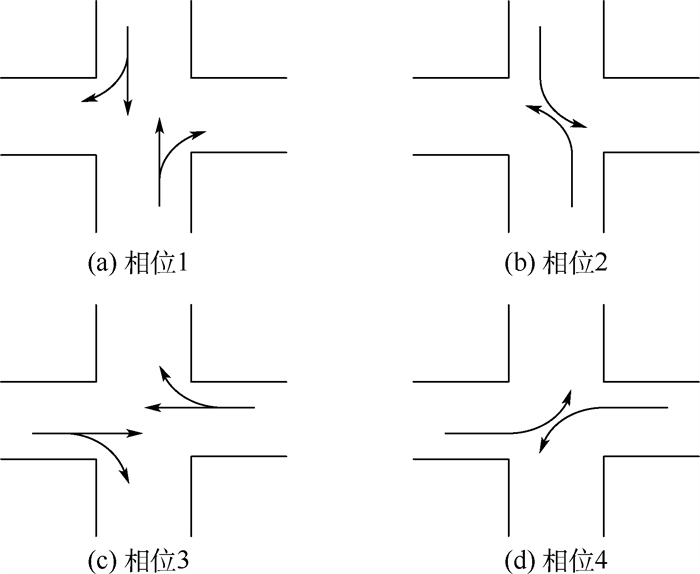
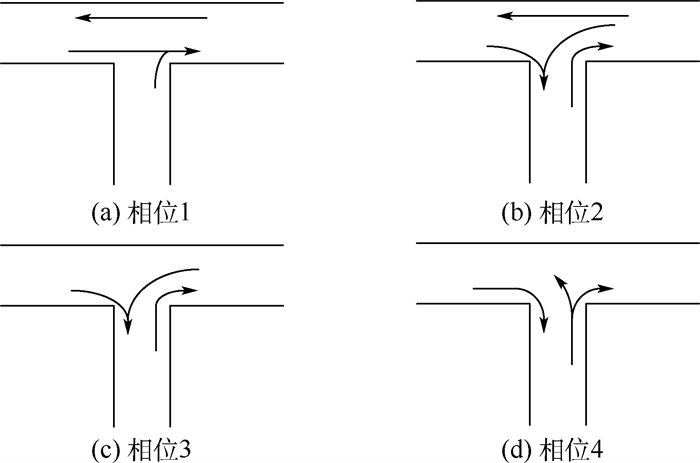

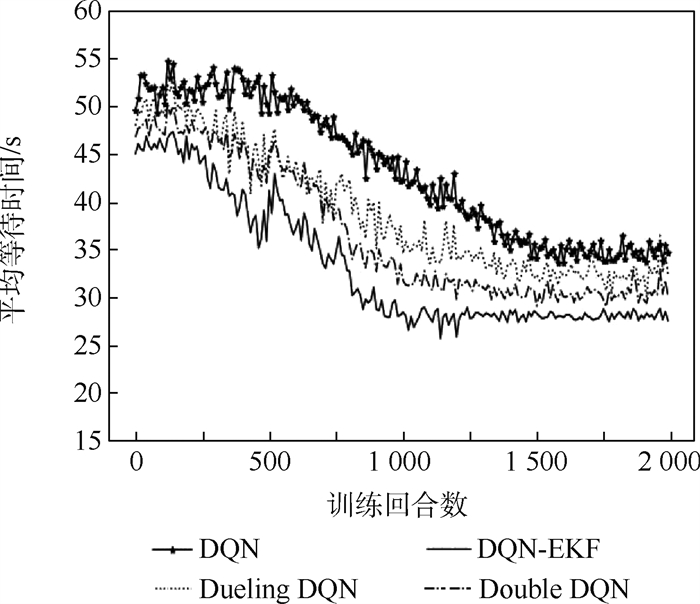


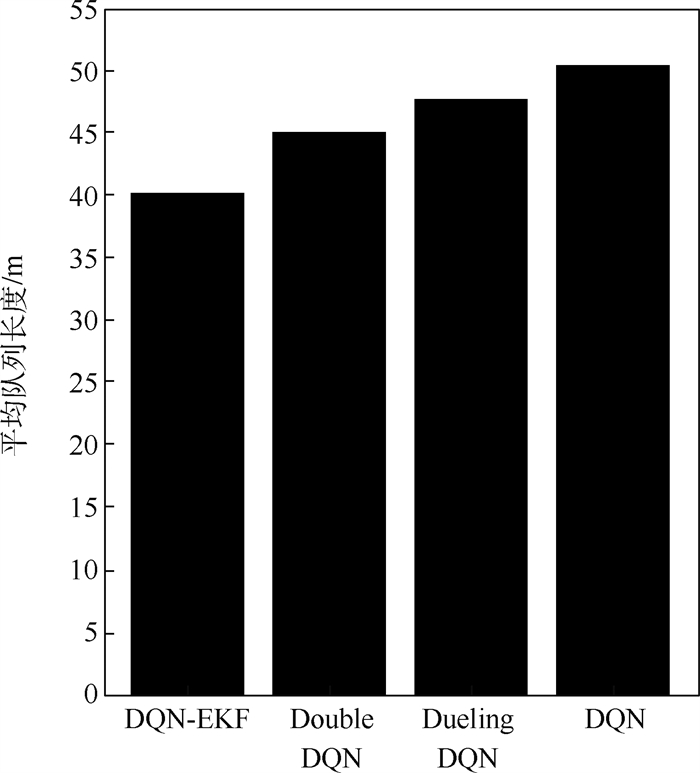



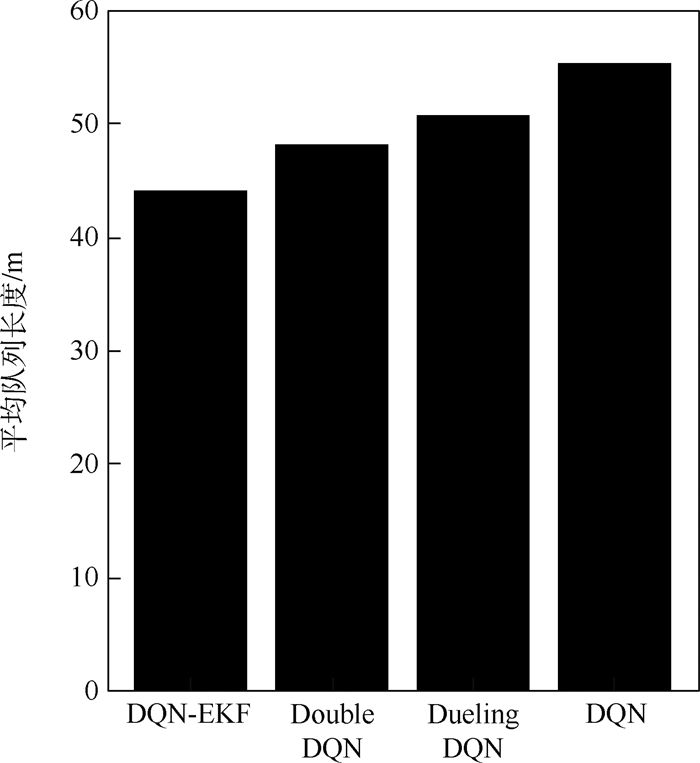

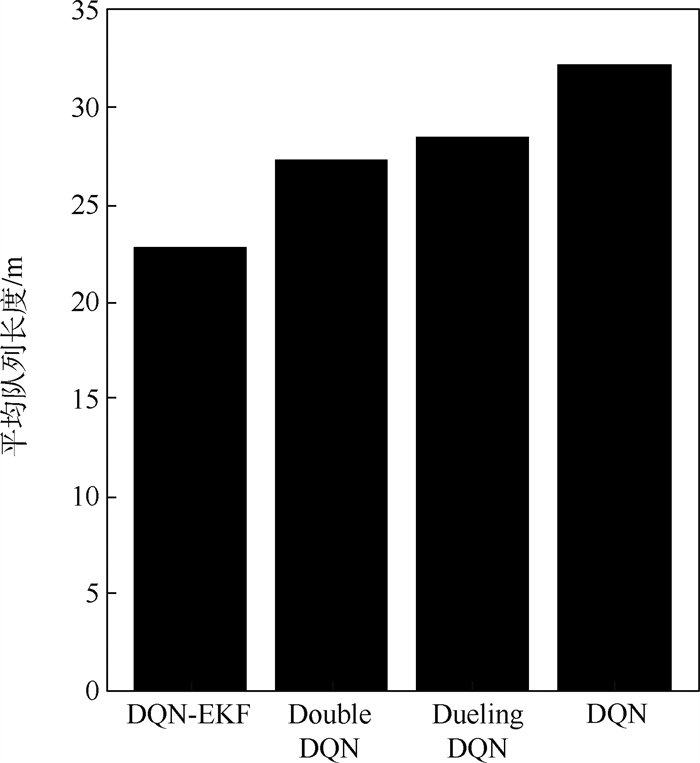
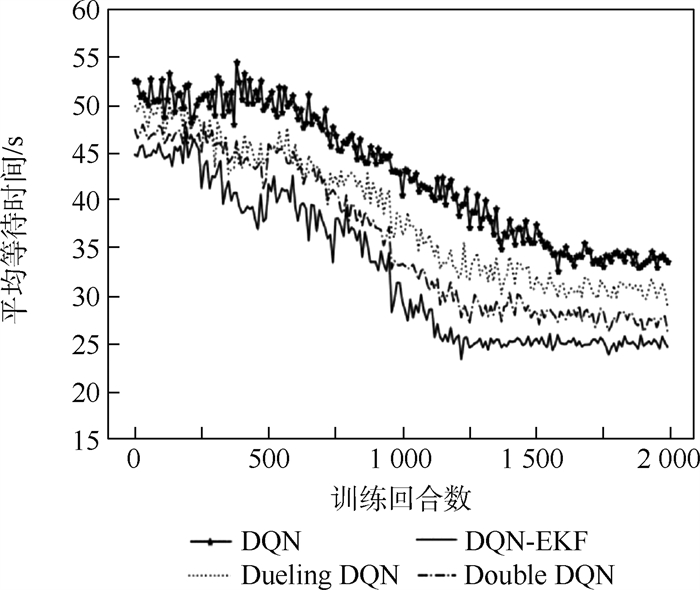









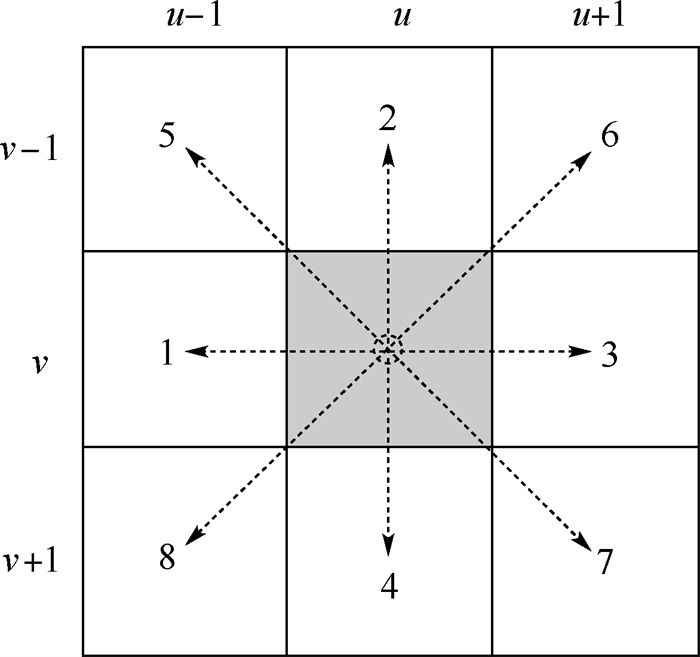
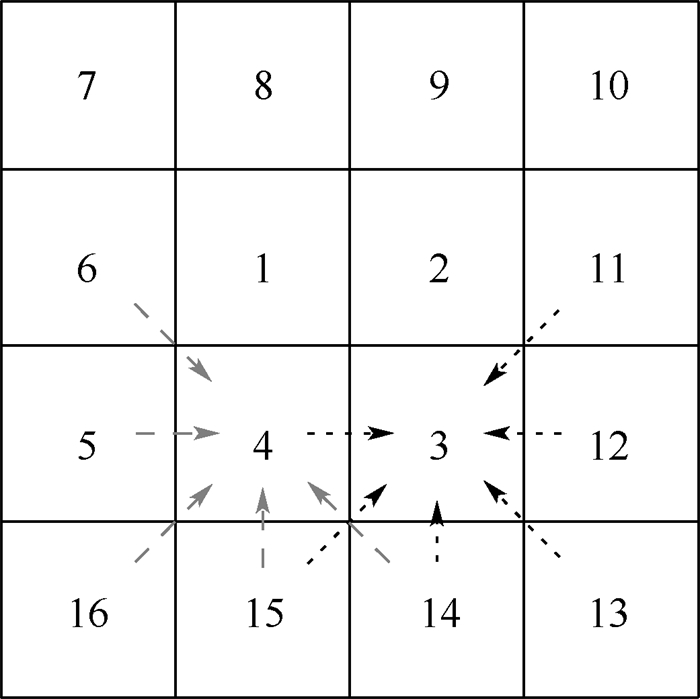







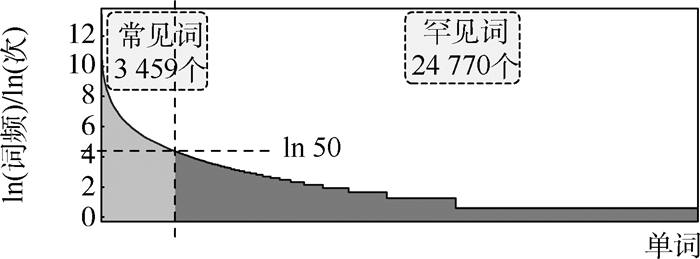
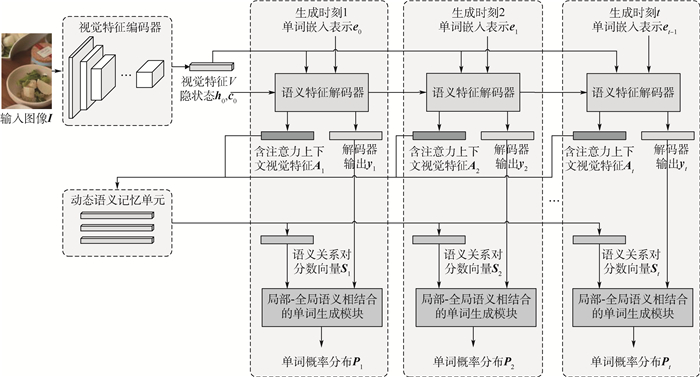



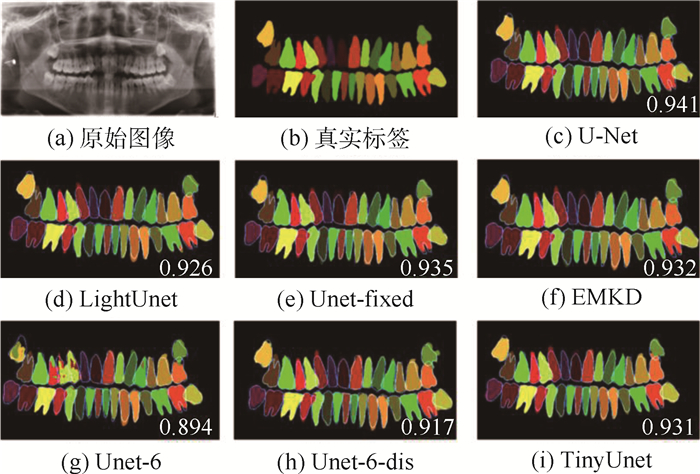
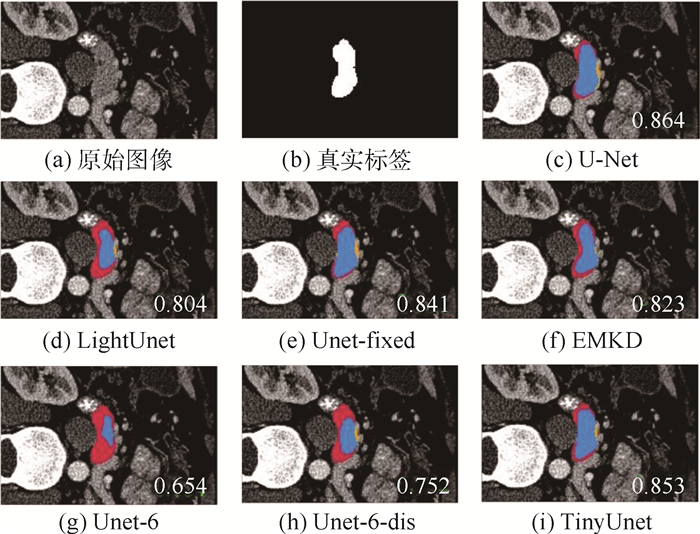


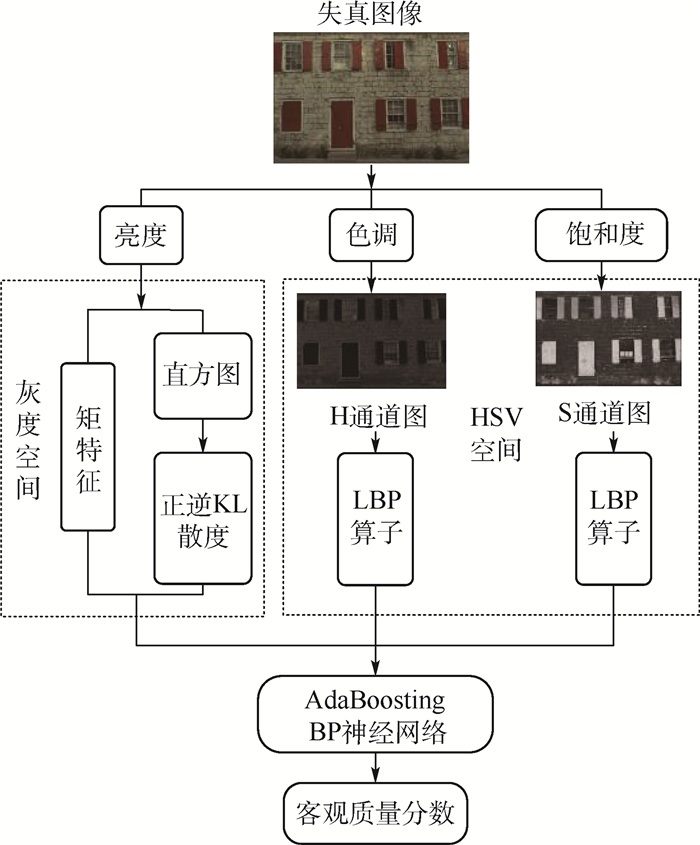
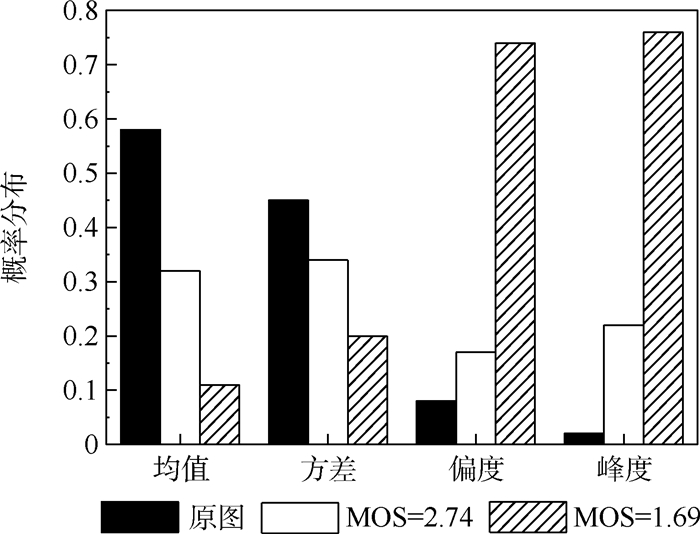




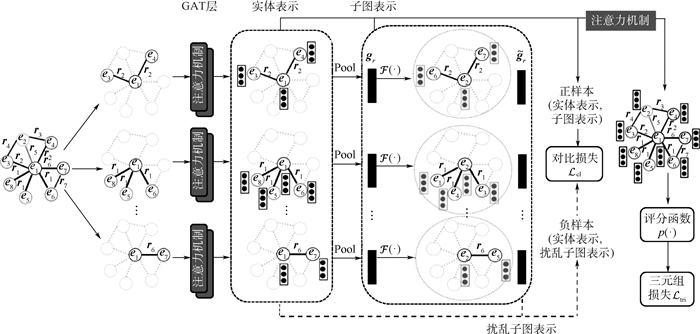

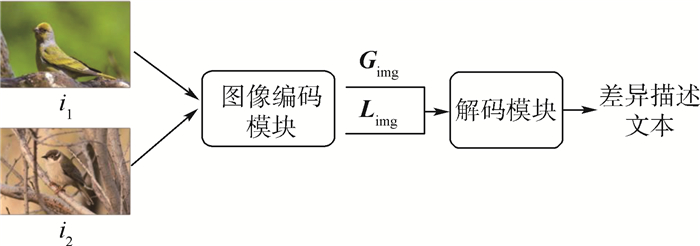







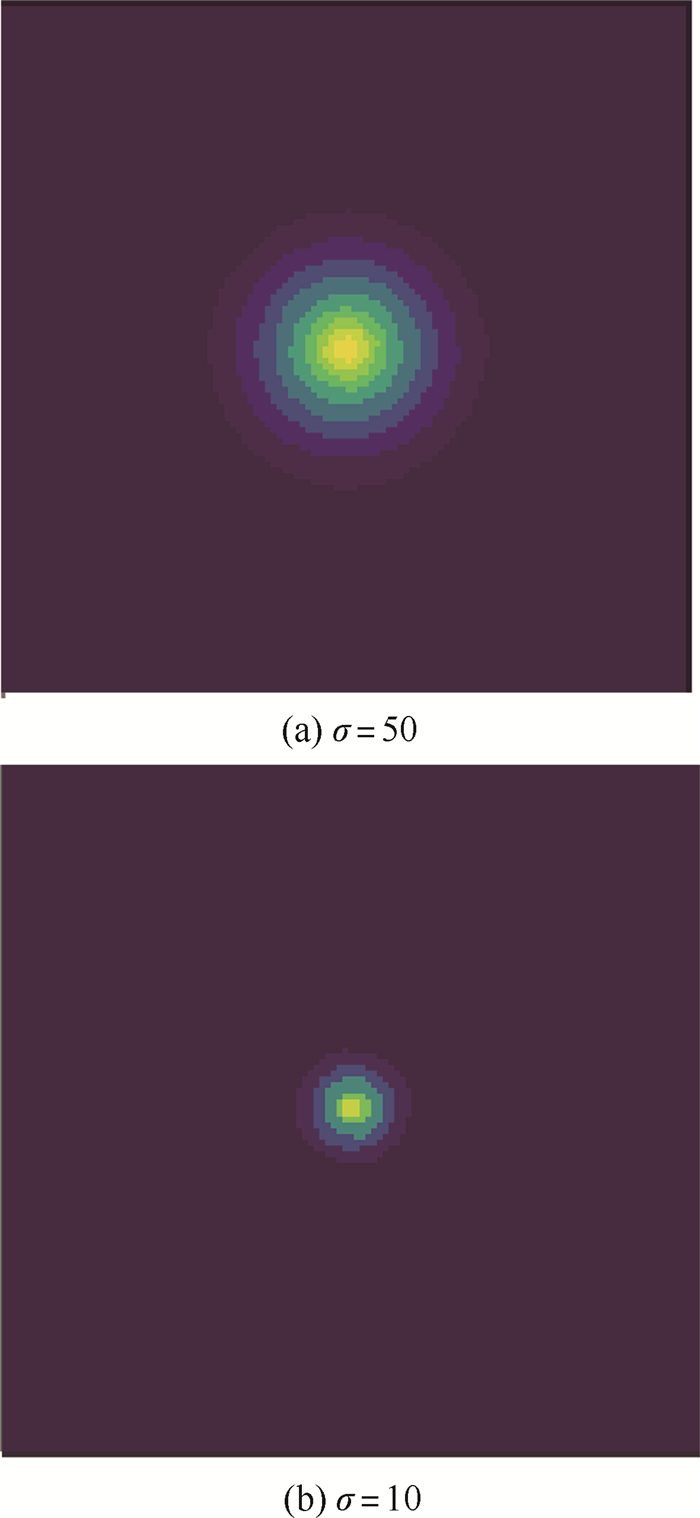
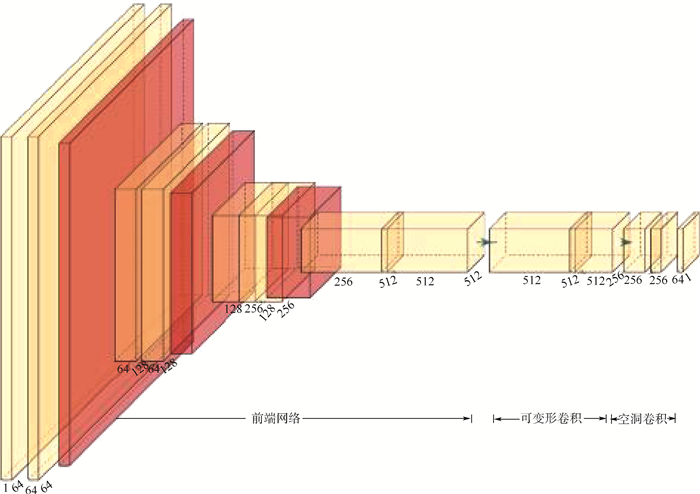
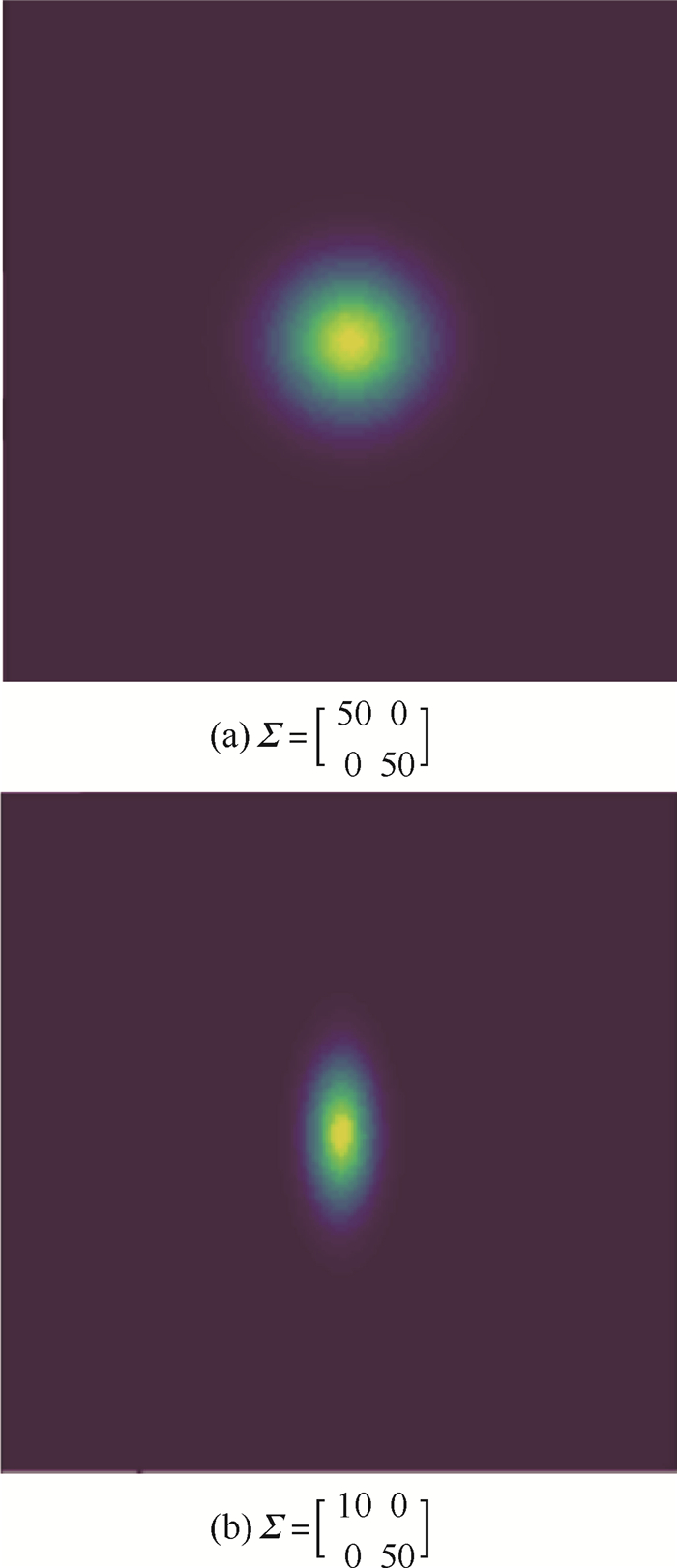





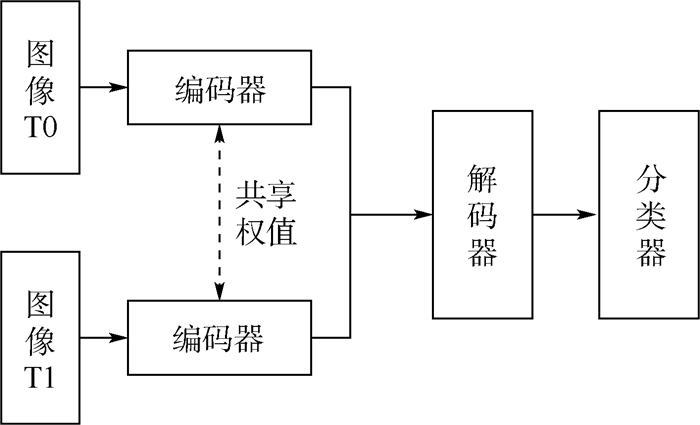

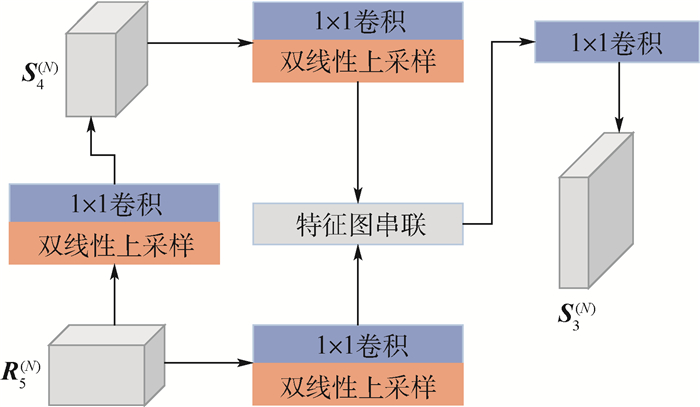

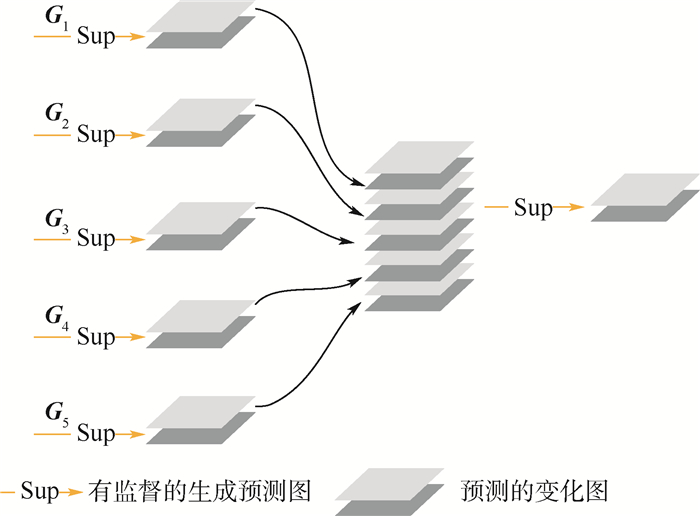


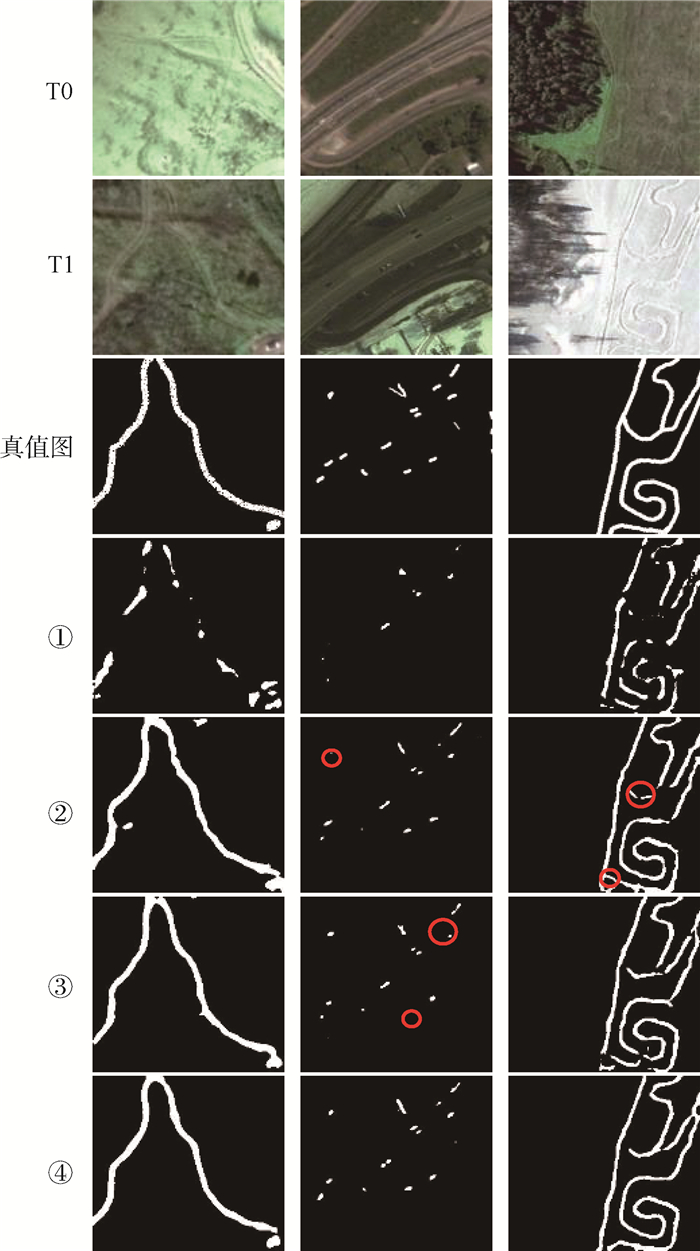
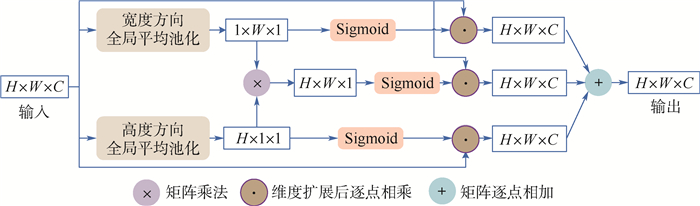



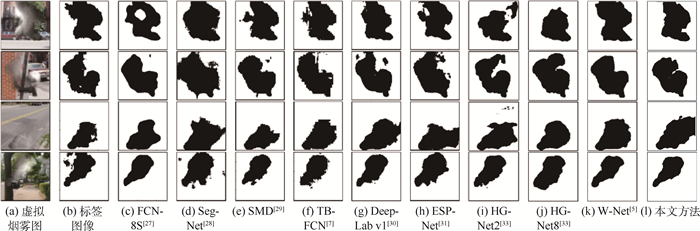




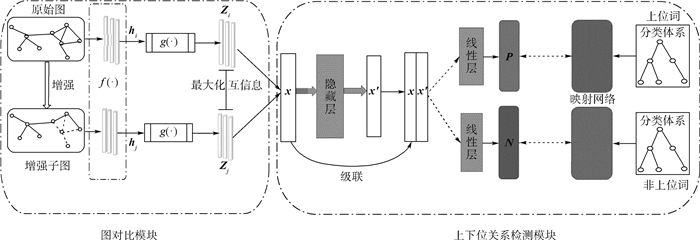
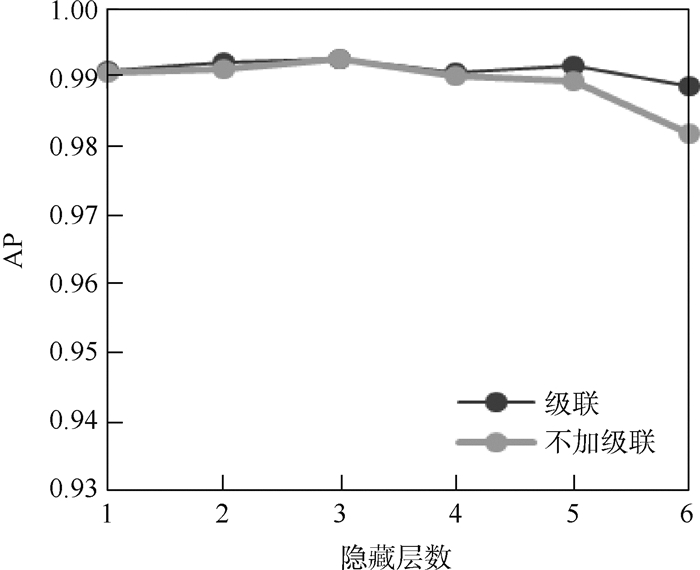

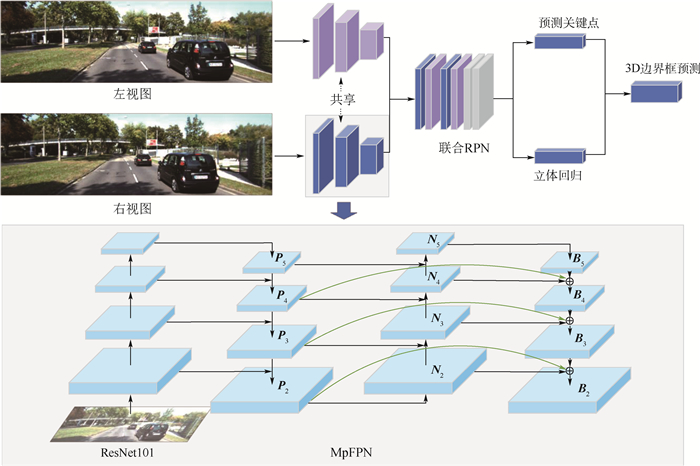

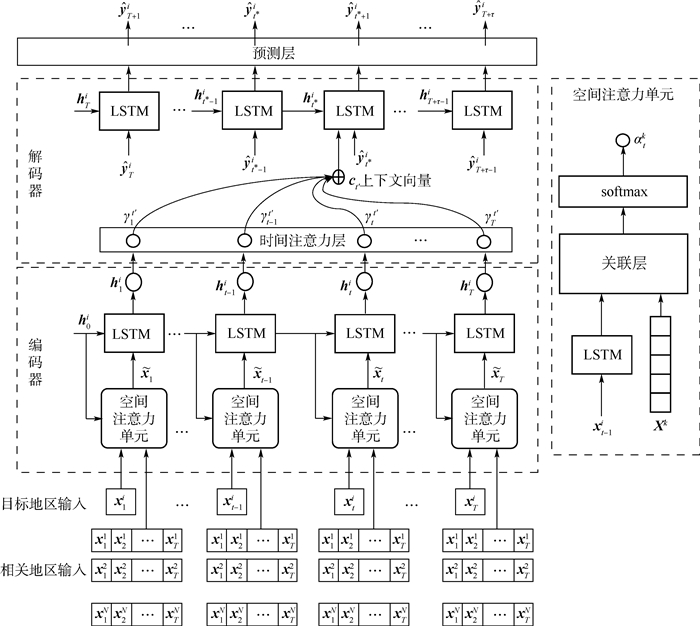


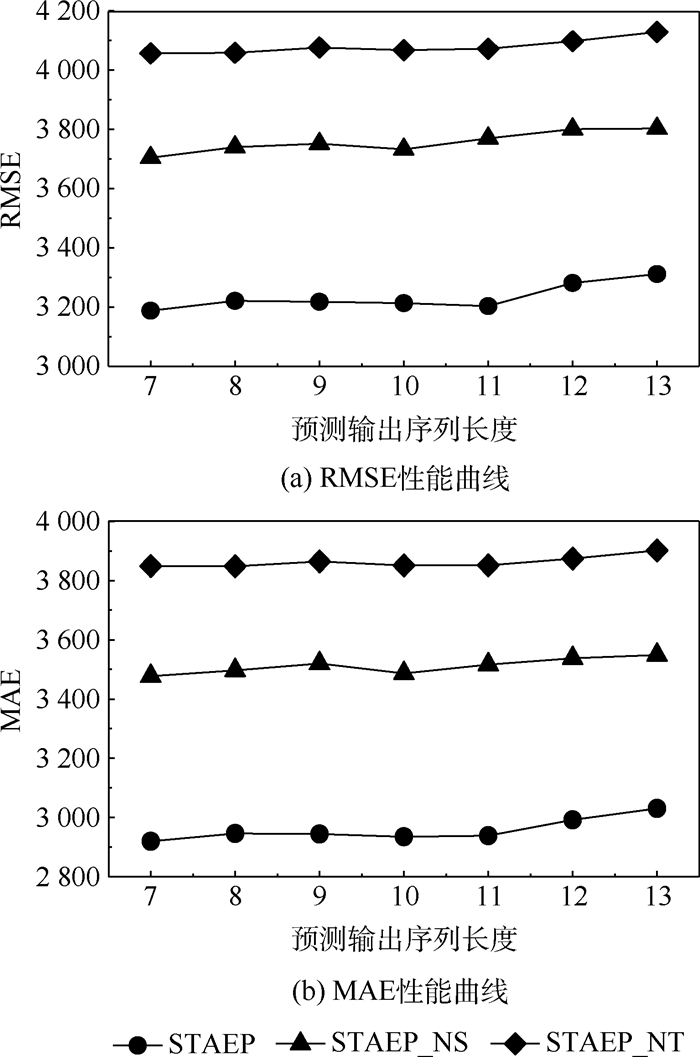







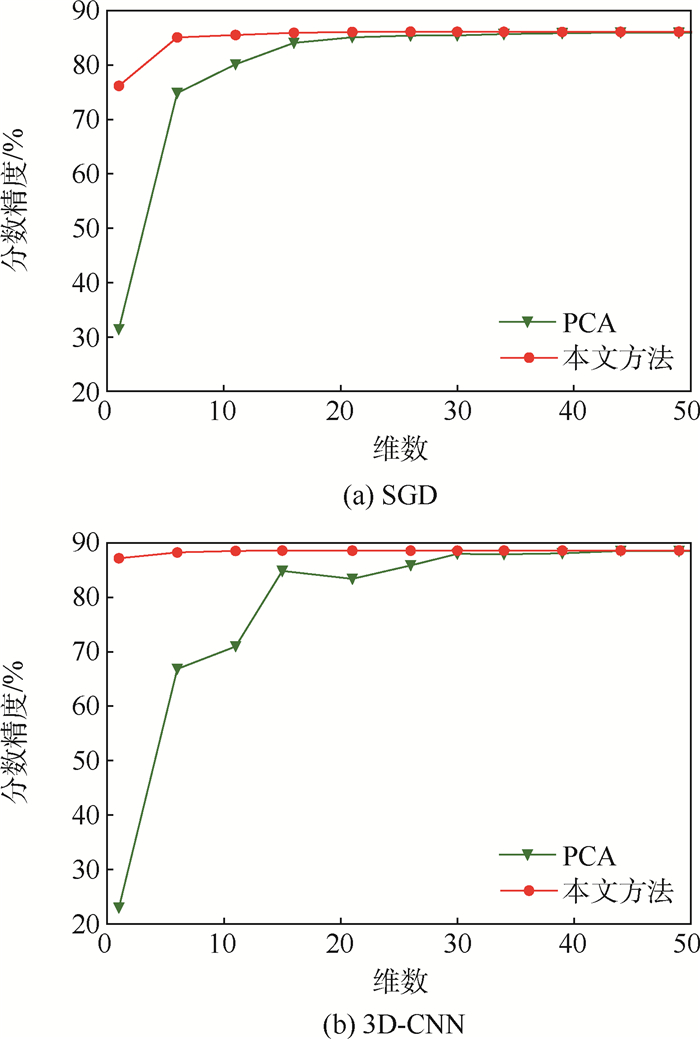
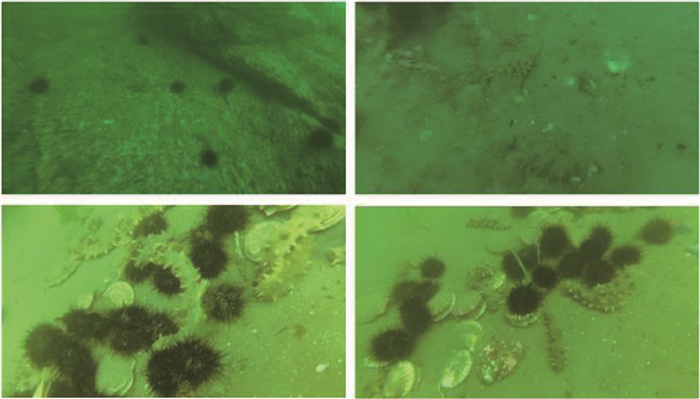




















版权所有 © 《北京航空航天大学学报》编辑部
通讯地址:北京市海淀区学院路37号 《北京航空航天大学学报》编辑部 邮编:100191 邮箱:jbuaa@buaa.edu.cn
本系统由
北京仁和汇智信息技术有限公司
开发



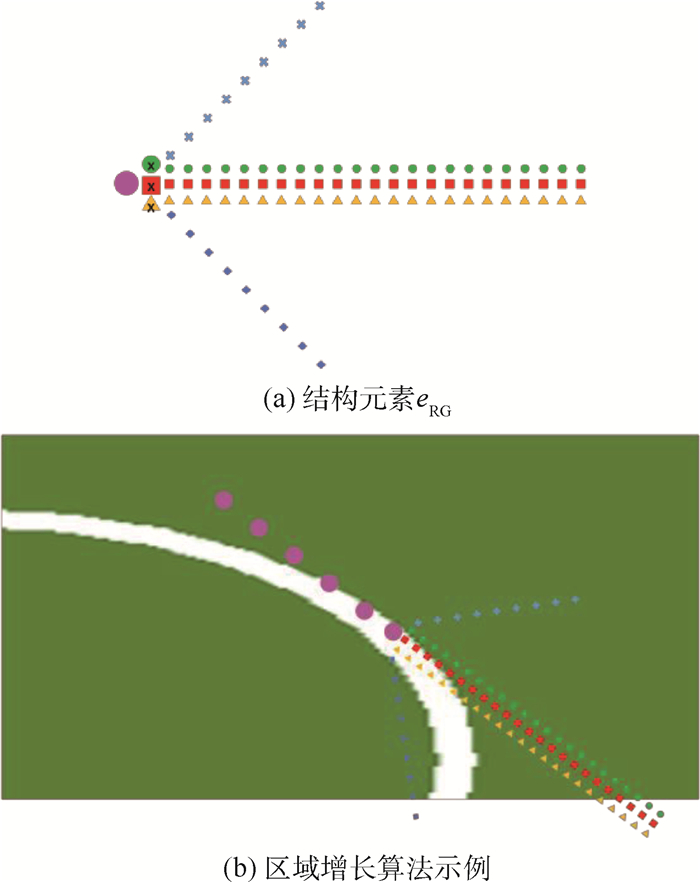
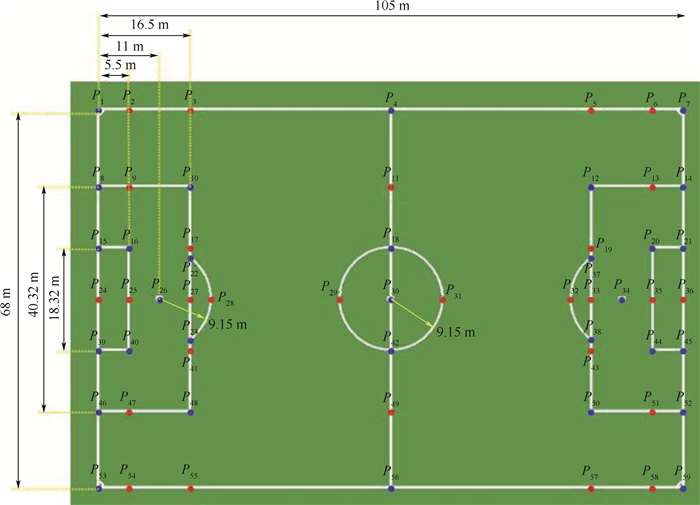

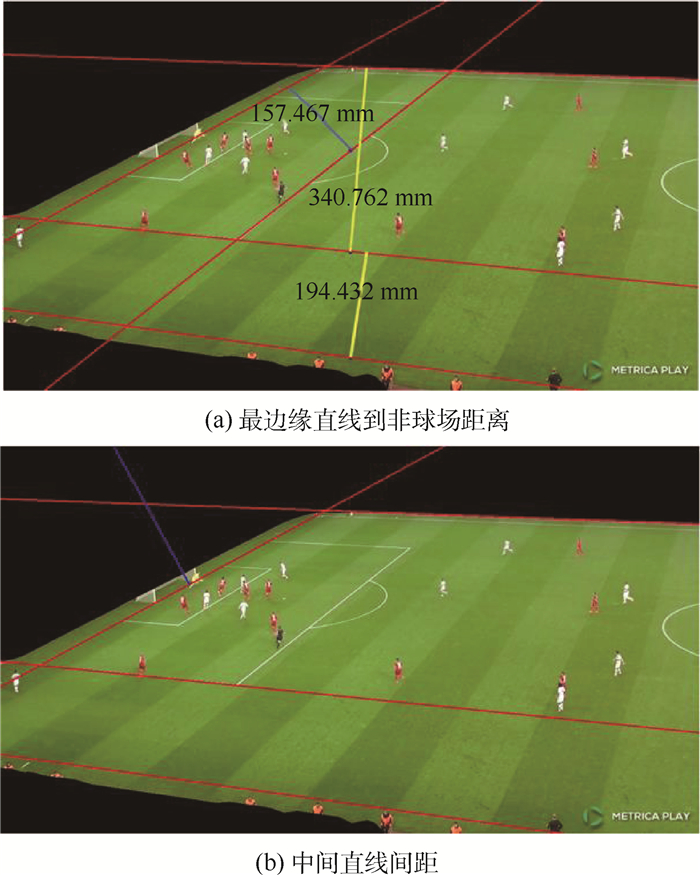

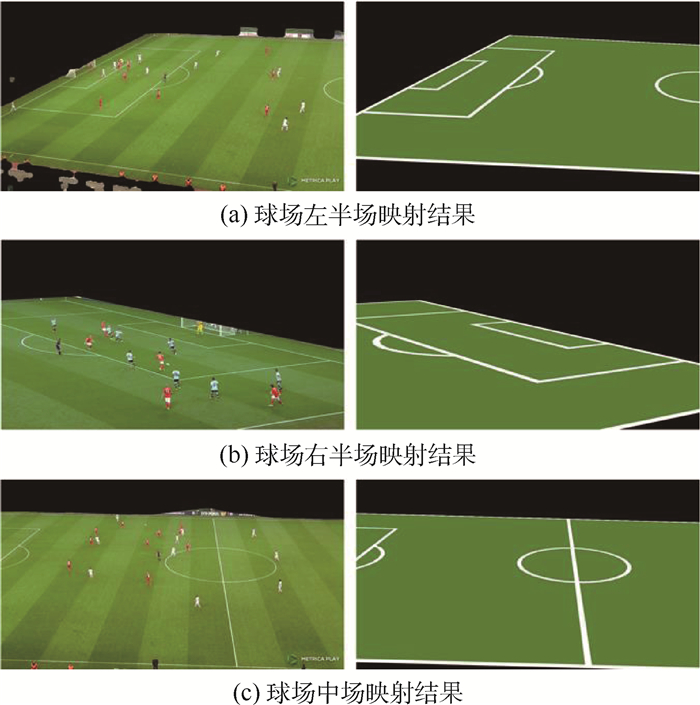







 XML在线生产平台
XML在线生产平台





