



-
摘要:
随着水下生物抓取技术的不断发展,高精度的水下物体识别与分割成为了挑战。已有的水下目标检测技术仅能给出物体的大体位置,无法提供物体轮廓等更加细致的信息,严重影响了抓取效率。为了解决这一问题,标注并建立了真实场景水下语义分割数据集DUT-USEG,该数据集包含6 617张图像,其中1 487张具有语义分割和实例分割标注,剩余5 130张图像具有目标检测框标注。基于该数据集,提出了一个关注边界的半监督水下语义分割网络(US-Net),该网络通过设计伪标签生成器和边界检测子网络,实现了对水下物体与背景之间边界的精细学习,提升了边界区域的分割效果。实验表明:所提方法在DUT-USEG数据集的海参、海胆和海星3个类别上相较于对比方法提升了6.7%,达到了目前最好的分割精度。
Abstract:Underwater object recognition and segmentation with high accuracy have become a challenge with the development of underwater object grabbing technology. The existing underwater object detection technology can only give the general position of an object, unable to give more detailed information such as the outline of the object, which seriously affects the grabbing efficiency. To address this problem, we label and establish underwater semantic segmentation dataset of a real scene (DUT-USEG). The DUT-USEG dataset includes 6 617 images, 1 487 of which have semantic segmentation and instance segmentation annotations, and the remaining 5 130 images have object detection box annotations. Based on this dataset, we propose a semi-supervised underwater semantic segmentation network (US-Net) focusing on the boundaries. By designing a pseudo label generator and a boundary detection subnetwork, this network realizes the fine learning of boundaries between underwater objects and background, and improves the segmentation effect of boundary areas. Experiments show that the proposed method improves by 6.7% in three categories of holothurian, echinus, and starfish in DUT-USEG dataset, and achieves state-of-the-art results.
-

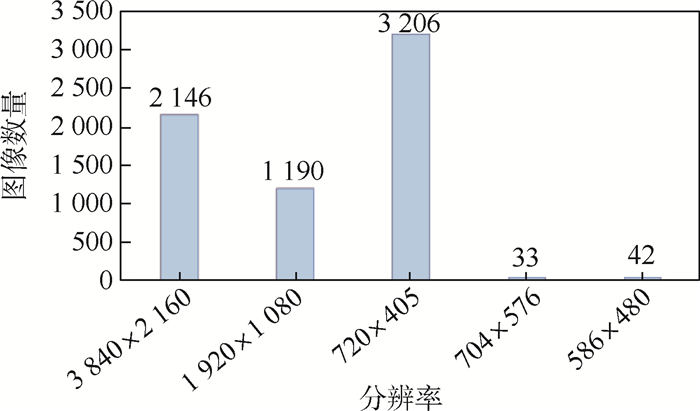
图 4 本文数据集中不同分辨率图像数量统计
Figure 4. Statistics on number of images with different resolutions in the proposed dataset

图 5 本文数据集中不同类别对应的实例数量统计
Figure 5. Statistics on number of instances of different categories in the proposed dataset

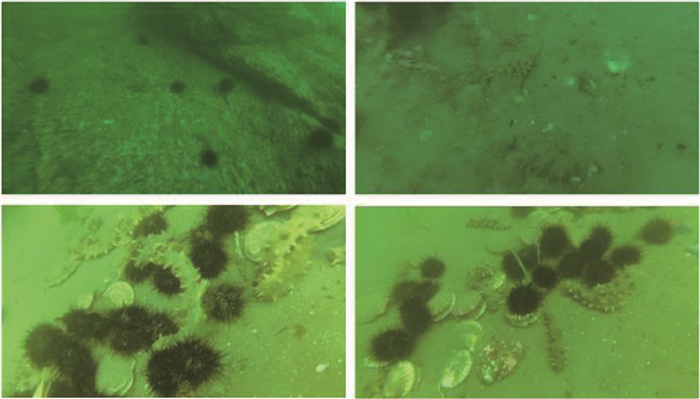
图 6 海洋生物不同类别数目不均衡问题的样例图像
Figure 6. Sampleimages showing the unbalanced numbers of different categories marine organisms
表 1 对比实验结果
Table 1. Results of contrast experiments
方法 IOU/% mIOU/% FWIOU/% PA/% 海参 海胆 扇贝 海星 GrabCut 52.5 63.8 77.8 58.2 70.1 97.6 98.6 GGANet 32.1 42.9 52.8 34.5 52.1 96.6 98.0 US-Net(本文方法) 54.9 67.7 70.4 63.6 71.1 98.1 98.9  下载: 导出CSV
下载: 导出CSV
表 2 运行时间对比实验结果
Table 2. Results of contrast experiment for running time
方法 运行时间/(s·张-1) GGANet 38.9 US-Net(本文方法) 47.6
下载: 导出CSV
表 3 边界检测网络消融实验结果
Table 3. Results of ablation experiment for boundary detection network
方法 mIOU/% 只用高斯注意力图 68.8 高斯注意力图+边界检测网络(本文方法) 71.1
下载: 导出CSV
表 4 伪标签生成器消融实验结果
Table 4. Results of ablation experiment for pseudo label generator
方法 mIOU/% 不使用伪标签生成器 67.6 高斯注意力图作为伪标签 68.6 高斯注意力图+类激活图作为伪标签(本文方法) 71.1
下载: 导出CSV
表 5 伪标签前景阈值消融实验结果
Table 5. Results of ablation experiment for foreground threshold of pseudo labels
前景阈值 0.2 0.3 0.4 mIOU % 70.5 71.1 69.7
下载: 导出CSV
表 6 像素对最大距离消融实验结果
Table 6. Results of ablation experiment for maximum distance of pixel pairs
最大距离γ 5 10 15 mIOU/% 70.2 71.1 71.3
下载: 导出CSV
-
[1] LI C, GUO C, REN W, et al. An underwater image enhancement benchmark dataset and beyond[J]. IEEE Transactions on Image Processing, 2019, 29: 4376-4389. [2] LI C, ANWAR S, PORIKLI F. Underwater scene prior inspired deep underwater image and video enhancement[J]. Pattern Recognition, 2020, 98: 107038. doi: 10.1016/j.patcog.2019.107038 [3] GUO Y, LI H, ZHUANG P. Underwater image enhancement using a multiscale dense generative adversarial network[J]. IEEE Journal of Oceanic Engineering, 2019, 45(3): 862-870. [4] CHEN L, LIU Z, TONG L, et al. Underwater object detection using invert multi-class adaboost with deep learning[C]//2020 International Joint Conference on Neural Networks (IJCNN). Piscataway: IEEE Press, 2020: 1-8. [5] LI X, SHANG M, QIN H, et al. Fast accurate fish detection and recognition of underwater images with fast R-CNN[C]//OCEANS 2015-MTS/IEEE Washington. Piscataway: IEEE Press, 2015: 1-5. [6] VILLON S, CHAUMONT M, SUBSOL G, et al. Coral reef fish detection and recognition in underwater videos by supervised machine learning: Comparison between deep learning and HOG+ SVM methods[C]//International Conference on Advanced Concepts for Intelligent Vision Systems. Berlin: Springer, 2016: 160-171. [7] LIU C W, LI H J, WANG S C, et al. A dataset and benchmark of underwater object detection for robot picking[EB/OL]. (2021-06-10)[2021-09-01]. https://arxiv.org/abs/2106.05681. [8] JIAN M, QI Q, DONG J, et al. The OUC-vision large-scale underwater image database[C]//2017 IEEE International Conference on Multimedia and Exposition (ICME). Piscataway: IEEE Press, 2017: 1297-1302. [9] LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2015: 3431-3440. [10] DAI J, HE K, SUN J. BoxSup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation[C]//Proceedings of the IEEE International Conference on Computer Vision. Piscataway: IEEE Press, 2015: 1635-1643. [11] KHOREVA A, BENENSON R, HOSANG J, et al. Simple does it: Weakly supervised instance and semantic segmentation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2017: 876-885. [12] ROTHER C, KOLMOGOROV V, BLAKE A. "GrabCut" interactive foreground extraction using iterated graph cuts[J]. ACM Transactions on Graphics, 2004, 23(3): 309-314. doi: 10.1145/1015706.1015720 [13] PONT-TUSET J, ARBELAEZ P, BARRON J T, et al. Multiscale combinatorial grouping for image segmentation and object proposal generation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 39(1): 128-140. [14] SONG C, HUANG Y, OUYANG W, et al. Box-driven class-wise region masking and filling rate guided loss for weakly supervised semantic segmentation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 3136-3145. [15] LEE J, YI J, SHIN C, et al. BBAM: Bounding box attribution map for weakly supervised semantic and instance segmentation[EB/OL]. (2021-03-16)[2021-09-01]. https://arxiv.org/abs/2103.08907. [16] ZHANG P, WANG Z, MA X, et al. Learning to segment unseen category objects using gradient gaussian attention[C]//2019 IEEE International Conference on Multimedia and Exposition (ICME). Piscataway: IEEE Press, 2019: 1636-1641. [17] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: Common objects in context[C]//European Conference on Computer Vision. Berlin: Springer, 2014: 740-755. [18] EVERINGHAM M, VAN GOOL L, WILLIAMS C K I, et al. The pascal visual object classes (VOC) challenge[J]. International Journal of Computer, 2015, 111: 98-136. [19] CHENG H K, CHUNG J, TAI Y W, et al. CascadePSP: Toward class-agnostic and very high-resolution segmentation via global and local refinement[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2020: 8890-8899. [20] ZHOU B, KHOSLA A, LAPEDRIZA A, et al. Learning deep features for discriminative localization[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 2921-2929. [21] AHN J, CHO S, KWAK S. Weakly supervised learning of instance segmentation with inter-pixel relations[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2019: 2209-2218. [22] KRÄHENBVHL P, KOLTUN V. Efficient inference in fully connected CRFS with gaussian edge potentials[J]. Advances in Neural Information Processing Systems, 2011, 24: 109-117. [23] LIU W, RABINOVICH A, BERG A C. ParseNet: Looking wider to see better[EB/OL]. (2015-11-19)[2021-09-01]. https://arxiv.org/abs/1506.04579. [24] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE Press, 2016: 770-778. -

 下载:
下载:









 点击查看大图
点击查看大图
计量
- 文章访问数: 765
- HTML全文浏览量: 182
- PDF下载量: 98
- 被引次数: 0
