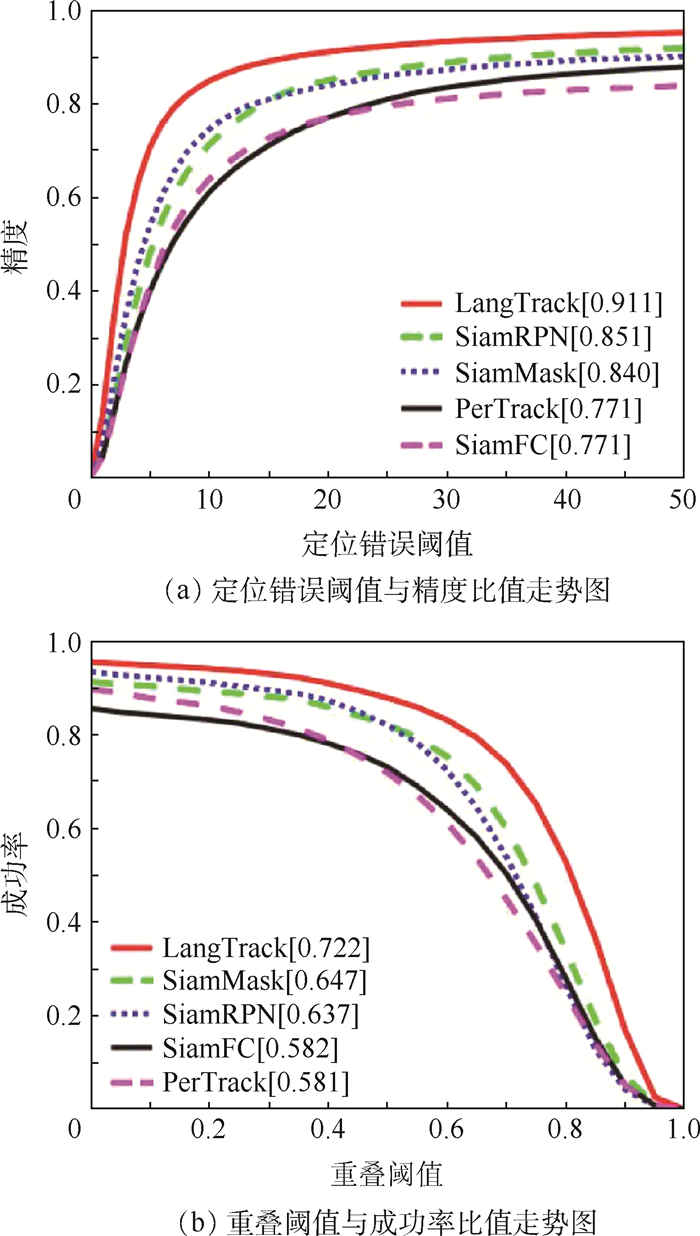
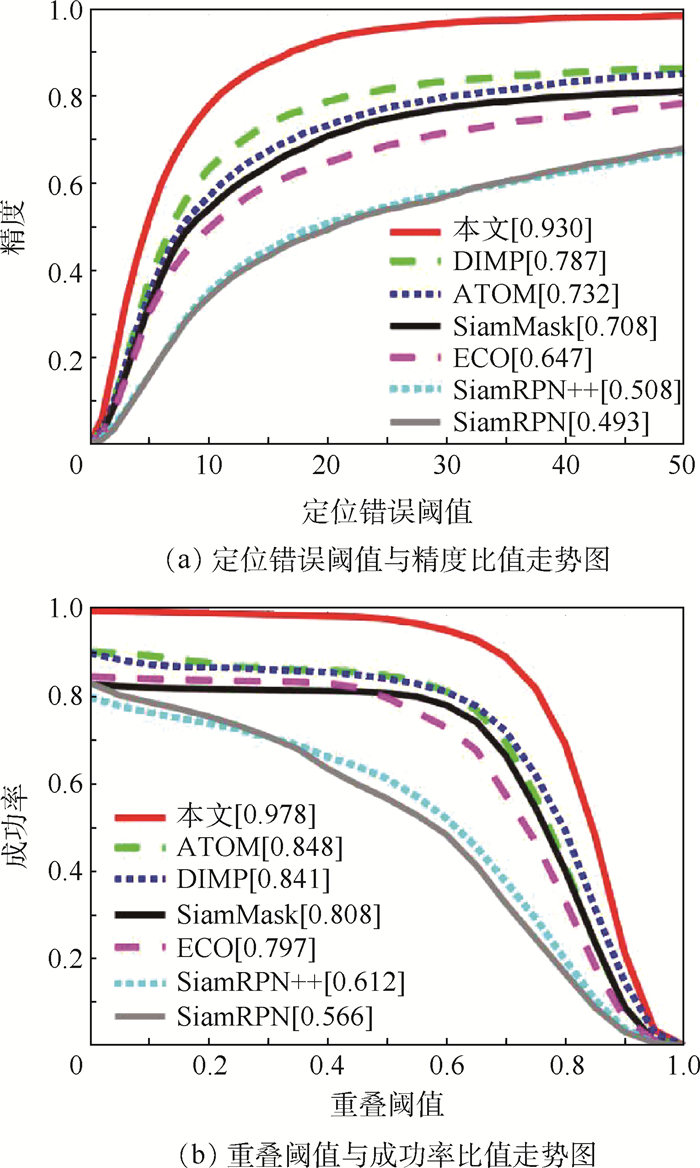
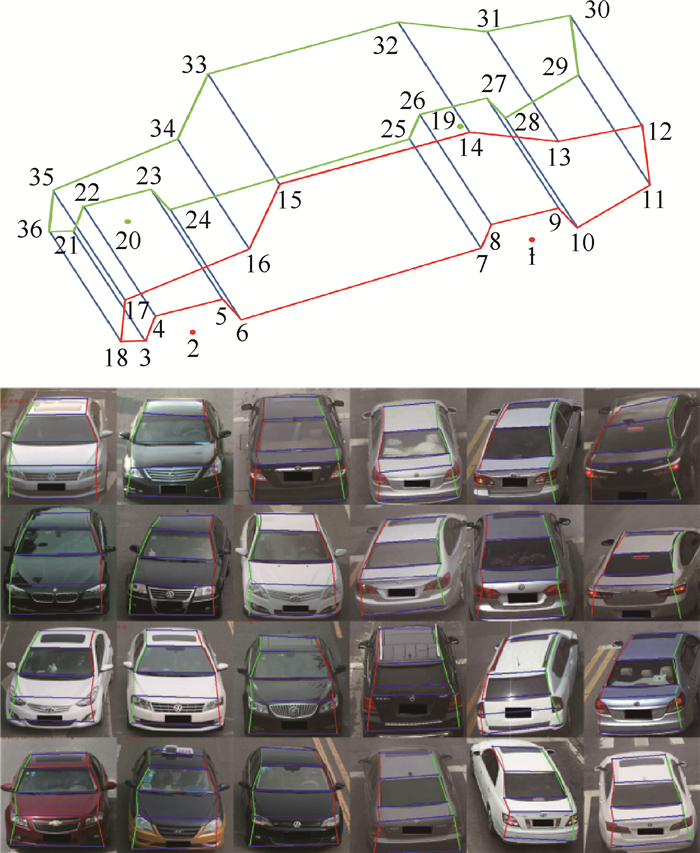
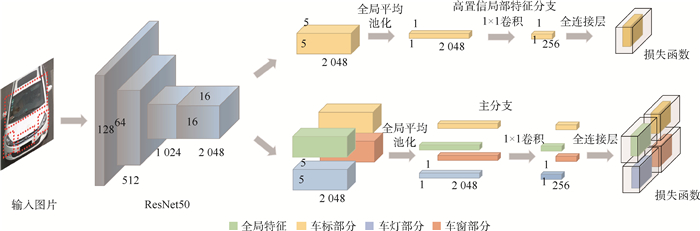
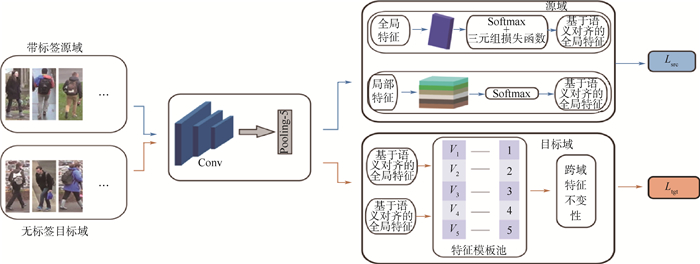
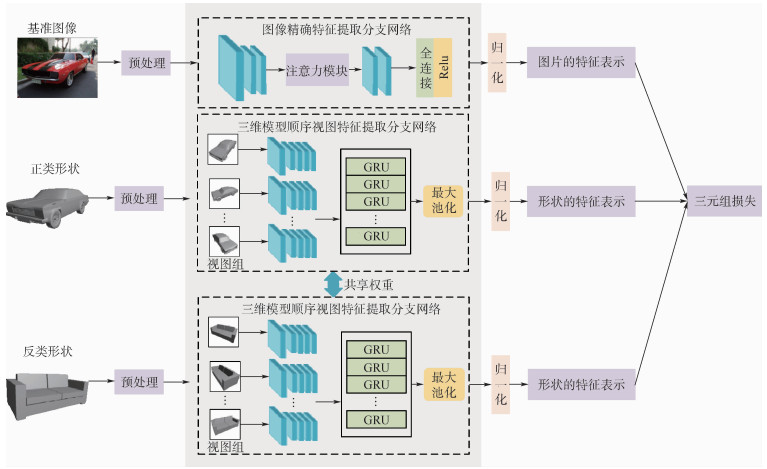
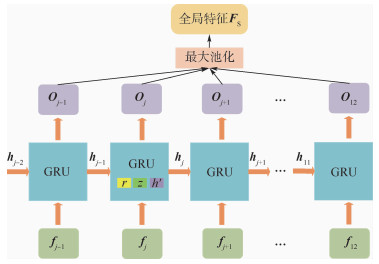
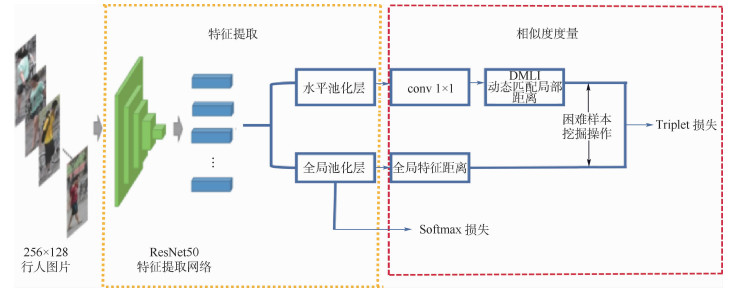
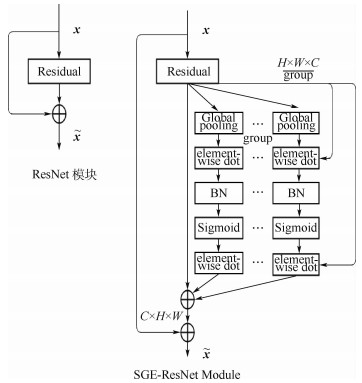
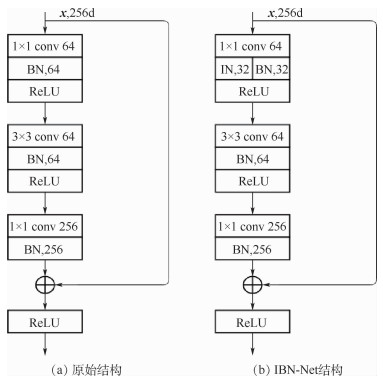
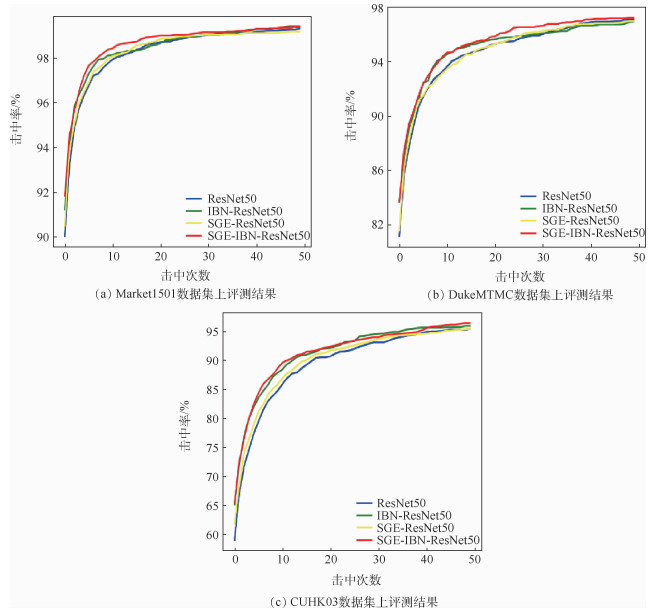
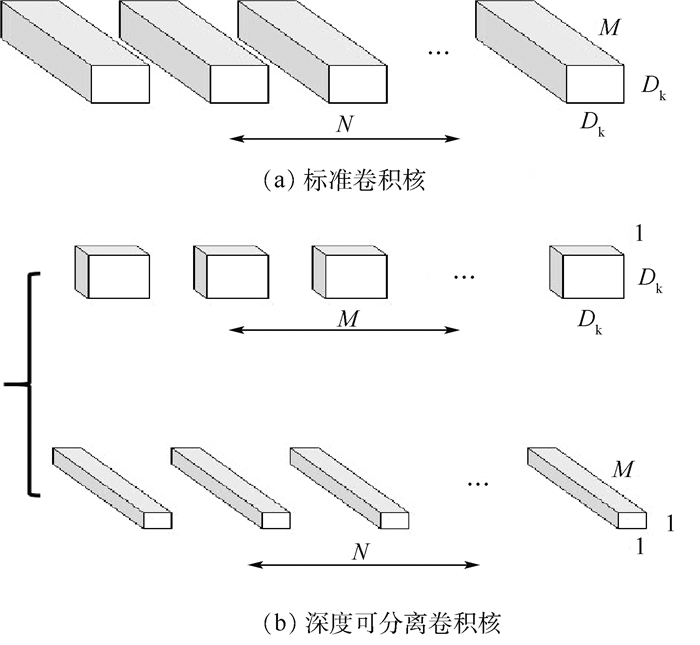
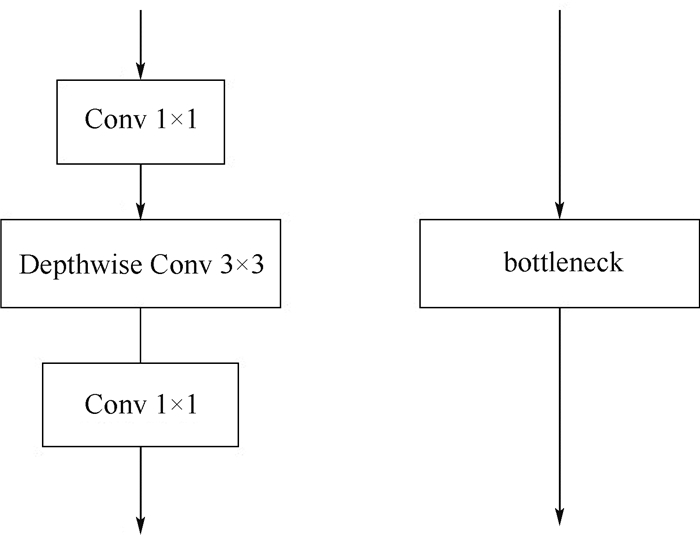
Pedestrian re-identification has always been an important part of image retrieval. However, due to different pedestrian poses and complex backgrounds, the extracted pedestrian features are not robust and representative, which in turn affects the accuracy of pedestrian re-recognition. In this paper, based on AlignedReID++ algorithm, we proposes a pedestrian re-identification method based on spatial attention mechanism. First, in the feature extraction part, a spatial attention mechanism is introduced to enhance feature expression while suppressing possible noise. Second, the Instance-Normalization (IN) layer is introduced in the convolution layer to assist the Batch-Normalization (BN) layer to normalize the features and to solve the problem of single BN layer insensitivity to feature tonal and illumination changes, which enhances the robustness of feature extraction to tonal and illumination changes. Finally, to validate the proposed method, extensive experiment has been carried out on the Market1501, DukeMTMC, and CUHK03 pedestrian re-identification datasets. The experimental results show that the recognition accuracy of the improved model on the three datasets has been improved by 2%, 2.9%, and 5.1%, respectively, compared with model before modification, which indicates that the proposed method achieves higher accuracy and more robustness.


 Download (78783)
Download (78783) 
 Views
Views  Cited by
Cited by 
















































































































 XML Online Production Platform
XML Online Production Platform
