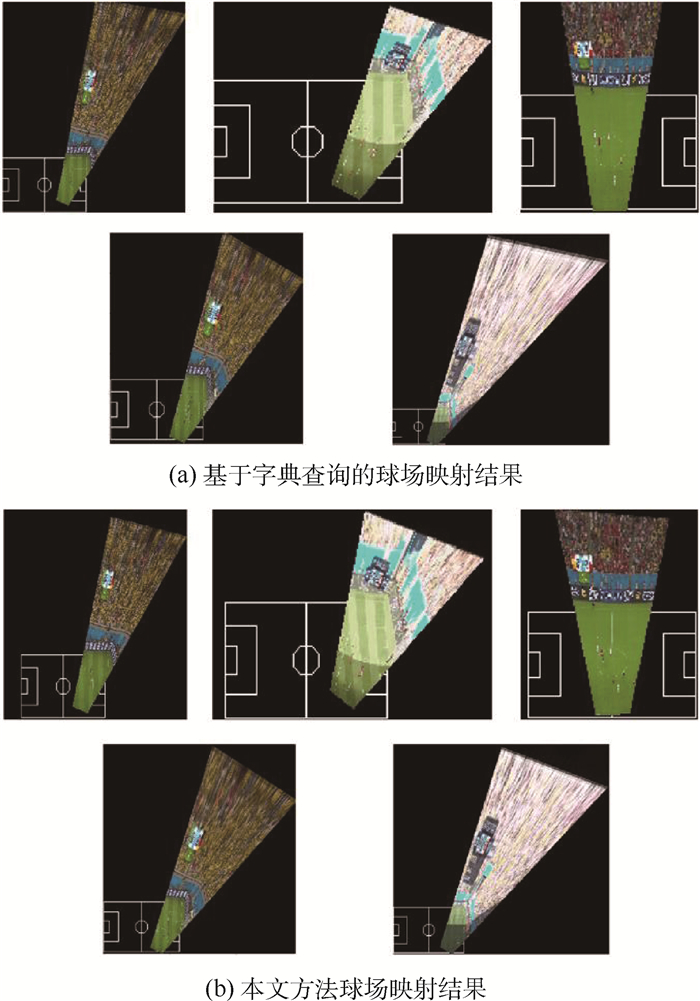
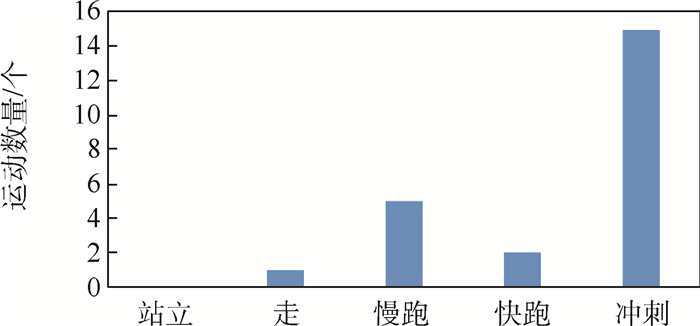
Objective In soccer matches, player data analysis is crucial to improve the viewing experience for viewers and to aid coaches in performance evaluation. The difficulty of player data analysis is how to locate the coordinates of players on the soccer field, i.e., how to determine the mapping relationship between the defective field appearing in a frame of soccer video and the standard two-dimensional field. Aiming at how to deal with the high-speed movement of the camera and the sharp change of the angle of view in the soccer match, we designed and proposed a method of player motion analysis using field reconstruction and player tracking. For field reconstruction, the field in the soccer video is grouped into three parts: left, center, and right. Each group is mapped from the defective field to the standard field by soccer field segmentation, straight line detection, straight-line grouping, center circle point set identification, and key point matching; the kernelized correlation filter (KCF) tracking algorithm is used for player tracking. Then, using a combination of field reconstruction and player tracking approaches, we determine the standard coordinates of players and generate a set of player motion data and visualization results.The player data analysis method proposed in this paper can accurately and effectively count the player data, including player coordinates, motion trajectory, running speed, activity range, and player spacing. In terms of field reconstruction, image intersection is used for evaluation, and the intersection ratio of our algorithm reaches 87%, which improves 3.7% compared to the traditional dictionary-based reconstruction method (83.3% intersection ratio). The results of the experiments suggest that our field reconstruction method can more precisely depict the field mapping connection and can give greater assistance for the statistical analysis of player data.In this paper, we design and propose a complete algorithm for player data analysis based on soccer field reconstruction and obtain visualization results of player statistics. The soccer field reconstruction method combining the knowledge of soccer has improved in accuracy and efficiency. The player data analysis in this paper can provide data support for soccer fans and practitioners, the field reconstruction method lays a solid foundation for further research in the field of player analysis.



 Download (90388)
Download (90388) 
 Views
Views  Cited by
Cited by 





















































































































 XML Online Production Platform
XML Online Production Platform
