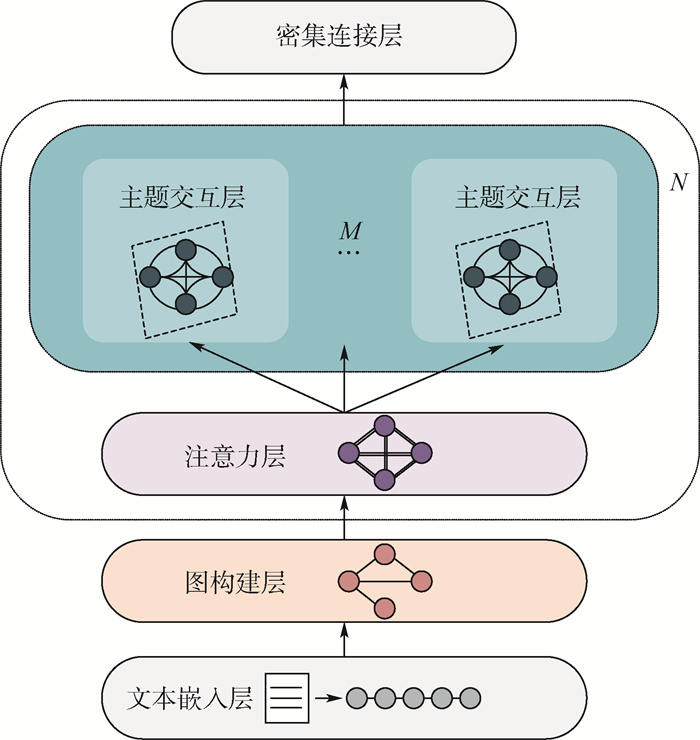
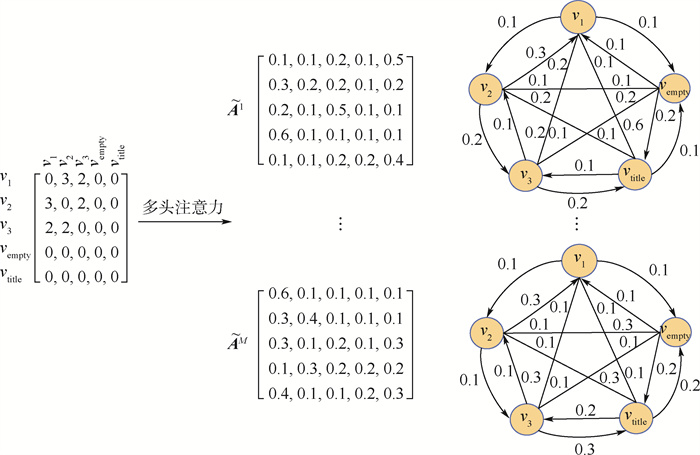
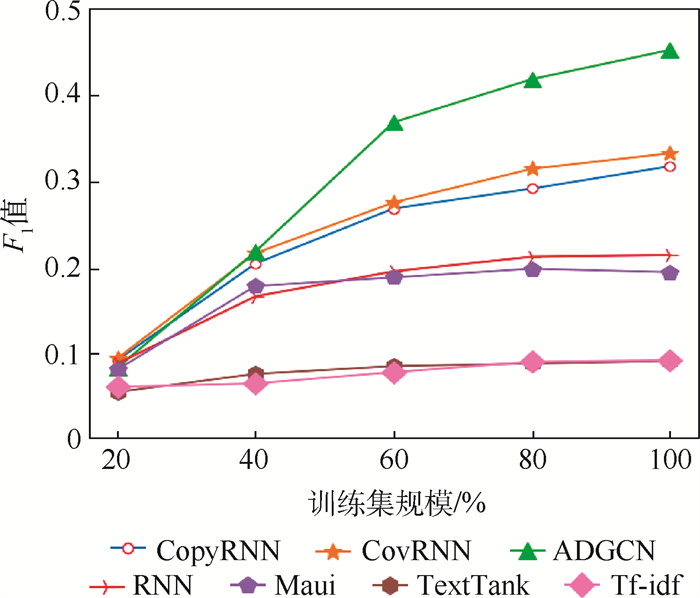
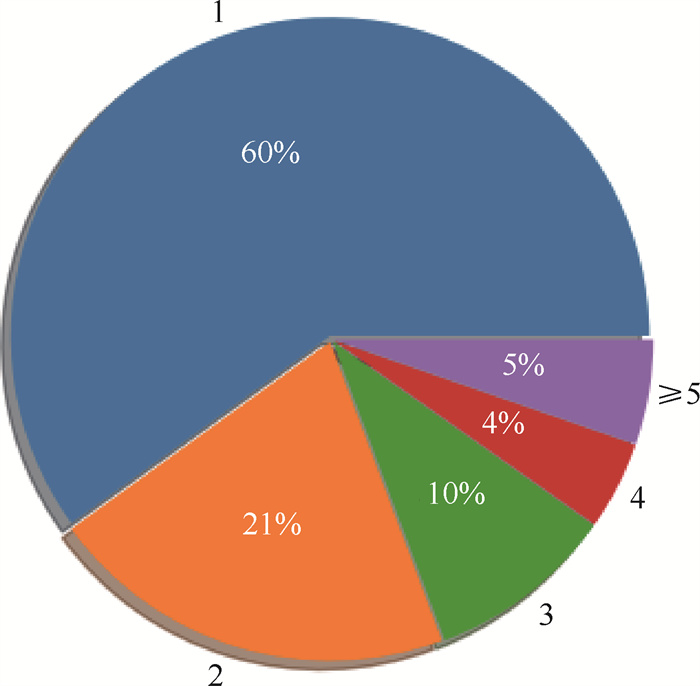
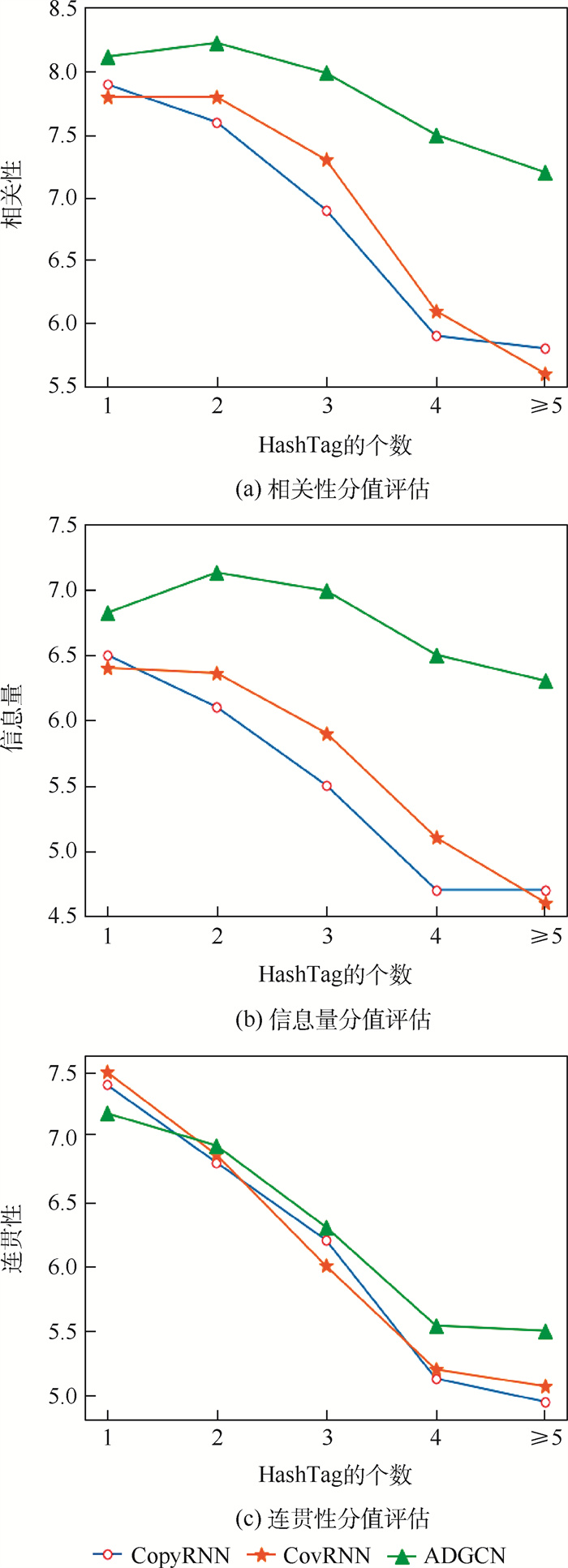
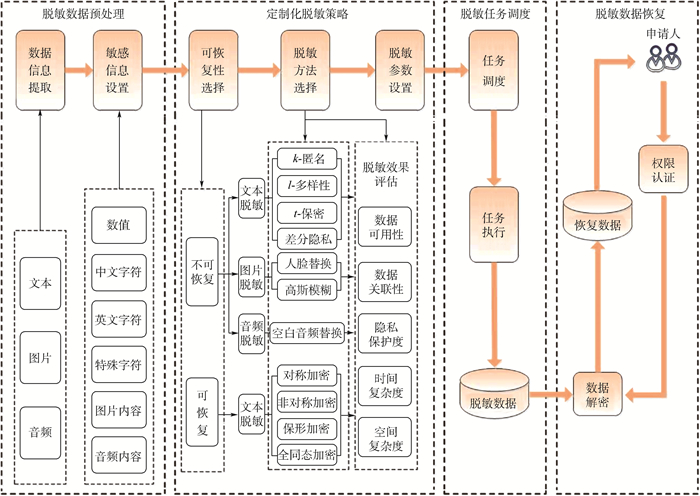
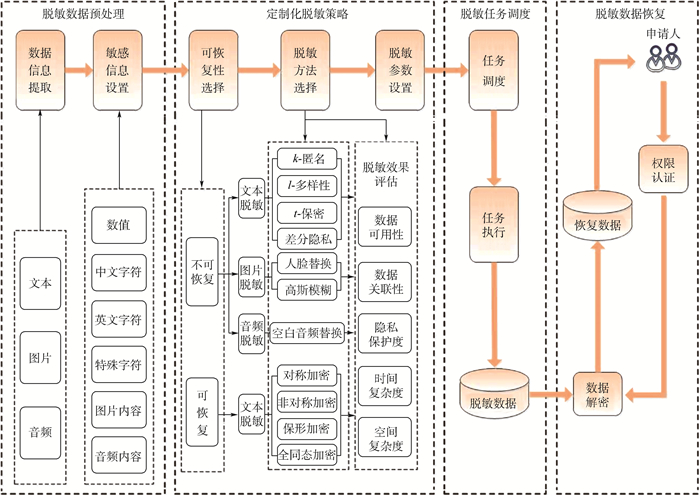
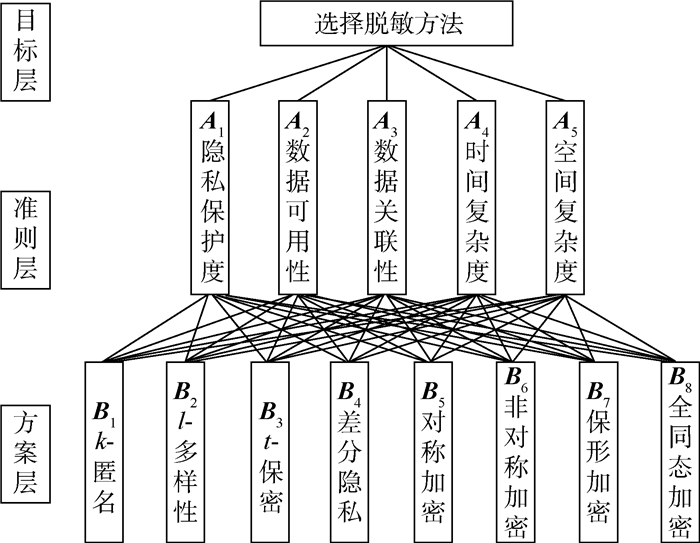
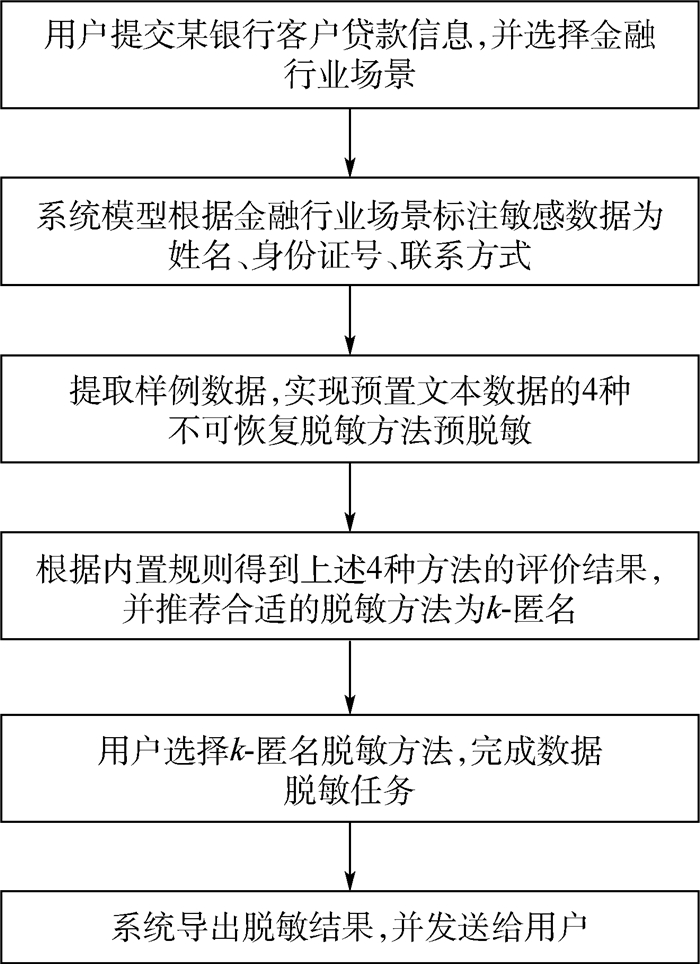
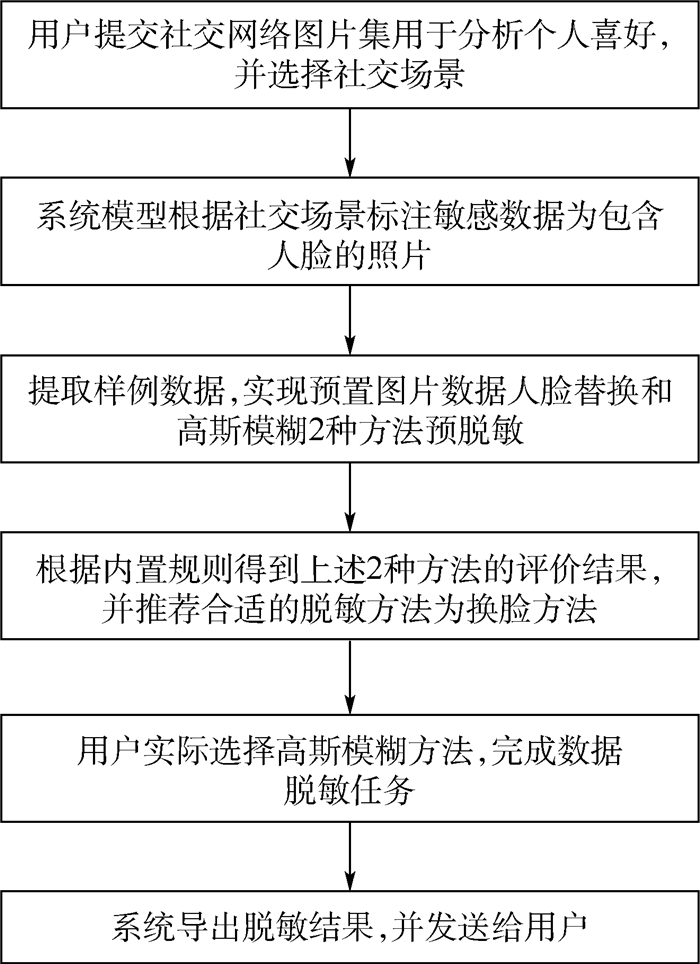
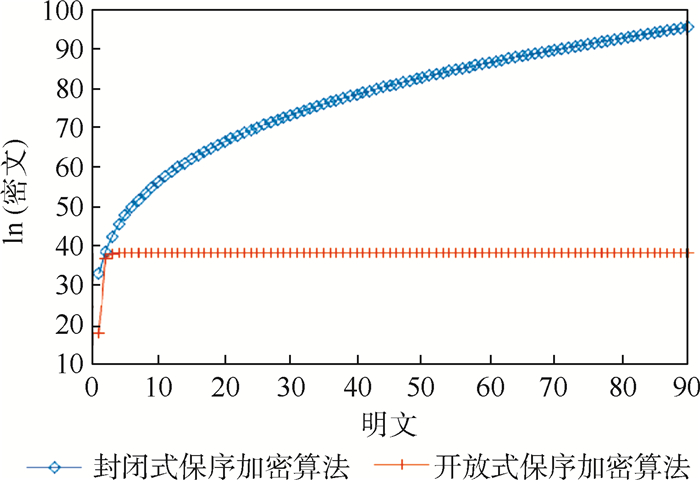
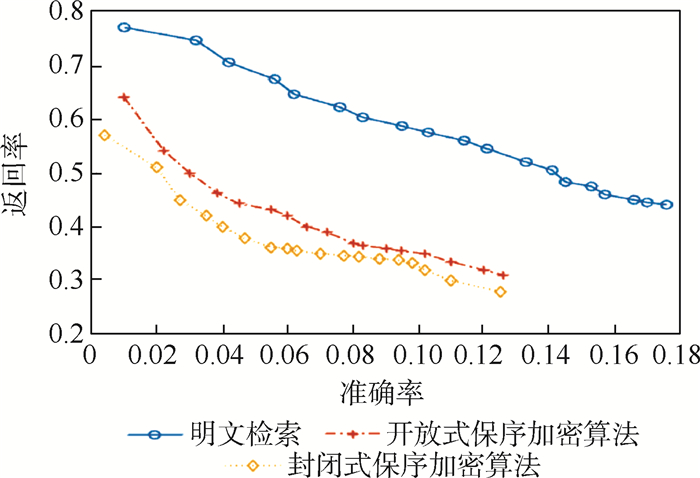
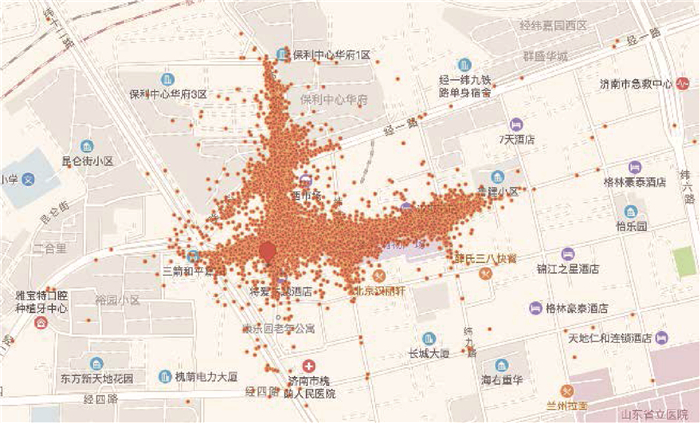
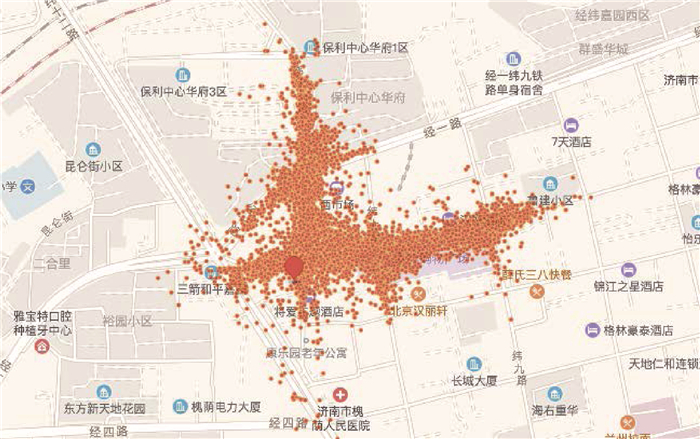
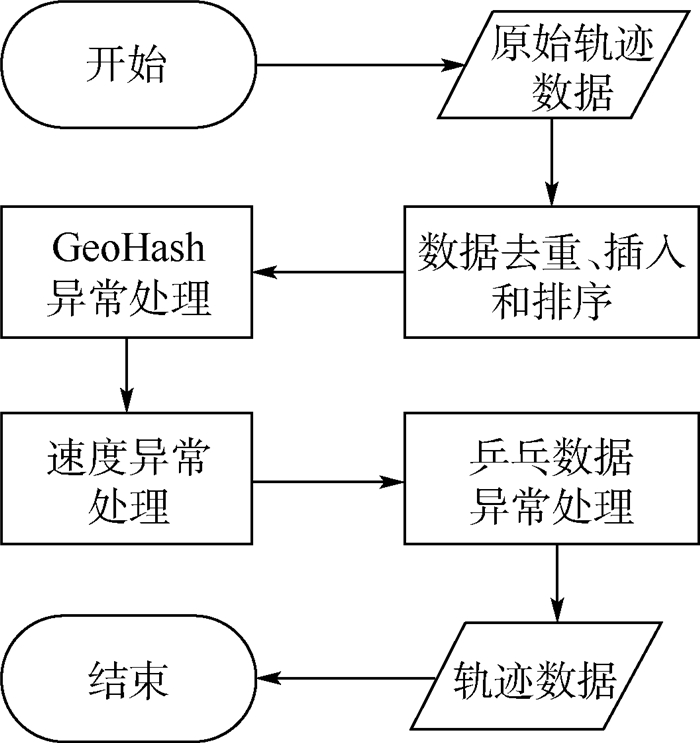
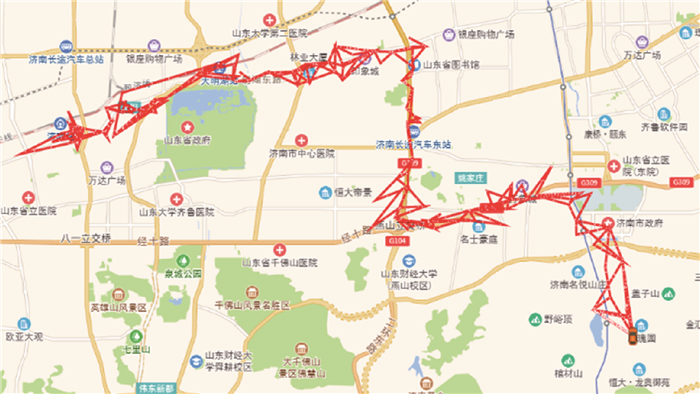
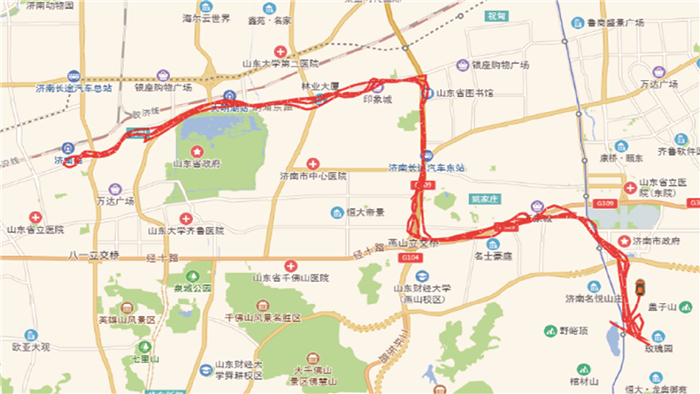
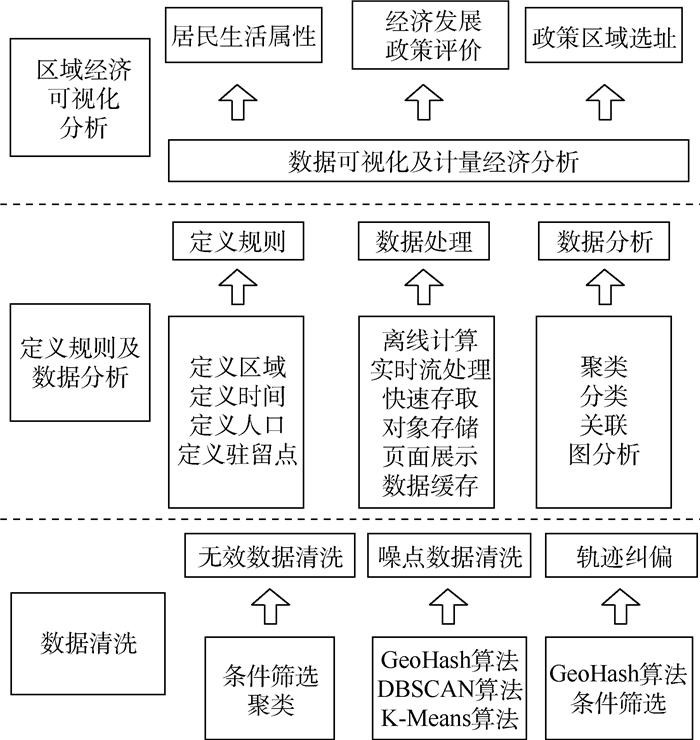
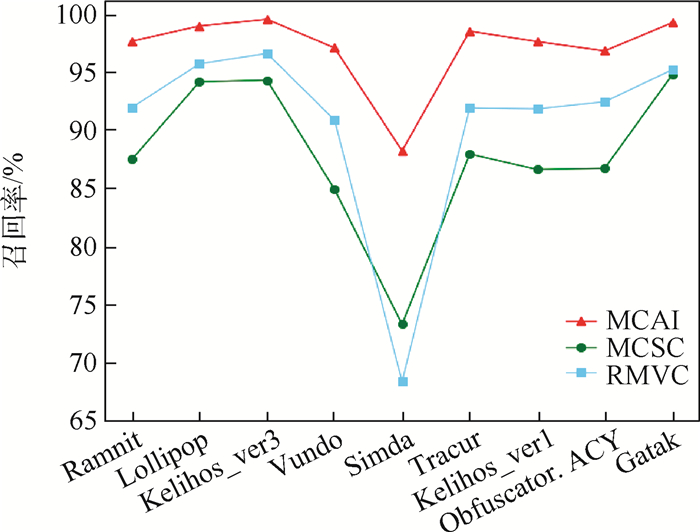
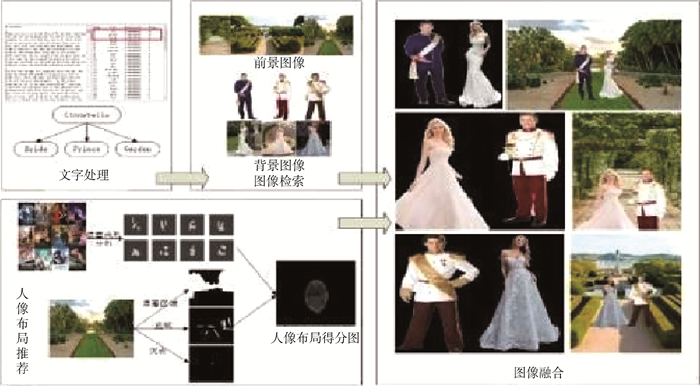
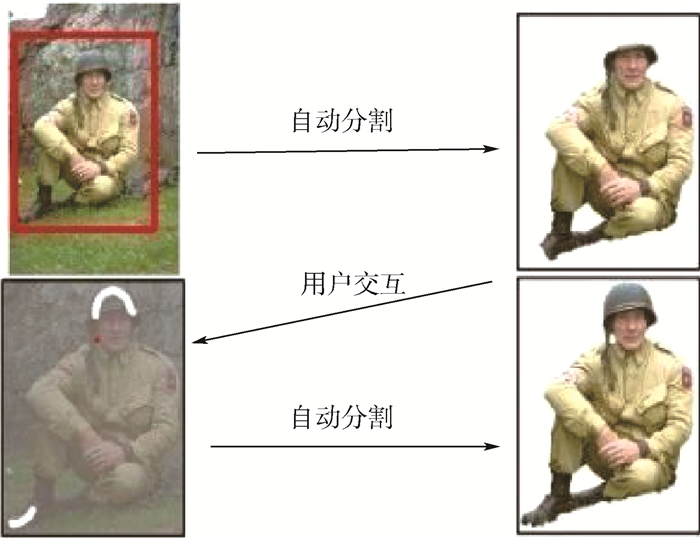
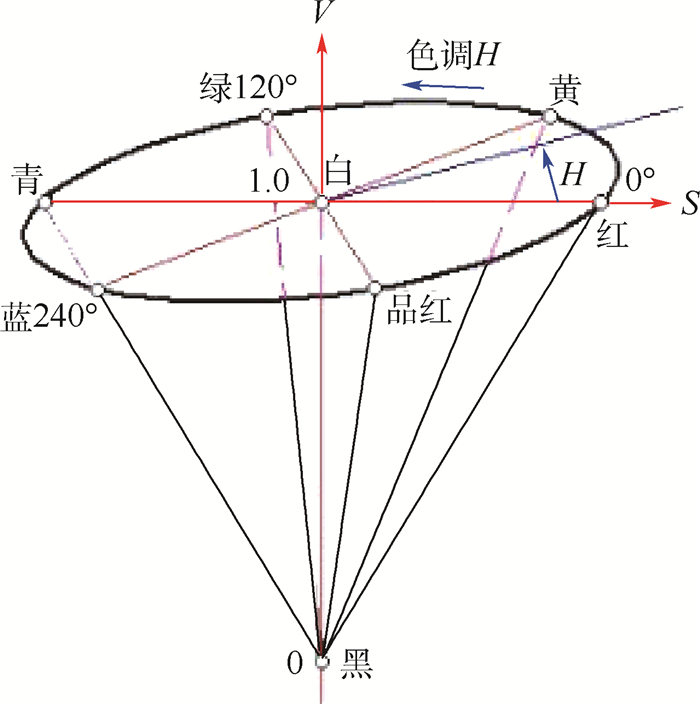
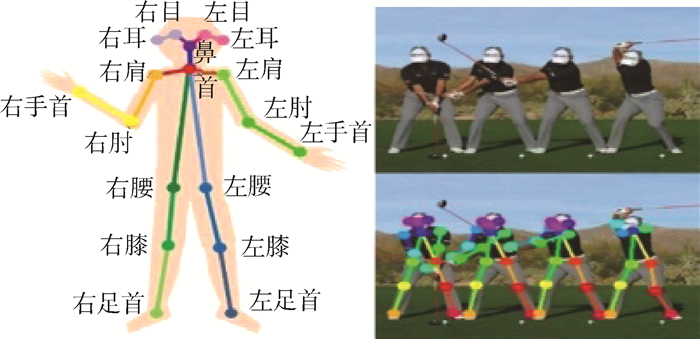
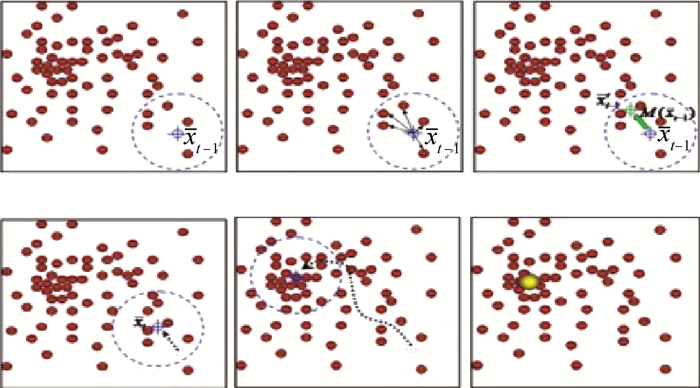
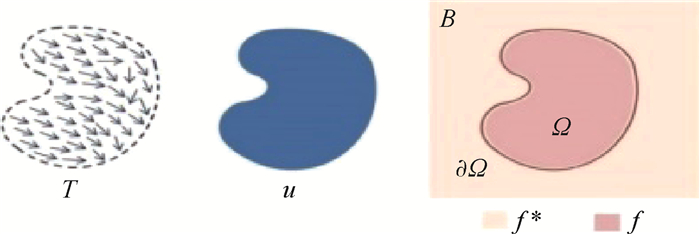
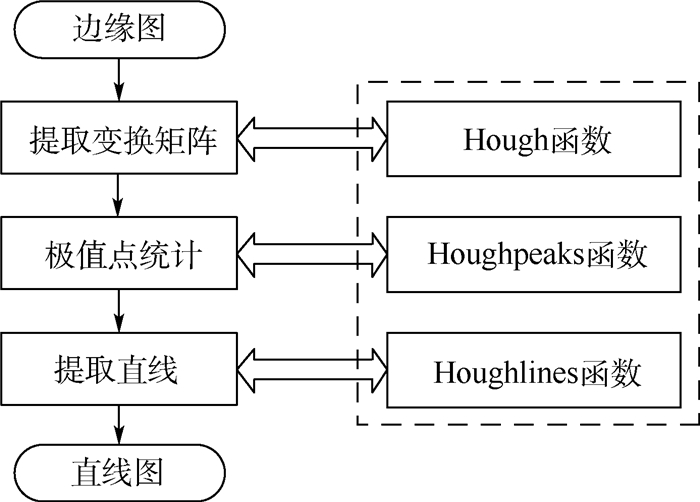
Due to the variety of data types and desensitization demand in different scenarios, traditional data masking methods cannot meet the user privacy protection requirements in the environment of big data. How to realize the accurate pointing and efficient desensitization of heterogeneous big data for data security, trust and availability, has become the key in this area. In this paper, we propose a data masking model for heterogeneous big data applications, such as texts, images, voices and databases, and four key modules are presented in our model. First, the sensitive data automatic identification and classification in different applications are realized in different application scenarios by desensitization data preprocessing. Second, with data pre-masking method, the data masking evaluation is implemented in five dimensions, including data availability, data relevance, degree of privacy protection, and time and space complexity, to construct the customized desensitization strategy. Finally, after task scheduling, the allocation and execution of the data masking tasks are performed, and the masking data recovery can also be partially supported. Two typical data masking applications are verified and analyzed based on the proposed heterogeneous big data masking model, indicating that effective desensitization can be achieved in different application scenarios.



 Download (50857)
Download (50857) 
 Views
Views  Cited by
Cited by 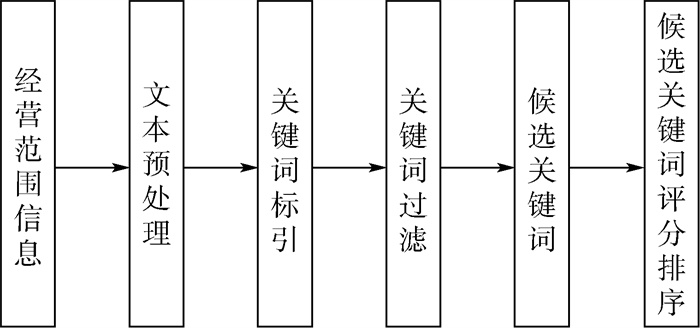

















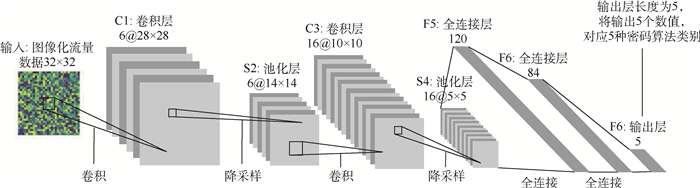
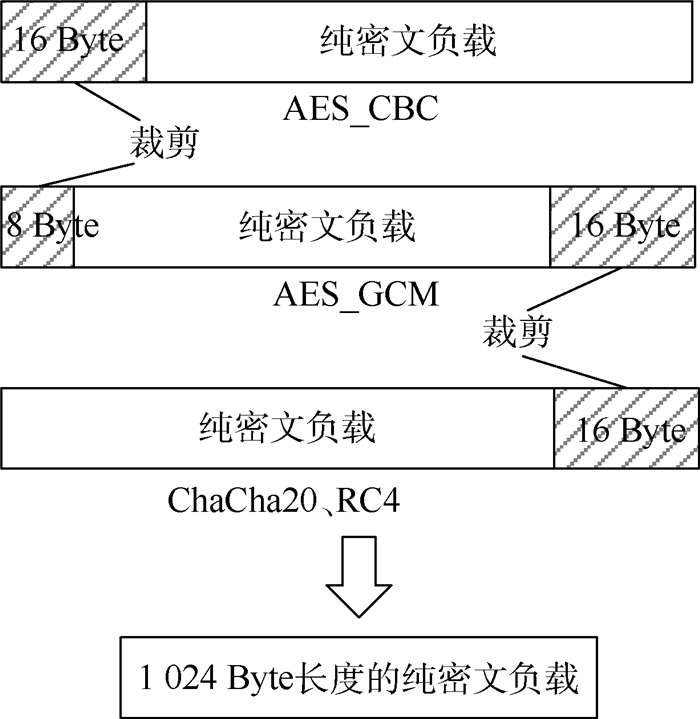
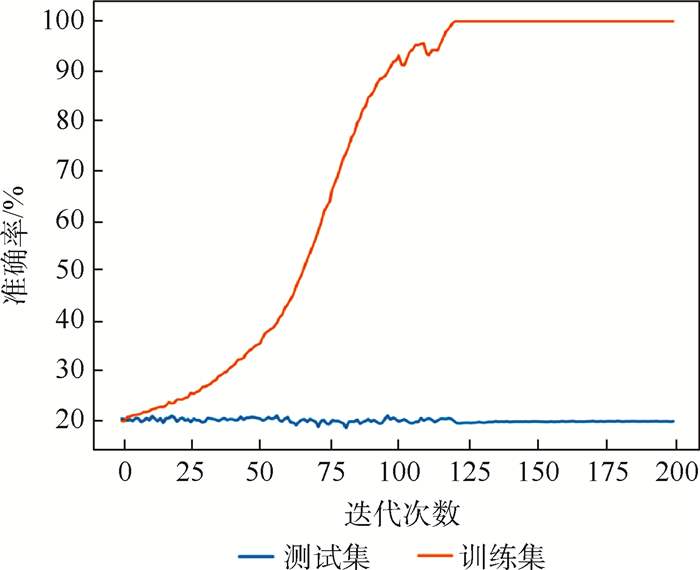















 XML Online Production Platform
XML Online Production Platform
